Tetapi bagaimana jika Anda mulai menggunakan beberapa produk non-SAP dan lebih disukai produk OpenSource sebagai penyimpanan? Kami di Grup Ritel X5 memilih GreenPlum. Ini, tentu saja, memecahkan masalah biaya, tetapi pada saat yang sama, pertanyaan segera muncul yang, ketika menggunakan SAP BW, diselesaikan hampir secara default.

Secara khusus, bagaimana cara mendapatkan data dari sistem sumber, yang sebagian besar merupakan solusi SAP?
Metrik SDM adalah proyek pertama yang menangani masalah ini. Tujuan kami adalah membuat gudang untuk data SDM dan membangun pelaporan analitik di area kerja dengan karyawan. Dalam hal ini, sumber data utama adalah sistem transaksional SAP HCM, di mana semua aktivitas kepegawaian, organisasi dan penggajian dilakukan.
Ekstraksi data
Ada ekstraktor data standar dalam SAP BW untuk sistem SAP. Ekstraktor ini dapat secara otomatis mengumpulkan data yang diperlukan, melacak integritasnya, dan menentukan delta perubahan. Misalnya, berikut adalah sumber data standar untuk atribut karyawan 0EMPLOYEE_ATTR:

Hasil ekstraksi data dari satu karyawan dalam satu waktu:
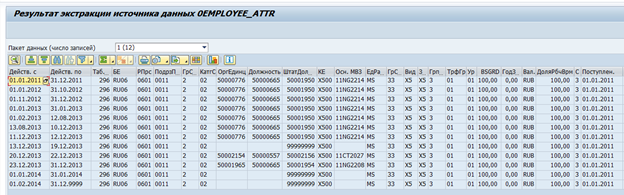
Jika perlu, ekstraktor semacam itu dapat dimodifikasi agar sesuai dengan kebutuhan Anda, atau ekstraktor Anda sendiri dapat dibuat.
Ide pertama muncul tentang kemungkinan penggunaan kembali mereka. Sayangnya, ini terbukti menjadi tugas yang mustahil. Sebagian besar logika diimplementasikan di sisi SAP BW, dan tidak mungkin memisahkan ekstraktor pada sumber dari SAP BW tanpa rasa sakit.
Menjadi jelas bahwa perlu mengembangkan mekanisme kustom untuk mengekstraksi data dari sistem SAP.
Struktur penyimpanan data di SAP HCM
Untuk memahami persyaratan mekanisme seperti itu, Anda harus terlebih dahulu menentukan jenis data yang kami butuhkan.
Sebagian besar data di SAP HCM disimpan dalam tabel SQL datar. Berdasarkan data ini, aplikasi SAP memvisualisasikan struktur organisasi, karyawan, dan informasi SDM lainnya kepada pengguna. Misalnya, ini adalah tampilan struktur organisasi di SAP HCM: Secara
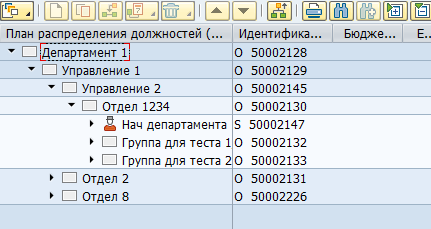
fisik, pohon seperti itu disimpan dalam dua tabel - dalam objek hrp1000 dan di hrp1001 tautan antara objek-objek ini.
Objek "Departemen 1" dan "Kantor 1":

Komunikasi antar objek:

Ada banyak sekali jenis objek dan jenis komunikasi di antara mereka. Ada kedua tautan standar antar objek, dan disesuaikan untuk kebutuhan spesifik Anda sendiri. Misalnya, hubungan B012 standar antara unit organisasi dan posisi penuh waktu menunjukkan kepala departemen.
Pemetaan manajer di SAP:
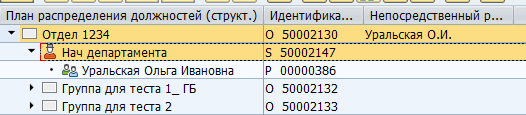
Penyimpanan di tabel DB:

Data karyawan disimpan dalam tabel pa *. Misalnya, data tentang aktivitas kepegawaian untuk seorang karyawan disimpan di tabel pa0000.
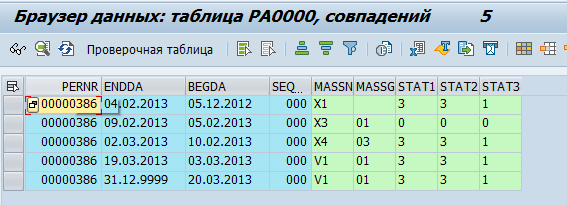
Kami telah memutuskan bahwa GreenPlum akan mengambil data "mentah", yaitu cukup salin dari tabel SAP. Dan sudah langsung di GreenPlum, mereka akan diproses dan diubah menjadi objek fisik (misalnya, Departemen atau Karyawan) dan metrik (misalnya, jumlah karyawan rata-rata).
Sekitar 70 tabel telah ditentukan, datanya harus ditransfer ke GreenPlum. Setelah itu, kami mulai mencari cara untuk mentransfer data ini.
SAP menawarkan sejumlah besar mekanisme integrasi. Tetapi cara termudah - akses langsung ke database dilarang karena pembatasan lisensi. Jadi, semua aliran integrasi harus diimplementasikan di tingkat server aplikasi.
Masalah berikutnya adalah kurangnya data tentang catatan yang dihapus dalam database SAP. Ketika sebuah baris dihapus dalam database, itu secara fisik dihapus. Itu. pembentukan delta perubahan selama waktu perubahan tidak mungkin.
Tentu saja, SAP HCM memiliki mekanisme untuk melakukan perubahan data. Misalnya, untuk transmisi selanjutnya ke sistem, penerima memiliki penunjuk perubahan yang merekam setiap perubahan dan atas dasar yang membentuk Idoc (objek untuk transmisi ke sistem eksternal).
Contoh IDoc untuk mengganti infotype 0302 untuk karyawan dengan nomor personel 1251445:
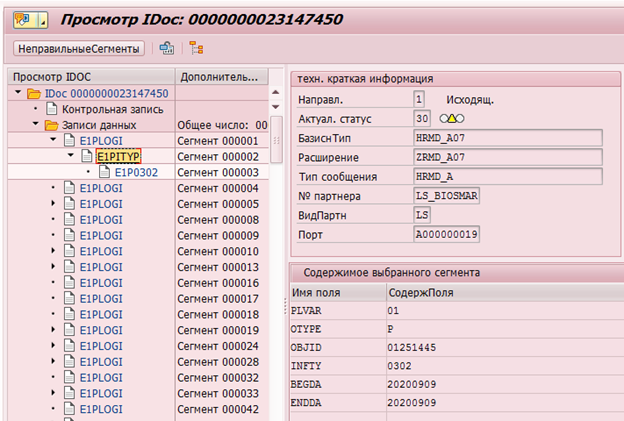
Atau memelihara log perubahan data di tabel DBTABLOG.
Contoh log untuk menghapus entri dengan kunci QK53216375 dari tabel hrp1000:

Tetapi mekanisme ini tidak tersedia untuk semua data yang diperlukan, dan pemrosesannya di tingkat server aplikasi dapat menghabiskan banyak sumber daya. Oleh karena itu, pencatatan log secara besar-besaran pada semua tabel yang diperlukan dapat menyebabkan penurunan kinerja sistem yang nyata.
Tabel yang dikelompokkan adalah masalah besar berikutnya. Perkiraan waktu dan data penggajian dalam versi RDBMS dari SAP HCM disimpan sebagai sekumpulan tabel logis per karyawan per penggajian. Tabel logis ini disimpan sebagai data biner di tabel pcl2.
Gugus Penggajian:
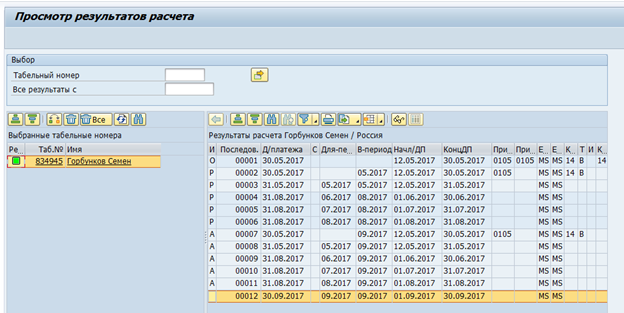
Data dari tabel berkerumun tidak dapat dibaca dengan perintah SQL dan memerlukan penggunaan makro SAP HCM atau modul fungsi khusus. Karenanya, kecepatan membaca tabel semacam itu akan sangat rendah. Di sisi lain, cluster seperti itu menyimpan data yang hanya dibutuhkan sebulan sekali - gaji akhir dan perkiraan waktu. Jadi kecepatan dalam hal ini tidak terlalu penting.
Mengevaluasi opsi dengan pembentukan delta perubahan data, kami memutuskan untuk juga mempertimbangkan opsi dengan pembongkaran penuh. Opsi untuk mentransfer gigabyte data yang tidak berubah antar sistem setiap hari tidak terlihat cantik. Namun, ini juga memiliki sejumlah keunggulan - tidak perlu implementasi delta di sisi sumber dan implementasi menyematkan delta ini di sisi penerima. Karenanya, biaya dan waktu implementasi berkurang, dan keandalan integrasi meningkat. Pada saat yang sama, diputuskan bahwa hampir semua perubahan dalam SAP HR terjadi dalam cakrawala tiga bulan sebelum tanggal saat ini. Dengan demikian, diputuskan untuk berhenti pada pengunduhan penuh harian data dari SAP HR N beberapa bulan sebelum tanggal saat ini dan pada pengunduhan penuh bulanan. Parameter N bergantung pada tabel spesifik
dan berkisar dari 1 hingga 15.
Untuk ekstraksi data, skema berikut diusulkan:

Sistem eksternal menghasilkan permintaan dan mengirimkannya ke SAP HCM, di mana permintaan ini diperiksa untuk kelengkapan data dan otorisasi untuk mengakses tabel. Jika pemeriksaan berhasil, SAP HCM menjalankan program yang mengumpulkan data yang diperlukan dan mentransfernya ke solusi integrasi Sekring. Fuse mendefinisikan topik yang diperlukan di Kafka dan meneruskan data di sana. Selanjutnya, data dari Kafka ditransfer ke Stage Area GP.
Kami di rantai ini tertarik dengan masalah penggalian data dari SAP HCM. Mari kita bahas lebih detail.
Diagram interaksi SAP HCM-FUSE.
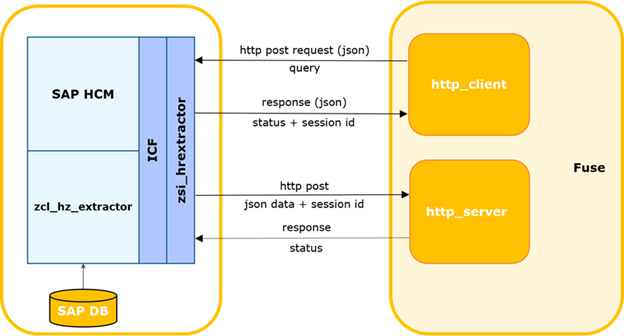
Sistem eksternal menentukan waktu permintaan terakhir yang berhasil ke SAP.
Prosesnya dapat dimulai dengan timer atau peristiwa lain, termasuk waktu tunggu untuk menunggu respons dengan data dari SAP dan inisiasi permintaan berulang. Kemudian itu menghasilkan permintaan delta dan mengirimkannya ke SAP.
Data permintaan diteruskan dalam body dalam format json.
Metode http: POST.
Permintaan sampel:

Layanan SAP memeriksa permintaan untuk kelengkapan, kepatuhan dengan struktur SAP saat ini, dan ketersediaan izin untuk mengakses tabel yang diminta.
Jika terjadi kesalahan, layanan mengembalikan respons dengan kode dan deskripsi yang sesuai. Jika kontrol berhasil, ini membuat proses latar belakang untuk menghasilkan pilihan, menghasilkan dan secara sinkron mengembalikan id sesi unik.
Sistem eksternal akan mencatatnya jika terjadi kesalahan. Jika respons berhasil, ia mengirimkan id sesi dan nama tabel yang membuat permintaan tersebut.
Sistem eksternal mendaftarkan sesi saat ini sebagai buka. Jika ada sesi lain untuk tabel ini, mereka ditutup dengan peringatan dicatat.
Pekerjaan latar belakang SAP menghasilkan kursor sesuai dengan parameter yang ditentukan dan paket data dengan ukuran yang ditentukan. Ukuran paket - jumlah maksimum rekaman yang dibaca proses dari database. Secara default, diasumsikan 2000. Jika sampel database berisi lebih banyak catatan daripada ukuran paket yang digunakan, setelah transmisi paket pertama, blok berikutnya dibentuk dengan offset yang sesuai dan nomor paket yang bertambah. Jumlahnya bertambah 1 dan dikirim secara berurutan.
Selanjutnya, SAP meneruskan paket sebagai input ke layanan web sistem eksternal. Dan itu adalah sistem yang mengontrol paket yang masuk. Sesi dengan id yang diterima harus terdaftar di sistem dan harus dalam keadaan terbuka. Jika nomor paket> 1, sistem harus mencatat penerimaan paket sebelumnya yang berhasil (package_id-1).
Jika kontrol berhasil, sistem eksternal akan mem-parsing dan menyimpan data tabel.
Selain itu, jika bendera terakhir ada dalam paket dan serialisasi berhasil, modul integrasi akan diberi tahu tentang penyelesaian pemrosesan sesi yang berhasil dan modul memperbarui status sesi.
Jika terjadi kesalahan kontrol / penguraian, kesalahan dicatat dan paket untuk sesi ini akan ditolak oleh sistem eksternal.
Demikian juga, dalam kasus sebaliknya, ketika sistem eksternal mengembalikan kesalahan, itu dicatat dan pengiriman paket dihentikan.
Layanan integrasi diimplementasikan untuk meminta data di sisi SAP HM. Layanan diimplementasikan pada kerangka ICF (SAP Internet Communication Framework - help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/en-US/488d6e0ea6ed72d5e10000000a42189c.html ). Ini memungkinkan Anda untuk meminta data dari sistem SAP HCM pada tabel tertentu. Saat membentuk permintaan data, dimungkinkan untuk menentukan daftar bidang tertentu dan parameter pemfilteran untuk mendapatkan data yang diperlukan. Pada saat yang sama, implementasi layanan tidak menyiratkan logika bisnis apa pun. Algoritme untuk menghitung delta, parameter permintaan, kontrol integritas, dll. Juga diterapkan di sisi sistem eksternal.
Mekanisme ini memungkinkan Anda mengumpulkan dan mentransfer semua data yang diperlukan dalam beberapa jam. Kecepatan ini hampir dapat diterima, oleh karena itu, kami menganggap solusi ini sementara, yang memungkinkan untuk menutupi kebutuhan akan alat ekstraksi pada proyek.
Dalam gambar target untuk memecahkan masalah ekstraksi data, opsi untuk menggunakan sistem CDC seperti Oracle Golden Gate atau alat ETL seperti SAP DS sedang dikerjakan.