Selama sekitar satu tahun sekarang, divisi infrastruktur kami telah memigrasikan semua layanan yang berjalan di GitLab.com ke Kubernetes. Selama ini, kami menghadapi masalah tidak hanya dengan pemindahan layanan ke Kubernetes, tetapi juga dengan pengelolaan penerapan hybrid selama transisi. Pelajaran berharga yang telah kita pelajari akan dibahas dalam artikel ini.
Sejak awal GitLab.com, servernya berjalan di cloud pada mesin virtual. Mesin virtual ini dikelola oleh Chef dan diinstal menggunakan paket Linux resmi kami . Strategi penerapan jika aplikasi perlu diperbarui adalah dengan memperbarui armada server secara berurutan terkoordinasi menggunakan pipeline CI. Metode ini - meskipun lambat dan sedikit membosankan - memastikan bahwa GitLab.com menggunakan metode instalasi dan konfigurasi yang sama dengan pengguna instalasi GitLab yang dikelola sendiri menggunakan paket Linux kami.
Kami menggunakan metode ini karena sangat penting untuk mengalami semua kesedihan dan kegembiraan yang dialami anggota komunitas biasa saat menginstal dan mengkonfigurasi salinan GitLab mereka. Pendekatan ini bekerja dengan baik untuk beberapa waktu, tetapi karena jumlah proyek di GitLab melebihi 10 juta, kami menyadari bahwa itu tidak lagi memenuhi kebutuhan penskalaan dan penerapan kami.
Langkah pertama menuju Kubernetes dan GitLab cloud-native
Pada tahun 2017, proyek GitLab Charts dibuat untuk mempersiapkan GitLab untuk penerapan di cloud, serta memungkinkan pengguna untuk menginstal GitLab di cluster Kubernetes. Kami tahu bahwa memindahkan GitLab ke Kubernetes akan meningkatkan skalabilitas platform SaaS, menyederhanakan penerapan, dan meningkatkan efisiensi komputasi. Pada saat yang sama, banyak fitur aplikasi kita bergantung pada partisi NFS yang terpasang, yang memperlambat transisi dari mesin virtual.
Mengejar cloud native dan Kubernetes memungkinkan teknisi kami merencanakan transisi bertahap, yang selama itu kami membuang beberapa dependensi NAS aplikasi, sambil terus mengembangkan fitur-fitur baru. Sejak kami mulai merencanakan migrasi pada musim panas 2019, banyak dari batasan ini telah dihapus, dan proses migrasi GitLab.com ke Kubernetes sekarang berjalan lancar!
Fitur karya GitLab.com di Kubernetes
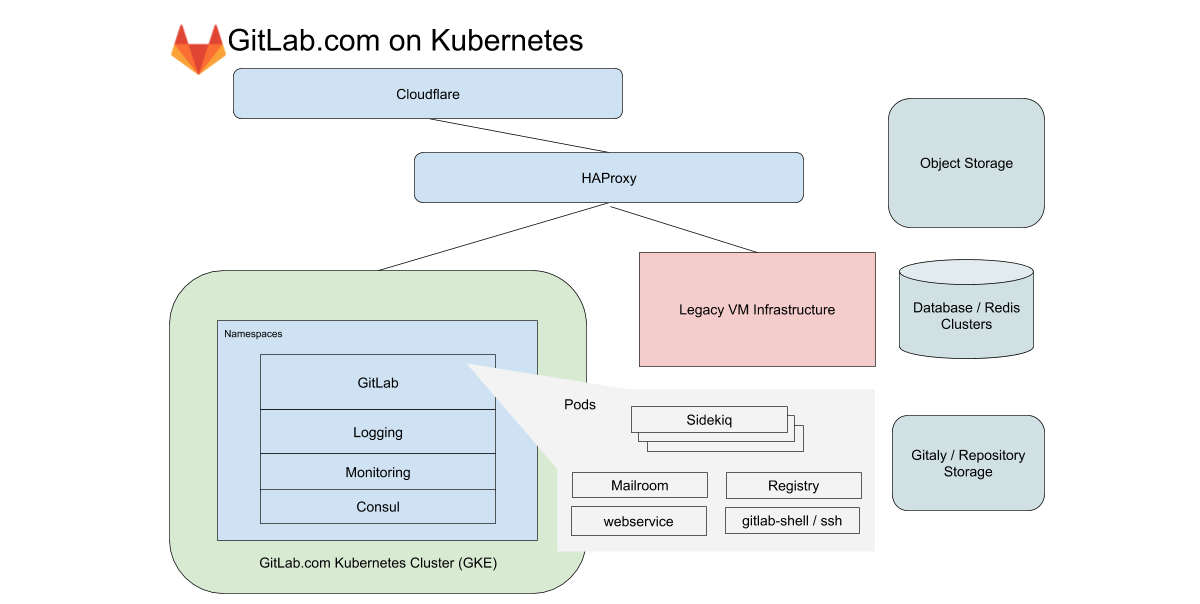
Untuk GitLab.com, kami menggunakan cluster GKE regional tunggal yang menangani semua lalu lintas aplikasi. Untuk meminimalkan kerumitan migrasi (yang sudah rumit), kami fokus pada layanan yang tidak bergantung pada penyimpanan lokal atau NFS. GitLab.com menggunakan basis kode Rails yang didominasi monolitik, dan kami merutekan lalu lintas berdasarkan karakteristik beban kerja ke berbagai titik akhir, yang diisolasi ke dalam kumpulan node kami sendiri.
Dalam kasus frontend, jenis ini dibagi menjadi permintaan ke web, API, Git SSH / HTTPS, dan Registry. Dalam kasus backend, kami mengantrekan pekerjaan sesuai dengan karakteristik yang berbeda bergantung pada batas sumber daya yang telah ditentukan sebelumnya yang memungkinkan kami menetapkan Sasaran Tingkat Layanan (SLO) untuk beban kerja yang berbeda.
Semua layanan GitLab.com ini dikonfigurasi menggunakan bagan Helm GitLab yang tidak dimodifikasi. Konfigurasi dilakukan dalam subchart, yang dapat diaktifkan secara selektif saat kami secara bertahap memigrasi layanan ke cluster. Meskipun diputuskan untuk tidak menyertakan beberapa layanan stateful kami seperti Redis, Postgres, GitLab Pages, dan Gitaly dalam migrasi, Kubernetes secara drastis mengurangi jumlah VM yang dikelola Chef saat ini.
Transparansi Kubernetes dan manajemen konfigurasi
Semua pengaturan dikontrol oleh GitLab itu sendiri. Untuk ini, tiga proyek konfigurasi berdasarkan Terraform dan Helm digunakan. Kami mencoba menggunakan GitLab itu sendiri jika memungkinkan untuk menjalankan GitLab, tetapi untuk tugas operasional kami memiliki instalasi GitLab yang terpisah. Ini harus independen dari ketersediaan GitLab.com untuk penerapan dan pembaruan GitLab.com.
Meskipun pipeline kami untuk cluster Kubernetes berjalan pada penginstalan GitLab terpisah, repo kode memiliki mirror yang tersedia untuk umum di alamat berikut:
- k8s-workloads / gitlab-com - konfigurasi GitLab.com yang mengikat untuk bagan Helm GitLab;
- k8s-workloads/gitlab-helmfiles — , GitLab . , PlantUML;
- Gitlab-com-infrastructure — Terraform Kubernetes (legacy) VM-. , , , , , IP-.

Saat perubahan dilakukan, ringkasan singkat yang tersedia untuk umum ditampilkan dengan link ke diff rinci, yang diurai SRE sebelum membuat perubahan pada cluster.
Untuk SRE, tautan menunjuk ke perbedaan rinci dalam instalasi GitLab yang digunakan untuk produksi dan aksesnya terbatas. Hal ini memungkinkan karyawan dan komunitas tanpa akses ke proyek operasional (hanya terbuka untuk SRE) untuk melihat perubahan konfigurasi yang diusulkan. Dengan menggabungkan instance publik GitLab untuk kode dengan instance privat untuk pipeline CI, kami mempertahankan alur kerja tunggal sambil memastikan independensi dari GitLab.com untuk pembaruan konfigurasi.
Apa yang kami temukan selama migrasi
Selama pemindahan, kami memperoleh pengalaman yang kami terapkan pada migrasi dan penerapan baru di Kubernetes.
1. -

Statistik keluar harian (byte per hari) untuk taman repositori Git di GitLab.com
Google membagi jaringannya menjadi beberapa wilayah. Mereka, pada gilirannya, dibagi menjadi zona ketersediaan (AZ). Git hosting dikaitkan dengan sejumlah besar data, jadi penting bagi kami untuk mengontrol jalan keluar jaringan. Untuk lalu lintas internal, keluar gratis hanya jika tetap dalam AZ yang sama. Pada saat penulisan ini, kami melayani sekitar 100 TB data pada hari kerja biasa (dan itu hanya untuk repositori Git). Layanan yang, dalam topologi berbasis VM lama kami, berada di mesin virtual yang sama, sekarang berjalan di pod Kubernetes yang berbeda. Ini berarti bahwa beberapa lalu lintas yang sebelumnya bersifat lokal ke VM berpotensi keluar dari Availability Zone.
Kluster GKE regional memungkinkan Anda menjangkau beberapa Availability Zone untuk redundansi. Kami sedang mempertimbangkan untuk membagi cluster GKE regional menjadi cluster zona tunggal untuk layanan yang menghasilkan lalu lintas volume besar. Ini akan mengurangi biaya jalan keluar sambil mempertahankan redundansi cluster.
2. Batasan, permintaan sumber daya, dan penskalaan

Jumlah lalu lintas produksi pemrosesan replika di registry.gitlab.com. Puncak lalu lintas pada ~ 15:00 UTC.
Kisah migrasi kami dimulai pada Agustus 2019, saat kami memindahkan layanan pertama kami, GitLab Container Registry, ke Kubernetes. Layanan misi-kritis dengan lalu lintas tinggi ini sangat sesuai untuk migrasi pertama karena ini adalah aplikasi tanpa negara dengan sedikit ketergantungan eksternal. Masalah pertama yang kami temui adalah banyaknya jumlah preempted pod karena memori pada node tidak cukup. Karena itu, kami harus mengubah permintaan dan batasan.
Ditemukan bahwa dalam kasus aplikasi di mana konsumsi memori meningkat seiring waktu, nilai rendah untuk request'ov (untuk setiap memory pod'a redundan) ditambah dengan "royal" rigid limit'om untuk digunakan menyebabkan unit saturasi (saturasi) dan tingkat perpindahan yang tinggi. Untuk mengatasi masalah ini, diputuskan untuk meningkatkan permintaan dan menurunkan batas . Ini mengambil tekanan dari node dan memastikan siklus hidup pod yang tidak memberikan terlalu banyak tekanan pada node. Kami sekarang memulai migrasi dengan permintaan yang murah hati (dan hampir identik) dan nilai batas, menyesuaikannya sesuai kebutuhan.
3. Metrik dan log

Infrastruktur berfokus pada latensi, tingkat kesalahan, dan saturasi dengan tujuan tingkat layanan (SLO) yang ditetapkan terkait dengan ketersediaan keseluruhan sistem kami .
Selama setahun terakhir, salah satu perkembangan utama di divisi infrastruktur adalah peningkatan dalam pemantauan dan kerja sama dengan SLO. SLO memungkinkan kami menetapkan tujuan untuk layanan individu, yang kami pantau dengan cermat selama migrasi. Tetapi bahkan dengan observabilitas yang lebih baik, tidak selalu mungkin untuk segera melihat masalah menggunakan metrik dan peringatan. Misalnya, dengan berfokus pada latensi dan tingkat kesalahan, kami tidak sepenuhnya mencakup semua kasus penggunaan untuk layanan yang menjalani migrasi.
Masalah ini ditemukan segera setelah memindahkan beberapa beban kerja ke cluster. Ini menjadi sangat akut ketika diperlukan untuk memeriksa fungsi, yang jumlah permintaannya kecil, tetapi memiliki dependensi konfigurasi yang sangat spesifik. Salah satu pelajaran utama dari hasil migrasi adalah perlunya memperhitungkan saat memantau tidak hanya metrik, tetapi juga log dan "long tail" (kita berbicara tentang distribusinya pada grafik - kira-kira. Terjemahan) . Sekarang, untuk setiap migrasi, kami menyertakan daftar mendetail dari kueri log dan merencanakan prosedur rollback yang jelas yang dapat diteruskan dari satu shift ke shift lainnya jika terjadi masalah.
Melayani permintaan yang sama secara paralel pada infrastruktur VM lama dan yang baru berdasarkan Kubernetes merupakan tantangan yang unik. Tidak seperti migrasi lift-and-shift (transfer cepat aplikasi "sebagaimana adanya" ke infrastruktur baru; Anda dapat membaca lebih lanjut, misalnya, di sini - kira-kira. Terjemahan) , pekerjaan paralel pada VM "lama" dan Kubernetes memerlukan alat untuk sistem pemantauan kompatibel dengan kedua lingkungan dan mampu menggabungkan metrik menjadi satu tampilan. Penting bagi kami untuk menggunakan dasbor dan kueri log yang sama untuk mencapai observasi yang konsisten selama transisi.
4. Mengalihkan lalu lintas ke cluster baru
Untuk GitLab.com, beberapa server dialokasikan untuk canary stage . Canary Park melayani proyek in-house kami dan juga dapat diaktifkan oleh pengguna . Tapi yang pertama dan terpenting, ini dimaksudkan untuk memvalidasi perubahan yang dilakukan pada infrastruktur dan aplikasi. Layanan pertama yang dimigrasi dimulai dengan menerima lalu lintas internal dalam jumlah terbatas, dan kami terus menggunakan metode ini untuk memastikan bahwa SLO terpenuhi sebelum meneruskan semua lalu lintas ke cluster.
Dalam kasus migrasi, ini berarti bahwa permintaan pertama untuk proyek internal dikirim ke Kubernetes, lalu kami secara bertahap mengalihkan sisa lalu lintas ke kluster dengan mengubah bobot untuk backend melalui HAProxy. Dalam proses perpindahan dari VM ke Kubernetes, menjadi jelas bahwa sangat bermanfaat memiliki cara sederhana untuk mengarahkan lalu lintas antara infrastruktur lama dan baru dan, oleh karena itu, menjaga infrastruktur lama tetap siap untuk rollback dalam beberapa hari pertama setelah migrasi.
5. Cadangan daya buah dan penggunaannya
Hampir seketika, masalah berikut teridentifikasi: pod untuk layanan Registri dimulai dengan cepat, tetapi peluncuran pod untuk Sidekiq membutuhkan waktu hingga dua menit . Pod yang berjalan lama untuk Sidekiq menjadi masalah saat kami mulai memigrasi beban kerja ke Kubernetes untuk pekerja yang perlu memproses pekerjaan dengan cepat dan menskalakan dengan cepat.
Dalam kasus ini, pelajarannya adalah bahwa meskipun Horizontal Pod Autoscaler (HPA) di Kubernetes menangani pertumbuhan traffic dengan baik, penting untuk mempertimbangkan karakteristik beban kerja dan mengalokasikan kapasitas pod cadangan (terutama dalam kondisi distribusi permintaan yang tidak merata). Dalam kasus kami, ada lonjakan tiba-tiba dalam pekerjaan, yang memerlukan penskalaan cepat, yang menyebabkan kejenuhan sumber daya CPU sebelum kami sempat menskalakan kumpulan node.
Selalu ada godaan untuk memeras sebanyak mungkin dari cluster, namun, kami, awalnya dihadapkan pada masalah performa, sekarang mulai dengan anggaran pod yang besar dan kemudian turunkan skalanya, dengan tetap memperhatikan SLO. Peluncuran pod untuk layanan Sidekiq telah dipercepat secara signifikan dan sekarang rata-rata membutuhkan waktu sekitar 40 detik.Baik GitLab.com dan pengguna penginstalan mandiri kami yang bekerja dengan bagan Helm GitLab resmi telah mendapatkan keuntungan dari pengurangan waktu peluncuran pod .
Kesimpulan
Setelah memigrasi setiap layanan, kami menikmati keuntungan menggunakan Kubernetes dalam produksi: penerapan aplikasi yang lebih cepat dan lebih aman, penskalaan, dan alokasi sumber daya yang lebih efisien. Selain itu, keuntungan migrasi melampaui layanan GitLab.com. Setiap peningkatan pada bagan Helm resmi juga menguntungkan penggunanya.
Saya harap Anda menikmati kisah petualangan migrasi Kubernetes kami. Kami terus memigrasi semua layanan baru ke cluster. Informasi tambahan dapat diperoleh dari publikasi berikut:
- « Mengapa kami bermigrasi ke Kubernetes <br>? ";
- " GitLab.com di Kubernetes ";
- Epik tentang Migrasi GitLab.com ke Kubernetes .
PS dari penerjemah
Baca juga di blog kami: