
Baru-baru ini, perusahaan besar Rusia semakin mencari solusi penyimpanan yang terjangkau. DBMS open source menjadi pesaing Oracle, SAP HANA, Sybase, Informix: PostgreSQL, MySQL, MariaDB, dll. Raksasa Barat - Alibaba, Instagram, Skype - telah lama menggunakannya dalam lanskap IT mereka.
Dalam proyek untuk Persatuan Perusahaan Asuransi Mobil (RSA) Rusia, di mana Jet Infosystems membangun infrastruktur TI untuk AIS OSAGO baru, para pengembang menggunakan DBMS PostgreSQL. Dan kami memikirkan tentang cara memastikan ketersediaan database maksimum dan kehilangan data minimum jika terjadi kegagalan perangkat keras. Dan deskripsi solusi "di atas kertas" ini tampaknya sesederhana 2 + 2, pada kenyataannya, tim kami harus bekerja keras untuk mencapai toleransi kesalahan.
Ada beberapa alat Pengelompokan Failover untuk PostgreSQL. Ini adalah Stolon, Patroni, Repmgr, Pacemaker + Corosync, dll.
Kami memilih Patroni karena proyek ini sedang berkembang secara aktif, tidak seperti proyek serupa, memiliki dokumentasi yang jelas dan semakin menjadi pilihan administrator database.
Komposisi "set sup"
Patroni adalah sekumpulan skrip python untuk mengotomatiskan peralihan peran utama server database PostgreSQL ke replika. Itu juga dapat menyimpan, memodifikasi dan menerapkan parameter DBMS PostgreSQL itu sendiri. Ternyata file konfigurasi PostgreSQL tidak perlu diperbarui di setiap server secara terpisah.
PostgreSQL adalah database relasional open source. Ini telah membuktikan dirinya dalam proses analitis yang besar dan kompleks.
Keepalived - dalam konfigurasi multi-node, ini digunakan untuk mengaktifkan alamat IP khusus di node cluster paling mana peran node PostgreSQL utama saat ini digunakan. Alamat IP berfungsi sebagai titik masuk untuk aplikasi dan pengguna.
DCS adalah penyimpanan konfigurasi terdistribusi. Patroni menggunakannya untuk menyimpan informasi tentang komposisi cluster, peran server cluster, serta menyimpan parameter konfigurasi PostgreSQL-nya sendiri. Artikel ini akan fokus pada etcd.
Bereksperimen dengan nuansa
Untuk mencari solusi toleransi kesalahan yang optimal dan untuk menguji hipotesis kami tentang pengoperasian opsi yang berbeda, kami membuat beberapa bangku uji. Awalnya, kami mempertimbangkan solusi yang berbeda dari arsitektur target: misalnya, kami menggunakan Haproxy karena node utama PostgreSQL atau DCS terletak di server yang sama dengan PostgreSQL. Kami mengorganisir hackathon internal, mempelajari bagaimana Patroni akan berperilaku jika terjadi kegagalan komponen server, tidak tersedianya jaringan, sistem file overflow, dll. Artinya, mereka mengerjakan berbagai skenario kegagalan. Sebagai hasil dari "studi ilmiah" ini, arsitektur akhir dari solusi toleransi kesalahan dibentuk.
Hidangan IT Gourmet
Ada peran server di PostgreSQL: primer - sebuah instance dengan kemampuan untuk menulis / membaca data; replika - instance hanya-baca, terus-menerus disinkronkan dengan primer. Peran ini statis saat PostgreSQL berjalan, dan jika server dengan peran utama gagal, DBA harus secara manual meningkatkan peran replika ke utama.
Patroni membuat cluster failover, yaitu menggabungkan server dengan peran utama dan replika. Ada perubahan peran otomatis di antara mereka jika terjadi kegagalan.

Ilustrasi di atas menunjukkan bagaimana server aplikasi terhubung ke salah satu server di cluster Patroni. Konfigurasi ini menggunakan satu node utama dan dua replika, salah satunya sinkron. Dengan replikasi sinkronis, PostgreSQL bekerja sedemikian rupa sehingga yang utama selalu menunggu perubahan untuk ditulis ke replika. Jika replika sinkron tidak tersedia, replika primer tidak akan menulis perubahan ke replika itu sendiri, melainkan hanya-baca. Ini adalah arsitektur PostgreSQL. Untuk "mengubah sifatnya", replika kedua digunakan - asinkron (jika replikasi sinkronis tidak diperlukan, Anda dapat membatasi diri Anda pada satu replika).
Saat menggunakan dua atau lebih replika dan mengaktifkan replikasi sinkronis, Patroni selalu membuat hanya satu replika sinkron. Jika simpul utama gagal, Patroni menaikkan level replika sinkron.
Ilustrasi berikut menunjukkan fungsionalitas Patroni tambahan yang penting dalam solusi perusahaan industri - replikasi data ke situs cadangan.
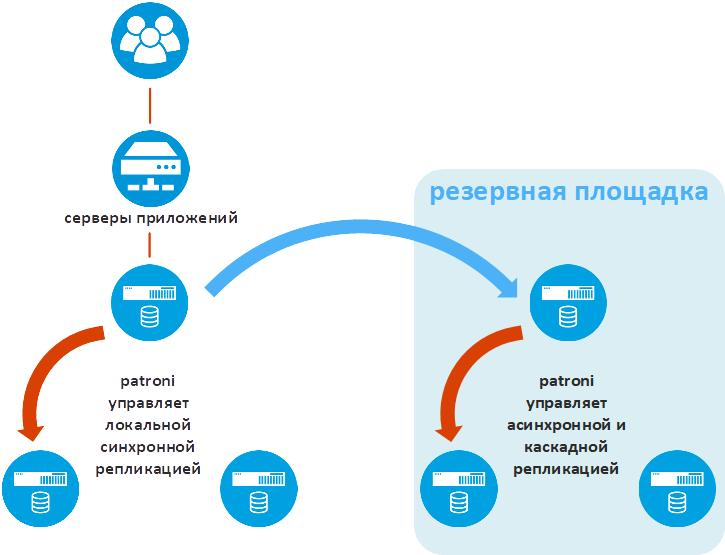
Patroni menyebut fungsi ini standby_cluster. Ini memungkinkan cluster Ratroni untuk digunakan di situs jarak jauh sebagai replika asinkron. Jika situs utama hilang, cluster cadangan Patroni akan mulai bekerja seolah-olah itu adalah situs utama.
Salah satu node dari cluster situs cadangan disebut Standby Leader. Ini adalah replika asinkron dari node utama dari situs utama. Dua node yang tersisa dari cluster situs cadangan menerima data dari Standby Leader. Ini adalah bagaimana replikasi bertingkat diimplementasikan, yang mengurangi volume lalu lintas antar situs teknologi.
Komposisi aplikasi cluster Patroni
Setelah diluncurkan, Patroni membuat port TCP terpisah. Setelah membuat permintaan HTTP ke port ini, Anda dapat memahami node cluster mana yang utama dan mana yang merupakan replika.

Di keepalived, kami telah menetapkan skrip kecil buatan sendiri sebagai objek pemantauan yang memeriksa port TCP Patroni. Skrip mengharapkan respons HTTP GET 200. Node cluster yang merespons adalah node Primer, di mana keepalived memulai alamat IP yang didedikasikan untuk terhubung ke cluster.
Jika Anda mengonfigurasi instance keepalived kedua untuk menunggu respons HTTP GET 200 dari replika sinkron, keepalived di node cluster yang sama akan meluncurkan alamat IP khusus lainnya. Alamat ini dapat digunakan oleh aplikasi untuk membaca data dari database. Opsi ini berguna, misalnya untuk menyiapkan laporan.
Karena Patroni adalah sekumpulan skrip, instance-nya pada setiap node tidak "berkomunikasi" secara langsung satu sama lain, tetapi menggunakan penyimpanan konfigurasi untuk ini. Kami menggunakan etcd sebagai itu, yang merupakan kuorum untuk Patroni itu sendiri - node utama saat ini secara konstan memperbarui kunci dalam penyimpanan etcd, menunjukkan bahwa itu adalah yang terdepan. Node cluster lainnya terus membaca kunci ini dan "memahami" bahwa mereka adalah replika. Layanan etcd terletak di server khusus dalam jumlah 3 atau 5. Sinkronisasi data dalam penyimpanan etcd antara server ini dilakukan dengan menggunakan layanan etcd itu sendiri.
Dalam percobaan kami, kami menemukan bahwa layanan etcd perlu dipindahkan ke server terpisah. Pertama, etcd sangat sensitif terhadap latensi jaringan dan respons subsistem disk, dan server khusus tidak akan dimuat. Kedua, dengan kemungkinan pemisahan jaringan dari node cluster Patroni, "pemisahan otak" dapat terjadi - dua node utama akan muncul, yang tidak akan tahu apa-apa tentang satu sama lain, karena cluster etcd juga akan "hancur".
Cek praktek
Pada skala proyek untuk membangun infrastruktur TI untuk AIS OSAGO, mencapai toleransi kesalahan PostgreSQL adalah salah satu tugas untuk "menanamkan" DBMS terbuka ke dalam lanskap TI perusahaan. Di sampingnya adalah masalah terkait integrasi cluster PostgreSQL dengan sistem cadangan, pemantauan infrastruktur dan keamanan informasi, keamanan data yang andal di situs cadangan. Masing-masing petunjuk arah ini memiliki kesulitan dan cara untuk melewatinya. Kami telah menulis tentang salah satunya - kami berbicara tentang pencadangan PostgreSQL menggunakan solusi perusahaan .

Arsitektur PostgreSQL yang toleran terhadap kesalahan, dipikirkan dan diuji di stand kami, telah membuktikan keefektifannya dalam praktik. Solusinya siap untuk "mentransfer" berbagai kegagalan sistem dan logika. Sekarang ini berjalan pada 10 cluster Patroni yang sangat dimuat dan tahan terhadap pemrosesan PostgreSQL yang memuat ratusan gigabyte data per jam.
Penulis: Dmitry Erykin, dan insinyur-perancang sistem komputasi Jet Infosystems