Artikel ini adalah terjemahan dari salah satu postingan neptune.ai dan menyoroti alat pembelajaran mendalam paling menarik yang disajikan di konferensi pembelajaran mesin ICLR 2020.

Di manakah pembelajaran mendalam lanjutan dibuat dan didiskusikan?
Salah satu tempat utama untuk diskusi Deep Learning adalah ICLR - konferensi deep learning terkemuka yang berlangsung pada 27-30 April 2020. Dengan lebih dari 5.500 peserta dan hampir 700 presentasi dan ceramah, ini adalah sukses besar untuk acara yang sepenuhnya online. Anda dapat menemukan informasi lengkap tentang konferensi di sini , di sini atau di sini .
Pertemuan sosial virtual adalah salah satu sorotan dari ICLR 2020. Penyelenggara memutuskan untuk meluncurkan sebuah proyek yang disebut "Alat dan praktik sumber terbuka dalam penelitian DL yang canggih". Topik ini dipilih karena fakta bahwa toolkit yang sesuai merupakan bagian yang tak terhindarkan dari pekerjaan peneliti deep learning. Kemajuan di daerah ini telah menyebabkan perkembangbiakan ekosistem besar (TensorFlow , PyTorch , MXNet), serta alat bertarget yang lebih kecil yang memenuhi kebutuhan khusus peneliti.
Tujuan dari acara tersebut adalah untuk bertemu dengan pencipta dan pengguna alat open source, serta untuk berbagi pengalaman dan kesan di antara komunitas Deep Learning. Secara total, lebih dari 100 orang dikumpulkan, termasuk para inspirator utama dan pemimpin proyek, yang kami berikan waktu singkat untuk mempresentasikan karya mereka. Peserta dan panitia dikejutkan oleh keragaman dan kreativitas alat dan perpustakaan yang disajikan.
Artikel ini berisi proyek-proyek cemerlang yang disajikan dari panggung virtual.
Alat dan Perpustakaan
Berikut adalah delapan alat yang didemonstrasikan di ICLR dengan gambaran umum kemampuan secara rinci.
Setiap bagian menyajikan jawaban atas sejumlah poin dengan cara yang sangat ringkas:
- Masalah apa yang dipecahkan oleh alat / pustaka?
- Bagaimana cara menjalankan atau membuat kasus penggunaan minimal?
- Sumber daya eksternal untuk mendalami pustaka / alat lebih dalam.
- Profil perwakilan proyek jika ada keinginan untuk menghubungi mereka.
Anda dapat melompat ke bagian tertentu di bawah ini atau cukup telusuri semuanya satu per satu. Selamat membaca!
AmpliGraph
Topik: Model Penyematan Berbasis Grafik Pengetahuan.
Bahasa pemrograman: Python
Oleh: Luca Costabello
Twitter | LinkedIn | GitHub | Grafik Pengetahuan Situs Web
adalah alat serbaguna untuk mewakili sistem yang kompleks. Baik itu jaringan sosial, kumpulan data bioinformatika, atau data pembelian eceran, pemodelan pengetahuan grafik memungkinkan organisasi untuk mengidentifikasi hubungan penting yang seharusnya terlewatkan.
Mengungkap hubungan antar data membutuhkan model pembelajaran mesin khusus yang dirancang khusus untuk bekerja dengan grafik.
AmpliGraphMerupakan sekumpulan model pembelajaran mesin yang dilisensikan oleh Apache2 untuk mengekstrak embeddings dari grafik pengetahuan. Model semacam itu menyandikan simpul dan tepi grafik dalam bentuk vektor dan menggabungkannya untuk memprediksi fakta yang hilang. Penyematan grafik digunakan dalam tugas-tugas seperti bagian atas grafik pengetahuan, penemuan pengetahuan, pengelompokan berbasis tautan, dan lain-lain.
AmpliGraph menurunkan penghalang untuk masuk ke topik penyematan grafik bagi peneliti dengan membuat model ini tersedia untuk pengguna yang tidak berpengalaman. Dengan memanfaatkan API sumber terbuka, proyek ini mendukung komunitas penggemar menggunakan grafik dalam pembelajaran mesin. Proyek ini memungkinkan Anda mempelajari cara membuat dan memvisualisasikan embeddings dari grafik pengetahuan berdasarkan data dunia nyata dan cara menggunakannya dalam tugas machine learning berikutnya.
Untuk memulai, di bawah ini adalah potongan kode minimal yang melatih model di salah satu set data referensi dan memprediksi link yang hilang:


AmpliGraph awalnya dikembangkan di Accenture Labs Dublin , di mana ia digunakan dalam berbagai proyek industri.
Automunge
Platform persiapan data tabular
Bahasa pemrograman: Python
Diposting oleh Nicholas Teague
Twitter | LinkedIn | GitHub | Situs
AutomungeAdalah pustaka Python untuk membantu menyiapkan data tabular untuk digunakan dalam pembelajaran mesin. Melalui toolkit paket, transformasi sederhana untuk pembuatan fitur dimungkinkan untuk menormalkan, menyandikan, dan mengisi celah. Transformasi diterapkan ke sub sampel pelatihan dan kemudian diterapkan dengan cara yang mirip dengan data dari sub sampel pengujian. Konversi dapat dilakukan secara otomatis, ditetapkan dari perpustakaan internal, atau dikonfigurasi secara fleksibel oleh pengguna. Opsi populasi mencakup "pengisian berbasis pembelajaran mesin", di mana model dilatih untuk memprediksi informasi yang hilang untuk setiap kolom data.
Sederhananya:
automunge (.) Menyiapkan data tabel untuk digunakan dalam pembelajaran mesin,
postmunge (.)data tambahan diproses secara berurutan dan dengan efisiensi tinggi.
Automunge tersedia untuk instalasi melalui pip:

Setelah penginstalan, cukup impor pustaka ke dalam Notebook Jupyter untuk inisialisasi:

Untuk secara otomatis memproses data dari sampel pelatihan dengan parameter default, cukup menggunakan perintah:

Selanjutnya, untuk pemrosesan data selanjutnya dari subset pengujian, cukup dengan menjalankan perintah menggunakan kamus postprocess_dict, diperoleh dengan memanggil automunge (.) Di atas:

Parameter assigncat dan assigninfill di panggilan automunge (.) Dapat digunakan untuk menentukan detail konversi dan tipe data untuk mengisi celah. Misalnya, kumpulan data dengan kolom 'kolom1' dan 'kolom2' dapat diberi penskalaan berdasarkan nilai minimum dan maksimum ('mnmx') dengan padding ML untuk kolom1 dan enkode one-hot ('teks') dengan padding berdasarkan nilai paling umum untuk kolom2. Data dari kolom lain yang tidak ditentukan secara eksplisit akan diproses secara otomatis.

Sumber dan Link
Situs | GitHub | Presentasi singkat
DynaML
Pembelajaran Mesin untuk
Pemrograman Scala Bahasa: Scala
Diposting oleh: Mandar Chandorkar
Twitter | LinkedIn | GitHub
DynaML adalah kotak peralatan penelitian dan pembelajaran mesin berbasis Scala. Ini bertujuan untuk menyediakan lingkungan ujung ke ujung yang dapat membantu pengguna dalam:
- pengembangan / pembuatan prototipe model,
- bekerja dengan jaringan pipa yang besar dan kompleks,
- visualisasi data dan hasil,
- penggunaan kembali kode dalam bentuk skrip dan Notes.
DynaML memanfaatkan kekuatan bahasa dan ekosistem Scala untuk menciptakan lingkungan yang memberikan kinerja dan fleksibilitas. Ini didasarkan pada proyek luar biasa seperti Ammonite scala, Tensorflow-Scala, dan pustaka komputasi numerik kinerja tinggi Breeze .
Komponen utama DynaML adalah REPL / wrapper, yang memiliki penyorotan sintaks dan sistem pelengkapan otomatis tingkat lanjut.
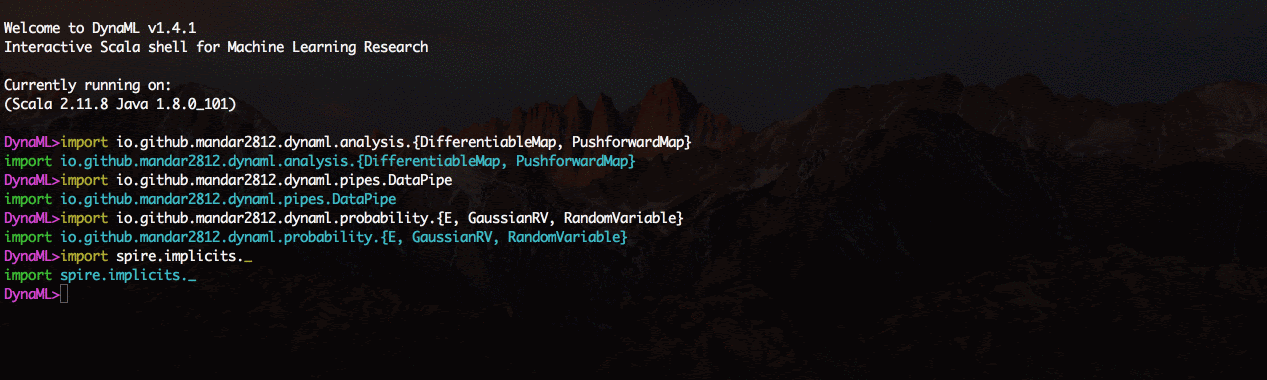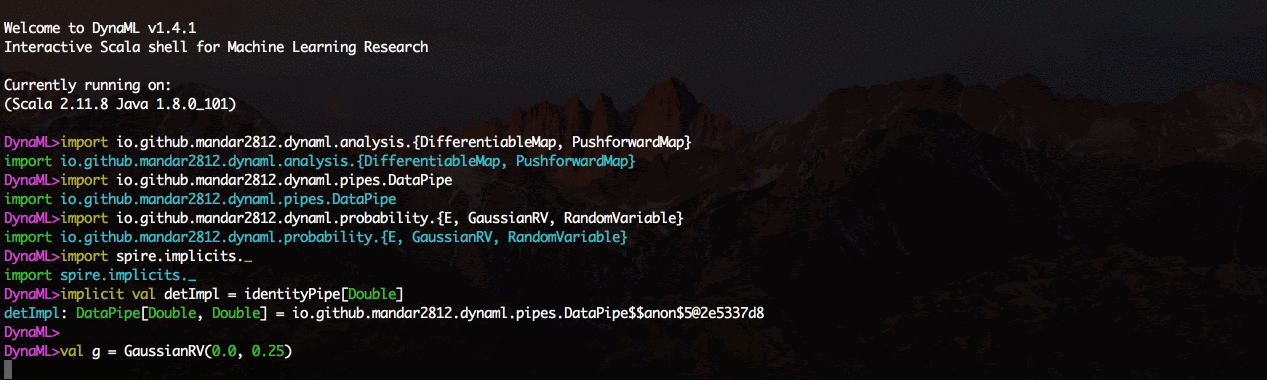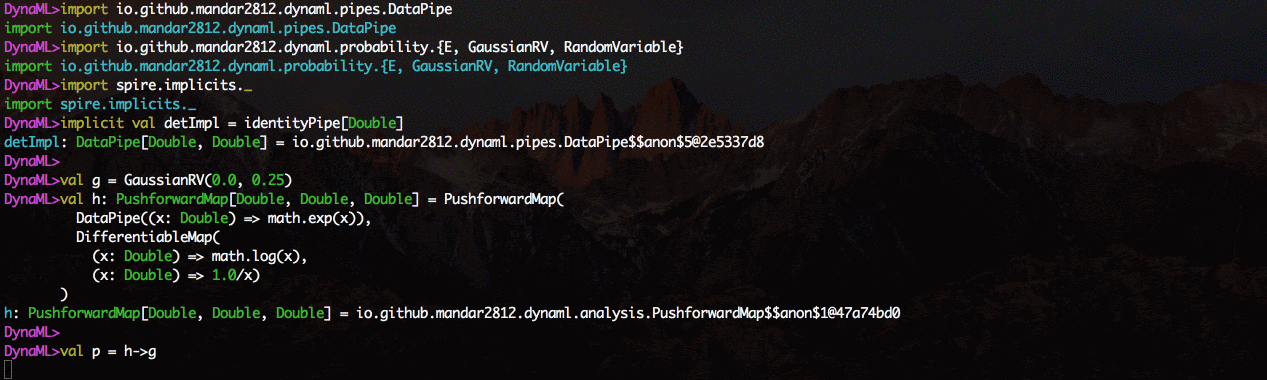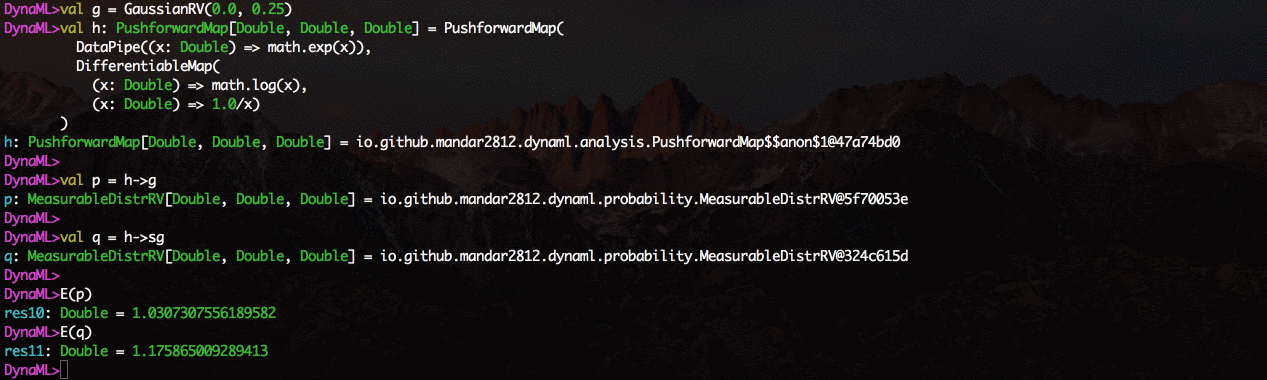
Lingkungan hadir dengan dukungan untuk visualisasi 2D dan 3D, hasilnya dapat ditampilkan langsung dari shell perintah.

Modul data pipe memudahkan pembuatan pipeline pemrosesan data dalam mode modular yang ramah tata letak. Membuat fungsi, membungkusnya menggunakan konstruktor DataPipe, dan membuat blok fungsi menggunakan operator>.
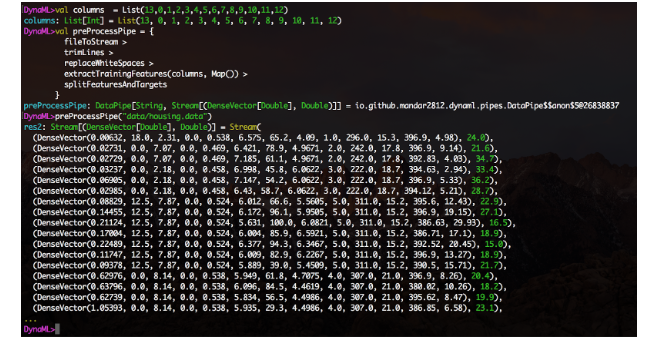
Fitur integrasi notebook Jupyter eksperimental juga tersedia, dan direktori notebook repositori berisi beberapa contoh penggunaan inti DynaML-Scala Jupyter.

Panduan Pengguna berisi referensi dan dokumentasi lengkap untuk membantu Anda menguasai dan mendapatkan hasil maksimal dari lingkungan DynaML.
Berikut adalah beberapa aplikasi menarik yang menonjolkan kelebihan DynaML:
- fisika mengilhami jaringan saraf untuk menyelesaikan persamaan Burger dan sistem Fokker-Planck ,
- Pelatihan Deep Learning,
- Model proses Gaussian untuk peramalan deret waktu autoregresif.
Sumber dan Tautan
GitHub | Panduan pengguna
Ular naga
Manajer konfigurasi dan parameter
Bahasa pemrograman: Python
Diposting oleh Omry Yadan
Twitter | GitHub
Dikembangkan oleh Facebook AI, Hydra adalah platform Python yang menyederhanakan pengembangan aplikasi penelitian dengan menyediakan kemampuan untuk membuat dan mengganti konfigurasi menggunakan file config dan baris perintah. Platform ini juga menyediakan dukungan untuk perluasan parameter otomatis, eksekusi jarak jauh dan paralel melalui plugin, manajemen direktori kerja otomatis, dan secara dinamis menyarankan opsi add-on dengan menekan tombol TAB.
Menggunakan Hydra juga membuat kode Anda lebih portabel di berbagai lingkungan pembelajaran mesin. Memungkinkan Anda beralih antara workstation pribadi, kluster publik dan pribadi tanpa mengubah kode Anda. Hal di atas dicapai melalui arsitektur modular.
Contoh Dasar Contoh
ini menggunakan konfigurasi database, tetapi Anda dapat dengan mudah menggantinya dengan model, dataset, atau apa pun yang Anda butuhkan.
config.yaml:

my_app.py:

Anda dapat mengganti apa pun dalam konfigurasi dari baris perintah:

Contoh komposisi:
Anda mungkin ingin beralih di antara dua konfigurasi database yang berbeda.
Buat struktur direktori ini:

config.yaml:
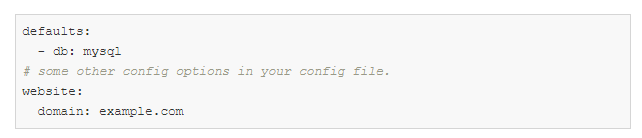
defaults adalah arahan khusus yang memberitahu Hydra untuk menggunakan db / mysql.yaml saat membuat objek konfigurasi.
Sekarang Anda dapat memilih konfigurasi database mana yang akan digunakan, serta mengganti nilai parameter dari baris perintah:

Lihat tutorial untuk mengetahui lebih lanjut.
Selain itu, fitur menarik baru akan segera hadir:
- konfigurasi yang sangat diketik (file konfigurasi terstruktur),
- pengoptimalan hyperparameter menggunakan plugin Ax dan Nevergrad,
- meluncurkan AWS menggunakan plugin peluncur Ray,
- peluncuran paralel lokal melalui plugin joblib dan banyak lagi.
Larq
Jaringan Syaraf Tiruan Binarized
Bahasa pemrograman: Python
Diposting oleh: Lucas Geiger
Twitter | LinkedIn | GitHub
Larq adalah ekosistem paket Python open source untuk membangun, melatih, dan menerapkan jaringan neural binarisasi (BNN). BNN adalah model pembelajaran mendalam di mana aktivasi dan bobot tidak dikodekan menggunakan 32, 16, atau 8 bit, tetapi hanya menggunakan 1 bit. Ini secara dramatis dapat mempercepat waktu inferensi dan mengurangi konsumsi daya, menjadikan BNN ideal untuk aplikasi seluler dan periferal.
Ekosistem open source Larq memiliki tiga komponen utama.
- Larq — , . API, TensorFlow Keras. . Larq BNNs, .
- Larq Zoo BNNs, . Larq Zoo , BNN .
- Larq Compute Engine — BNNs. TensorFlow Lite MLIR Larq FlatBuffer, TF Lite. ARM64, , Android Raspberry Pi, , , BNN.
Penulis proyek terus-menerus membuat model yang lebih cepat dan memperluas ekosistem Larq ke platform perangkat keras baru dan aplikasi pembelajaran mendalam. Misalnya, pekerjaan sedang dilakukan untuk mengintegrasikan kuantisasi 8-bit ujung ke ujung agar dapat melatih dan menerapkan kombinasi jaringan biner dan 8-bit menggunakan Larq.
Sumber Daya dan Tautan
Situs | GitHub larq / larq | GitHub larq / kebun binatang | GitHub larq / mesin-komputasi | Buku teks | Blog | Indonesia
McKernel
Metode Kernel dalam Waktu Linear Logaritma
Bahasa pemrograman: C / C ++
Diposting oleh: J. de Curtó i Díaz
Twitter | Situs Web
Pustaka C ++ open source pertama yang menyediakan pendekatan fitur acak dari metode kernel dan kerangka kerja Deep Learning yang lengkap.
McKernel menyediakan empat kegunaan berbeda.
- Kode Hadamard sumber terbuka secepat kilat yang mandiri. Untuk digunakan di area seperti kompresi, enkripsi, atau komputasi kuantum.
- Teknik nuklir yang sangat cepat. Dapat digunakan di mana pun metode SVM (Metode Vektor Dukungan: ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0 % BE% D1% 80% D0% BD% D1% 8B% D1% 85_% D0% B2% D0% B5% D0% BA% D1% 82% D0% BE% D1% 80% D0% BE% D0% B2 ) lebih unggul dari Pembelajaran Mendalam. Misalnya, beberapa aplikasi robotika dan beberapa kasus penggunaan machine learning dalam perawatan kesehatan dan area lainnya termasuk Federated Learning dan pemilihan saluran.
- Integrasi Pembelajaran Mendalam dan metode nuklir memungkinkan pengembangan arsitektur Pembelajaran Mendalam ke arah antropomorfik / matematika apriori.
- Kerangka penelitian Pembelajaran Mendalam untuk memecahkan sejumlah pertanyaan terbuka dalam pembelajaran mesin.
Persamaan yang menggambarkan semua perhitungan terlihat seperti ini:

Disini penulis sebagai pelopor formalisme digunakan untuk menjelaskan dengan menggunakan gejala acak seperti metode Deep Learning , dan teknik nuklir . Basis teoritis didasarkan pada empat raksasa: Gauss, Wiener, Fourier dan Kalman. Fondasi untuk ini diletakkan oleh Rahimi dan Rekht (NIPS 2007) dan Le et al. (ICML 2013).
Menargetkan pengguna biasa
Audiens utama McKernel adalah peneliti dan praktisi di bidang robotika, pembelajaran mesin untuk perawatan kesehatan, pemrosesan sinyal, dan komunikasi yang perlu diimplementasikan secara efisien dan cepat di C ++. Dalam hal ini, sebagian besar pustaka Pembelajaran Dalam tidak memenuhi ketentuan yang diberikan, karena sebagian besar didasarkan pada implementasi Python tingkat tinggi. Selain itu, audiens mungkin merupakan perwakilan dari komunitas pembelajaran mesin dan Pembelajaran Mendalam yang lebih luas, yang sedang mencari cara untuk meningkatkan arsitektur jaringan saraf menggunakan metode nuklir.
Contoh visual super sederhana untuk menjalankan perpustakaan tanpa menghabiskan waktu terlihat seperti ini:

Apa berikutnya?
Pembelajaran End-to-End, Pembelajaran yang Diawasi Sendiri, Pembelajaran Meta, Integrasi dengan Strategi Evolusioner, Secara Signifikan Mengurangi Ruang Pencarian dengan NAS, ...
Sumber Daya, dan Tautan
GitHub | Presentasi lengkap
Mesin Pelatihan SCCH
Otomatisasi rutinitas untuk Deep Learning
Bahasa Pemrograman: Python
Diposting oleh: Natalya Shepeleva
Twitter | LinkedIn | Pembuatan Situs Web
dengan pipeline Deep Learning yang khas cukup standar: pemrosesan awal data, desain / implementasi tugas, pelatihan model, dan evaluasi hasil. Namun demikian, dari proyek ke proyek, penggunaannya membutuhkan partisipasi seorang insinyur di setiap tahap pengembangan, yang mengarah pada pengulangan tindakan yang sama, duplikasi kode dan, pada akhirnya, menyebabkan kesalahan.
Sasaran Mesin Pelatihan SCCH adalah menyatukan dan mengotomatiskan proses pengembangan Pembelajaran Mendalam untuk dua framework paling populer PyTorch dan TensorFlow. Arsitektur single-entry meminimalkan waktu pengembangan dan melindungi dari bug.
Untuk siapa?
Arsitektur fleksibel Mesin Pelatihan SCCH memiliki dua tingkat pengalaman pengguna.
Utama. Pada level ini, pengguna harus menyediakan data untuk pelatihan dan menulis parameter pelatihan model di file konfigurasi. Setelah itu, semua proses, termasuk pemrosesan data, pelatihan model, dan validasi hasil, akan dilakukan secara otomatis. Hasilnya, model yang terlatih akan diperoleh dalam salah satu framework utama.
Maju.Berkat konsep komponen modular, pengguna dapat memodifikasi modul sesuai dengan kebutuhan mereka, menerapkan model mereka sendiri dan menggunakan berbagai fungsi kerugian dan metrik kualitas. Arsitektur modular ini memungkinkan Anda menambahkan fitur tambahan tanpa mengganggu pengoperasian pipeline utama.
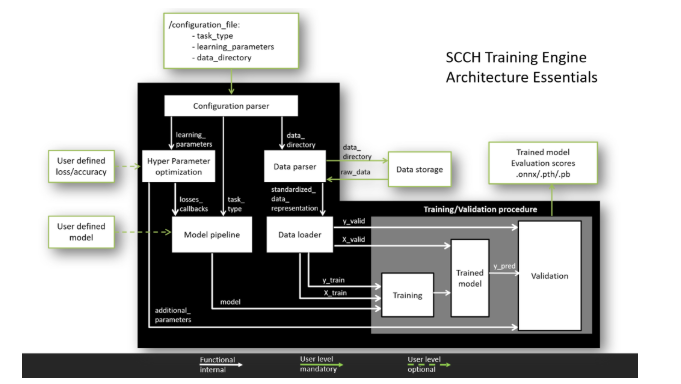
Apa yang dapat dia lakukan?
Kemampuan saat ini:
- bekerja dengan TensorFlow dan PyTorch,
- pipeline standar untuk mem-parsing data dari berbagai format,
- pipeline standar untuk pelatihan model dan validasi hasil,
- dukungan untuk klasifikasi, segmentasi dan tugas deteksi,
- dukungan validasi silang.
Fitur dalam pengembangan:
- mencari hyperparameter model yang optimal,
- memuat bobot model dan pelatihan dari titik kontrol tertentu,
- Dukungan arsitektur GAN.
Bagaimana itu bekerja?
Untuk melihat Mesin Pelatihan SCCH dalam segala kemegahannya, Anda perlu mengambil dua langkah.
- Cukup salin repositori dan instal paket yang diperlukan menggunakan perintah: pip install requirement.txt.
- Jalankan python main.py untuk melihat studi kasus MNIST dengan pemrosesan dan pelatihan pada model LeNet-5.
Semua informasi tentang cara membuat file konfigurasi dan cara menggunakan fitur lanjutan dapat ditemukan di halaman GitHub .
Rilis stabil dengan fitur inti: dijadwalkan pada akhir Mei 2020.
Sumber Daya dan Tautan
GitHub | Situs web
Tokenizer
Tokenizers teks
Bahasa pemrograman: Rust dengan Python API
Diposting oleh: Anthony Mua
Twitter | LinkedIn | Huggingface / tokenizers GitHub menyediakan akses ke tokenizer paling modern, dengan fokus pada kinerja dan penggunaan multiguna. Tokenizer memungkinkan Anda untuk melatih dan menggunakan tokenizer dengan mudah. Tokenizer dapat membantu Anda terlepas dari apakah Anda seorang sarjana atau praktisi di bidang NLP. Fitur utama
- Kecepatan ekstrem: Tokenisasi tidak boleh menjadi penghambat dalam pipeline Anda, dan Anda tidak perlu memproses data Anda sebelumnya. Berkat implementasi Rust asli, tokenisasi gigabyte teks hanya membutuhkan beberapa detik.
- Offsets / Alignment: Memberikan kontrol offset bahkan saat memproses teks dengan prosedur normalisasi yang kompleks. Ini memudahkan untuk mengekstrak teks untuk tugas-tugas seperti NER atau menjawab pertanyaan.
- Pra-pemrosesan: menangani semua pemrosesan awal yang diperlukan sebelum memasukkan data ke dalam model bahasa Anda (memotong, mengisi, menambahkan token khusus, dll.).
- Kemudahan Belajar: Latih tokenizer apa pun pada sasis baru. Misalnya, mempelajari tokenizer untuk BERT dalam bahasa baru tidak pernah semudah ini.
- Multi-bahasa: satu paket dengan banyak bahasa. Anda dapat mulai menggunakannya sekarang dengan Python, Node.js, atau Rust. Bekerja ke arah ini terus berlanjut!
Contoh:

Dan seterusnya:
- serialisasi ke satu file dan memuat dalam satu baris untuk tokenizer apa pun,
- Dukungan Unigram.
Hugging Face melihat misi mereka sebagai membantu mempromosikan dan mendemokratisasi NLP. GitHub
Resources and Links
huggingface / transformer | GitHub huggingface / tokenizers | Indonesia
Kesimpulan
Sebagai kesimpulan, perlu dicatat bahwa ada banyak library yang berguna untuk Deep Learning dan machine learning secara umum, dan tidak ada cara untuk mendeskripsikan semuanya dalam satu artikel. Beberapa proyek yang dijelaskan di atas akan berguna dalam kasus-kasus tertentu, beberapa sudah terkenal, dan beberapa proyek luar biasa, sayangnya, tidak berhasil dimasukkan ke dalam artikel.
Kami di CleverDATA berusaha untuk terus mengikuti alat baru dan pustaka yang berguna, dan secara aktif menerapkan pendekatan baru dalam pekerjaan kami terkait dengan penggunaan Pembelajaran Mendalam dan Pembelajaran Mesin. Bagi saya, saya ingin menarik perhatian pembaca ke dua perpustakaan ini yang tidak termasuk dalam artikel utama, tetapi sangat membantu dalam bekerja dengan jaringan saraf: Catalyst (https://catalyst-team.com ) dan Albumentation ( https://albumentations.ai/ ).
Saya yakin bahwa setiap ahli praktik memiliki alat dan perpustakaan favoritnya sendiri, termasuk yang tidak banyak diketahui khalayak luas. Jika menurut Anda ada alat yang berguna dalam pekerjaan Anda telah diabaikan secara tidak perlu, silakan tulis di komentar: bahkan menyebutkannya dalam diskusi akan membantu proyek yang menjanjikan untuk menarik pengikut baru, dan peningkatan popularitas, pada gilirannya, mengarah pada peningkatan fungsionalitas dan pengembangan diri mereka sendiri perpustakaan.
Terima kasih atas perhatiannya dan semoga kumpulan perpustakaan yang disajikan bermanfaat dalam pekerjaan Anda!