Kisah yang dideskripsikan bukanlah sebuah fantasi, melainkan deskripsi kolektif dari beberapa peristiwa di tahun 2020. Di perusahaan besar, rencana pemulihan bencana (DRP) selalu tersedia untuk kasus ini. Di perusahaan, spesialis kelangsungan bisnis bertanggung jawab untuk ini. Namun di perusahaan menengah dan kecil, solusi untuk masalah tersebut berada di departemen TI. Anda perlu memahami logika bisnis sendiri, memahami apa yang bisa jatuh dan di mana, muncul dengan perlindungan dan penerapan.
Sangat bagus jika profesional TI berhasil bernegosiasi dengan bisnis dan mendiskusikan kebutuhan akan perlindungan. Tetapi saya telah melihat lebih dari sekali bagaimana perusahaan menghemat solusi pemulihan bencana (DR), karena dianggap mubazir. Ketika terjadi kecelakaan, pemulihan yang lama terancam kerugian, dan bisnis belum siap. Anda dapat mengulangi sebanyak yang Anda suka: "Tapi saya sudah bilang" - layanan TI masih harus memulihkan layanan.

Dari sudut pandang seorang arsitek, saya akan memberi tahu Anda bagaimana menghindari situasi ini. Pada bagian pertama artikel saya akan menunjukkan pekerjaan persiapan: bagaimana mendiskusikan tiga pertanyaan dengan pelanggan untuk memilih alat perlindungan:
- Apa yang kita lindungi?
- Dari apa kita melindungi?
- Seberapa kuat kita melindungi?
Pada bagian kedua, kita akan berbicara tentang opsi untuk menjawab pertanyaan: dengan apa mempertahankan. Saya akan memberikan contoh kasus bagaimana pelanggan yang berbeda membangun perlindungan mereka.
Yang kami lindungi: mengklarifikasi fungsi bisnis penting
Yang terbaik adalah memulai persiapan dengan mendiskusikan rencana bencana dengan pelanggan bisnis. Kesulitan utama di sini adalah menemukan bahasa yang sama. Pelanggan biasanya tidak peduli bagaimana solusi TI bekerja. Dia peduli jika layanan tersebut dapat menjalankan fungsi bisnis dan menghasilkan uang. Misalnya: jika situs berfungsi, dan sistem pembayaran "bohong", tidak ada tanda terima dari pelanggan, dan yang "ekstrem" tetaplah spesialis IT.
Seorang profesional TI mungkin merasa kesulitan untuk bernegosiasi karena beberapa alasan:
- Layanan TI tidak sepenuhnya menyadari peran sistem informasi dalam bisnis. Misalnya, jika tidak ada deskripsi proses bisnis atau model bisnis transparan.
- Tidak seluruh proses bergantung pada departemen TI. Misalnya, ketika beberapa pekerjaan dilakukan oleh kontraktor, dan spesialis TI tidak memiliki pengaruh langsung pada mereka.
Saya akan menyusun percakapan seperti ini:
- Kami menjelaskan kepada bisnis bahwa kecelakaan terjadi pada semua orang, dan pemulihan membutuhkan waktu. Hal terbaik adalah mendemonstrasikan situasinya, bagaimana hal itu terjadi, dan konsekuensi apa yang mungkin terjadi.
- Kami menunjukkan bahwa tidak semuanya bergantung pada layanan IT, tetapi Anda siap membantu dengan rencana tindakan di area tanggung jawab Anda.
- Kami meminta pelanggan bisnis untuk menjawab: jika kiamat terjadi, proses mana yang harus dipulihkan terlebih dahulu? Siapa yang berpartisipasi di dalamnya dan bagaimana?
Bisnis membutuhkan jawaban sederhana, misalnya: call center harus terus mendaftarkan permintaan 24/7.
- - .
, .
: - , . 1 -, .
- , . :
- ( ),
- , ( ),
- ( ).
- ( ),
- Kami menemukan titik-titik kegagalan yang mungkin: titik-titik sistem di mana kinerja layanan bergantung. Secara terpisah, kami menandai node yang didukung oleh perusahaan lain: operator telekomunikasi, penyedia hosting, pusat data, dan sebagainya. Dengan ini, Anda dapat kembali ke pelanggan bisnis untuk langkah selanjutnya.
Apa yang kami lindungi dari: risiko
Kemudian kami mencari tahu dari pelanggan bisnis risiko apa yang kami lindungi sejak awal. Kami akan membagi semua risiko secara kondisional menjadi dua kelompok:
- kehilangan waktu karena downtime layanan;
- kehilangan data karena dampak fisik, faktor manusia, dll.
Bisnis takut kehilangan data dan waktu - semua ini menyebabkan hilangnya uang. Jadi sekali lagi kami mengajukan pertanyaan tentang setiap kelompok risiko:
- Dapatkah kami memperkirakan untuk proses ini berapa banyak kehilangan data dan waktu yang terbuang percuma?
- Data apa yang tidak bisa kita hilangkan?
- Di mana kami tidak mengizinkan downtime?
- Peristiwa apa yang paling mungkin dan lebih mengancam kita?
Setelah berdiskusi, kita akan memahami bagaimana memprioritaskan poin-poin kegagalan.
Seberapa kuat kami melindungi: RPO dan RTO
Ketika titik kritis kegagalan dipahami, kami menghitung metrik RTO dan RPO.
Izinkan saya mengingatkan Anda bahwa RTO (tujuan waktu pemulihan) adalah waktu yang diizinkan dari saat kecelakaan hingga pemulihan layanan sepenuhnya. Dalam bahasa bisnis, ini adalah waktu henti yang dapat diterima. Jika kita tahu berapa banyak uang yang dihasilkan dari proses tersebut, maka kita dapat menghitung kerugian dari setiap menit waktu henti dan menghitung kerugian yang diperbolehkan.
RPO (tujuan titik pemulihan) adalah titik pemulihan data yang valid. Ini menentukan waktu di mana kita bisa kehilangan data. Dari perspektif bisnis, kehilangan data dapat menyebabkan, misalnya, denda. Kerugian semacam itu juga bisa diubah menjadi uang.
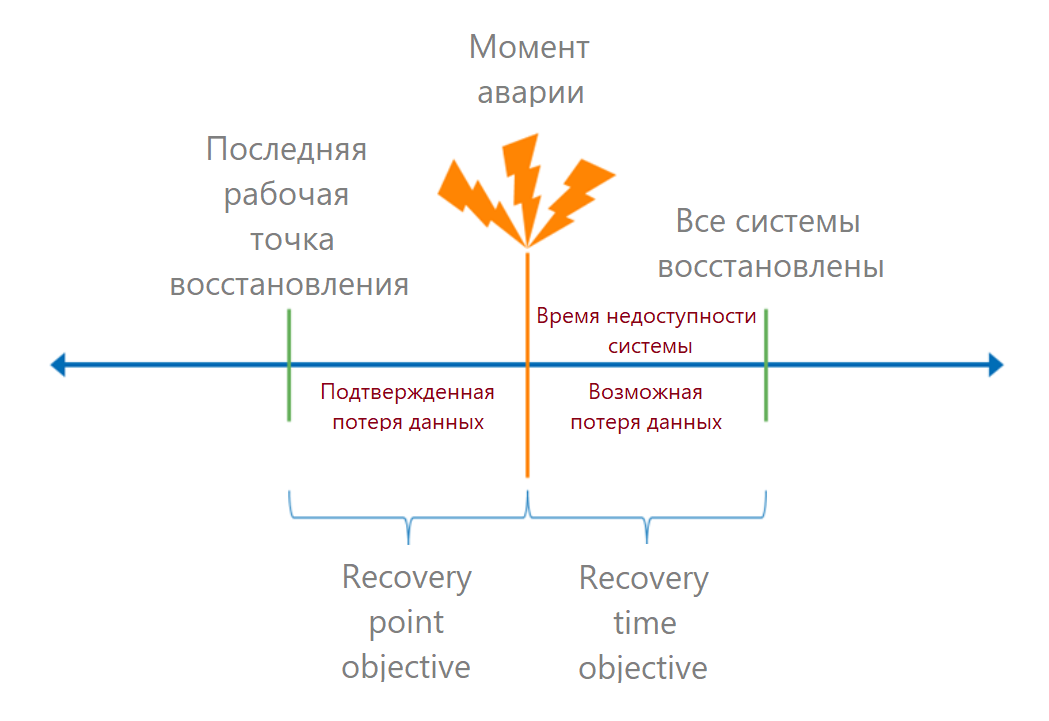
Waktu pemulihan harus dihitung untuk pengguna akhir: berapa lama waktu yang dibutuhkan untuk masuk ke sistem. Jadi pertama-tama kami menambahkan waktu pemulihan semua tautan dalam rantai. Di sini mereka sering membuat kesalahan: mereka mengambil RTO penyedia dari SLA, dan melupakan persyaratan lainnya.
Mari kita lihat contoh spesifiknya. Pengguna memasuki 1C, sistem terbuka dengan kesalahan database. Dia menghubungi administrator sistem. Basisnya ada di cloud, sysadmin melaporkan masalah tersebut ke penyedia layanan. Katakanlah semua komunikasi membutuhkan waktu 15 menit. Di awan, database sebesar ini akan dipulihkan dari cadangan dalam satu jam, oleh karena itu, RTO di sisi penyedia layanan - satu jam. Tetapi ini bukan tenggat waktu terakhir, karena pengguna ditambahkan 15 menit untuk mendeteksi masalah.Perhitungan ini akan menunjukkan bisnis pada faktor eksternal apa yang bergantung pada periode pemulihan. Misalnya, jika kantor kebanjiran, maka pertama-tama Anda perlu mendeteksi kebocoran dan memperbaikinya. Ini akan memakan waktu yang tidak bergantung pada TI.
Selanjutnya, administrator sistem perlu memeriksa apakah database sudah benar, menghubungkannya ke 1C, dan memulai layanan. Butuh waktu satu jam lagi, artinya RTO di sisi administrator sudah 2 jam 15 menit. Pengguna membutuhkan 15 menit lagi: masuk, periksa apakah transaksi yang diperlukan telah muncul. 2 jam 30 menit adalah waktu pemulihan total untuk layanan dalam contoh ini.
Cara kami melindungi: memilih alat untuk berbagai risiko
Setelah membahas semua poin, pelanggan sudah memahami biaya kecelakaan untuk bisnis. Sekarang Anda dapat memilih alat dan mendiskusikan anggaran. Saya akan menunjukkan dengan contoh kasus klien alat apa yang kami tawarkan untuk berbagai tugas.
Mari kita mulai dengan kelompok risiko pertama: kerugian akibat waktu henti layanan. Solusi untuk tugas ini harus memberikan RTO yang baik.
-
— . , , , - .
, . . , 2 . , .
RTO: . .
: .
: , , - .
-
RTO, .
active-passive active-active. , . . , .
RTO: .
: , .
: - . .
: - . . DR , . .
. . -
, , 2 -. - , --. , .
RTO: 0.
: .
: , , .
: . :
- .
- . : «» «». «» , . «» . . .
, . . - .
-
, : . , . DR: VMware vCloud Availability (vCAV). on-premise . vCAV .
RPO RTO: 5 .
: , , . vCAV, , PAYG (10% ).
: 6 . : , — . , .
VMware vCloud Availability. - 5 . , - .
Semua solusi yang dipertimbangkan menyediakan ketersediaan tinggi, tetapi tidak menyelamatkan Anda dari kehilangan data karena virus enkripsi atau kesalahan karyawan yang tidak disengaja. Dalam hal ini, kami memerlukan cadangan yang menyediakan RPO yang diperlukan.
5. Jangan lupa tentang backup
Semua orang tahu bahwa Anda perlu membuat backup, meskipun Anda memiliki solusi pemulihan bencana yang paling keren. Jadi saya hanya akan mengingat beberapa poin.
Sebenarnya, cadangan bukanlah DR. Dan itulah kenapa:
- Butuh waktu lama. Jika data diukur dalam terabyte, perlu waktu lebih dari satu jam untuk memulihkannya. Anda perlu memulihkan, menetapkan jaringan, memeriksa apa yang menyala, melihat bahwa datanya teratur. Jadi Anda hanya dapat mencapai RTO yang baik jika hanya ada sedikit data.
- Data mungkin tidak dipulihkan untuk pertama kalinya, dan Anda perlu memberikan waktu untuk tindakan kedua. Misalnya, ada kalanya kita tidak tahu persis kapan datanya hilang. Misalkan kerugian diperhatikan pada pukul 15.00, dan salinan dibuat setiap jam. Dari pukul 15.00 kami memantau semua titik pemulihan: 14:00, 13:00, dan seterusnya. Jika sistemnya kritis, kami mencoba meminimalkan usia titik pemulihan. Tetapi jika data yang diperlukan tidak ditemukan di cadangan baru, kami mengambil poin berikutnya - ini adalah waktu tambahan.
Dengan demikian, jadwal pencadangan dapat memberikan RPO yang dibutuhkan . Untuk backup, penting untuk menyediakan geo-redundansi jika terjadi masalah dengan situs utama. Anda disarankan untuk menyimpan beberapa cadangan secara terpisah.
Rencana pemulihan bencana terakhir harus memiliki setidaknya 2 alat:
- Salah satu opsi 1-4, yang akan melindungi sistem dari crash dan crash.
- Cadangan untuk melindungi data dari kehilangan.
Sebaiknya juga menjaga saluran komunikasi cadangan jika penyedia Internet utama macet. Dan voila! - DR gaji minimum sudah siap.