
Sejak penemuan GPU pertamanya pada tahun 1999, NVIDIA telah menjadi yang terdepan dalam grafik 3D dan komputasi yang dipercepat GPU. Setiap arsitektur NVIDIA dirancang dengan cermat untuk memberikan tingkat kinerja dan efisiensi yang revolusioner.
A100, GPU pertama dengan arsitektur NVIDIA Ampere, dirilis pada Mei 2020. Ini memberikan akselerasi luar biasa untuk pelatihan AI, HPC, dan analitik data. A100 didasarkan pada chip GA100, yang murni bersifat komputasi dan, tidak seperti GA102, belum bermain game.
GPU GA10x didasarkan pada arsitektur NVIDIA Turing GPU. Turing adalah arsitektur pertama di dunia yang menawarkan pelacakan sinar real-time berperforma tinggi, grafis yang dipercepat AI, dan rendering grafis profesional, semuanya dalam satu perangkat.
Pada artikel ini, kami akan menganalisis perubahan utama dalam arsitektur kartu video NVIDIA baru dibandingkan dengan pendahulunya.

Gambar 1. Arsitektur Ampere GA10x
Fitur utama GA102
GA102 diproduksi menggunakan teknologi 8nm kepemilikan NVIDIA - 8N NVIDIA Custom. Chip tersebut berisi 28,3 miliar transistor pada die 628,4 mm2. Seperti semua GeForce RTX, GA102 didasarkan pada prosesor yang berisi tiga jenis sumber daya komputasi:
- Kernel CUDA untuk bayangan yang dapat diprogram;
- RT-, (BVH) ;
- , .
Ampere
GPC, TPC SM
Seperti pendahulunya, GA102 terdiri dari Graphics Processing Clusters (GPCs), Texture Processing Clusters (TPCs), Streaming Multiprocessors (SM), Raster Operator ROPs (ROPs), dan pengontrol memori. Chip lengkap memiliki tujuh unit GPC, 42 TPC, dan 84 SM.
GPC adalah blok level tinggi yang dominan yang berisi semua grafik utama. Setiap GPC memiliki Mesin Raster khusus dan sekarang juga memiliki dua bagian ROP yang masing-masing terdiri dari delapan blok, yang merupakan inovasi dalam arsitektur Ampere. Selain itu, GPC berisi enam TPC, masing-masing berisi dua multiprosesor dan satu PolyMorph Engine.
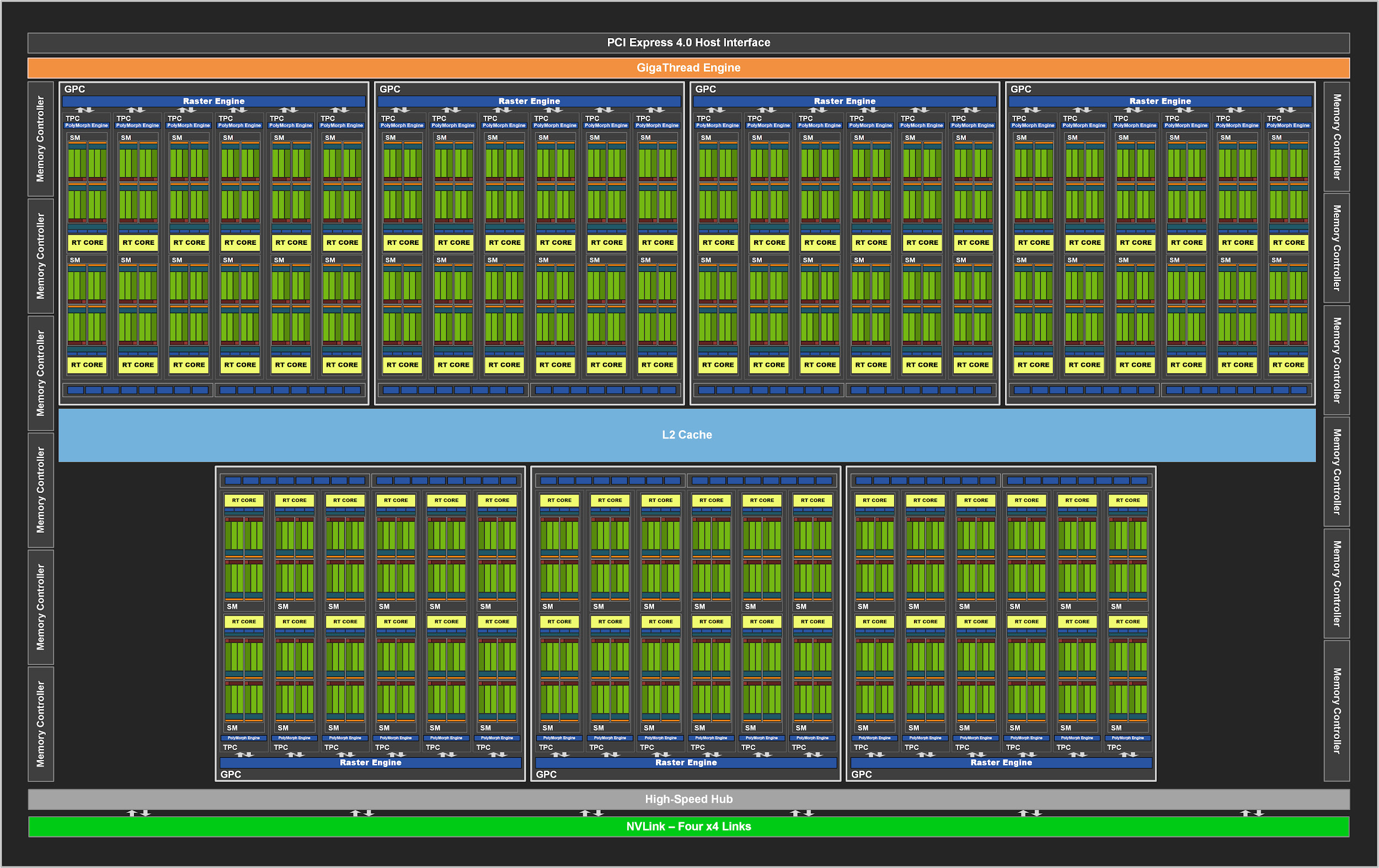
Gambar 2. Lengkap GPU GA102 dengan 84 blok SM
Pada gilirannya, setiap SM di GA10x berisi 128 inti CUDA, empat inti Tensor generasi ketiga, file register 256 KB, empat unit tekstur, satu inti penelusuran sinar dari generasi kedua dan 128 KB L1 / memori bersama, yang dapat dikonfigurasi untuk kapasitas yang berbeda. tergantung pada kebutuhan tugas komputasi atau grafik.
Optimasi ROP
Di GPU NVIDIA sebelumnya, ROP diikat ke pengontrol memori dan cache L2. Dimulai dengan GA10x, keduanya adalah bagian dari GPC, yang meningkatkan kinerja operasi raster dengan meningkatkan jumlah total ROP.
Secara total, dengan tujuh GPC dan 16 ROP di setiap GPC, GPU GA102 terdiri dari 112 ROP, bukan 96, misalnya, di TU102. Ini semua memiliki efek positif pada multisample anti-aliasing, pixel fill rate, dan blending.
NVLink generasi ketiga
GPU GA102 mendukung antarmuka NVIDIA NVLink generasi ketiga, yang mencakup empat jalur x4, masing-masing menyediakan bandwidth 14,0625 GB / dtk antara dua GPU di kedua arah. Keempat saluran bersama-sama memberikan 56,25 GB / dtk bandwidth di setiap arah dan total 112,5 GB / dtk antara dua GPU. Jadi, dengan menggunakan NVLink, dua GPU RTX 3090 dapat dihubungkan.
PCIe Gen 4
GPU GA10x dilengkapi dengan PCI Express 4.0, yang menawarkan dua kali lipat bandwidth PCIe 3.0, kecepatan transfer hingga 16GTransfers per detik, dan berkat slot x16 PCIe 4.0, bandwidth puncak mencapai 64GB / s.
Arsitektur Multiprosesor GA10x
Arsitektur multiprosesor Turing adalah yang pertama di NVIDIA yang memiliki inti terpisah untuk mempercepat operasi penelusuran sinar. Kemudian Volta memperkenalkan kernel tensor pertama, dan Turing memperkenalkan kernel tensor generasi kedua yang canggih. Inovasi lain di Turing dan Volta adalah kemampuan untuk menjalankan operasi FP32 dan INT32 secara bersamaan. Multiprosesor di GA10x mendukung semua fitur di atas, dan juga memiliki sejumlah peningkatannya sendiri.
Berbeda dengan TU102, yang memiliki delapan inti tensor generasi kedua, multiprosesor GA10x memiliki empat inti tensor generasi ketiga, dengan masing-masing inti tensor GA10x dua kali lebih kuat dari Turing.
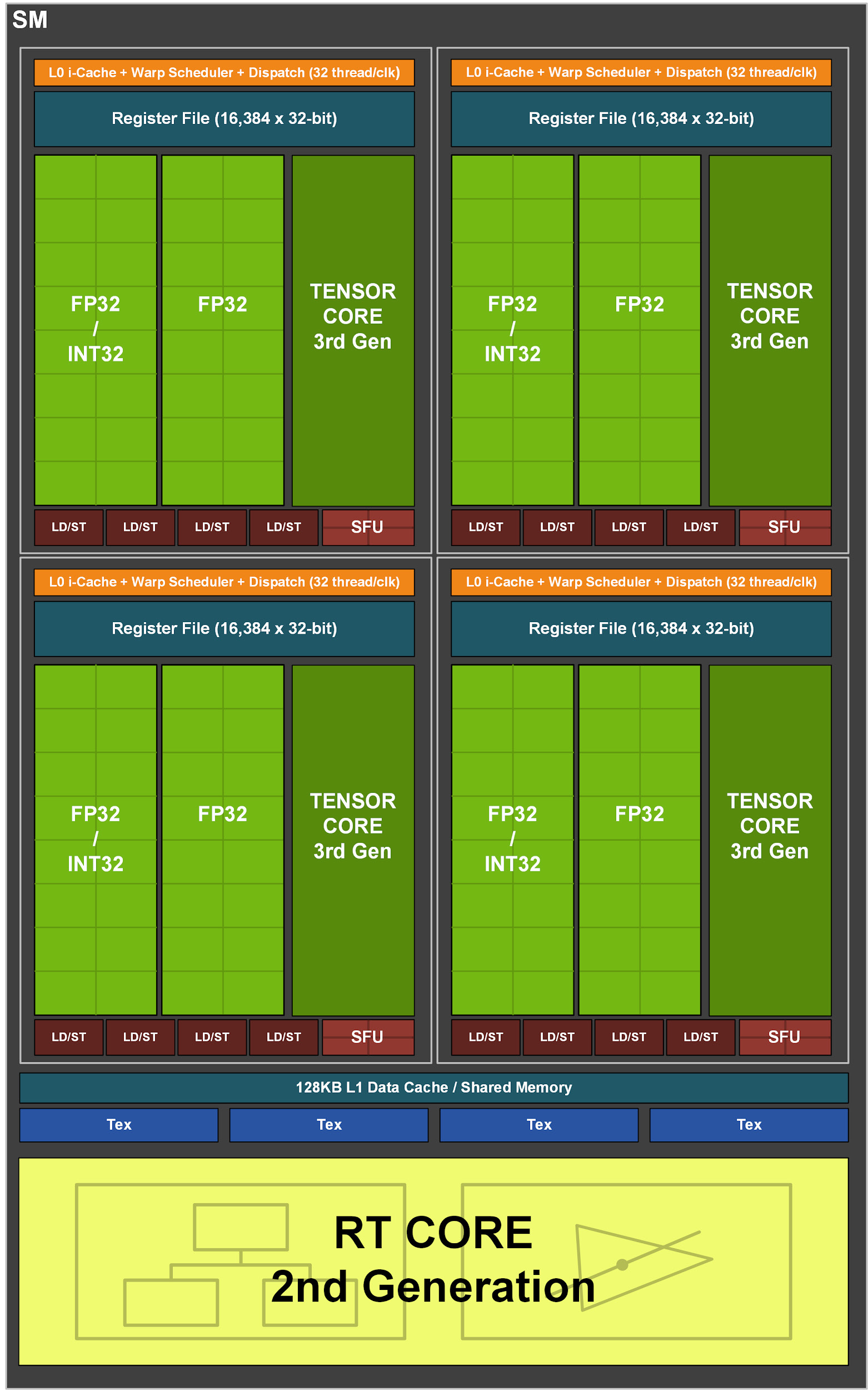
Gambar 3. Multiprosesor Streaming GA10x
Menggandakan kecepatan komputasi FP32
Sebagian besar kalkulasi grafik adalah operasi floating point 32-bit (FP32). Multiprosesor Streaming Ampere GA10x memberikan kecepatan dua kali lipat dari operasi FP32 pada kedua saluran data. Hasilnya, dalam konteks FP32, GeForce RTX 3090 menyediakan lebih dari 35 teraflop, yang lebih dari 2 kali lipat kemampuan Turing.
GA10X dapat menjalankan 128 operasi FP32 atau 64 operasi FP32 dan 64 operasi INT32 per jam, yang menggandakan kecepatan komputasi Turing.
Tugas permainan modern memiliki berbagai macam kebutuhan pemrosesan. Banyak perhitungan memerlukan sekumpulan operasi FP32 (seperti FFMA, penambahan titik mengambang (FADD), atau perkalian titik mengambang (FMUL)), serta banyak perhitungan bilangan bulat yang lebih sederhana.
Multiprosesor GA10x terus mendukung operasi FP16 kecepatan ganda (HFMA), yang juga didukung di Turing. Dan, mirip dengan GPU TU102, TU104, dan TU106, di GA10x, operasi FP16 standar juga ditangani oleh inti tensor.
Memori bersama dan cache data L1
GA10x memiliki arsitektur terpadu untuk memori bersama, cache data L1, dan cache tekstur. Desain terpadu ini dapat dimodifikasi berdasarkan beban kerja dan kebutuhan.
Chip GA102 berisi 10.752 KB cache L1 (dibandingkan dengan 6.912 KB di TU102). Selain itu, GA10x juga memiliki bandwidth memori bersama dua kali lipat dibandingkan dengan Turing (128 byte / siklus versus 64 byte / siklus). Total bandwidth L1 untuk GeForce RTX 3080 adalah 219 GB / dtk versus 116 GB / dtk untuk GeForce RTX 2080 Super.
Performa per watt
Seluruh arsitektur NVIDIA Ampere dibangun untuk meningkatkan efisiensi - dari logika, memori, manajemen daya dan termal hingga desain PCB, perangkat lunak, dan algoritme. Pada tingkat kinerja yang sama, GPU Ampere lebih hemat energi hingga 1,9x daripada perangkat Turing yang sebanding.
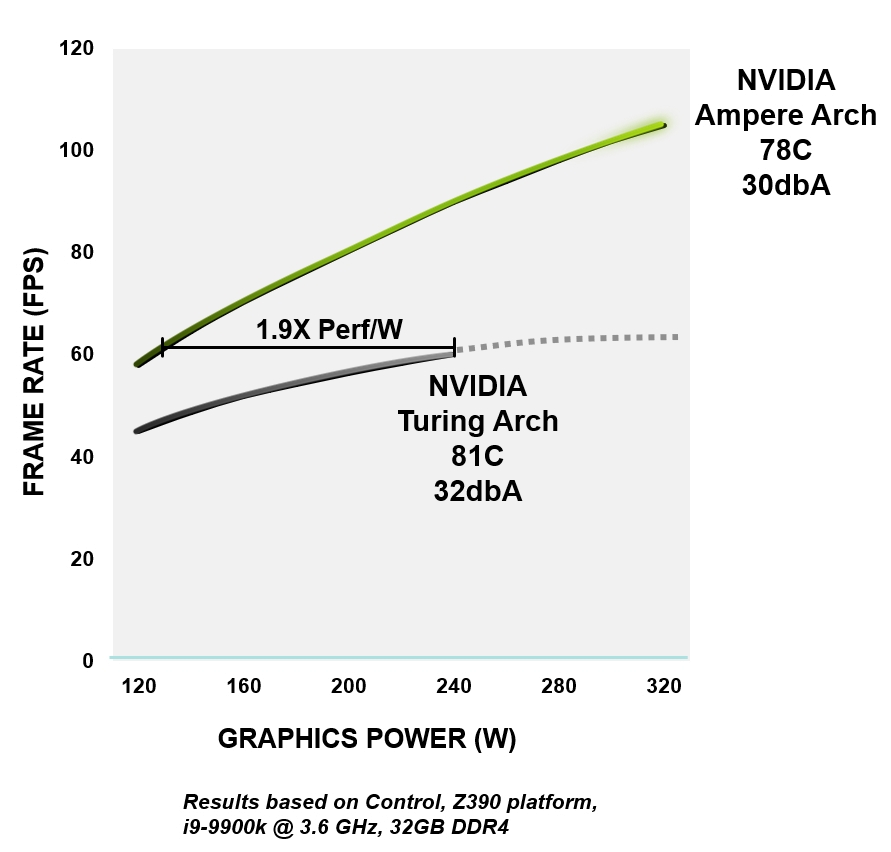
Gambar 4. Efisiensi daya RTX 3080 versus arsitektur GeForce RTX 2080 Super
Core RT generasi kedua
Core RT yang baru menampilkan sejumlah penyempurnaan yang, jika digabungkan dengan sistem caching yang diperbarui, secara efektif menggandakan kinerja ray-tracing prosesor Ampere dibandingkan Turing. Selain itu, GA10x memungkinkan proses lain dijalankan secara bersamaan dengan komputasi RT, sehingga secara signifikan mempercepat banyak tugas.
Pelacakan sinar generasi kedua di GA10x
GeForce RTX berdasarkan arsitektur Turing adalah GPU pertama yang membuat pelacakan sinar sinematik menjadi kenyataan dalam game PC. GA10x dilengkapi dengan teknologi ray tracing generasi kedua. Seperti Turing, multiprosesor GA10x memiliki blok perangkat keras khusus untuk memeriksa persimpangan sinar dengan BVH dan segitiga. Pada saat yang sama, inti dari multiprosesor Ampere memiliki kecepatan dua kali lipat pengujian persimpangan sinar dan segitiga dibandingkan dengan Turing.
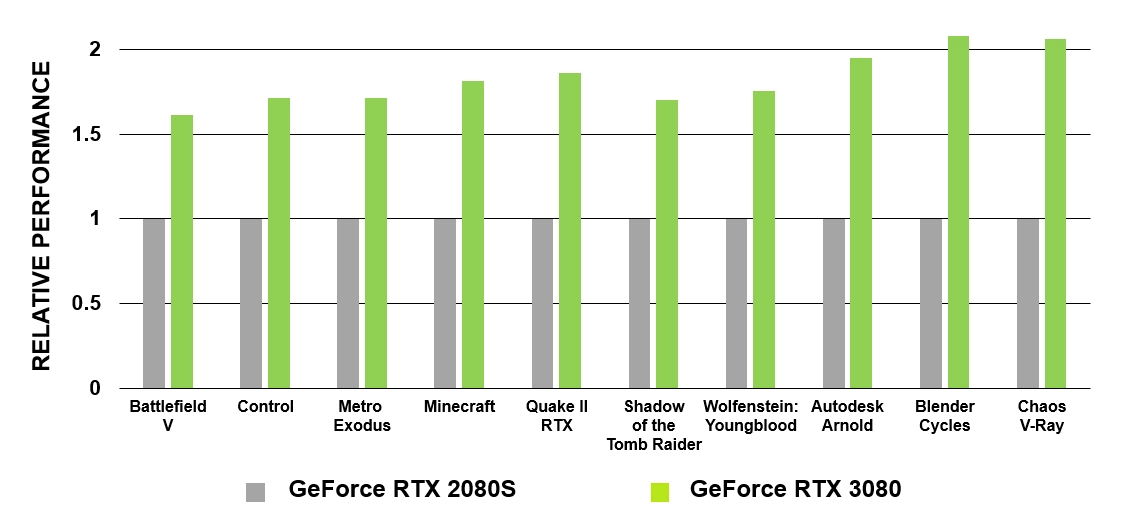
Gambar 5. Perbandingan kinerja RT core GeForce RTX 3080 dan GeForce RTX 2080 Super
Multiprosesor GA10x dapat melakukan operasi secara bersamaan dan tidak terbatas pada komputasi dan grafik saja, seperti yang terjadi pada GPU generasi sebelumnya. Jadi, misalnya di GA10x, algoritma pengurangan noise dapat dijalankan secara bersamaan dengan ray tracing.

Gambar 6. Inti RT Generasi Kedua di GPU GA10x
Perhatikan bahwa beban kerja intensif RT tidak secara signifikan meningkatkan beban pada inti multiprosesor, sehingga memungkinkan daya pemrosesan multiprosesor digunakan untuk tugas lain. Ini adalah keuntungan besar dibandingkan arsitektur pesaing lainnya yang tidak memiliki inti RT khusus dan oleh karena itu harus menggunakan blok penyusunnya untuk grafik dan penelusuran sinar.
Prosesor Ampere RTX sedang beraksi
Pelacakan sinar dan shader intensif secara komputasi. Tetapi akan jauh lebih mahal untuk menjalankan semuanya dengan inti CUDA saja, jadi termasuk inti tensor dan RT membantu mempercepat pemrosesan secara signifikan. Gambar 7 menunjukkan contoh game Wolfenstein: Youngblood dengan penelusuran sinar yang diaktifkan dalam berbagai skenario.
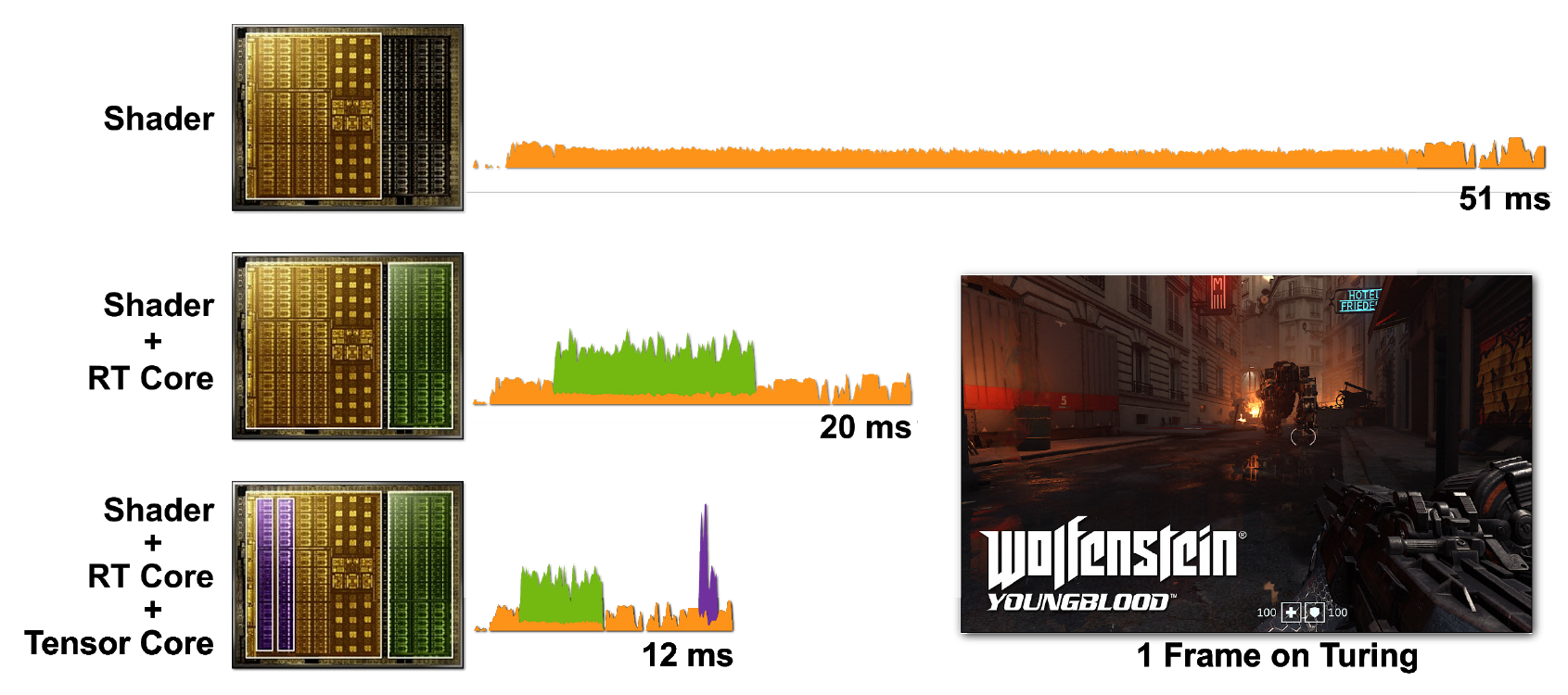
Gambar 7. Rendering frame tunggal Wolfenstein: Youngblood pada RTX 2080 Super GPU menggunakan a) shader core (CUDA), b) shader core dan RT core, c) shader core, tensor core, dan RT core. Perhatikan waktu frame yang semakin berkurang saat Anda menambahkan kekuatan berbagai inti prosesor RTX.
Dalam kasus pertama, dibutuhkan 51 ms (~ 20 fps) untuk memulai satu frame. Saat inti RT diaktifkan, bingkai dirender jauh lebih cepat - dalam 20 mdtk (50 fps). Menggunakan DLSS pada inti tensor mengurangi waktu bingkai menjadi 12 mdtk (~ 83 fps).
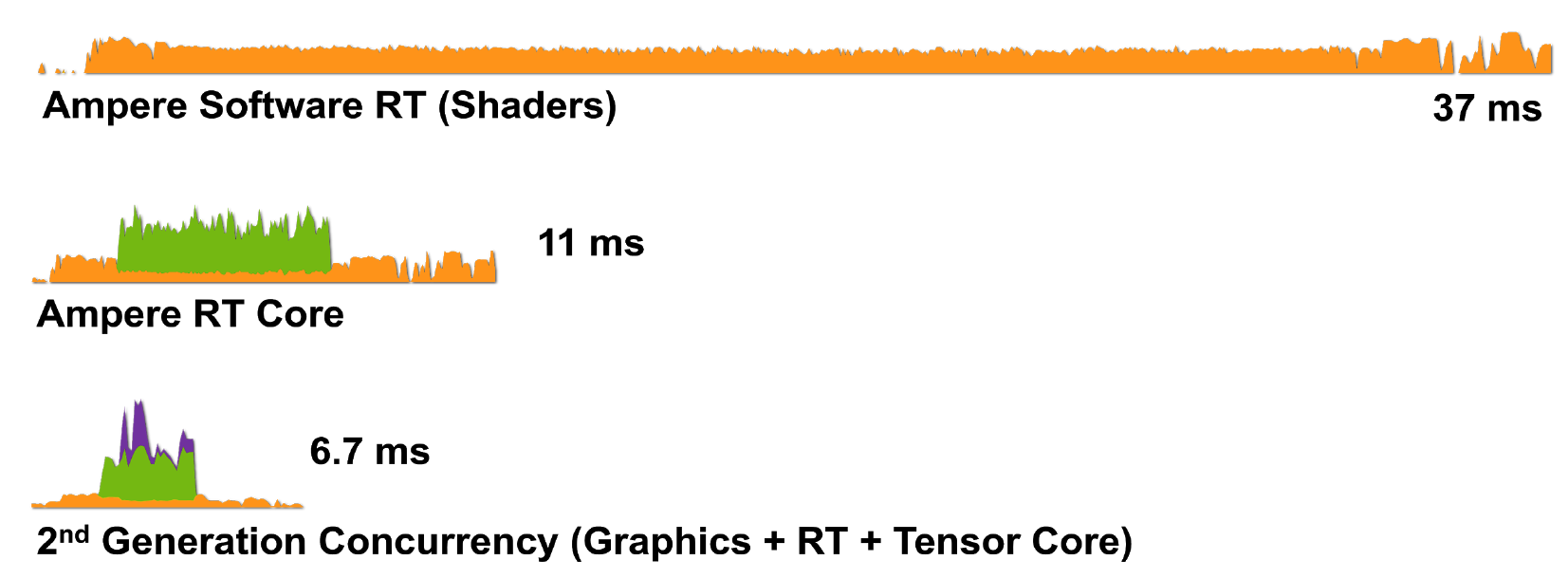
Gambar 8. Rendering frame tunggal Wolfenstein: Youngblood pada RTX 3080 menggunakan a) shader cores (CUDA), b) shader cores dan RT cores, c) shader cores, tensor dan RT cores.
Jadi, teknologi RTX dengan arsitektur Ampere bahkan lebih efisien dalam menangani tugas rendering: RTX 3080 merender bingkai dalam 6,7 ms (150 fps), yang merupakan peningkatan besar dibandingkan RTX 2080.
Penelusuran sinar yang dipercepat perangkat keras menggunakan buram gerakan
Motion blur adalah gerakan yang sering digunakan dalam grafik komputer. Gambar foto tidak dibuat secara instan, tetapi dengan memaparkan film ke cahaya untuk jangka waktu terbatas. Subjek yang bergerak cukup cepat dibandingkan dengan waktu eksposur kamera akan muncul di foto sebagai goresan atau bintik. Agar GPU dapat membuat gambar buram gerakan yang tampak realistis saat objek dalam suatu pemandangan bergerak cepat di depan kamera statis, GPU harus dapat mensimulasikan cara kerja kamera dan film dengan pemandangan tersebut. Buram gerakan terutama penting dalam pembuatan film karena film diputar pada 24 bingkai per detik dan pemandangan tanpa keburaman gerakan akan tampak tajam dan berombak.
GPU Turing melakukan pekerjaan yang cukup baik untuk mempercepat gerakan kabur secara umum. Namun, dalam kasus geometri yang bergerak, tugasnya bisa lebih sulit, karena informasi tentang BVH berubah seiring dengan posisi objek dalam ruang.
Seperti yang Anda lihat pada Gambar 9, inti Turing RT melakukan penelusuran perangkat keras dari hierarki BVH, memeriksa persimpangan sinar dengan BBox dan segitiga. GA10x dapat melakukan semua hal yang sama, tetapi sebagai tambahan, GA10x memiliki blok Interpolate Triangle Position baru, yang mempercepat gerakan kabur dalam penelusuran sinar.
Core Turing dan GA10x RT mengimplementasikan arsitektur MIMD (Multiple Instruction Multiple Data), yang memungkinkan beberapa berkas diproses secara bersamaan.
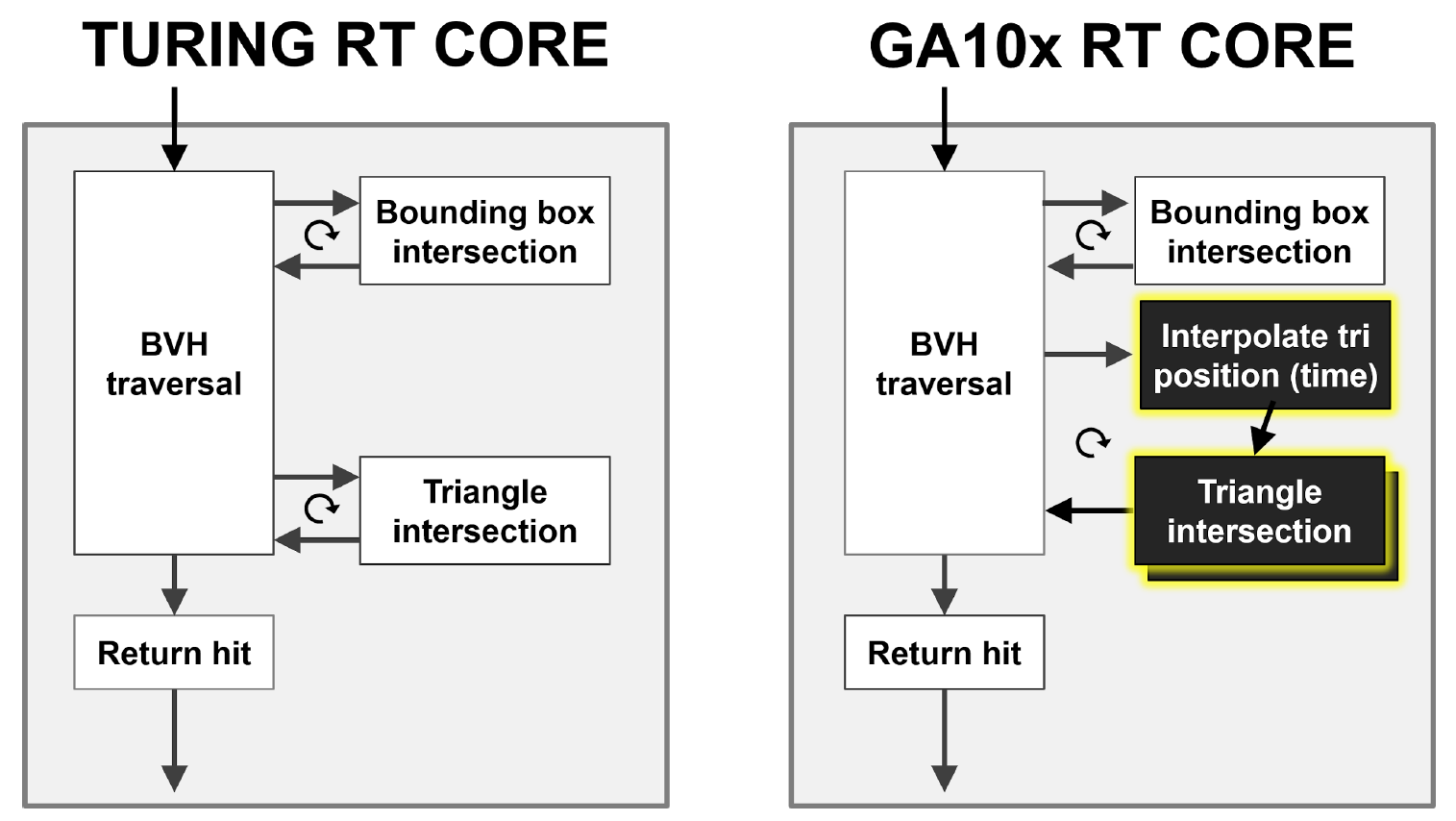
Gambar 9. Perbandingan akselerasi perangkat keras buram gerakan dalam kasus Turing dan Ampere
Masalah utama dengan buram gerakan adalah bahwa segitiga dalam pemandangan tidak tetap dalam waktu. Dalam penelusuran sinar dasar, pengujian persimpangan statis dilakukan, dan ketika sinar mengenai segitiga, ia mengembalikan informasi tentang pukulan tersebut. Seperti yang ditunjukkan pada Gambar 10, dengan blur, tidak ada segitiga yang memiliki koordinat tetap. Setiap sinar diberi stempel waktu untuk menunjukkan waktu pelacakannya, dan posisi segitiga serta perpotongan sinar ditentukan dari persamaan BVH.
Jika proses ini tidak diakselerasi oleh perangkat keras, maka dapat menyebabkan banyak masalah, termasuk karena nonliniernya.
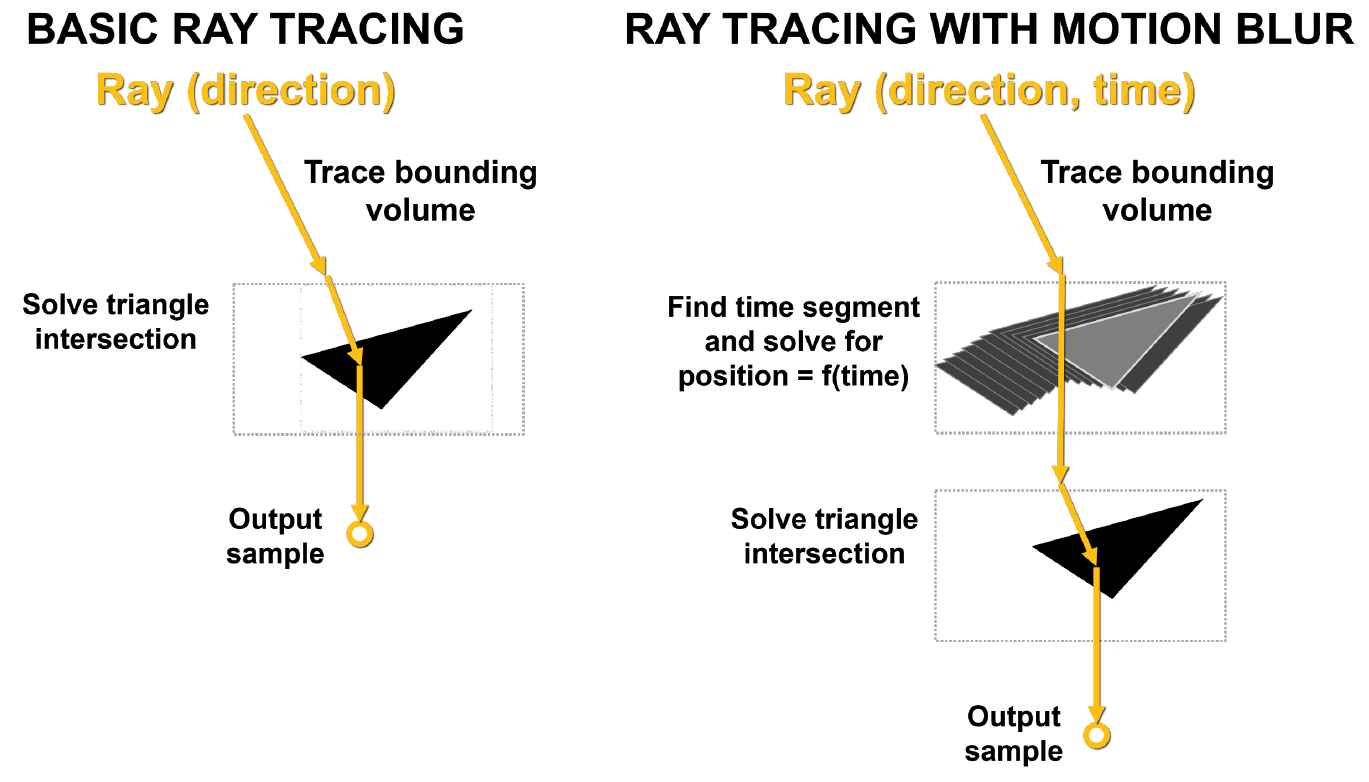
Gambar. 10. Penelusuran sinar dasar dan penelusuran sinar dengan buram gerakan
Di sisi kiri Gambar 11, sinar yang dikirim ke pemandangan statis mengenai segitiga yang sama pada waktu yang bersamaan. Titik putih menunjukkan tempat tumbukan, hasil ini dikembalikan. Dalam kasus buram gerakan, setiap sinar ada pada momennya masing-masing. Setiap balok diberi cap waktu yang berbeda secara acak. Misalnya, sinar jingga mencoba melintasi segitiga jingga pada saat yang sama, lalu sinar hijau dan biru melakukan hal yang sama. Pada akhirnya, sampel dicampur, menghasilkan hasil buram yang lebih akurat secara matematis.
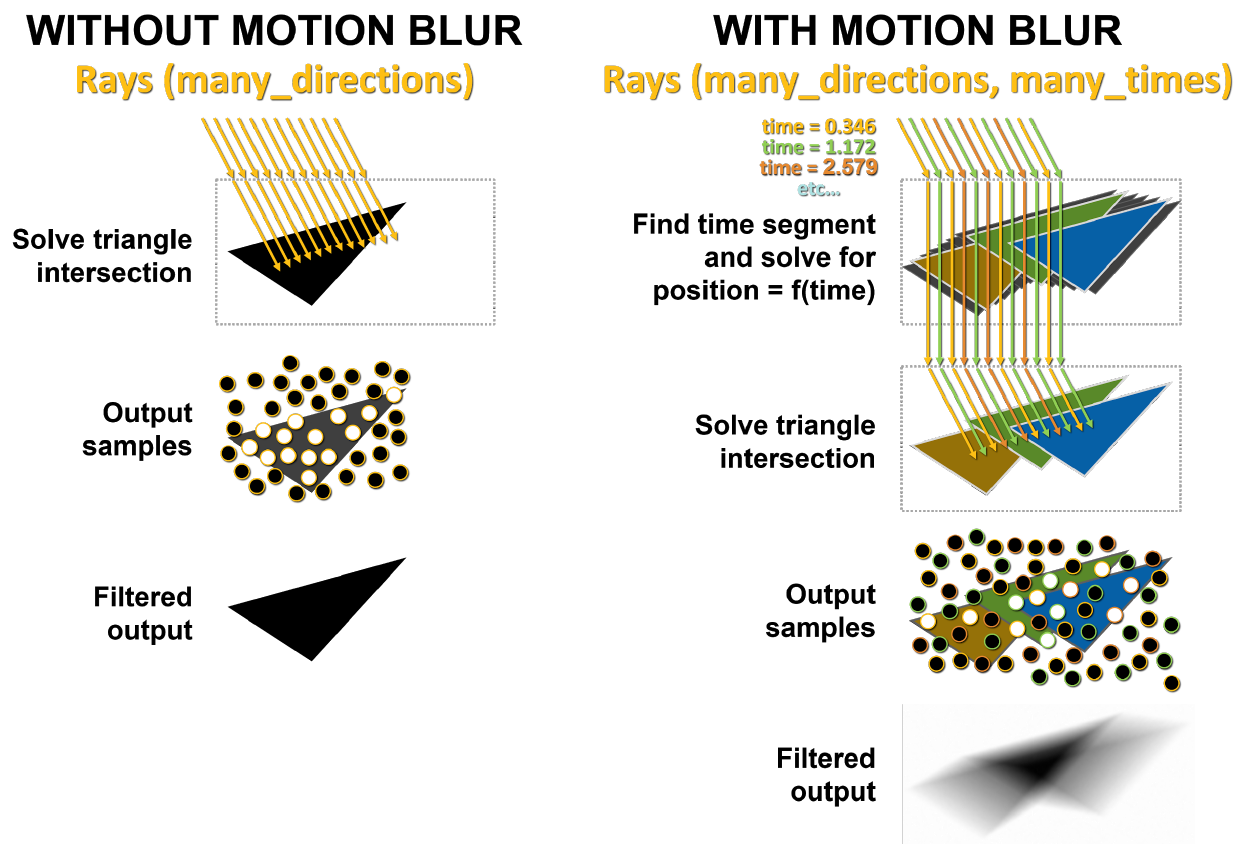
Gambar 11. Rendering tanpa blur dan blur di GA10x
Blok Interpolate Triangle Position menginterpolasi segitiga di BVH antara segitiga yang sudah ada berdasarkan pergerakan objek, sehingga sinar akan memotongnya di lokasi yang diharapkan pada saat yang ditentukan oleh stempel waktu sinar. Pendekatan ini memungkinkan rendering akurat dari gerakan yang dilacak dengan sinar hingga delapan kali lebih cepat daripada Turing.
Motion blur yang dipercepat perangkat keras GA10x didukung oleh Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold dan Redshift Renderer 3.0.X menggunakan NVIDIA OptiX 7.0 API.
Kecepatan rendering motion blur hingga 5x lebih cepat dengan RTX 3080 dibandingkan dengan RTX 2080 Super.
Core Tensor Generasi ke-3 di GPU GA10x
GA10x menyertakan NVIDIA Tensor Cores generasi ketiga baru, yang menampilkan dukungan untuk tipe data baru, peningkatan kinerja, efisiensi, dan fleksibilitas pemrograman. Fitur ketersebaran baru menggandakan kinerja Tensor Cores dibandingkan Turing generasi sebelumnya. Fungsi AI seperti NVIDIA DLSS untuk resolusi super AI (sekarang dengan dukungan 8K), NVIDIA Broadcast untuk pemrosesan suara dan video, dan NVIDIA Canvas untuk menggambar juga lebih cepat.
Kernel tensor adalah unit eksekusi khusus yang dirancang untuk melakukan operasi tensor / matriks - fungsi komputasi utama dalam pembelajaran mendalam. Mereka diperlukan untuk meningkatkan kualitas grafis dengan DLSS (Deep Learning Super Sampling), pengurangan kebisingan berbasis AI, penghilangan kebisingan latar belakang di dalam obrolan suara dalam game menggunakan RTX Voice, dan banyak lagi aplikasi lainnya.
Pengenalan Tensor Cores ke dalam GPU game GeForce telah memungkinkan pembelajaran mendalam secara real-time di aplikasi game untuk pertama kalinya. Desain inti tensor generasi ketiga dalam GPU GA10x semakin meningkatkan kinerja mentah dan memanfaatkan mode presisi komputasi baru seperti TF32 dan BFloat16. Ini memainkan peran besar dalam aplikasi Layanan Neural NVIDIA NGX berbasis AI untuk meningkatkan grafis, rendering, dan fitur lainnya.
Perbandingan Turing dan Ampere Tensor Cores
Inti Tensor Ampere telah diatur ulang melalui Turing untuk meningkatkan efisiensi dan mengurangi konsumsi daya. Arsitektur inti Ampere SM memiliki lebih sedikit inti tensor, tetapi masing-masing lebih bertenaga.
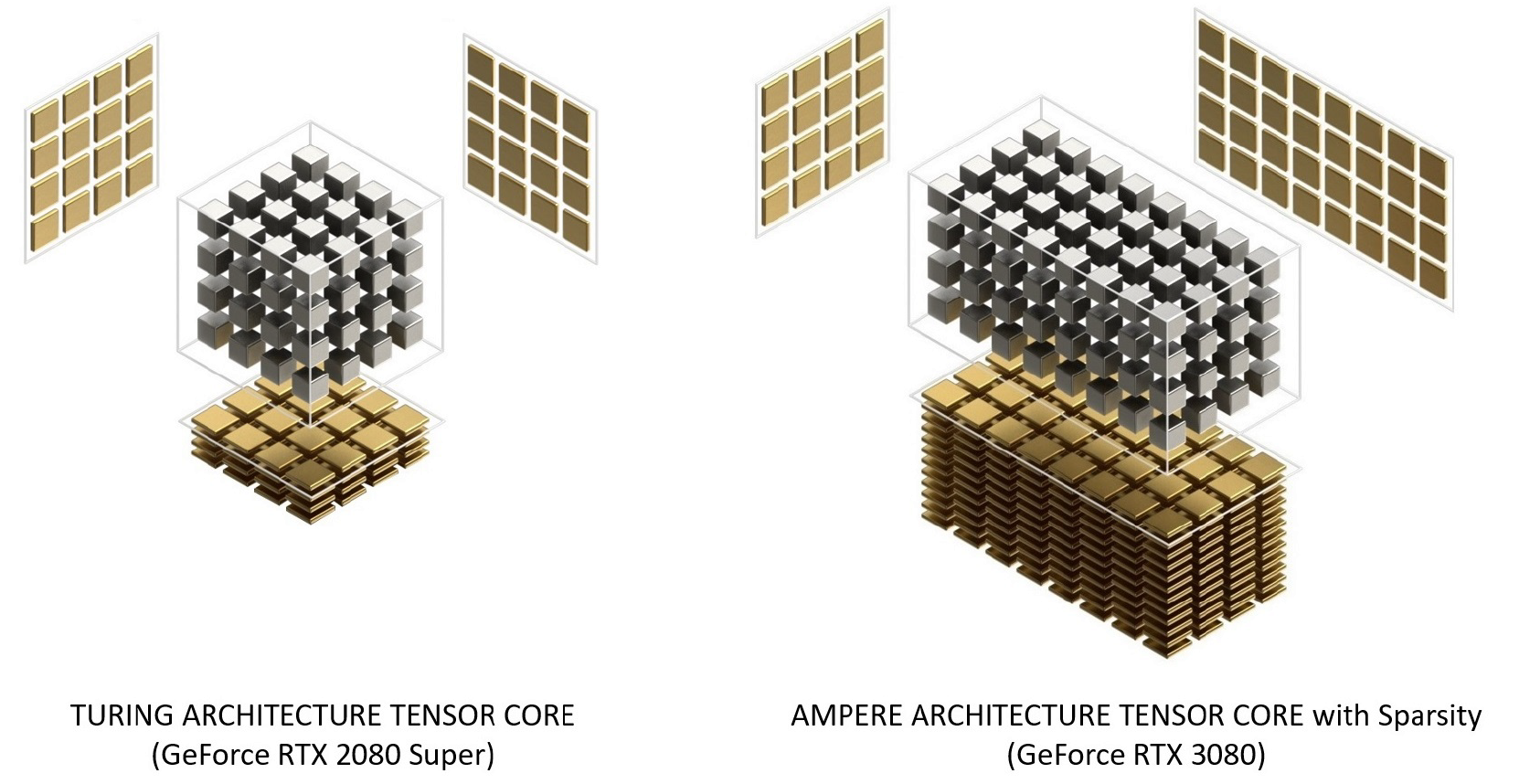
Gambar 12. Tensor core dengan arsitektur Turing dan Ampere. GeForce RTX 3080 menghadirkan bandwidth Tensor Core FP16 2,7x lebih cepat daripada GeForce RTX 2080 Super
Ketersebaran terstruktur berbutir halus
Dengan GPU A100, NVIDIA telah memperkenalkan Fine-Grained Structured Sparsity, pendekatan baru untuk menggandakan bandwidth komputasi untuk jaringan neural dalam. Fitur ini juga didukung oleh GPU GA10x dan membantu mempercepat beberapa operasi rendering grafis berbasis AI.
Karena jaringan pembelajaran yang dalam dapat menyesuaikan bobot melalui pembelajaran umpan balik, secara umum, batasan struktural tidak memengaruhi keakuratan model yang dilatih.
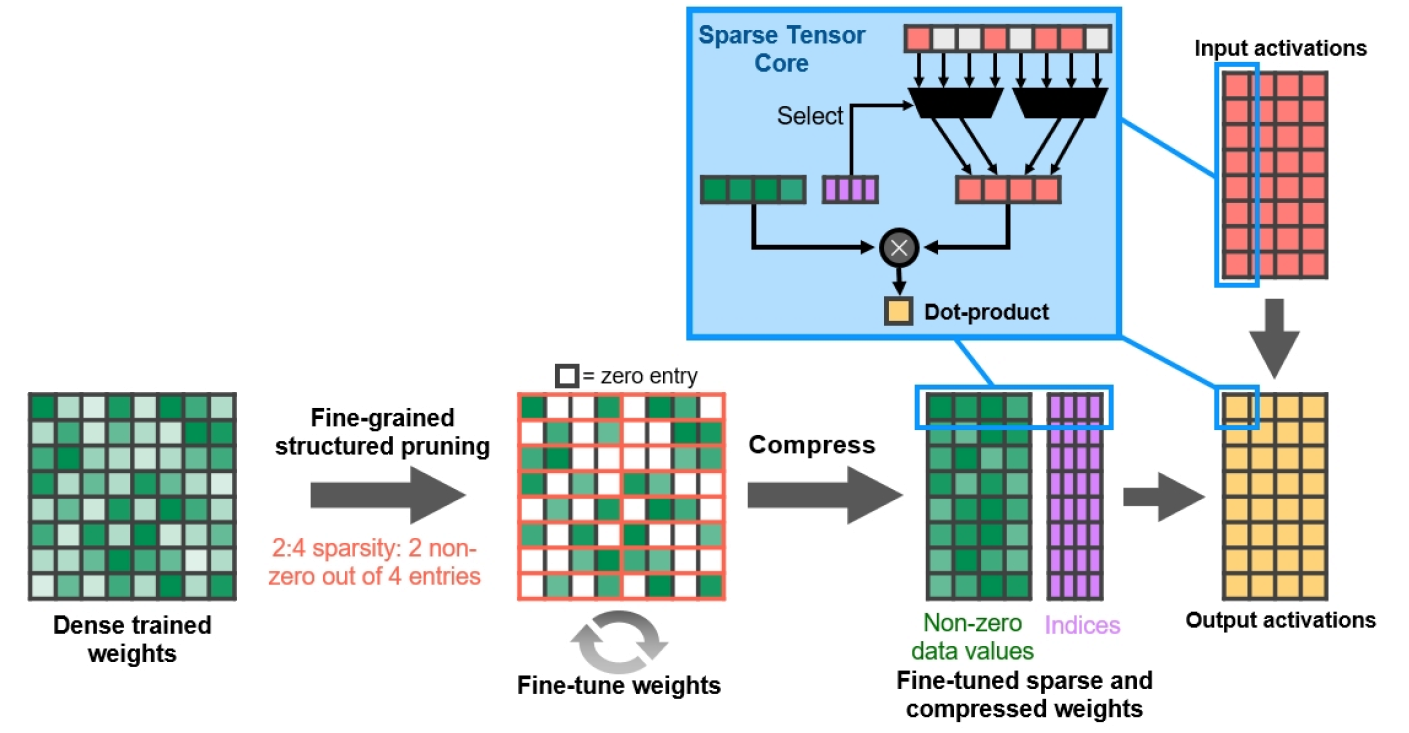
Gambar 13. Ketersebaran terstruktur berbutir halus
NVIDIA telah mengembangkan algoritma ketersebaran jaringan neural dalam yang sederhana dan serbaguna menggunakan pola ketersebaran 2: 4 yang terstruktur. Jaringan pertama kali dilatih dengan bobot padat, kemudian terjadi pemangkasan terstruktur yang sangat detail, setelah itu nilai nol dapat dibuang, dan matematika yang tersisa dikompresi untuk meningkatkan throughput. Algoritme tidak memengaruhi keakuratan jaringan terlatih untuk inferensi, ini hanya mempercepatnya.
NVIDIA DLSS 8K
Merender gambar dengan pelacakan sinar pada kecepatan bingkai tinggi sangat mahal secara komputasi. Sebelum munculnya NVIDIA Turing, diyakini bahwa penerapannya akan memakan waktu bertahun-tahun. Untuk membantu masalah ini, NVIDIA telah membuat Deep Learning Supersampling (DLSS).

Gambar 14. Watch Dogs: Legion dengan DLSS pada 1080p, 4K, dan 8K. Perhatikan teks dan detail yang lebih tajam yang disediakan oleh DLSS dalam 8K
DLSS hanya menjadi lebih baik di NVIDIA Ampere melalui penggunaan Tensor Cores generasi ketiga dan faktor penskalaan resolusi super 9x, yang untuk pertama kalinya memungkinkan untuk menjalankan game yang ditelusuri dengan sinar pada 8K pada 60 fps.
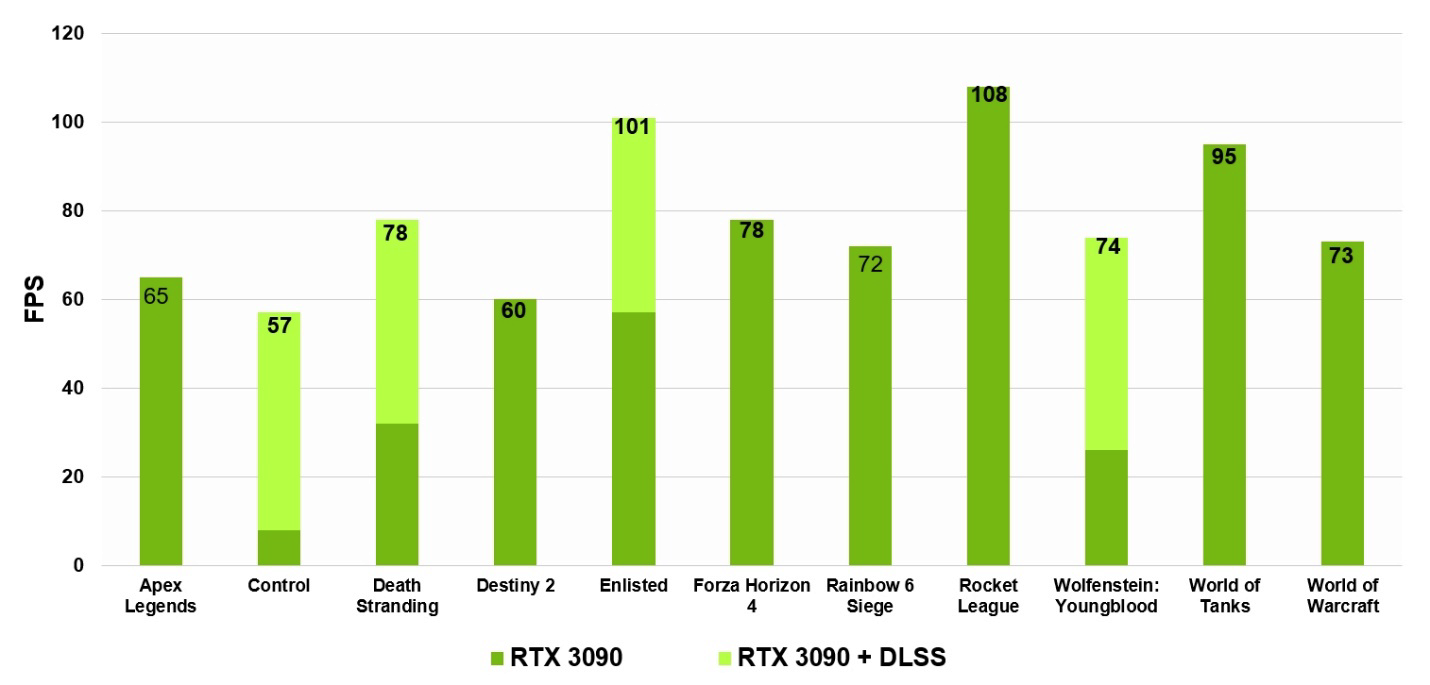
15. GeForce RTX 3090 60 fps 8K DLSS . , . Core i9-10900K
GDDR6X
Game PC modern dan aplikasi kreatif memerlukan lebih banyak bandwidth memori untuk menangani geometri pemandangan yang semakin kompleks, tekstur yang lebih halus, penelusuran sinar, inferensi AI, dan tentu saja bayangan dan supersampling.
GDDR6X adalah memori grafis pertama yang melebihi 900 GB / s. Untuk mencapai hal ini, teknologi pensinyalan inovatif dan modulasi amplitudo pulsa empat level (PAM4) telah digunakan, secara kolektif merevolusi cara data dipindahkan dalam memori. Dengan algoritme PAM4, GDDR6X mentransfer lebih banyak data dengan laju yang jauh lebih cepat, memindahkan dua bit data sekaligus, yang menggandakan laju data I / O dari skema PAM2 / NRZ sebelumnya.
GDDR6X saat ini mendukung 19,5 Gbps untuk GeForce RTX 3090 dan 19 Gbps untuk GeForce RTX 3080. Berkat ini, GeForce RTX 3080 memberikan kinerja memori 1,5 kali lipat dari pendahulunya, RTX 2080 Super. ...
Gambar 16 menunjukkan perbandingan struktur GDDR6 (kiri) dan GDDR6X (kanan). GDDR6X mentransmisikan data yang sama pada setengah frekuensi GDDR6. Atau, sebagai alternatif, GDDR6X dapat menggandakan bandwidth efektifnya sambil mempertahankan frekuensi yang sama.

Gambar 16. Sinyal GDDR6X yang menggunakan PAM4 menunjukkan kinerja dan efisiensi yang lebih baik daripada GDDR6
Skema pengkodean MTA (Pencegahan Transisi Maksimum) baru telah dikembangkan untuk mengatasi masalah SNR yang terkait dengan pensinyalan PAM4. MTA mencegah sinyal berkecepatan tinggi dari tertinggi ke terendah dan sebaliknya.

Gambar 17. Enkode baru di GDDR6X
Mendukung kecepatan data hingga 19,5 Gbps pada chip GA10x, GDDR6X memberikan bandwidth memori puncak hingga 936 GB / dtk, 52% lebih banyak daripada GPU TU102 yang digunakan di GeForce RTX 2080 Ti. GDDR6X memiliki lompatan terbesar dalam bandwidth dalam 10 tahun setelah GPU seri GeForce 200.
RTX IO
Game modern mengandung dunia yang sangat besar. Dengan perkembangan teknologi seperti fotogrametri, mereka semakin meniru kenyataan dan, akibatnya, terkandung dalam file dengan volume yang semakin besar. Proyek game terbesar membutuhkan lebih dari 200 GB, yaitu 3 kali lebih banyak dari empat tahun lalu, dan jumlah ini hanya akan bertambah seiring waktu.
Gamer semakin beralih ke SSD untuk mengurangi waktu muat game: Meskipun hard drive dibatasi pada bandwidth 50-100MB / dtk, SSD M.2 PCIe Gen4 terbaru membaca data hingga 7GB / dtk.
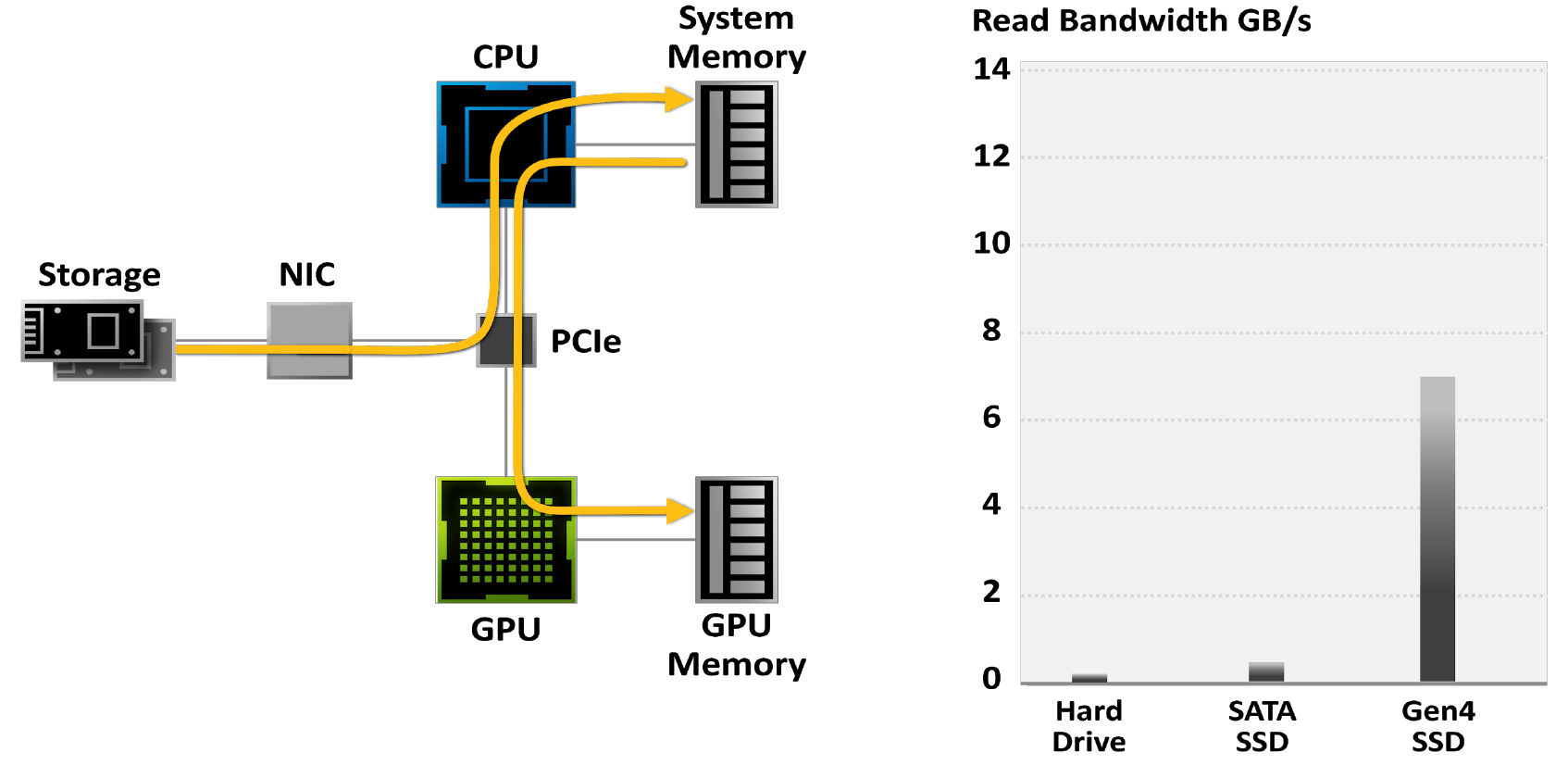
Gambar 18. Game dibatasi oleh sistem I / O tradisional

Gambar 19. Menggunakan model penyimpanan tradisional, membongkar game dapat mengambil semua 24 inti prosesor. Mesin game modern telah melampaui kemampuan API penyimpanan tradisional. Inilah mengapa dibutuhkan arsitektur I / O generasi baru. Di sini, bilah abu-abu menunjukkan kecepatan transfer data, blok hitam dan biru - inti CPU yang diperlukan untuk ini.
NVIDIA RTX IO adalah seperangkat teknologi yang menyediakan pemuatan dan pembongkaran aset berbasis GPU yang cepat dan memberikan kinerja I / O hingga 100x lebih cepat daripada hard drive dan API penyimpanan tradisional.
NVIDIA RTX IO didukung oleh Microsoft DirectStorage API, penyimpanan generasi berikutnya yang dirancang khusus untuk PC gaming NVMe SSD saat ini. NVIDIA RTX IO memberikan dekompresi lossless, memungkinkan data untuk dibaca dalam bentuk terkompresi melalui DirectStorage dan dikirim ke GPU. Ini melepaskan beban CPU dengan memindahkan data dari penyimpanan ke GPU dalam bentuk terkompresi yang lebih efisien dan menggandakan kinerja I / O.

Gambar 20. RTX IO Menghasilkan 100X Lebih Banyak Throughput dan 20X Lebih Rendah Penggunaan CPU. Bilah abu-abu dan hijau menunjukkan baud rate, blok hitam dan biru diperlukan untuk inti CPU ini.
Mesin layar dan video
DisplayPort 1.4a dengan DSC 1.2a
Pawai menuju resolusi yang lebih tinggi dan frame rate yang lebih tinggi terus berlanjut, dan GPU NVIDIA Ampere berusaha untuk tetap menjadi yang terdepan dalam industri untuk menghadirkan keduanya. Gamer sekarang dapat bermain di layar 4K (3820 x 2160) pada 120Hz dan 8K (7680 x 4320) pada 60Hz - empat kali jumlah piksel 4K.
Mesin arsitektur Ampere dirancang untuk mendukung banyak teknologi baru yang termasuk dalam antarmuka tampilan tercepat yang tersedia saat ini. Ini termasuk DisplayPort 1.4a, yang menghasilkan 8K @ 60Hz dengan VESA Display Stream Compression (DSC) 1.2a. GPU Ampere baru dapat dihubungkan ke dua layar 8K 60Hz hanya dengan satu kabel per layar.
HDMI 2.1 dengan DSC 1.2a
Arsitektur NVIDIA Ampere menambahkan dukungan untuk HDMI 2.1, pembaruan terbaru pada spesifikasi HDMI, untuk pertama kalinya untuk GPU terpisah. HDMI telah meningkatkan bandwidth maksimum hingga 48 Gbps, yang juga memungkinkan format HDR dinamis. Dukungan untuk 8K @ 60Hz dengan HDR memerlukan kompresi DSC 1.2a atau format piksel 4: 2: 0.
NVDEC Generasi ke-5 - Decoding Video yang Dipercepat Perangkat Keras
GPU NVIDIA menyertakan Hardware-Accelerated Video Decoding (NVDEC) Generasi ke-5, yang menyediakan decoding video perangkat keras lengkap untuk berbagai codec populer.

Gambar 21. Format encoding dan decoding video yang didukung oleh
GPU GA10x Dekoder NVIDIA generasi kelima di GA10x mendukung decoding yang dipercepat perangkat keras dari codec video berikut pada platform Windows dan Linux: MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9, dan AV1.
NVIDIA adalah produsen GPU pertama yang memberikan dukungan perangkat keras untuk decoding AV1.
Penguraian kode perangkat keras AV1
Meskipun AV1 sangat efisien dalam mengompresi video, decoding-nya sangat intensif secara komputasi. Dekoder perangkat lunak modern menyebabkan penggunaan CPU yang tinggi dan menyulitkan pemutaran video definisi tinggi. Dalam pengujian NVIDIA, prosesor Intel i9 9900K menghasilkan rata-rata 28 frame per detik di YouTube dalam 8K60 HDR, dengan penggunaan CPU melebihi 85%. GPU GA10x dapat memainkan AV1 dengan meneruskan decoding ke NVDEC, yang mampu memutar konten HDR 8K60 dengan penggunaan CPU yang sangat rendah (~ 4% pada CPU yang sama seperti pada pengujian sebelumnya).
NVENC Generasi Ketujuh - Encoding Video yang Dipercepat Perangkat Keras
Pengkodean video bisa menjadi tugas komputasi yang kompleks, tetapi jika Anda mengunggahnya ke NVENC, mesin grafis dan CPU dibebaskan untuk operasi lain. Misalnya, saat streaming game ke Twitch.tv menggunakan Open Broadcaster Software (OBS), melepas penyandian video ke NVENC akan memungkinkan mesin GPU dialokasikan untuk merender game, dan CPU untuk tugas pengguna lainnya.
NVENC memungkinkan:
- Kualitas tinggi, pengkodean latensi sangat rendah dan streaming game dan aplikasi tanpa menggunakan CPU;
- pengkodean kualitas sangat tinggi untuk pengarsipan, streaming OTT, video web;
- Enkode daya sangat rendah per streaming (W / streaming).
Dengan setelan streaming bersama untuk Twitch dan YouTube, pengkodean perangkat keras berbasis NVENC di GA10x GPU mengungguli pembuat enkode perangkat lunak x264 menggunakan prasetel Cepat dan setara dengan x264 Medium, prasetel yang biasanya membutuhkan daya dua komputer. Ini secara dramatis menghilangkan pemanfaatan CPU. Encoding 4K merupakan beban kerja yang terlalu berat untuk konfigurasi CPU pada umumnya, tetapi encoder NVENC GA10x menyediakan encoding resolusi tinggi yang mulus hingga 4K di H.264 dan bahkan 8K di HEVC.
Kesimpulan
Dengan setiap arsitektur prosesor baru, NVIDIA berupaya menghadirkan kinerja revolusioner kepada generasi berikutnya sambil memperkenalkan fitur-fitur baru yang meningkatkan kualitas gambar. Turing adalah GPU pertama yang memperkenalkan penelusuran sinar yang dipercepat perangkat keras, sebuah fitur yang pernah dianggap sebagai cawan suci grafik komputer. Saat ini, efek ray tracing yang sangat realistis dan akurat secara fisik ditambahkan ke banyak game PC AAA baru, dan ray tracing yang dipercepat GPU dianggap sebagai fitur yang harus dimiliki oleh sebagian besar gamer PC. GPU NVIDIA GA10x Ampere yang baru menghadirkan fitur dan kinerja yang Anda butuhkan untuk menikmati game dengan penelusuran sinar baru ini dengan frekuensi gambar hingga 2x lebih cepat daripada yang tersedia saat ini.Fitur lain dari Turing - peningkatan pemrosesan AI dengan akselerasi CPU yang meningkatkan pembatalan kebisingan, rendering, dan aplikasi grafis lainnya - juga dibawa ke level berikutnya berkat arsitektur Ampere.
Terakhir, tautan ke dokumen lengkap .