
Nama saya Ilya Gulyaev, saya adalah insinyur otomatisasi pengujian di tim Verifikasi Pasca Penerapan di DINS.
Di DINS, kami menggunakan Jenkins dalam banyak proses: mulai dari membangun build hingga menjalankan penerapan dan tes otomatis. Di tim saya, kami menggunakan Jenkins sebagai platform untuk meluncurkan pemeriksaan asap secara seragam setelah menerapkan setiap layanan kami dari lingkungan pengembangan hingga produksi.
Setahun yang lalu, tim lain memutuskan untuk menggunakan pipeline kami tidak hanya untuk memeriksa satu layanan setelah mengupdatenya, tetapi juga untuk memeriksa status seluruh lingkungan sebelum menjalankan batch pengujian yang besar. Beban pada platform kami telah meningkat sepuluh kali lipat, dan Jenkins telah berhenti menangani tugas yang ada dan baru saja mulai turun. Kami segera menyadari bahwa menambahkan sumber daya dan mengutak-atik pengumpul sampah hanya dapat menunda masalah, tetapi tidak menyelesaikannya sepenuhnya. Oleh karena itu, kami memutuskan untuk menemukan bottleneck Jenkins dan mengoptimalkannya.
Dalam artikel ini, saya akan menjelaskan cara kerja Jenkins Pipeline dan membagikan temuan saya yang dapat membantu Anda membuat pipeline Anda lebih cepat. Materi tersebut akan berguna bagi para insinyur yang telah bekerja dengan Jenkins dan ingin mengenal alat tersebut lebih baik.
Benar-benar Jenkins Pipeline Beast
Jenkins Pipeline adalah alat canggih yang memungkinkan Anda mengotomatiskan berbagai proses. Jenkins Pipeline adalah sekumpulan plugin yang memungkinkan Anda mendeskripsikan tindakan dalam bentuk Groovy DSL, dan merupakan penerus plugin Build Flow.
Skrip untuk plugin Build Flow dijalankan langsung pada master di utas Java terpisah yang menjalankan kode Groovy tanpa penghalang yang mencegah akses ke API internal Jenkins. Pendekatan ini menimbulkan risiko keamanan, yang kemudian menjadi salah satu alasan untuk mengabaikan Build Flow, dan berfungsi sebagai prasyarat untuk membuat alat yang aman dan skalabel untuk menjalankan skrip - Jenkins Pipeline.
Anda dapat mempelajari lebih lanjut tentang sejarah pembuatan Jenkins Pipeline dari artikel penulis Build Flow atauPembicaraan Oleg Nenashev tentang Groovy DSL di Jenkins .
Cara Kerja Jenkins Pipeline
Sekarang mari kita cari tahu bagaimana jaringan pipa bekerja dari dalam. Mereka biasanya mengatakan bahwa Jenkins Pipeline adalah jenis pekerjaan yang sama sekali berbeda di Jenkins, tidak seperti pekerjaan gaya bebas lama yang bagus yang dapat diklik di antarmuka web. Dari sudut pandang pengguna, mungkin terlihat seperti ini, tetapi dari sisi Jenkins, pipeline adalah sekumpulan plugin yang memungkinkan Anda mentransfer deskripsi tindakan ke dalam kode.
Kesamaan Pekerjaan Pipeline dan Freestyle
- Deskripsi pekerjaan (bukan langkah) disimpan dalam file config.xml
- Parameter disimpan di config.xml
- Pemicu juga disimpan di config.xml
- Dan bahkan beberapa opsi disimpan di config.xml
Begitu. Berhenti. The dokumentasi resmi mengatakan bahwa parameter, pemicu dan pilihan dapat diatur secara langsung dalam Pipeline. Dimana kebenarannya?
Yang benar adalah bahwa parameter yang dijelaskan di Pipeline akan secara otomatis ditambahkan ke bagian konfigurasi di antarmuka web saat pekerjaan dimulai. Anda dapat mempercayai saya karena saya menulis fungsi ini di edisi terbaru , tetapi lebih lanjut tentang ini di bagian kedua artikel.
Perbedaan antara Pekerjaan Pipeline dan Freestyle
- Pada saat memulai pekerjaan, Jenkins tidak mengetahui apapun tentang agen untuk melaksanakan pekerjaan tersebut.
- Tindakannya dijelaskan dalam satu skrip yang menarik.
Meluncurkan Jenkins Declarative Pipeline
Proses startup Jenkins Pipeline terdiri dari langkah-langkah berikut:
- Muat deskripsi pekerjaan dari file config.xml
- Memulai utas terpisah (pemain ringan) untuk menyelesaikan tugas
- Memuat skrip pipeline
- Membangun dan memeriksa pohon sintaks
- Pembaruan konfigurasi pekerjaan
- Menggabungkan parameter dan properti yang ditentukan dalam deskripsi pekerjaan dan dalam skrip
- Menyimpan Deskripsi Pekerjaan ke Sistem File
- Menjalankan skrip di kotak pasir yang keren
- Agen meminta seluruh pekerjaan atau satu langkah
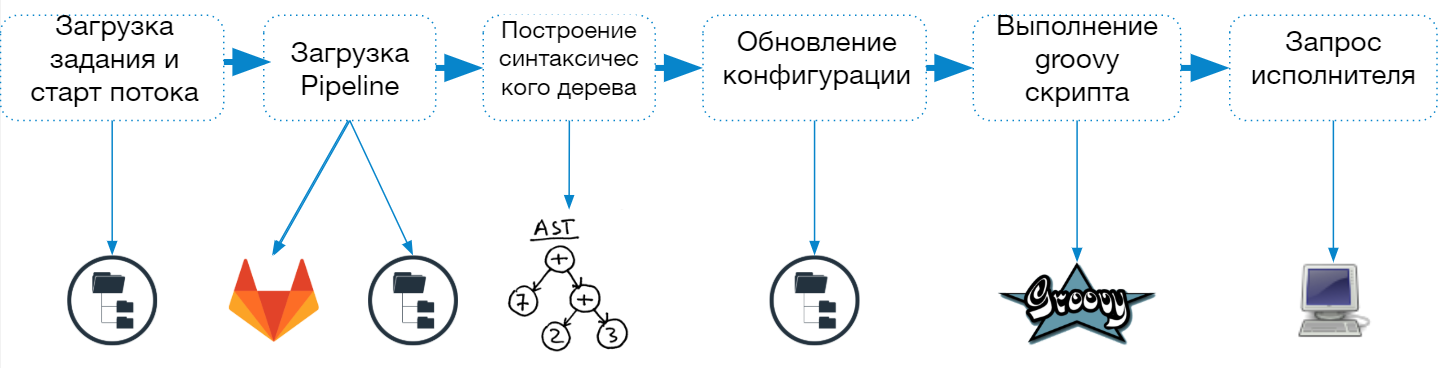
Saat tugas pipeline dimulai, Jenkins membuat thread terpisah dan mengirim tugas ke antrean untuk dieksekusi, dan setelah memuat skrip, ini menentukan agen yang diperlukan untuk menyelesaikan tugas.
Untuk mendukung pendekatan ini, kumpulan utas Jenkins khusus (pelaksana ringan) digunakan. Anda dapat melihat bahwa mereka dijalankan pada master, tetapi tidak mempengaruhi kumpulan eksekutor yang biasa:
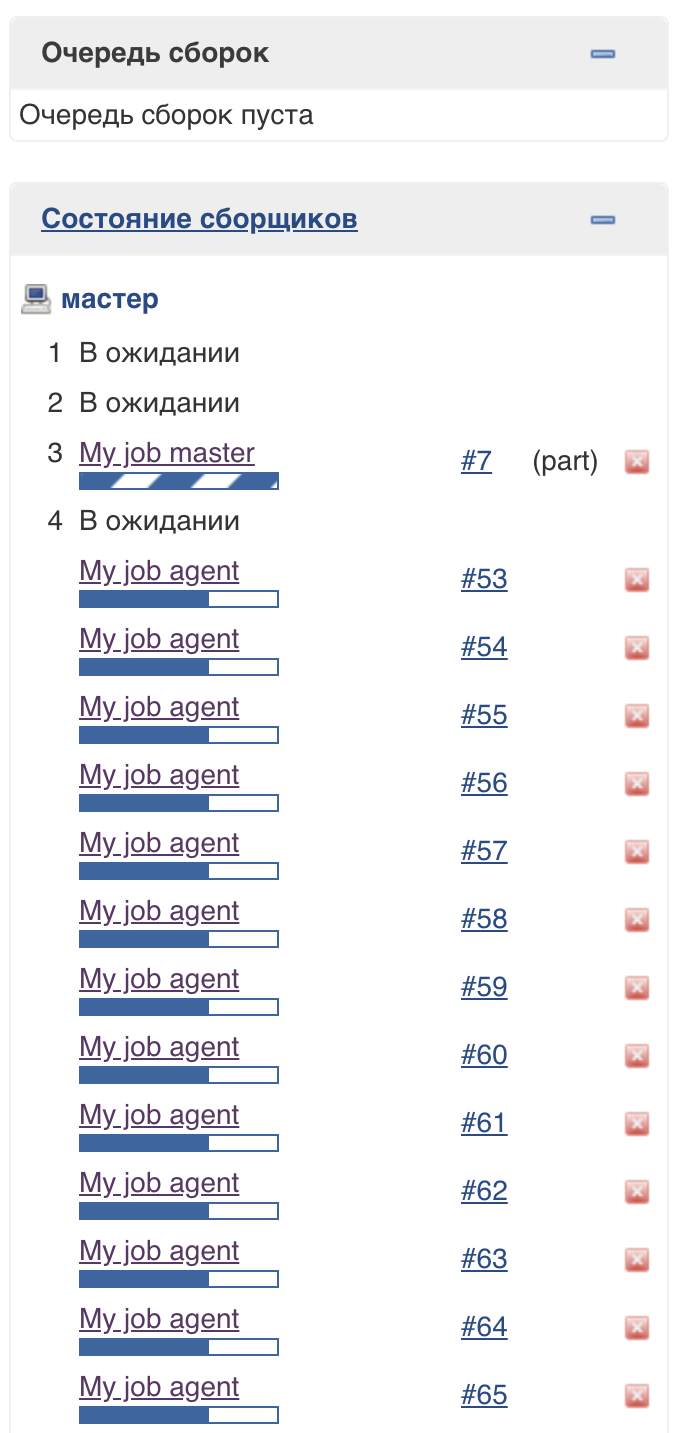
Jumlah utas dalam kumpulan ini tidak terbatas (pada saat penulisan ini).
Parameter kerja di Pipeline. Serta pemicu dan beberapa opsi
Pemrosesan parameter dapat dijelaskan dengan rumus:

Dari parameter pekerjaan yang kita lihat saat startup, parameter Pipeline dari peluncuran sebelumnya dihapus terlebih dahulu, dan baru kemudian parameter yang ditentukan di Pipeline dari peluncuran saat ini ditambahkan. Ini memungkinkan parameter dihapus dari pekerjaan jika dihapus dari Pipeline.
Bagaimana cara kerjanya dari dalam ke luar?
Mari pertimbangkan contoh config.xml (file yang menyimpan konfigurasi pekerjaan):
<?xml version='1.1' encoding='UTF-8'?>
<flow-definition plugin="workflow-job@2.35">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobAction plugin="pipeline-model-definition@1.5.0"/>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="pipeline-model-definition@1.5.0">
<jobProperties>
<string>jenkins.model.BuildDiscarderProperty</string>
</jobProperties>
<triggers/>
<parameters>
<string>parameter_3</string>
</parameters>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties>
<hudson.model.ParametersDefinitionProperty>
<parameterDefinitions>
<hudson.model.StringParameterDefinition>
<name>parameter_1</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_2</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_3</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
</parameterDefinitions>
</hudson.model.ParametersDefinitionProperty>
<jenkins.model.BuildDiscarderProperty>
<strategy class="org.jenkinsci.plugins.BuildRotator.BuildRotator" plugin="buildrotator@1.2">
<daysToKeep>30</daysToKeep>
<numToKeep>10000</numToKeep>
<artifactsDaysToKeep>-1</artifactsDaysToKeep>
<artifactsNumToKeep>-1</artifactsNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
<com.sonyericsson.rebuild.RebuildSettings plugin="rebuild@1.28">
<autoRebuild>false</autoRebuild>
<rebuildDisabled>false</rebuildDisabled>
</com.sonyericsson.rebuild.RebuildSettings>
</properties>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="workflow-cps@2.80">
<scm class="hudson.plugins.filesystem_scm.FSSCM" plugin="filesystem_scm@2.1">
<path>/path/to/jenkinsfile/</path>
<clearWorkspace>true</clearWorkspace>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>
Bagian properti berisi parameter, pemicu, dan opsi yang akan digunakan untuk meluncurkan pekerjaan. Bagian tambahan, DeclarativeJobPropertyTrackerAction, digunakan untuk menyimpan parameter yang disetel hanya di pipeline.
Jika parameter dihapus dari pipeline, ia akan dihapus dari DeclarativeJobPropertyTrackerAction dan dari properti , karena Jenkins akan mengetahui bahwa parameter tersebut hanya ditentukan di pipeline.
Saat menambahkan parameter, situasinya dibalik, parameter akan ditambahkan DeclarativeJobPropertyTrackerAction dan properti , tetapi hanya pada saat eksekusi pipeline.
Itulah mengapa jika Anda menyetel parameter hanya di pipeline, maka parameter tersebuttidak akan tersedia pada peluncuran pertama .
Eksekusi Jenkins Pipeline
Setelah skrip Pipeline diunduh dan dikompilasi, proses eksekusi dimulai. Tetapi proses ini tidak hanya melibatkan melakukan groovy. Saya telah menyoroti operasi kelas berat utama yang dilakukan pada saat eksekusi tugas:
Eksekusi kode Groovy
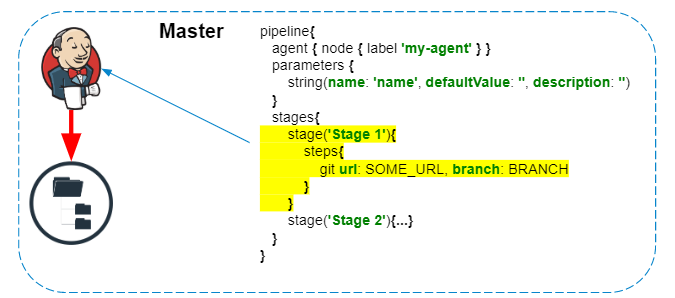
Skrip pipeline selalu dijalankan pada master - kita tidak boleh melupakannya, agar tidak membuat beban yang tidak perlu pada Jenkins. Hanya langkah-langkah yang berinteraksi dengan sistem file agen atau panggilan sistem yang dijalankan pada agen.
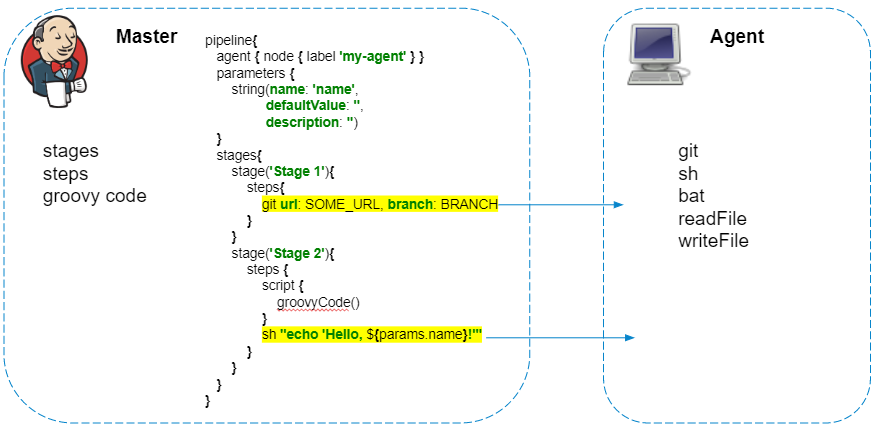
Pipeline memiliki plugin hebat yang memungkinkan Anda membuat permintaan HTTP . Selain itu, jawabannya dapat disimpan ke dalam file.
httpRequest url: 'http://localhost:8080/jenkins/api/json?pretty=true', outputFile: 'result.json'
Awalnya, tampaknya kode ini harus dijalankan sepenuhnya di agen, mengirim permintaan dari agen, dan menyimpan respons ke file result.json. Tapi semuanya terjadi sebaliknya, dan permintaan dijalankan dari Jenkins sendiri, dan untuk menyimpan konten file disalin ke agen. Jika pemrosesan tambahan respons di pipeline tidak diperlukan, maka saya menyarankan Anda untuk mengganti permintaan seperti itu dengan curl:
sh 'curl "http://localhost:8080/jenkins/api/json?pretty=true" -o "result.json"'
Bekerja dengan log dan artefak
Terlepas dari agen tempat perintah dijalankan, log dan artefak diproses dan disimpan ke sistem file master secara real time.
Jika pipeline menggunakan kredensial, maka sebelum menyimpan log juga difilter pada master .
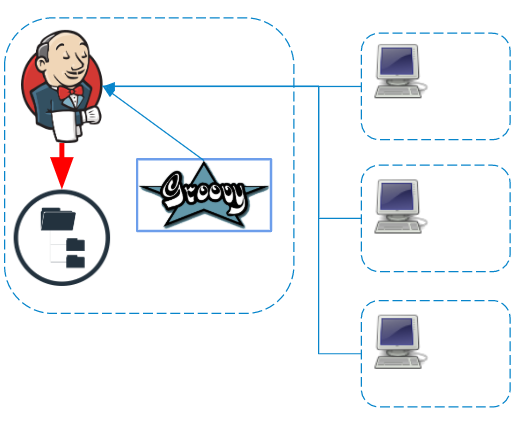
Menyimpan Langkah (Ketahanan Pipa)
Jenkins Pipeline memposisikan dirinya sebagai tugas yang terdiri dari bagian terpisah yang independen dan dapat direproduksi saat master crash. Tetapi Anda harus membayar untuk ini dengan penulisan tambahan ke disk, karena bergantung pada pengaturan tugas, langkah-langkah dengan tingkat detail yang berbeda-beda akan diserialkan dan disimpan ke disk.
Bergantung pada ketahanan pipeline, langkah-langkah dalam grafik pipeline akan disimpan dalam satu atau beberapa file untuk setiap pekerjaan yang dijalankan. Kutipan dari dokumentasi :
Plugin dukungan alur kerja untuk menyimpan langkah-langkah (FlowNode) menggunakan kelas FlowNodeStorage dan implementasi SimpleXStreamFlowNodeStorage dan BulkFlowNodeStorage.
- FlowNodeStorage menggunakan cache dalam memori untuk menggabungkan penulisan disk. Buffer secara otomatis ditulis pada saat runtime. Anda biasanya tidak perlu mengkhawatirkan hal ini, tetapi perlu diingat bahwa menyimpan FlowNode tidak menjamin bahwa itu akan segera ditulis ke disk.
- SimpleXStreamFlowNodeStorage menggunakan satu file XML kecil untuk setiap FlowNode - meskipun kami menggunakan cache dalam memori referensi lunak untuk node, ini menghasilkan kinerja yang jauh lebih buruk saat pertama kali melintasi FlowNodes.
- BulkFlowNodeStorage menggunakan satu file XML yang lebih besar dengan semua FlowNodes di dalamnya. Kelas ini digunakan dalam mode aktif PERFORMANCE_OPTIMIZED, yang menulis lebih jarang. Ini umumnya jauh lebih efisien karena satu rekaman streaming besar lebih cepat daripada sekumpulan rekaman kecil dan meminimalkan beban pada OS untuk mengelola semua file kecil.
Asli
Storage: in the workflow-support plugin, see the 'FlowNodeStorage' class and the SimpleXStreamFlowNodeStorage and BulkFlowNodeStorage implementations.
- FlowNodeStorage uses in-memory caching to consolidate disk writes. Automatic flushing is implemented at execution time. Generally, you won't need to worry about this, but be aware that saving a FlowNode does not guarantee it is immediately persisted to disk.
- The SimpleXStreamFlowNodeStorage uses a single small XML file for every FlowNode — although we use a soft-reference in-memory cache for the nodes, this generates much worse performance the first time we iterate through the FlowNodes (or when)
- The BulkFlowNodeStorage uses a single larger XML file with all the FlowNodes in it. This is used in the PERFORMANCE_OPTIMIZED durability mode, which writes much less often. It is generally much more efficient because a single large streaming write is faster than a bunch of small writes, and it minimizes the system load of managing all the tiny files.
Langkah-langkah yang disimpan dapat ditemukan di direktori:
$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_ID/workflow/
File contoh:
<?xml version='1.1' encoding='UTF-8'?>
<Tag plugin="workflow-support@3.5">
<node class="cps.n.StepStartNode" plugin="workflow-cps@2.82">
<parentIds>
<string>4</string>
</parentIds>
<id>5</id>
<descriptorId>org.jenkinsci.plugins.workflow.support.steps.StageStep</descriptorId>
</node>
<actions>
<s.a.LogStorageAction/>
<cps.a.ArgumentsActionImpl plugin="workflow-cps@2.82">
<arguments>
<entry>
<string>name</string>
<string>Declarative: Checkout SCM</string>
</entry>
</arguments>
<isUnmodifiedBySanitization>true</isUnmodifiedBySanitization>
</cps.a.ArgumentsActionImpl>
<wf.a.TimingAction plugin="workflow-api@2.40">
<startTime>1600855071994</startTime>
</wf.a.TimingAction>
</actions>
</Tag>
Hasil
Saya harap materi ini menarik dan membantu untuk lebih memahami apa itu pipeline dan bagaimana cara kerjanya dari dalam. Jika Anda masih memiliki pertanyaan - bagikan di bawah ini, saya akan dengan senang hati menjawabnya!
Di bagian kedua artikel, saya akan mempertimbangkan kasus terpisah yang akan membantu Anda menemukan masalah dengan Jenkins Pipeline dan mempercepat tugas Anda. Kami akan mempelajari cara menyelesaikan masalah peluncuran bersamaan, melihat opsi survivabilitas, dan membahas mengapa Jenkins harus diprofilkan.