Halo! Nama saya Igor Narazin, saya adalah pemimpin tim logistik Klub Pengiriman. Saya ingin memberi tahu Anda bagaimana kami membangun dan mengubah arsitektur kami dan bagaimana hal itu memengaruhi proses pengembangan kami.
Sekarang Delivery Club (serta seluruh pasar foodtech) berkembang sangat pesat, yang menciptakan banyak tantangan bagi tim teknis, yang dapat diringkas dengan dua kriteria terpenting:
- Penting untuk memastikan stabilitas tinggi dan ketersediaan semua bagian platform.
- Pada saat yang sama, pertahankan kecepatan tinggi dalam pengembangan fitur baru.
Tampaknya kedua masalah ini saling eksklusif: kami mengubah platform, mencoba membuat perubahan baru sesedikit mungkin hingga kami menyelesaikannya, atau kami dengan cepat mengembangkan fitur baru tanpa perubahan drastis dalam sistem.
Tapi kami berhasil (sejauh ini) keduanya. Bagaimana kita melakukan ini akan dibahas lebih lanjut.
Pertama, saya akan memberi tahu Anda tentang platform kami : bagaimana kami mengubahnya dengan mempertimbangkan volume data yang terus berkembang, kriteria apa yang kami terapkan pada layanan kami, dan masalah apa yang kami hadapi di sepanjang jalan.
Kedua, saya akan membagikan bagaimana kami menyelesaikan masalah pengiriman fitur tanpa bertentangan dengan perubahan platform dan tanpa degradasi sistem yang tidak perlu .
Mari kita mulai dengan platformnya.
Awalnya ada monolit
Baris pertama kode Delivery Club ditulis 11 tahun yang lalu, dan dalam tradisi terbaik dari genre tersebut, arsitekturnya adalah monolit dalam PHP. Selama 7 tahun itu dipenuhi dengan lebih banyak fungsionalitas sampai menghadapi masalah klasik arsitektur monolitik.
Pada awalnya, kami benar-benar puas dengannya: pemeliharaan, pengujian, dan penerapannya mudah dilakukan. Dan dia mengatasi beban awal tanpa masalah. Namun, seperti yang biasanya terjadi, di beberapa titik kami mencapai tingkat pertumbuhan sedemikian rupa sehingga monolit kami menjadi penghambat yang sangat berbahaya:
- kegagalan atau masalah apa pun dalam monolit akan memengaruhi semua proses kami secara mutlak;
- monolit terikat secara kaku ke tumpukan tertentu yang tidak dapat diubah;
- dengan mempertimbangkan pertumbuhan tim pengembangan, membuat perubahan menjadi sulit: konektivitas komponen yang tinggi tidak memungkinkan pengiriman fitur yang cepat;
- monolit tidak dapat diskalakan secara fleksibel.
Hal ini membawa kami ke arsitektur (kejutan) layanan mikro - banyak yang telah dikatakan dan ditulis tentang kelebihan dan kekurangannya. Hal utama adalah bahwa ini memecahkan salah satu masalah utama kami dan memungkinkan kami untuk mencapai ketersediaan maksimum dan toleransi kesalahan dari seluruh sistem. Saya tidak akan membahas ini di artikel ini, sebagai gantinya saya akan memberi tahu Anda dengan contoh bagaimana kami melakukannya dan mengapa.
Masalah utama kami adalah ukuran basis kode monolit dan buruknya keahlian tim di dalamnya (kami menyebut platform seperti itu - lama). Tentu saja, pada awalnya kami hanya ingin mengambil dan memotong monolit untuk menyelesaikan masalah sepenuhnya. Tetapi kami segera menyadari bahwa itu akan memakan waktu lebih dari satu tahun, dan jumlah perubahan yang dibuat di sana tidak akan pernah memungkinkannya untuk berakhir.
Oleh karena itu, kami pergi ke arah lain: kami membiarkannya apa adanya, dan memutuskan untuk membangun layanan lainnya di sekitar monolit. Ini terus menjadi titik utama dari logika pemrosesan pesanan dan master data, tetapi mulai mengalirkan data untuk layanan lain.
Ekosistem
Seperti yang dikatakan Andrey Evsyukov dalam sebuah artikel tentang tim kami, kami telah menyoroti area utama area domain: Litbang, Logistik, Konsumen, Vendor, Internal, Platform. Di dalam area ini, area domain utama tempat layanan bekerja sudah terkonsentrasi: misalnya, untuk Logistik, ini adalah kurir dan pesanan, dan untuk Penjual - restoran dan posisi.
Selanjutnya, kami perlu naik ke level yang lebih tinggi dan membangun ekosistem layanan kami di sekitar platform: pemrosesan pesanan ada di pusat dan merupakan master data, layanan lainnya dibangun di sekitarnya. Pada saat yang sama, penting bagi kami untuk membuat arah kami otonom: jika satu bagian gagal, sisanya terus berfungsi.
Pada beban rendah, membangun ekosistem yang diperlukan cukup sederhana: proses pemrosesan dan penyimpanan data kami, dan layanan rujukan mengajukan permohonan sesuai kebutuhan.
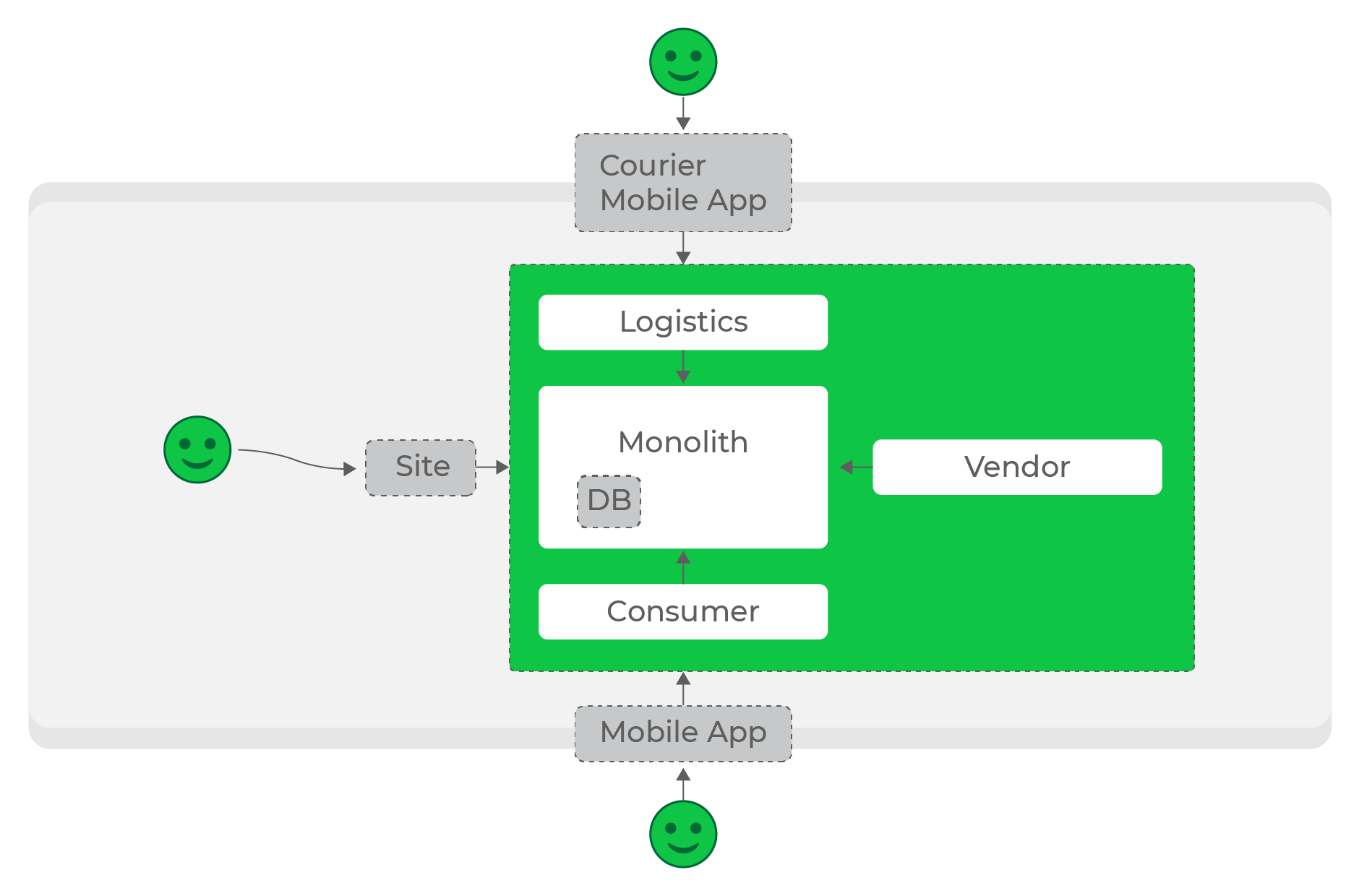 Beban rendah, permintaan sinkron, semuanya berfungsi dengan baik.
Beban rendah, permintaan sinkron, semuanya berfungsi dengan baik.
Pada tahap pertama, kami melakukan hal itu: sebagian besar layanan berkomunikasi satu sama lain dengan permintaan HTTP sinkron. Di bawah beban tertentu, hal ini diperbolehkan, tetapi semakin banyak proyek dan jumlah layanan bertambah, semakin banyak masalah yang terjadi.
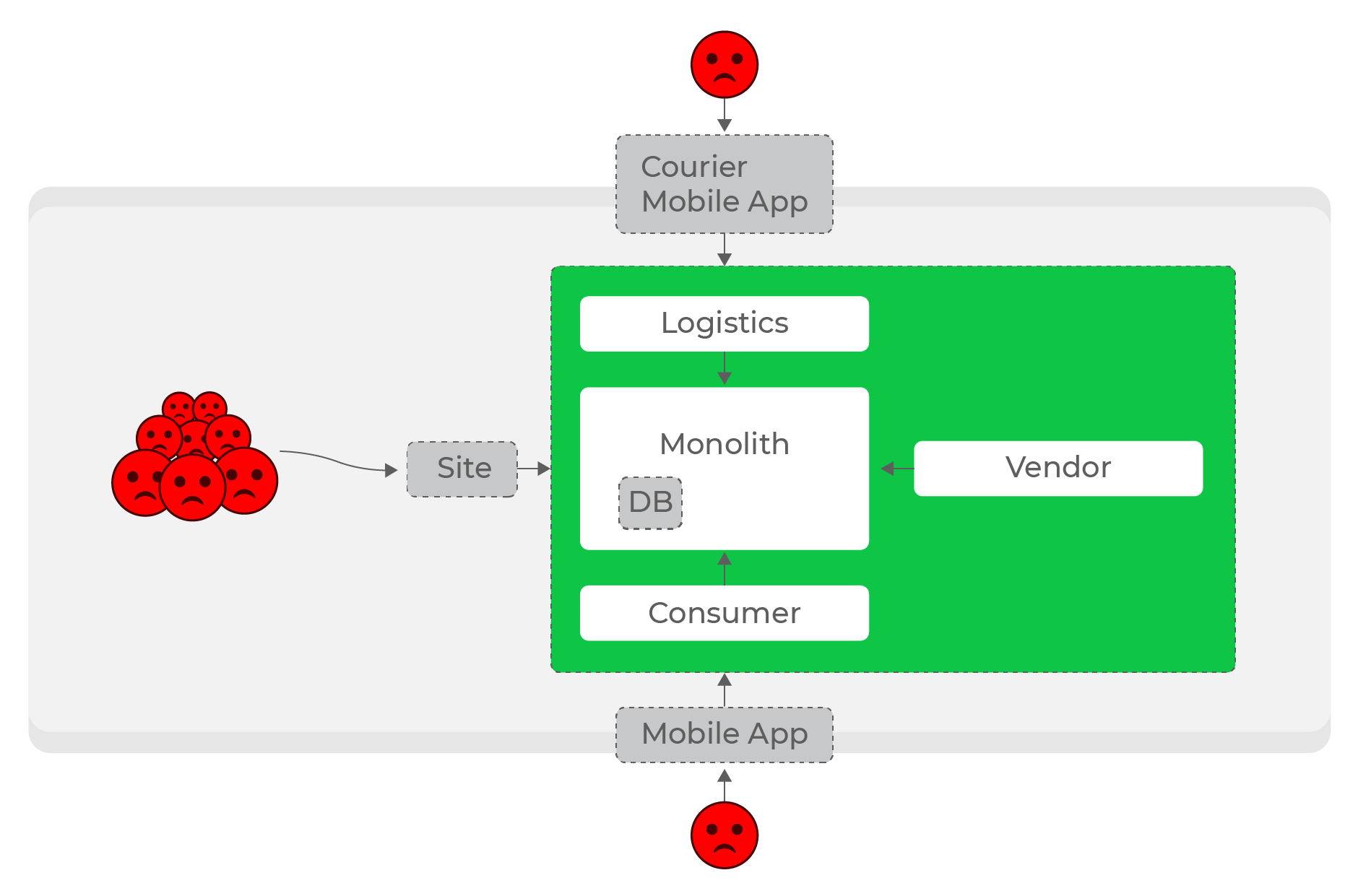
Beban tinggi, permintaan sinkron: semua orang menderita, bahkan pengguna domain yang sama sekali berbeda - kurir.
Bahkan lebih sulit untuk membuat layanan otonom dalam arah: misalnya, peningkatan beban logistik seharusnya tidak mempengaruhi sistem lainnya. Dengan sejumlah permintaan sinkron, ini adalah masalah yang tidak dapat dipecahkan. Jelas, itu perlu untuk meninggalkan permintaan sinkron dan beralih ke komunikasi asinkron.
Bus data
Jadi, kami mendapat banyak kemacetan, saat kami mengakses data dalam mode sinkron. Tempat-tempat ini sangat berbahaya dalam hal peningkatan beban.
Berikut contohnya. Siapapun yang melakukan pemesanan melalui Delivery Club setidaknya sekali mengetahui bahwa setelah kurir mengambil pesanan, kartu akan terlihat. Di atasnya Anda dapat melacak pergerakan kurir secara real time. Beberapa layanan mikro terlibat untuk fitur ini, yang utama adalah:
mobile-gatewayyang merupakan backend untuk frontend untuk aplikasi seluler;courier-trackeryang menyimpan logika penerimaan dan pengiriman koordinat;logistics-couriersyang menyimpan koordinat ini. Mereka dikirim dari aplikasi seluler kurir.
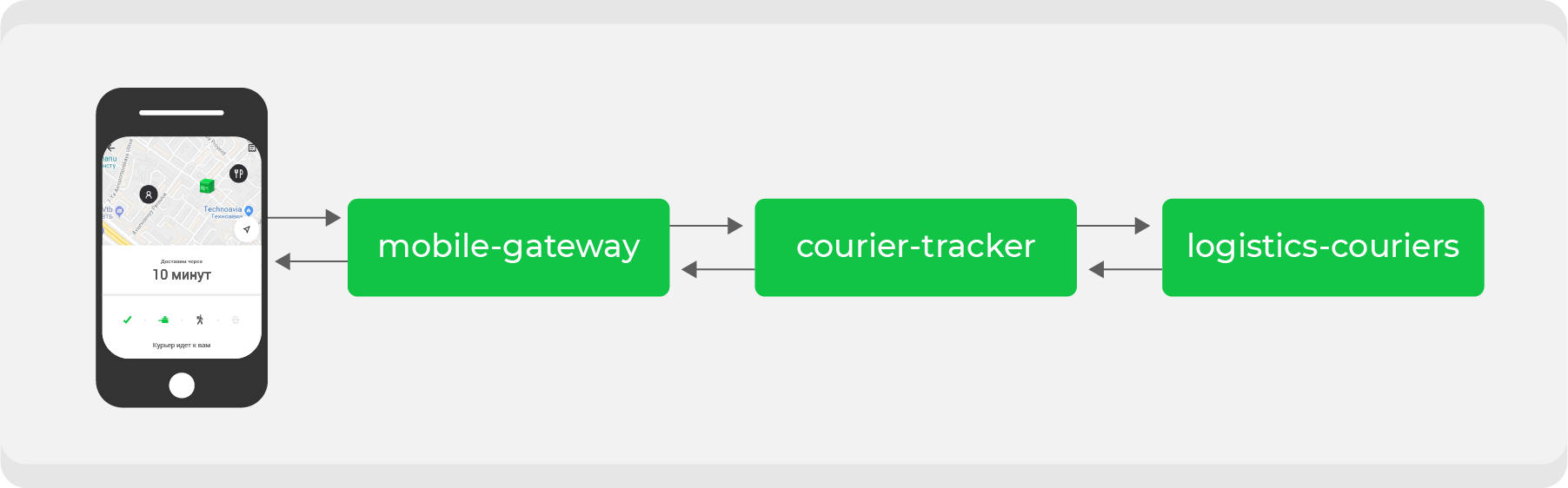
Dalam skema aslinya, ini semua bekerja secara sinkron: permintaan dari aplikasi seluler sekali dalam satu menit melalui
mobile-gatewaylayanan courier-trackeryang mengakses logistics-couriersdan menerima koordinat. Tentu saja, dalam skema ini tidak sesederhana itu, tetapi pada akhirnya semuanya bermuara pada kesimpulan sederhana: semakin banyak pesanan aktif yang kita miliki, semakin banyak permintaan koordinat yang diterima logistics-couriers.
Pertumbuhan kami terkadang tidak dapat diprediksi dan, yang terpenting, cepat - masalah waktu sebelum skema seperti itu gagal. Ini berarti kita perlu mengulangi proses untuk interaksi asinkron: untuk membuat permintaan koordinat semurah mungkin. Untuk melakukan ini, kita perlu mengubah aliran data kita.
Mengangkut
Kami telah menggunakan RabbitMQ, termasuk untuk komunikasi antar layanan. Tetapi sebagai moda transportasi utama, kami memilih alat yang sudah terbukti baik - Apache Kafka. Kami akan menulis artikel terperinci yang terpisah tentang itu, tetapi sekarang saya ingin berbicara secara singkat tentang bagaimana kami menggunakannya.
Ketika kami pertama kali mulai menerapkan Kafka sebagai transportasi, kami menggunakannya dalam bentuk mentah, menghubungkan langsung ke broker dan mengirim pesan kepada mereka. Pendekatan ini memungkinkan kami untuk segera menguji Kafka dalam pertempuran dan memutuskan apakah akan terus menggunakannya sebagai moda transportasi utama kami.
Tetapi pendekatan ini memiliki kelemahan yang signifikan: pesan tidak memiliki pengetikan dan validasi - kami tidak tahu pasti format pesan mana yang kami baca dari topik tersebut.
Hal ini meningkatkan risiko kesalahan dan inkonsistensi antara layanan yang menyediakan data dan yang mengkonsumsinya.
Untuk mengatasi masalah ini, kami menulis pembungkus - layanan mikro di Go, yang menyembunyikan Kafka di balik API-nya. Ini menambahkan dua manfaat:
- validasi data pada saat mengirim dan menerima. Faktanya, ini adalah DTO yang sama, jadi kami selalu yakin dengan format data yang diharapkan.
- integrasi cepat layanan kami dengan transportasi ini.
Karenanya, bekerja dengan Kafka menjadi serabstrak mungkin untuk layanan kami: mereka hanya bekerja dengan API tingkat atas dari pembungkus ini.
Mari kembali ke contoh
Dengan mentransfer komunikasi sinkron ke bus acara, kita perlu membalikkan aliran data: apa yang kita minta sekarang harus kita terima melalui Kafka itu sendiri. Dalam contoh, kita berbicara tentang koordinat kurir, yang sekarang kami akan membuat topik khusus dan akan memproduksinya saat kami menerimanya dari kurir oleh layanan tersebut
logistics-couriers.
Layanan hanya perlu
courier-trackermengumpulkan koordinat dalam jumlah yang diperlukan dan untuk periode yang diperlukan. Hasilnya, titik akhir kami menjadi sesederhana mungkin: ambil data dari database layanan dan berikan ke aplikasi seluler. Peningkatan beban di atasnya sekarang aman bagi kami.
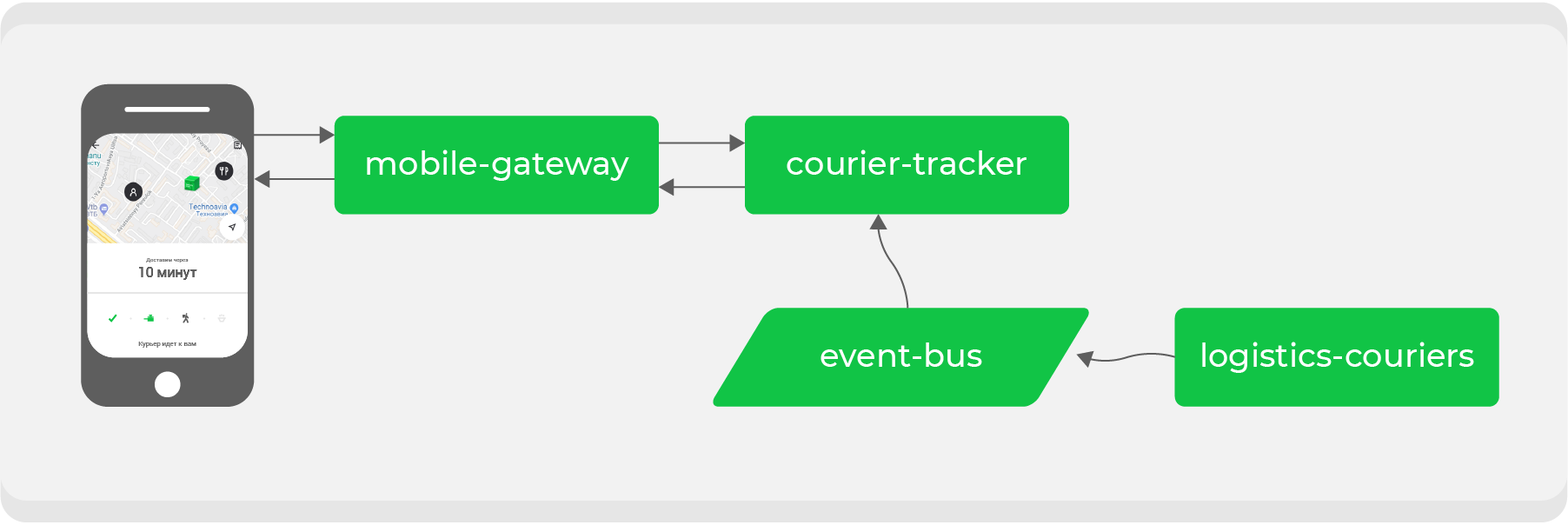
Selain menyelesaikan masalah tertentu, sebagai hasilnya, kami mendapatkan topik data dengan koordinat kurir yang sebenarnya, yang dapat digunakan oleh layanan kami untuk tujuan mereka sendiri.
Konsistensi akhirnya
Dalam contoh ini, semuanya berfungsi dengan baik, kecuali koordinat kurir tidak akan selalu mutakhir dibandingkan dengan opsi sinkron: dalam arsitektur yang dibangun di atas interaksi asinkron, muncul pertanyaan tentang relevansi data pada waktu tertentu. Tetapi kami tidak memiliki banyak data penting yang perlu selalu diperbarui, jadi skema ini ideal untuk kami: kami mengorbankan relevansi beberapa informasi untuk meningkatkan tingkat ketersediaan sistem. Tetapi kami menjamin bahwa pada akhirnya, di semua bagian sistem, semua data akan relevan dan konsisten (pada akhirnya konsistensi).
Denormalisasi data ini diperlukan jika menyangkut sistem beban tinggi dan arsitektur layanan mikro: setiap layanan itu sendiri memastikan penyimpanan data yang diperlukannya agar berfungsi. Misalnya, salah satu entitas utama domain kami adalah kurir. Banyak layanan beroperasi dengannya, tetapi mereka semua membutuhkan kumpulan data yang berbeda: seseorang membutuhkan data pribadi, dan seseorang hanya membutuhkan informasi tentang jenis pergerakannya. Master data domain ini akan menghasilkan seluruh entitas ke dalam aliran, dan layanan mengakumulasi bagian-bagian yang diperlukan:
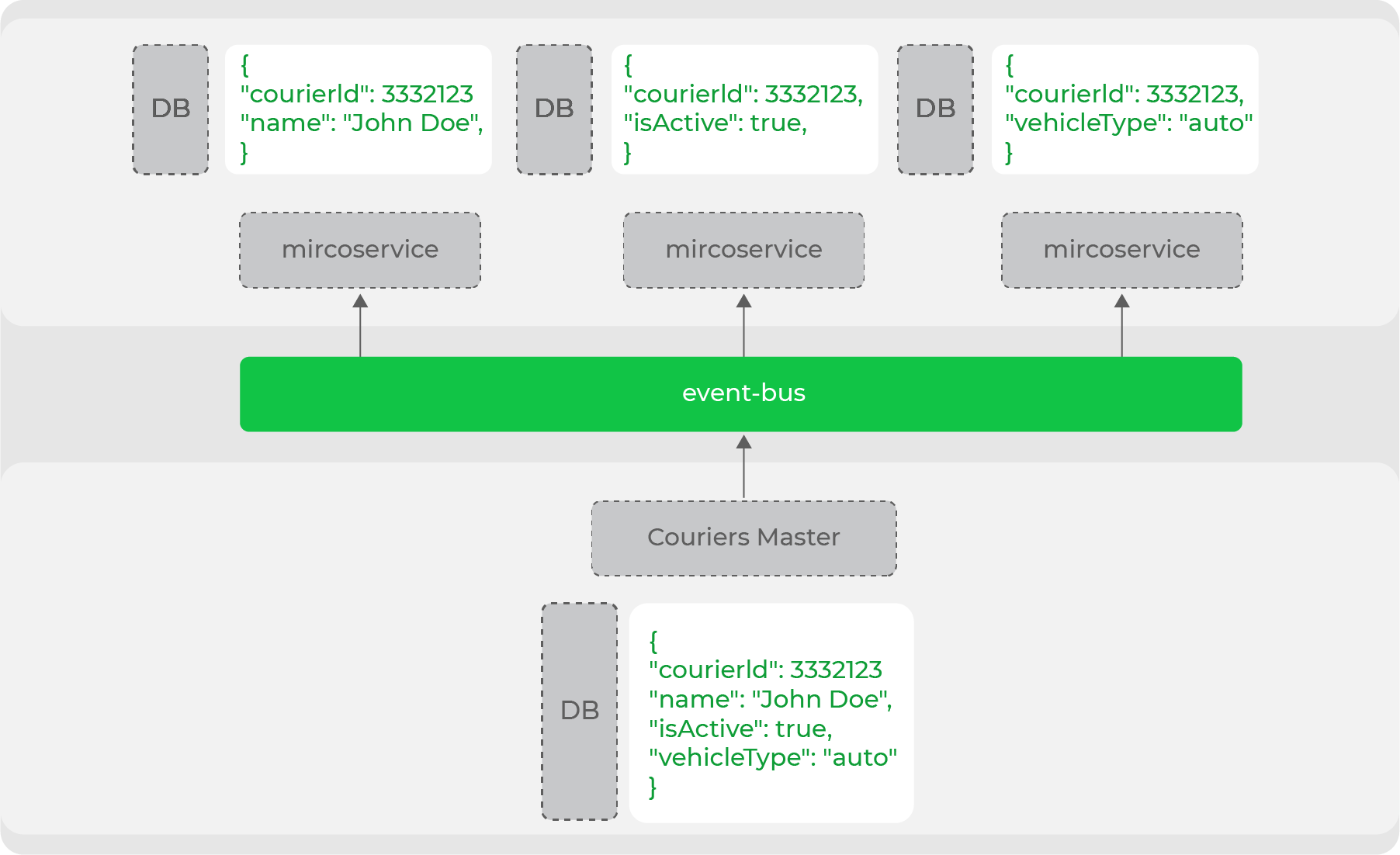
Dengan demikian, kami dengan jelas membagi layanan kami menjadi mereka yang merupakan master data dan mereka yang menggunakan data ini. Faktanya, ini adalah perdagangan tanpa kepala dari arsitektur evolusioner - kami telah dengan jelas memisahkan semua "etalase" (situs web, aplikasi seluler) dari produsen data ini.
Denormalisasi
Contoh lain: kami memiliki mekanisme untuk pemberitahuan yang ditargetkan kepada kurir - ini adalah pesan yang akan datang kepada mereka dalam aplikasi. Di sisi backend, ada API yang kuat untuk mengirim notifikasi semacam itu. Di dalamnya, Anda dapat mengkonfigurasi filter surat: dari kurir tertentu hingga grup kurir sesuai dengan kriteria tertentu.
Layanan bertanggung jawab atas pemberitahuan ini
logistics-courier-notifications. Setelah dia menerima permintaan untuk mengirim, tugasnya adalah menghasilkan pesan untuk kurir yang telah ditargetkan. Untuk melakukan ini, dia perlu mengetahui informasi yang diperlukan tentang semua kurir Klub Pengiriman. Dan kami memiliki dua opsi untuk memecahkan masalah ini:
- membuat titik akhir di sisi layanan - wizard data kurir (
logistics-couriers), yang akan dapat memfilter dan mengembalikan kurir yang diperlukan oleh bidang yang ditransmisikan; - menyimpan semua informasi yang diperlukan secara langsung dalam layanan, mengkonsumsinya dari topik yang relevan dan menyimpan data yang akan kami perlukan untuk memfilter di masa mendatang.
Beberapa logika untuk menghasilkan pesan dan kurir penyaringan tidak dimuat, itu dijalankan di latar belakang, jadi tidak ada pertanyaan tentang beban layanan
logistics-couriers. Tetapi jika kita memilih opsi pertama, kita dihadapkan pada serangkaian masalah:
- Anda harus mendukung titik akhir yang sangat terspesialisasi dalam layanan pihak ketiga, yang kemungkinan besar hanya kami perlukan;
- jika Anda memilih filter yang terlalu lebar, semua kurir yang tidak cocok dengan respons HTTP akan disertakan dalam sampel, dan Anda harus menerapkan pagination (dan mengulanginya saat mengumpulkan layanan).
Jelas, kami berhenti menyimpan data di layanan itu sendiri. Ini secara mandiri dan terisolasi melakukan semua pekerjaan, tidak mengakses di mana pun, tetapi hanya mengumpulkan semua data yang diperlukan dari dirinya sendiri dari topik Kafka. Ada risiko kami akan menerima pesan tentang pembuatan kurir baru nanti, dan itu tidak akan disertakan dalam beberapa pilihan. Tetapi kerugian dari arsitektur asinkron ini tidak bisa dihindari.
Hasilnya, kami telah merumuskan beberapa prinsip penting untuk mendesain layanan:
- Layanan harus memiliki tanggung jawab khusus. Jika sebuah layanan masih diperlukan untuk berfungsi penuh, maka ini adalah kesalahan desain, keduanya harus digabungkan atau arsitekturnya harus direvisi.
- Kami melihat secara kritis setiap panggilan sinkron. Untuk layanan dalam satu arah, ini dapat diterima, tetapi untuk komunikasi antar layanan dalam arah yang berbeda - tidak
- Jangan bagikan apa pun. Kami tidak membuka database layanan yang melewati mereka. Semua permintaan hanya melalui API.
- Spesifikasi Pertama. Pertama, kami menjelaskan dan menyetujui protokol.
Jadi, dengan mengubah sistem kami secara berulang sesuai dengan prinsip dan pendekatan yang diterima, kami sampai pada arsitektur berikut:
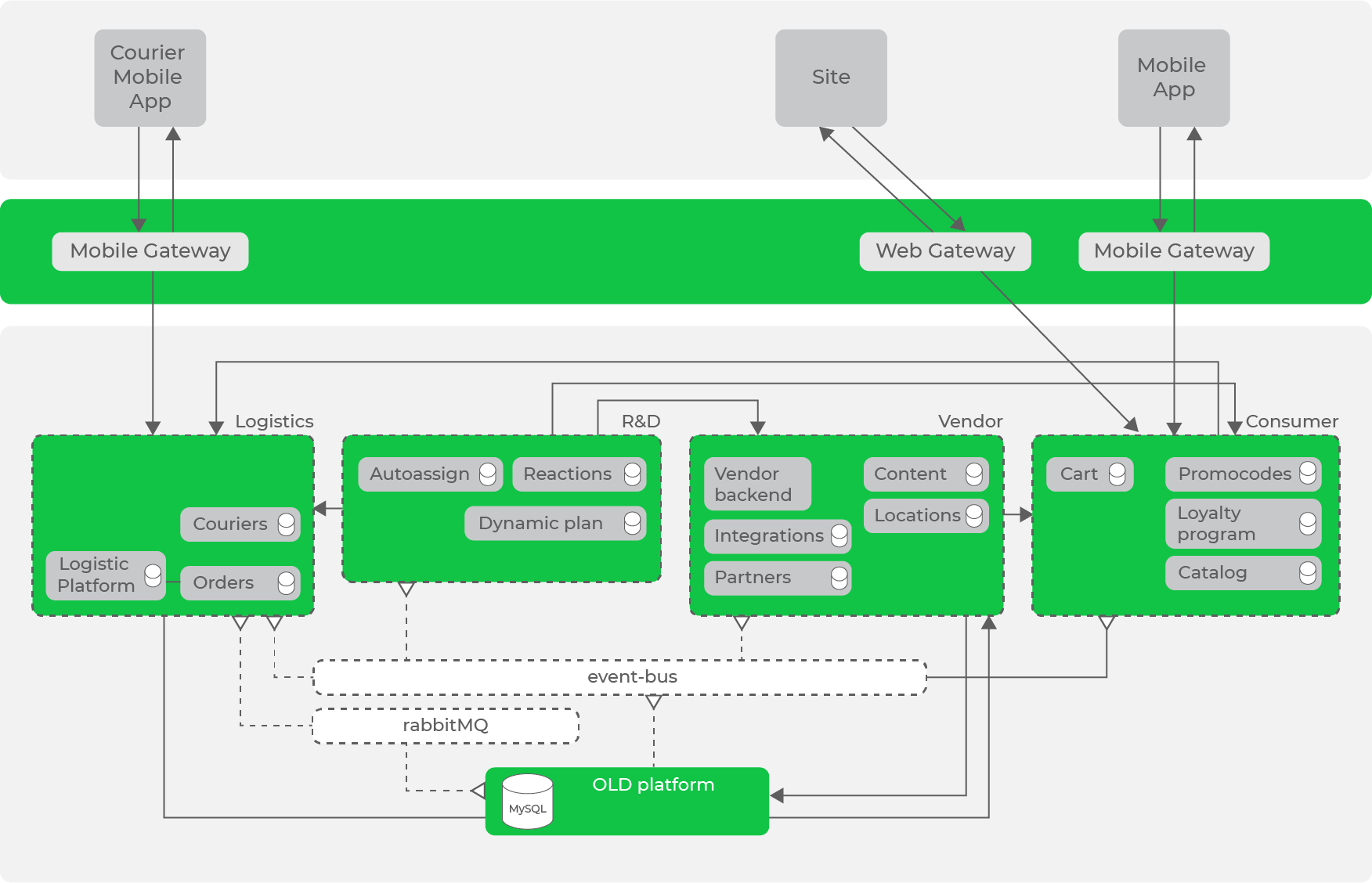
Kami sudah memiliki bus data dalam bentuk Kafka, yang sudah memiliki sejumlah besar aliran data, tetapi masih ada permintaan sinkron antar arah.
Bagaimana kami berencana mengembangkan arsitektur kami
Klub pengiriman, seperti yang saya katakan di awal, berkembang pesat, kami merilis sejumlah besar fitur baru ke dalam produksi. Dan kami bereksperimen lebih banyak lagi ( Nikolay Arkhipov membicarakan hal ini secara rinci ) dan menguji hipotesis. Ini semua memunculkan sejumlah besar sumber data dan bahkan lebih banyak opsi untuk penggunaannya. Dan manajemen arus data yang benar, yang sangat penting untuk dibangun dengan benar - inilah tugas kita.
Mulai saat ini, kami akan terus menerapkan pendekatan yang dikembangkan untuk semua layanan Delivery Club: untuk membangun ekosistem layanan di sekitar platform dengan transportasi dalam bentuk bus data.
Tugas utama adalah memastikan bahwa informasi di semua domain sistem dipasok ke bus data. Untuk layanan baru dengan data baru, hal ini tidak menjadi masalah: pada tahap menyiapkan layanan, ia akan diwajibkan untuk mengalirkan data domainnya ke Kafka.
Namun selain yang baru, kami memiliki layanan lama yang besar dengan data di domain utama kami: pesanan dan kurir. Mengalirkan data ini “sebagaimana adanya” merupakan masalah, karena disimpan tersebar di lusinan tabel, dan akan sangat mahal untuk membangun entitas akhir untuk menghasilkan semua perubahan setiap saat.
Oleh karena itu, kami memutuskan untuk menggunakan Debezium untuk layanan lama ., yang memungkinkan Anda untuk mengalirkan informasi langsung dari tabel berdasarkan bin-log: sebagai hasilnya, Anda mendapatkan topik siap pakai dengan data mentah dari tabel. Tetapi mereka tidak cocok untuk digunakan dalam bentuk aslinya, sehingga melalui trafo di tingkat Kafka, mereka akan diubah menjadi format yang dapat dimengerti oleh konsumen dan didorong ke topik baru. Dengan demikian, kami akan memiliki satu set topik pribadi dengan data mentah dari tabel, yang akan diubah menjadi format yang nyaman dan disiarkan ke topik publik untuk digunakan oleh konsumen.
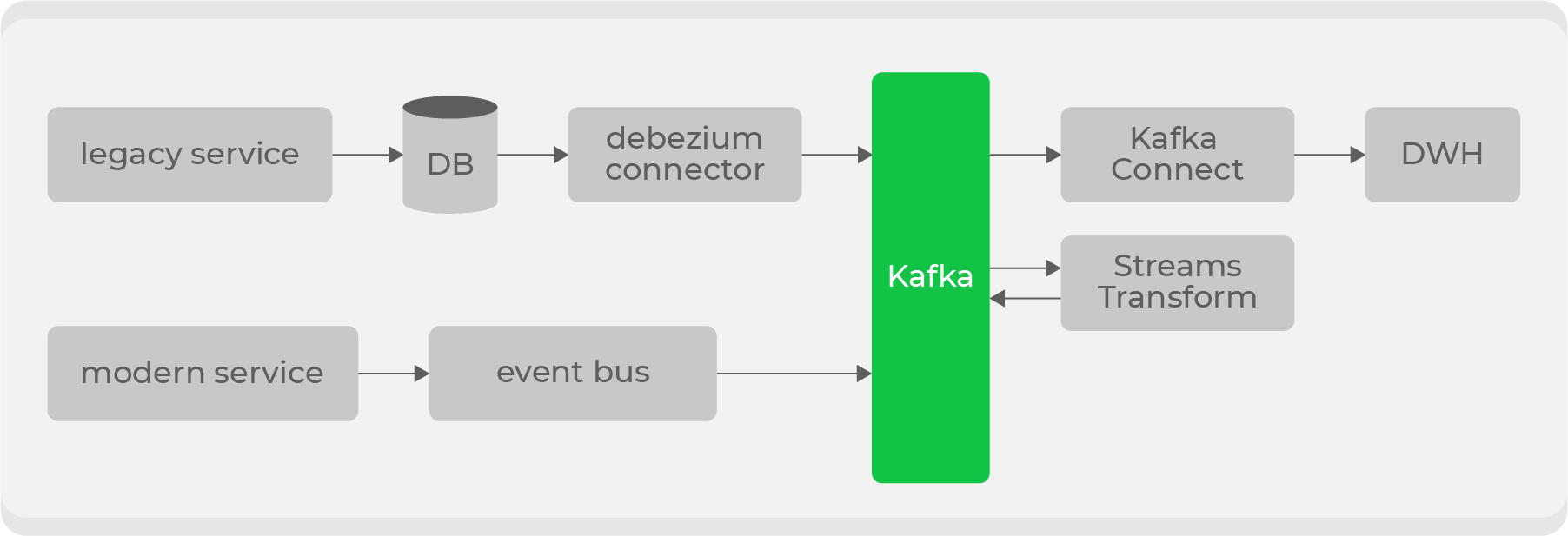
Akan ada beberapa titik masuk untuk menulis ke Kafka dan berbagai jenis topik, jadi selanjutnya kami akan menerapkan hak akses berdasarkan peran di sisi penyimpanan dan menambahkan validasi skema di sisi bus data melalui Confluent .
Lebih jauh dari bus data, layanan akan menggunakan data dari topik yang diperlukan. Dan kami sendiri akan menggunakan data ini untuk sistem kami: misalnya, streaming melalui Kafka Connect ke ElasticSearch atau DWH. Dengan yang terakhir, prosesnya akan lebih rumit: agar informasi di dalamnya tersedia untuk semua orang, itu harus dibersihkan dari data pribadi apa pun.
Kami juga akhirnya harus menyelesaikan masalah dengan monolit: masih ada proses kritis yang akan kami tanggung dalam waktu dekat. Baru-baru ini, kami telah meluncurkan layanan terpisah yang berhubungan dengan tahap pertama pembuatan pesanan: membentuk keranjang, tanda terima, dan pembayaran. Kemudian dia mengirimkan data ini ke monolit untuk diproses lebih lanjut. Nah, semua operasi lain tidak lagi memerlukan sinkronisasi.
Bagaimana melakukan refactoring ini secara transparan untuk klien
Saya akan memberi tahu Anda satu contoh lagi: katalog restoran. Jelas, ini adalah tempat yang sangat sibuk, dan kami memutuskan untuk memindahkannya ke layanan terpisah di Go. Untuk mempercepat pengembangan, kami telah membagi takeaway menjadi dua tahap:
- Pertama, di dalam layanan, kami langsung menuju replika basis monolit kami dan mendapatkan data dari sana.
- Kemudian kami mulai mengalirkan data yang kami butuhkan melalui Debezium dan mengumpulkannya dalam database layanan itu sendiri.
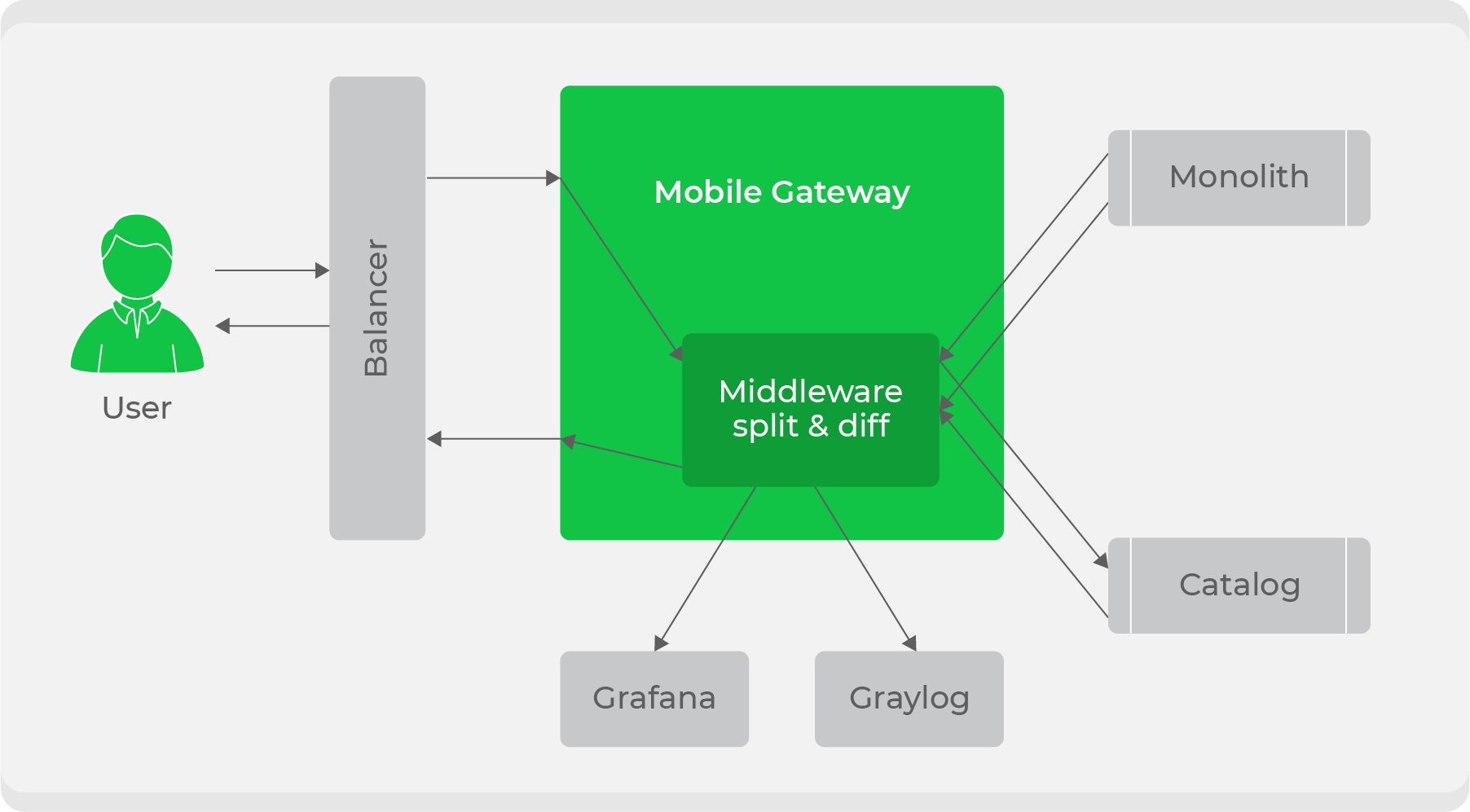
Ketika layanan sudah siap, pertanyaan yang muncul adalah bagaimana mengintegrasikannya secara transparan ke dalam alur kerja saat ini. Kami menggunakan skema pembagian lalu lintas: semua lalu lintas dari klien pergi ke layanan
mobile-gateway, dan kemudian dibagi antara monolit dan layanan baru. Awalnya, kami terus memproses semua lalu lintas melalui monolit, tetapi kami menduplikasi beberapa di antaranya menjadi layanan baru, membandingkan tanggapan mereka, dan mencatat log tentang perbedaan dalam metrik kami. Dengan ini, kami memastikan transparansi pengujian layanan dalam kondisi pertempuran. Setelah itu, hanya tinggal beralih secara bertahap dan meningkatkan lalu lintas di atasnya sampai layanan baru sepenuhnya menggantikan monolit.
Secara umum, kami memiliki banyak rencana dan ide yang ambisius. Kami baru pada awal mengembangkan strategi kami selanjutnya, sementara bentuk akhirnya tidak jelas dan tidak diketahui apakah semuanya akan bekerja seperti yang kami harapkan. Segera setelah kami menerapkan dan menarik kesimpulan, kami pasti akan membagikan hasilnya.
Seiring dengan semua perubahan konseptual ini, kami terus secara aktif mengembangkan dan memberikan fitur ke produk, yang menghabiskan sebagian besar waktu. Di sini kita sampai pada masalah kedua, yang saya bicarakan di awal: dengan mempertimbangkan jumlah pengembang (180 orang), masalah memvalidasi arsitektur dan kualitas layanan baru muncul. Yang baru seharusnya tidak menurunkan sistem, itu harus dibangun dengan benar sejak awal. Tapi bagaimana cara mengontrolnya dalam skala industri?
Komite Arsitektur
Kebutuhan itu tidak segera muncul. Ketika tim pengembangan masih kecil, setiap perubahan pada sistem mudah dikendalikan. Tapi semakin banyak orang, semakin sulit melakukannya.
Hal ini menimbulkan masalah nyata (layanan tidak dapat menahan beban karena desain yang tidak tepat) dan masalah konseptual ("mari kita ke sini secara sinkron, bebannya kecil").
Jelas bahwa sebagian besar masalah diselesaikan di tingkat tim. Tetapi jika kita berbicara tentang semacam integrasi kompleks ke dalam sistem saat ini, maka tim tersebut mungkin tidak memiliki cukup keahlian. Oleh karena itu, saya ingin menciptakan semacam asosiasi orang-orang dari segala arah, di mana orang dapat datang dengan pertanyaan apa pun tentang arsitektur dan mendapatkan jawaban yang lengkap.
Jadi kami sampai pada pembentukan komite arsitektur, yang mencakup pemimpin tim, pemimpin arah, dan CTO. Kami bertemu setiap dua minggu dan membahas perubahan besar yang direncanakan dalam sistem atau hanya menyelesaikan masalah tertentu.
Akibatnya, kami menutup masalah dengan mengontrol perubahan besar, pertanyaan tentang pendekatan umum terhadap kualitas kode di Delivery Club tetap: masalah khusus kode atau kerangka kerja di tim yang berbeda dapat diselesaikan dengan cara yang berbeda. Kami datang ke guild dengan model Spotify: ini adalah persatuan orang-orang yang tidak peduli dengan beberapa teknologi. Contohnya, ada guild Go, PHP dan Frontend.
Mereka mengembangkan gaya pemrograman yang seragam, pendekatan desain dan arsitektur, membantu membentuk dan mempertahankan budaya teknikdi level tertinggi. Mereka juga memiliki backlog sendiri, di mana mereka meningkatkan alat internal, misalnya, Go-template kami untuk layanan mikro.
Kode Produk
Selain fakta bahwa perubahan besar melewati komite arsitektur, dan guild memantau budaya kode secara keseluruhan, kami masih memiliki tahap penting dalam mempersiapkan layanan untuk produksi: menyusun daftar periksa di Confluence. Pertama, saat menyusun daftar periksa, pengembang sekali lagi mengevaluasi keputusannya; kedua, ini adalah persyaratan operasional, karena mereka perlu memahami jenis layanan baru yang muncul dalam produksi.
Daftar periksa biasanya menunjukkan:
- bertanggung jawab atas layanan (biasanya ini adalah pimpinan teknis layanan);
- tautan ke dasbor dengan peringatan yang disesuaikan;
- deskripsi layanan dan tautan ke Swagger;
- deskripsi layanan yang akan berinteraksi dengannya;
- perkiraan beban pada layanan;
- health-check. URL, . Health-check - : 200, , - . , health check URL’ , , , PostgreSQL Redis.
Peringatan layanan dirancang pada tahap persetujuan arsitektur. Pengembang harus memahami bahwa layanan tersebut aktif dan tidak hanya memperhitungkan metrik teknis, tetapi juga metrik produk. Ini tidak berarti konversi bisnis apa pun, tetapi metrik yang menunjukkan bahwa layanan berfungsi sebagaimana mestinya.
Misalnya, Anda dapat menggunakan layanan yang telah dibahas di atas
courier-tracker, yang melacak kurir di peta. Salah satu metrik utama di dalamnya adalah jumlah kurir yang koordinatnya diperbarui. Jika tiba-tiba beberapa rute tidak diperbarui untuk waktu yang lama, peringatan "ada yang tidak beres" muncul. Mungkin di suatu tempat mereka tidak pergi untuk mendapatkan data, atau mereka salah memasukkan database, atau beberapa layanan lain jatuh. Ini bukan metrik teknis atau metrik produk, tetapi ini menunjukkan kelayakan layanan.
Untuk metrik, kami menggunakan Graylog dan Prometheus, membuat dasbor, dan mengatur peringatan di Grafana.
Terlepas dari banyaknya persiapan, pengiriman layanan ke produksi cukup cepat: semua layanan awalnya dikemas dalam Docker, diluncurkan ke tahapan secara otomatis setelah bagan yang diketik untuk Kubernetes terbentuk, dan kemudian semuanya ditentukan oleh sebuah tombol di Jenkins.
Peluncuran layanan baru ke prod terdiri dari penugasan tugas ke admin di Jira, yang menyediakan semua informasi yang kita siapkan sebelumnya.
Dibawah tenda
Kami sekarang memiliki 162 layanan mikro yang ditulis dalam PHP dan Go. Mereka didistribusikan di antara layanan sekitar 50% hingga 50%. Awalnya, kami menulis ulang beberapa layanan beban tinggi di Go. Kemudian menjadi jelas bahwa Go lebih mudah untuk dipelihara dan dipantau dalam produksi, ia memiliki ambang masuk yang rendah, jadi baru-baru ini kami hanya menulis layanan di dalamnya. Tidak ada tujuan untuk menulis ulang sisa layanan PHP di Go: ini cukup berhasil mengatasi fungsinya.
Dalam layanan PHP, kami memiliki Symfony, di atasnya kami menggunakan kerangka kerja kecil kami sendiri. Itu memberlakukan arsitektur umum pada layanan, berkat itu kami menurunkan ambang batas untuk memasukkan kode sumber layanan: tidak peduli layanan apa yang Anda buka, akan selalu jelas apa yang ada di dalamnya dan di mana. Dan kerangka kerja juga merangkum lapisan transportasi komunikasi antar layanan, untuk pengembang, permintaan ke layanan pihak ketiga melihat abstraksi tingkat tinggi:
Di sini kita membentuk DTO dari request ($courierResponse = $this->courierProtocol->get($courierRequest);
$courierRequest), memanggil metode objek protokol dari layanan tertentu, yang merupakan pembungkus di atas titik akhir tertentu. Di bawah tenda, objek kami $courierRequestdiubah menjadi objek permintaan, yang diisi dengan bidang dari DTO. Ini semua fleksibel: kolom dapat disisipkan di header dan di URL permintaan itu sendiri. Selanjutnya request tersebut dikirim melalui cURL, kita mendapatkan objek Respon dan mengubahnya kembali menjadi objek yang kita harapkan $courierResponse.
Ini memungkinkan pengembang untuk fokus pada logika bisnis, tanpa detail interaksi pada level rendah. Objek protokol, permintaan, dan respons layanan berada dalam repositori terpisah - SDK layanan ini. Berkat ini, layanan apa pun yang ingin menggunakan protokolnya akan menerima seluruh paket protokol yang diketik setelah mengimpor SDK.
Tetapi proses ini memiliki kelemahan besar: repositori dengan SDK sulit dipelihara, karena semua DTO ditulis secara manual, dan pembuatan kode yang mudah tidaklah mudah: ada upaya, tetapi pada akhirnya, mengingat transisi ke Go, mereka tidak menginvestasikan waktu di dalamnya.
Akibatnya, perubahan dalam protokol layanan dapat berubah menjadi beberapa permintaan tarik: ke dalam layanan itu sendiri, ke dalam SDK-nya, dan menjadi layanan yang membutuhkan protokol ini. Yang terakhir, kita perlu meningkatkan versi SDK yang diimpor sehingga perubahan akan terjadi. Hal ini sering menimbulkan pertanyaan dari developer baru: "Saya baru saja mengubah parameternya, mengapa saya perlu membuat tiga request ke tiga repositori yang berbeda ?!"
Di Go, semuanya jauh lebih sederhana: kami memiliki generator kode yang sangat baik (Sergey Popov menulis artikel mendetail tentang ini), berkat seluruh protokol yang diketik, dan sekarang bahkan opsi untuk menyimpan semua spesifikasi dalam repositori terpisah sedang dibahas. Jadi, jika seseorang mengubah spesifikasi, semua layanan yang bergantung padanya akan segera mulai menggunakan versi yang diperbarui.
Radar teknis
Selain Go dan PHP yang telah disebutkan, kami menggunakan sejumlah besar teknologi lain. Mereka bervariasi dari satu arah ke arah lainnya dan bergantung pada tugas tertentu. Pada dasarnya, di backend kami menggunakan:
Python, di mana tim Ilmu Data menulis.KotlindanSwift- untuk pengembangan aplikasi seluler.PostgreSQLsebagai database, tetapi beberapa layanan lama masih menjalankan MySQL. Di layanan mikro, kami menggunakan beberapa pendekatan: setiap layanan memiliki database sendiri dan tidak berbagi apa-apa - kami tidak pergi ke database yang melewati layanan, hanya melalui API mereka.ClickHouse- untuk layanan yang sangat terspesialisasi terkait analitik.RedisdanMemcachedsebagai penyimpanan dalam memori.
Saat memilih teknologi, kami dipandu oleh prinsip-prinsip khusus . Salah satu persyaratan utamanya adalah Kemudahan penggunaan: kami menggunakan teknologi yang paling sederhana dan mudah dipahami untuk pengembang, sebanyak mungkin dengan mengikuti tumpukan yang diterima. Bagi mereka yang ingin mengetahui seluruh tumpukan teknologi tertentu, kami telah menyusun radar teknis yang sangat rinci .
Singkat cerita
Akibatnya, kami beralih dari arsitektur monolitik ke layanan mikro, dan sekarang kami sudah memiliki grup layanan yang disatukan oleh arah (area domain) di sekitar platform, yaitu master inti dan data master.
Kami memiliki visi tentang bagaimana mengatur ulang aliran data kami dan bagaimana melakukannya tanpa mempengaruhi kecepatan pengembangan fitur baru. Di masa depan, kami pasti akan memberi tahu Anda tentang ke mana hal ini membawa kami.
Dan berkat transfer pengetahuan yang aktif dan proses pembuatan perubahan yang diformalkan, kami dapat menghadirkan sejumlah besar fitur yang tidak memperlambat proses transformasi arsitektur kami.
Sekian untuk saya, terima kasih sudah membaca!