
Semakin sering permintaan berikut datang dari pelanggan: "Kami menginginkannya seperti Amazon RDS, tetapi lebih murah"; "Kami menginginkannya seperti RDS, tetapi di mana pun, dalam infrastruktur apa pun." Untuk mengimplementasikan solusi terkelola seperti itu di Kubernetes, kami melihat keadaan operator paling populer saat ini untuk PostgreSQL (Stolon, operator dari Crunchy Data dan Zalando) dan membuat pilihan kami.
Artikel ini adalah pengalaman kami baik dari sudut pandang teoritis (tinjauan solusi) dan dari sudut pandang praktis (apa yang dipilih dan apa hasilnya). Tapi pertama-tama, mari kita tentukan apa persyaratan umum untuk calon pengganti RDS ...
Apa itu RDS
Ketika orang berbicara tentang RDS, menurut pengalaman kami yang mereka maksud adalah layanan DBMS terkelola yang:
- mudah disesuaikan;
- memiliki kemampuan untuk bekerja dengan snapshot dan memulihkannya (sebaiknya dengan dukungan PITR );
- memungkinkan Anda membuat topologi master-slave;
- memiliki daftar ekstensi yang kaya;
- menyediakan audit dan manajemen pengguna / akses.
Secara umum, pendekatan pelaksanaan tugas bisa sangat berbeda, tetapi jalur dengan Ansible bersyarat tidak dekat dengan kita. (Kesimpulan serupa dicapai oleh kolega di 2GIS sebagai hasil dari upaya mereka untuk membuat "alat untuk dengan cepat menerapkan kluster failover berdasarkan Postgres.")
Operator adalah pendekatan yang diterima secara umum untuk memecahkan masalah seperti itu di ekosistem Kubernetes. Rincian lebih lanjut tentang mereka terkait dengan database yang berjalan di dalam Kubernetes telah diberitahukan oleh departemen teknis Flant,distol, di salah satu laporannya .
NB : Untuk membuat operator sederhana dengan cepat, kami menyarankan Anda untuk memperhatikan utilitas shell-operator open source kami . Dengan menggunakannya, Anda dapat melakukan ini tanpa pengetahuan tentang Go, tetapi dengan cara yang lebih familiar bagi sysadmin: di Bash, Python, dll.
Ada beberapa operator K8s populer untuk PostgreSQL:
- Stolon;
- Operator PostgreSQL Data Renyah;
- Operator Zalando Postgres.
Mari kita lihat lebih dekat.
Pemilihan operator
Selain fitur-fitur penting yang telah disebutkan di atas, kami - sebagai teknisi operasi infrastruktur di Kubernetes - juga mengharapkan hal-hal berikut dari operator:
- menyebarkan dari Git dan dari Sumber Daya Kustom ;
- dukungan anti-afinitas pod;
- memasang afinitas node atau pemilih node;
- mengatur toleransi;
- ketersediaan peluang tuning;
- teknologi yang dapat dimengerti dan bahkan perintah.
Tanpa merinci masing-masing poin (tanyakan di komentar jika Anda masih memiliki pertanyaan tentang mereka setelah membaca seluruh artikel), saya perhatikan secara umum bahwa parameter ini diperlukan untuk deskripsi yang lebih rinci tentang spesialisasi node cluster untuk memesannya untuk aplikasi tertentu. Dengan cara ini kami dapat mencapai keseimbangan optimal antara kinerja dan biaya.
Sekarang untuk operator PostgreSQL itu sendiri.
1. Stolon
Stolon dari perusahaan Italia Sorint.lab dalam laporan tersebut dianggap sebagai standar tertentu di antara operator untuk DBMS. Ini adalah proyek yang agak lama: rilis publik pertamanya dilakukan pada November 2015 (!), Dan repositori GitHub menawarkan hampir 3000 bintang dan 40+ kontributor.
Memang, Stolon adalah contoh bagus dari arsitektur yang dipikirkan dengan baik:
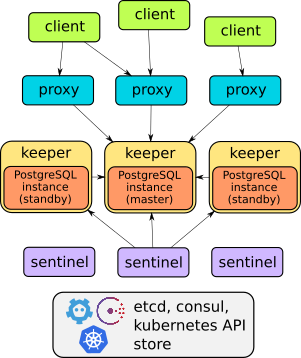
Detail perangkat operator ini dapat ditemukan di laporan atau dokumentasi proyek . Secara umum, cukup untuk mengatakan bahwa dia dapat melakukan semua yang dijelaskan: failover, proxy untuk akses klien transparan, cadangan ... Selain itu, proxy menyediakan akses melalui satu layanan titik akhir - tidak seperti dua solusi lain yang dibahas di bawah (mereka memiliki dua layanan untuk mengakses mendasarkan).
Akan tetapi, Stolon tidak memiliki Sumber Daya Kustom , itulah sebabnya ia tidak dapat diterapkan sedemikian rupa dengan mudah dan cepat - "seperti kue panas" - membuat instance DBMS di Kubernetes. Manajemen dilakukan melalui utilitas
stolonctl, penerapan - melalui Helm-chart, dan setelan pengguna ditentukan di ConfigMap.
Di satu sisi, ternyata operator bukanlah operator (lagipula, ia tidak menggunakan CRD). Namun di sisi lain, ini adalah sistem fleksibel yang memungkinkan Anda menyesuaikan sumber daya di K8 sesuka Anda.
Untuk meringkas, bagi kami pribadi, ini bukan cara yang optimal untuk membuat bagan terpisah untuk setiap database. Karena itu, kami mulai mencari alternatif.
2. Operator PostgreSQL Data Renyah
Operator dari Crunchy Data , startup muda Amerika, tampak seperti alternatif yang logis. Sejarah publiknya dimulai dengan rilis pertama pada Maret 2017, sejak itu repositori GitHub telah menerima kurang dari 1.300 bintang dan 50+ kontributor. Rilis terbaru dari bulan September telah diuji untuk bekerja dengan Kubernetes 1.15-1.18, OpenShift 3.11+ dan 4.4+, GKE dan VMware Enterprise PKS 1.3+.
Arsitektur Crunchy Data PostgreSQL Operator juga memenuhi persyaratan yang disebutkan:
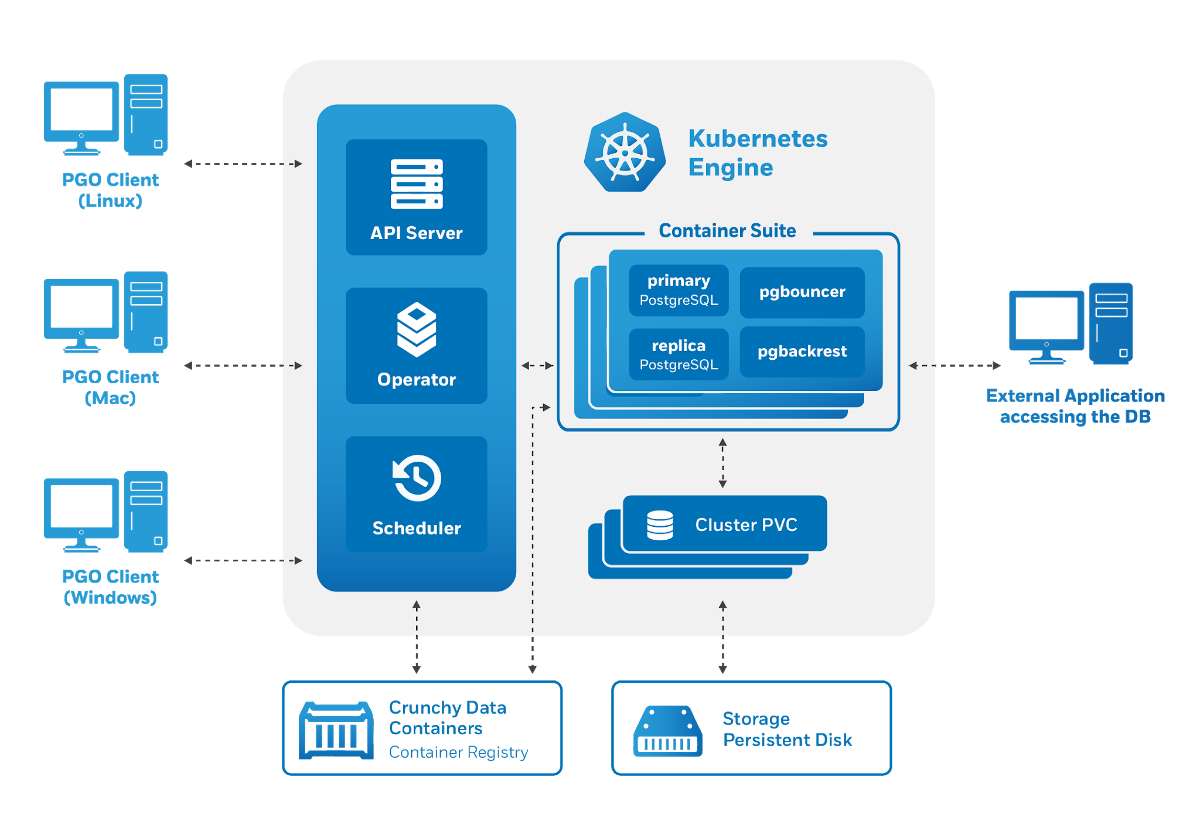
Manajemen terjadi melalui utilitas
pgo, tetapi, pada gilirannya, menghasilkan Sumber Daya Kustom untuk Kubernetes. Oleh karena itu, operator menyenangkan kami sebagai pengguna potensial:
- ada kontrol melalui CRD;
- manajemen pengguna yang nyaman (juga melalui CRD);
- integrasi dengan komponen lain dari Crunchy Data Container Suite - kumpulan khusus gambar container untuk PostgreSQL dan utilitas untuk bekerja dengannya (termasuk pgBackRest, pgAudit, ekstensi kontrib, dll.).
Namun, upaya untuk mulai menggunakan operator dari Crunchy Data mengungkapkan beberapa masalah:
- Tidak ada kemungkinan toleransi - hanya nodeSelector yang disediakan.
- Pod yang kami buat adalah bagian dari Deployment, meskipun faktanya kami menerapkan aplikasi stateful. Tidak seperti StatefulSets, Deployments tidak dapat membuat disk.
Kelemahan terakhir mengarah ke momen lucu: di lingkungan pengujian, dimungkinkan untuk menjalankan 3 replika dengan satu disk penyimpanan lokal , sebagai akibatnya operator melaporkan bahwa 3 replika berfungsi (meskipun ini bukan masalahnya).
Fitur lain dari operator ini adalah integrasi siap pakai dengan berbagai sistem tambahan. Misalnya, mudah untuk menginstal pgAdmin dan pgBounce, dan dokumentasinya mencakup Grafana dan Prometheus yang telah dikonfigurasi sebelumnya. Rilis terbaru 4.5.0-beta1 secara terpisah mencatat peningkatan integrasi dengan proyek pgMonitor , yang karenanya operator menawarkan visualisasi visual metrik untuk PgSQL di luar kotak.
Namun, pilihan aneh sumber daya Kubernetes yang dihasilkan membuat kami mencari solusi lain.
3. Operator Zalando Postgres
Kami telah mengenal produk Zalando sejak lama: kami memiliki pengalaman menggunakan Zalenium dan, tentu saja, kami mencoba Patroni , solusi HA populer mereka untuk PostgreSQL. Salah satu penulisnya, Aleksey Klyukin, berbicara tentang pendekatan perusahaan terhadap pembuatan Postgres Operator di Postgres-Tuesday # 5 , dan kami menyukainya.
Ini adalah solusi termuda yang dibahas dalam artikel: rilis pertama terjadi pada Agustus 2018. Namun, terlepas dari jumlah rilis formal yang sedikit, proyek ini telah berkembang pesat, telah melampaui popularitas solusi dari Crunchy Data dengan 1300+ bintang di GitHub dan jumlah kontributor maksimum (70+).
Di bawah kap operator ini, solusi yang telah teruji waktu digunakan:
Beginilah cara arsitektur operator Zalando ditampilkan:
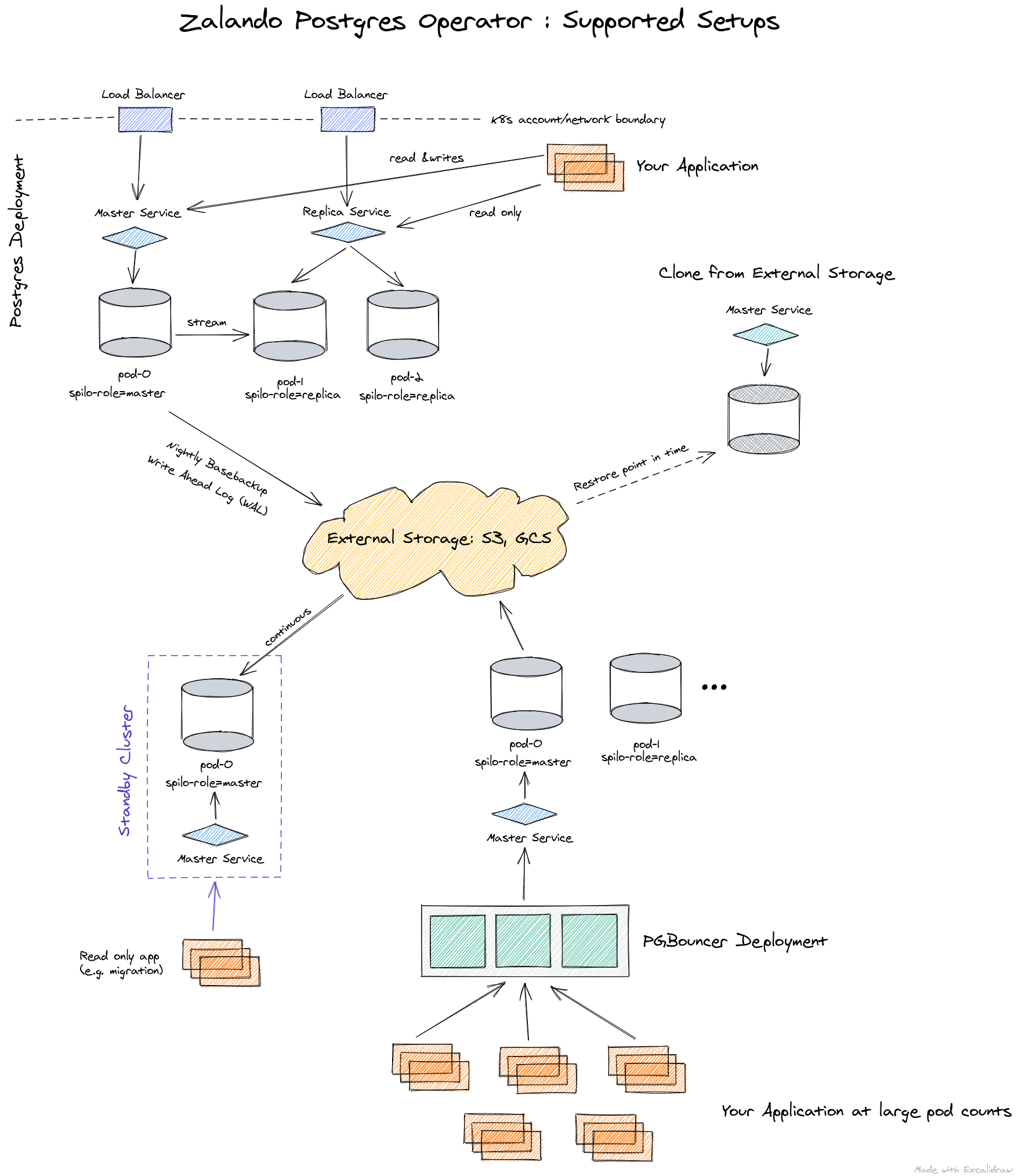
Operator sepenuhnya dikelola melalui Sumber Daya Kustom, secara otomatis membuat StatefulSet dari container, yang kemudian dapat disesuaikan dengan menambahkan berbagai sidecars ke pod. Semua ini merupakan nilai tambah yang signifikan dibandingkan dengan operator dari Crunchy Data.
Karena itu adalah solusi dari Zalando yang kami pilih di antara 3 opsi yang dipertimbangkan, penjelasan lebih lanjut tentang kemampuannya akan disajikan di bawah ini, segera bersama dengan praktik penerapannya.
Berlatih dengan Operator Postgres Zalando
Menerapkan operator sangat sederhana: cukup unduh rilis saat ini dari GitHub dan terapkan file YAML dari direktori manifes . Atau, Anda juga dapat menggunakan OperatorHub .
Setelah instalasi, Anda harus khawatir tentang menyiapkan penyimpanan untuk log dan cadangan . Ini dilakukan melalui ConfigMap
postgres-operatordi namespace tempat Anda menginstal pernyataan. Dengan repositori yang dikonfigurasi, Anda dapat menerapkan cluster PostgreSQL pertama Anda.
Misalnya, penerapan standar kami terlihat seperti ini:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Manifes ini menerapkan sekumpulan 3 instance dengan bantuan dalam bentuk postgres_exporter , tempat kami mengambil metrik aplikasi. Seperti yang Anda lihat, semuanya sangat sederhana, dan jika mau, Anda dapat membuat cluster dalam jumlah yang tidak terbatas.
Perlu memperhatikan panel administrasi web - postgres-operator-ui . Itu datang dengan operator dan memungkinkan Anda untuk membuat dan menghapus cluster, serta bekerja dengan backup yang dibuat oleh operator. Manajemen Cadangan
Daftar Cluster PostgreSQL Fitur menarik lainnya adalah dukungan API Teams . Mekanisme ini secara otomatis membuat peran di PostgreSQL
berdasarkan daftar nama pengguna yang dihasilkan. Setelah itu, API memungkinkan Anda menampilkan daftar pengguna yang perannya dibuat secara otomatis.
Masalah dan solusi
Namun, penggunaan operator segera menunjukkan beberapa kerugian yang signifikan:
- kurangnya dukungan untuk nodeSelector;
- ketidakmampuan untuk menonaktifkan backup;
- saat menggunakan fungsi pembuatan database, hak istimewa default tidak muncul;
- secara berkala tidak ada dokumentasi yang cukup atau sudah usang.
Untungnya, banyak di antaranya dapat diselesaikan. Mari kita mulai dari akhir - masalah dengan dokumentasi .
Kemungkinan besar, Anda akan menemukan fakta bahwa cara mendaftarkan cadangan dan cara menghubungkan keranjang cadangan ke UI Operator tidak selalu jelas. Dokumentasi membicarakan hal ini secara sepintas, tetapi deskripsi sebenarnya ada di PR :
- Anda perlu membuat rahasia;
-
pod_environment_secret_nameCRD ConfigMap ( , ).
Namun, ternyata, saat ini hal tersebut tidak mungkin. Itulah mengapa kami telah menyusun versi kami sendiri dari operator dengan beberapa pengembangan pihak ketiga tambahan. Lihat di bawah untuk lebih jelasnya.
Jika Anda meneruskan parameter untuk pencadangan ke operator, yaitu,
wal_s3_bucketkunci akses di AWS S3, maka dia akan mencadangkan semuanya : tidak hanya basis dalam produksi, tetapi juga pementasan. Itu tidak cocok untuk kita.
Dalam deskripsi parameter untuk Spilo, yang merupakan pembungkus Docker dasar untuk PgSQL saat menggunakan operator, ternyata Anda dapat mengirimkan parameter
WAL_S3_BUCKETkosong, sehingga menonaktifkan backup. Selain itu, dengan sukacita yang besar, PR yang sudah jadi ditemukan , yang segera kami terima ke garpu kami. Sekarang cukup dengan menambahkan enableWALArchiving: falsecluster PostgreSQL ke sumber daya.
Ya, ada peluang untuk melakukannya secara berbeda dengan menjalankan 2 operator: satu untuk pementasan (tanpa cadangan), dan yang kedua untuk produksi. Tapi jadi kami bisa bertahan dengan satu.
Ok, kita belajar bagaimana mentransfer akses ke database untuk S3 dan backup mulai masuk ke penyimpanan. Bagaimana cara membuat halaman cadangan berfungsi di UI Operator?

Di UI Operator, Anda perlu menambahkan 3 variabel:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
Setelah itu, mengelola cadangan akan tersedia, yang dalam kasus kami akan menyederhanakan pekerjaan dengan pementasan, memungkinkan Anda mengirimkan potongan dari produksi di sana tanpa skrip tambahan.
Bekerja dengan Teams API dan peluang luas untuk membuat basis dan peran menggunakan alat operator disebut sebagai nilai tambah lainnya. Namun, peran yang dibuat tidak memiliki hak default . Karenanya, pengguna dengan hak baca tidak dapat membaca tabel baru.
Mengapa demikian? Terlepas dari kenyataan bahwa kode tersebut berisi yang diperlukan
GRANT, mereka tidak selalu digunakan. Ada 2 metode: syncPreparedDatabasesdan syncDatabases. B syncPreparedDatabases- terlepas dari kenyataan bahwa preparedDatabases ada kondisi di bagian defaultRolesdandefaultUsersuntuk membuat peran, hak default tidak diterapkan. Kami sedang dalam proses menyiapkan tambalan agar hak-hak ini diterapkan secara otomatis.
Dan momen terakhir dalam peningkatan yang relevan bagi kami adalah tambalan yang menambahkan Node Affinity ke StatefulSet yang dibuat. Klien kami sering kali lebih suka memotong biaya dengan menggunakan instance spot, dan mereka jelas tidak boleh menghosting layanan database. Masalah ini bisa diselesaikan melalui toleransi, tetapi kehadiran Node Affinity memberi banyak kepercayaan.
Apa yang terjadi?
Sebagai hasil dari pemecahan masalah di atas, kami membagi Operator Postgres dari Zalando ke dalam repositori kami , di mana ia dibangun dengan tambalan yang sangat berguna. Dan demi kenyamanan, kami juga mengumpulkan image Docker .
Daftar PR bercabang:
- membangun di Docker gambar ringan yang aman untuk operator ;
- nonaktifkan cadangan ;
- memperbarui versi sumber daya untuk versi k8s saat ini ;
- implementasi Node Affinity .
Akan sangat bagus jika komunitas mendukung PR ini sehingga mereka mendapatkan upstream dengan versi operator berikutnya (1.6).
Bonus! Kisah sukses migrasi produksi
Jika Anda menggunakan Patroni, produksi langsung dapat dipindahkan ke operator dengan waktu henti yang minimal.
Spilo memungkinkan Anda membuat kluster siaga melalui penyimpanan S3 dengan Wal-E , saat log biner PgSQL pertama kali disimpan ke S3 dan kemudian diunduh oleh replika. Tetapi bagaimana jika Anda tidak memiliki Wal-E di infrastruktur lama Anda? Solusi untuk masalah ini telah diusulkan di Habré.
Replikasi logis PostgreSQL datang untuk menyelamatkan. Namun, kami tidak akan menjelaskan secara rinci tentang cara membuat publikasi dan langganan, karena ... rencana kami gagal.
Faktanya adalah bahwa database memiliki beberapa tabel yang dimuat dengan jutaan baris, yang, terlebih lagi, terus-menerus diisi ulang dan dihapus. Langganan sederhana dengan
copy_data, saat replika baru menyalin semua konten dari master, replika tersebut sama sekali tidak mengikuti master. Menyalin konten berhasil selama seminggu, tetapi tidak pernah menyusul masternya. Hasilnya, artikel oleh kolega dari Avito membantu mengatasi masalah tersebut : Anda dapat mentransfer data menggunakan pg_dump. Saya akan menjelaskan versi algoritma ini (sedikit dimodifikasi).
Idenya adalah Anda dapat membuat langganan dimatikan terkait dengan slot replikasi tertentu dan kemudian memperbaiki nomor transaksi. Ada replika untuk pekerjaan produksi. Ini penting karena replika akan membantu membuat dump yang konsisten dan terus menerima perubahan dari master.
Dalam perintah berikut yang menjelaskan proses migrasi, notasi host berikut akan digunakan:
- master - server sumber;
- replica1 - replika streaming pada produksi lama;
- replica2 adalah replika logis baru.
Rencana migrasi
1. Di wizard, buat langganan ke semua tabel di skema
publicdatabase dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Mari buat slot replikasi pada master:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Hentikan replikasi pada replika lama:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Dapatkan nomor transaksi dari master:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Buang replika lama. Kami akan melakukan ini di beberapa utas, yang akan membantu mempercepat proses:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Unggah dump ke server baru:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. Setelah mengunduh dump, Anda dapat memulai replikasi pada replika streaming:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Mari buat langganan pada replika logis baru:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Dapatkan
oidlangganan:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Katakanlah itu diterima
oid=1000. Mari terapkan nomor transaksi untuk berlangganan:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Mari mulai replikasi:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Periksa status langganan, replikasi harus berfungsi:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. Setelah replikasi dimulai dan database disinkronkan, Anda dapat beralih.
13. Setelah menonaktifkan replikasi, Anda perlu memperbaiki urutannya. Ini didokumentasikan dengan baik dalam artikel di wiki.postgresql.org .
Berkat rencana ini, peralihan berjalan dengan penundaan yang minimal.
Kesimpulan
Operator Kubernetes memungkinkan Anda menyederhanakan berbagai aktivitas dengan menguranginya menjadi sumber daya K8s. Namun, setelah mencapai otomatisasi yang luar biasa dengan bantuan mereka, perlu diingat bahwa hal itu juga dapat menghadirkan sejumlah nuansa tak terduga, jadi pilihlah operator Anda dengan bijak.
Setelah meninjau tiga operator Kubernetes terpopuler untuk PostgreSQL, kami memilih sebuah proyek dari Zalando. Dan saya harus mengatasi kesulitan tertentu dengannya, tetapi hasilnya sangat memuaskan, jadi kami berencana untuk memperluas pengalaman ini ke beberapa instalasi PgSQL lainnya. Jika Anda memiliki pengalaman menggunakan solusi serupa, kami akan senang melihat detailnya di komentar!
PS
Baca juga di blog kami: