
Bayangkan log 2,5 gigabyte setelah build yang gagal. Itu tiga juta baris. Anda mencari bug atau regresi yang muncul di baris sejuta. Mungkin tidak mungkin menemukan satu baris seperti itu secara manual. Salah satu opsinya adalah perbedaan antara build terakhir yang berhasil dan yang gagal dengan harapan bug tersebut menulis baris yang tidak biasa ke log. Solusi Netflix lebih cepat dan lebih akurat daripada LogReduce - tidak perlu diragukan lagi.
Netflix dan garis di tumpukan log
Perbedaan md5 standar cepat, tetapi mencetak setidaknya ratusan ribu baris kandidat untuk dilihat karena menunjukkan perbedaan garis. Variasi logreduce adalah fuzzy diff menggunakan pencarian k-terdekat yang menemukan sekitar 40.000 kandidat, tetapi membutuhkan waktu satu jam. Solusi di bawah ini menemukan 20.000 string kandidat dalam 20 menit. Berkat keajaiban open source, ini hanya sekitar seratus baris kode Python.
Solusi - kombinasi representasi kata vektor yang menyandikan informasi semantik dari kata dan kalimat, dan hash berbasis lokasi(LSH - Hash Sensitif Lokal), yang secara efektif mendistribusikan elemen yang kira-kira dekat ke dalam beberapa kelompok dan elemen yang jauh ke dalam kelompok lain. Menggabungkan representasi vektor dari kata-kata dan LSH adalah ide bagus kurang dari sepuluh tahun yang lalu .
Catatan: kami menjalankan Tensorflow 2.2 pada CPU dan dengan eksekusi langsung untuk transfer learning dan scikit-learnNearestNeighboruntuk k tetangga terdekat. Ada perkiraan kompleks dari tetangga terdekat yang akan lebih baik untuk memecahkan masalah tetangga terdekat berbasis model.
Representasi kata vektor: apa itu dan mengapa?
Membangun sekumpulan kata dengan kategori k (pengkodean k-hot, generalisasi pengkodean kesatuan) adalah titik awal yang khas (dan berguna) untuk masalah deduplikasi, pencarian, dan kesamaan antara teks tidak terstruktur dan semi-terstruktur. Jenis kumpulan kata-kata pengkodean ini tampak seperti kamus dengan kata-kata individual dan nomornya. Contoh dengan kalimat "log in error, check log".
{"log": 2, "in": 1, "error": 1, "check": 1}
Pengkodean tersebut juga diwakili oleh vektor, di mana indeks sesuai dengan sebuah kata dan nilainya sesuai dengan jumlah kata. Di bawah ini adalah frasa "kesalahan masuk, periksa log" sebagai vektor, di mana entri pertama dicadangkan untuk menghitung kata "log", entri kedua untuk menghitung kata "masuk", dan seterusnya:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
Harap diperhatikan: vektor terdiri dari banyak angka nol. Nol adalah semua kata lain di kamus yang tidak ada dalam kalimat ini. Jumlah total entri vektor yang mungkin, atau dimensi vektor, adalah ukuran kosakata bahasa Anda, yang sering kali jutaan kata atau lebih, tetapi menyusut menjadi ratusan ribu dengan trik cerdas . Mari kita lihat kamus dan representasi vektor dari frase "otentikasi masalah". Kata-kata yang cocok dengan lima entri vektor pertama tidak muncul sama sekali dalam kalimat baru.
{"problem": 1, "authenticating": 1}
Ternyata:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
Kalimat "otentikasi masalah" dan "kesalahan masuk, periksa log" serupa secara semantik. Artinya, mereka pada dasarnya adalah hal yang sama, tetapi secara leksikal berbeda sebisa mungkin. Mereka tidak memiliki kata-kata yang sama. Dalam istilah fuzzy diff, kita dapat mengatakan bahwa mereka terlalu mirip untuk membedakannya, tetapi pengkodean md5 dan dokumen yang diproses oleh k-hot dengan kNN tidak mendukung ini.
Pengurangan dimensi menggunakan aljabar linier atau jaringan saraf tiruan untuk menempatkan kata, kalimat, atau garis log yang mirip secara semantik di samping satu sama lain dalam ruang vektor baru. Representasi vektor digunakan. Dalam contoh kita, "kesalahan masuk, periksa log" dapat memiliki vektor lima dimensi untuk mewakili:
[0.1, 0.3, -0.5, -0.7, 0.2]
Frasa "masalah otentikasi" bisa jadi
[0.1, 0.35, -0.5, -0.7, 0.2]
Vektor-vektor ini dekat satu sama lain dalam hal ukuran seperti kesamaan kosinus , berlawanan dengan vektor kantong kata mereka. Tampilan padat dan berdimensi rendah sangat berguna untuk dokumen pendek seperti jalur perakitan atau syslog.
Nyatanya, Anda akan mengganti ribuan atau lebih dimensi kamus hanya dengan representasi 100 dimensi yang kaya akan informasi (bukan lima). Pendekatan modern untuk pengurangan dimensi termasuk dekomposisi nilai singular dari matriks kata co-kejadian ( sarung tangan ) dan jaringan saraf khusus ( word2vec , Bert , ELMO ).
Bagaimana dengan pengelompokan? Mari kembali ke log build
Kami bercanda bahwa Netflix adalah layanan produksi log yang sesekali mengalirkan video. Pembuatan log, streaming, penanganan pengecualian - ini adalah ratusan ribu permintaan per detik. Oleh karena itu, penskalaan diperlukan ketika kita ingin menerapkan ML yang diterapkan di telemetri dan logging. Untuk alasan ini, kami berhati-hati dalam menskalakan deduplikasi teks, mencari kesamaan semantik, dan mendeteksi pencilan teks. Ketika masalah bisnis diselesaikan secara real time, tidak ada cara lain.
Solusi kami melibatkan merepresentasikan setiap baris dalam vektor berdimensi rendah dan secara opsional "menyempurnakan" atau memperbarui model sematan secara bersamaan, menetapkannya ke cluster, dan menentukan garis dalam cluster berbeda sebagai "berbeda". Pencirian lokasi- algoritma probabilistik yang memungkinkan Anda menetapkan cluster dalam waktu yang konstan dan mencari tetangga terdekat dalam waktu yang hampir konstan.
LSH bekerja dengan memetakan representasi vektor ke sekumpulan skalar. Algoritme hashing standar cenderung menghindari benturan antara dua input yang cocok. LSH berusaha menghindari tabrakan jika input berjauhan dan mempromosikannya jika berbeda tetapi berdekatan dalam ruang vektor.
Vektor yang mewakili frase "kesalahan masuk, periksa kesalahan" dapat dicocokkan dengan angka biner
01. Kemudian01mewakili sebuah cluster. Vektor "otentikasi masalah" dengan probabilitas tinggi juga dapat ditampilkan pada 01. Jadi LSH memberikan perbandingan fuzzy dan memecahkan masalah invers - perbedaan fuzzy. Aplikasi awal LSH berada di atas ruang vektor multidimensi dari sekumpulan kata. Kami tidak dapat memikirkan satu alasan mengapa dia tidak akan bekerja dengan ruang representasi vektor kata. Ada indikasi bahwa orang lain berpikiran sama .

Gambar di atas menunjukkan penggunaan LSH saat menempatkan karakter dalam grup yang sama, tetapi terbalik.
Pekerjaan yang telah kami lakukan untuk menerapkan LSH dan cutaway vektor dengan mendeteksi pencilan teks di log build sekarang memungkinkan insinyur untuk melihat sebagian kecil dari baris log untuk mengidentifikasi dan memperbaiki potensi kesalahan kritis bisnis. Ini juga memungkinkan Anda mencapai pengelompokan semantik dari hampir semua baris log secara real time.
Pendekatan ini sekarang berfungsi di setiap build Netflix. Bagian semantik memungkinkan Anda mengelompokkan item yang tampaknya berbeda berdasarkan artinya dan menampilkan item tersebut dalam laporan emisi.
Beberapa contoh
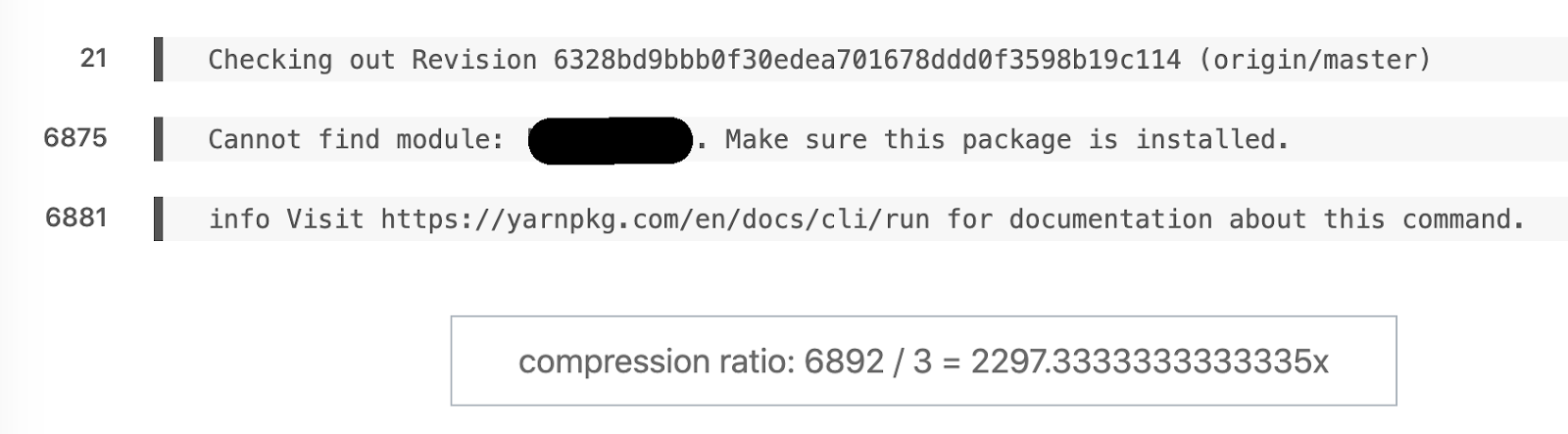
Contoh favorit dari diff semantik. 6892 baris berubah menjadi 3.
Contoh lain: perakitan ini mencatat 6044 baris, tetapi 171 tetap ada dalam laporan Masalah utama muncul hampir seketika pada baris 4036.

Tentu saja, lebih cepat untuk mengurai 171 baris daripada 6044. Tetapi bagaimana kita mendapatkan log perakitan yang besar? Beberapa dari ribuan tugas pembuatan yang merupakan uji tekanan untuk elektronik konsumen dilakukan dalam mode jejak. Sulit untuk bekerja dengan volume data seperti itu tanpa pemrosesan awal.

Rasio kompresi: 91366/455 = 205,3.
Ada berbagai contoh yang mencerminkan perbedaan semantik antara framework, bahasa, dan skrip build.
Kesimpulan
Kematangan produk pembelajaran transfer sumber terbuka dan SDK telah memungkinkan LSH untuk memecahkan masalah pencarian tetangga terdekat semantik dalam beberapa baris kode. Kami tertarik dengan manfaat khusus yang dibawa oleh pemelajaran transfer dan penyesuaian ke aplikasi. Kami senang dapat memecahkan masalah tersebut dan membantu orang melakukan apa yang mereka lakukan dengan lebih baik dan lebih cepat.
Kami harap Anda mempertimbangkan untuk bergabung dengan Netflix dan menjadi salah satu kolega hebat yang kehidupannya kami permudah dengan pembelajaran mesin. Keterlibatan adalah nilai inti Netflix, dan kami sangat tertarik untuk membentuk perspektif yang berbeda tentang tim teknologi. Oleh karena itu, jika Anda bergerak di bidang analitik, teknik, ilmu data, atau bidang lain dan memiliki latar belakang yang tidak biasa di industri ini, kami akan sangat senang mendengar dari Anda!
Jika Anda memiliki pertanyaan tentang fitur Netflix, silakan hubungi kontributor LinkedIn: Stanislav Kirdey , William High Bagaimana Anda mengatasi masalah pencarian log
?
Cari tahu detail tentang cara mendapatkan profesi profil tinggi dari awal atau Naik Level dalam keterampilan dan gaji dengan mengikuti kursus online SkillFactory:
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
