
Memperkenalkan struktur pohon keputusan yang dapat disesuaikan dan interaktif yang ditulis dengan Python. Implementasi ini cocok untuk mengekstraksi pengetahuan dari data, menguji intuisi, meningkatkan pemahaman Anda tentang cara kerja dalam pohon keputusan, dan mengeksplorasi hubungan sebab dan akibat alternatif untuk masalah pembelajaran Anda. Ini dapat digunakan sebagai bagian dari algoritme, visualisasi, dan laporan yang lebih kompleks, untuk tujuan penelitian apa pun, dan sebagai platform yang dapat diakses untuk dengan mudah menguji gagasan algoritme pohon keputusan Anda.
TL; DR
- Repositori HDTree
- Notebook Pelengkap di dalamnya
examples. Direktori repositori ada di sini (setiap ilustrasi yang Anda lihat di sini akan dibuat di notepad). Anda dapat membuat ilustrasi sendiri.
Tentang apa postingan itu?
Implementasi lain dari pohon keputusan yang saya tulis sebagai bagian dari tesis saya. Pekerjaan tersebut dibagi menjadi tiga bagian sebagai berikut:
- Saya akan mencoba menjelaskan mengapa saya memutuskan untuk meluangkan waktu untuk membuat penerapan pohon keputusan saya sendiri. Saya akan mencantumkan beberapa fiturnya , tetapi juga kerugian dari implementasi saat ini.
- Saya akan menunjukkan penggunaan dasar HDTree dengan beberapa cuplikan kode dan beberapa detail yang dijelaskan di sepanjang jalan.
- Kiat tentang cara menyesuaikan dan memperluas HDTree dengan ide-ide Anda.
Motivasi dan latar belakang
Untuk disertasi saya, saya mulai bekerja dengan pohon keputusan. Tujuan saya sekarang adalah untuk mengimplementasikan model ML yang berpusat pada manusia di mana HDTree (Pohon Keputusan Manusia, dalam hal ini) adalah bahan tambahan yang diterapkan sebagai bagian dari antarmuka pengguna yang sebenarnya untuk model itu. Meskipun cerita ini secara eksklusif tentang HDTree, saya dapat menulis sekuel yang merinci komponen lainnya.
Fitur HDTree dan perbandingannya dengan pohon keputusan belajar scikit
Secara alami, saya menemukan implementasi pohon keputusan
scikit-learn[4]. Penerapannya sckit-learnmemiliki banyak keuntungan:
- Cepat dan efisien;
- Ditulis dalam dialek Cython. Cython mengkompilasi ke kode C (yang, pada gilirannya, mengkompilasi ke biner), sambil tetap berinteraksi dengan interpreter Python;
- Sederhana dan nyaman;
- Banyak orang di ML tahu cara menggunakan model
scikit-learn. Dapatkan bantuan di mana saja berkat basis penggunanya; - Ini telah diuji dalam kondisi pertempuran (digunakan oleh banyak orang);
- Ini hanya bekerja;
- Ini mendukung berbagai teknik pra-pemangkasan dan pasca-pemangkasan [6] dan menyediakan banyak fitur (misalnya, pemangkasan dengan biaya minimal dan bobot sampel);
- Mendukung rendering dasar [7].
Namun, hal tersebut tentunya memiliki beberapa kekurangan:
- Tidak sepele untuk berubah, sebagian karena dialek Cython yang agak tidak biasa (lihat keuntungan di atas);
- Tidak ada cara untuk memperhitungkan pengetahuan pengguna tentang bidang subjek atau mengubah proses pembelajaran;
- Visualisasinya cukup minimalis;
- Tidak ada dukungan untuk fitur kategoris;
- Tidak ada dukungan untuk nilai yang hilang;
- Antarmuka untuk mengakses node dan melintasi pohon rumit dan tidak intuitif;
- Tidak ada dukungan untuk nilai yang hilang;
- Hanya partisi biner (lihat di bawah);
- Tidak ada partisi multivariasi (lihat di bawah).
Fitur HDTree
HDTree menawarkan solusi untuk sebagian besar masalah ini, tetapi mengorbankan banyak manfaat dari implementasi scikit-learn. Kami akan kembali ke poin-poin ini nanti, jadi jangan khawatir jika Anda belum memahami keseluruhan daftar berikut:
- Berinteraksi dengan perilaku belajar;
- Komponen utama bersifat modular dan cukup mudah untuk dikembangkan (mengimplementasikan antarmuka);
- Ditulis dengan Python murni (lebih banyak tersedia)
- Memiliki visualisasi yang kaya;
- Mendukung data kategoris;
- Mendukung nilai-nilai yang hilang;
- Mendukung pemisahan multivariat;
- Memiliki antarmuka yang nyaman untuk menavigasi struktur pohon;
- Mendukung partisi n-ary (lebih dari 2 node anak);
- Solusi representasi tekstual;
- Mendorong penjelasan dengan mencetak teks yang dapat dibaca manusia.
Minus:
- Lambat;
- Tidak diuji dalam pertempuran;
- Kualitas perangkat lunaknya biasa-biasa saja;
- Tidak banyak pilihan tanam. Meskipun implementasinya mendukung beberapa parameter dasar.
Tidak banyak kerugiannya, tetapi itu sangat penting. Mari kita perjelas sekarang: Jangan memasukkan data besar untuk implementasi ini. Anda akan menunggu selamanya. Jangan gunakan di lingkungan produksi. Itu bisa pecah secara tak terduga. Anda telah diperingatkan! Beberapa masalah di atas dapat diselesaikan seiring berjalannya waktu. Namun, kecepatan pemelajaran kemungkinan akan tetap rendah (meskipun kesimpulannya valid). Anda perlu menemukan solusi yang lebih baik untuk memperbaikinya. Saya mengundang Anda untuk berkontribusi. Namun, apa saja kemungkinan penerapannya?
- Menggali pengetahuan dari data;
- Memeriksa tampilan data yang intuitif;
- Memahami cara kerja bagian dalam pohon keputusan;
- Jelajahi hubungan kausal alternatif dalam kaitannya dengan masalah belajar Anda;
- Gunakan sebagai bagian dari algoritme yang lebih kompleks;
- Pembuatan laporan dan visualisasi;
- Gunakan untuk tujuan penelitian apa pun;
- Sebagai platform yang dapat diakses untuk menguji ide Anda dengan mudah untuk algoritme pohon keputusan.
Struktur pohon keputusan
Meskipun pohon keputusan tidak akan dibahas secara rinci dalam makalah ini, kami akan meringkas blok bangunan utamanya. Ini akan memberikan dasar untuk memahami contoh nanti, dan juga menyoroti beberapa fitur HDTree. Gambar berikut menunjukkan output aktual dari HDTree (tidak termasuk penanda).
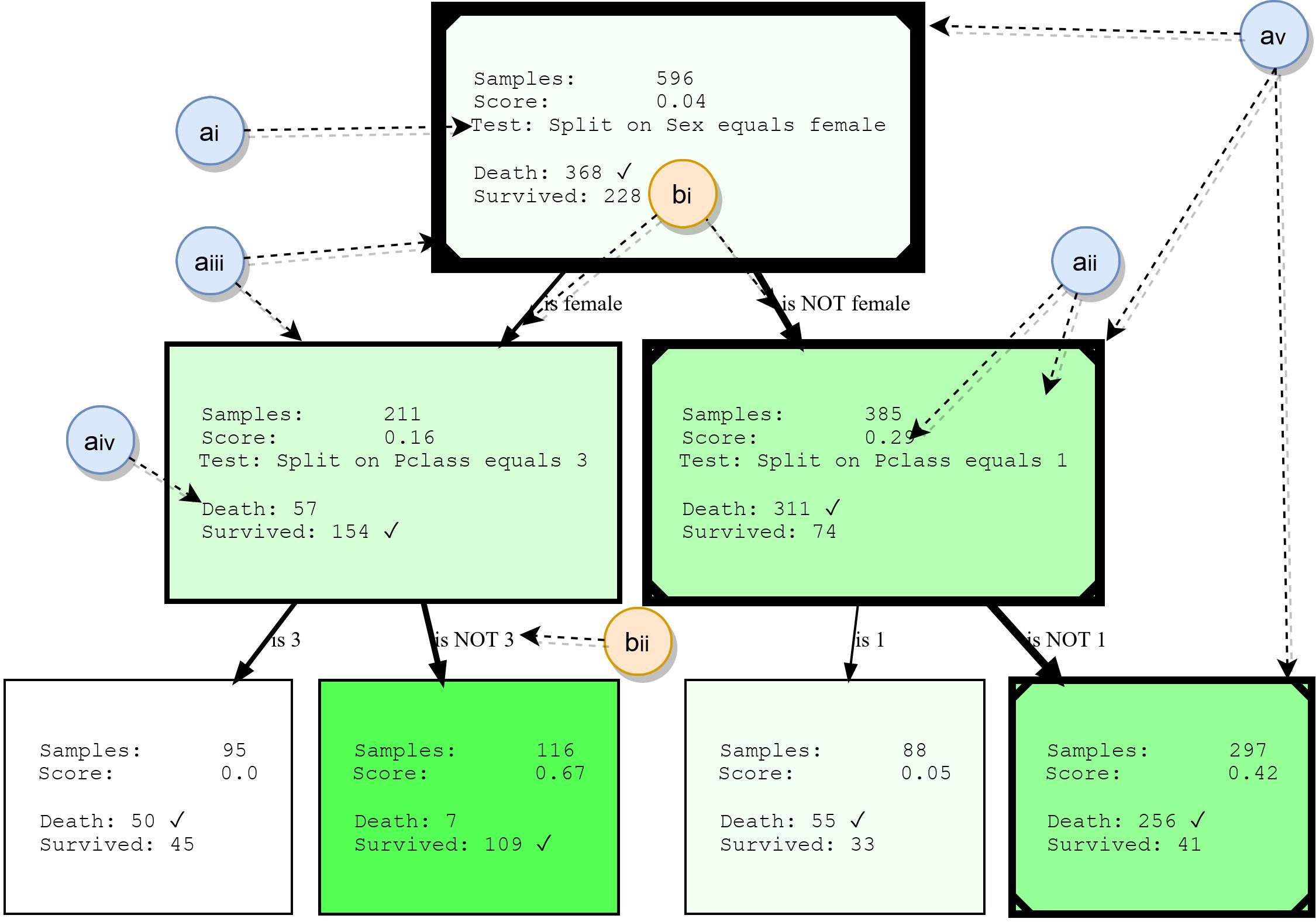
Node
- ai: , . . * * . . 3.
- aii: , , , , . , . . , ( , .. ). HDTree.
- aiii: Batas node menunjukkan berapa banyak titik data yang melewati node ini. Semakin tebal batasnya, semakin banyak data yang mengalir melalui node.
- aiv: daftar target prediksi dan label yang memiliki titik data yang melewati node ini. Kelas paling umum ditandai.
- av: Secara opsional, visualisasi dapat menandai jalur yang diikuti setiap titik data (menggambarkan keputusan yang dibuat saat titik data melintasi pohon). Ini ditandai dengan garis di sudut pohon keputusan.
Tulang iga
- bi: panah menghubungkan setiap kemungkinan hasil pemisahan (ai) ke node turunannya. Semakin banyak data relatif terhadap "aliran" induk di sekitar edge, semakin tebal tampilannya.
- bii: setiap tepi memiliki representasi tekstual yang dapat dibaca manusia dari hasil pemisahan yang sesuai.
Dari mana asal set split dan pengujian yang berbeda?
Pada titik ini, Anda mungkin sudah bertanya-tanya bagaimana HDTree berbeda dari pohon
scikit-learn(atau implementasi lainnya) dan mengapa kita mungkin ingin memiliki jenis partisi yang berbeda? Mari kita coba menjelaskan ini. Mungkin Anda memiliki pemahaman intuitif tentang ruang fitur . Semua data yang kami kerjakan berada dalam ruang multidimensi tertentu, yang ditentukan oleh jumlah dan jenis fitur di data Anda. Tugas algoritma klasifikasi sekarang adalah membagi ruang ini menjadi area yang tidak tumpang tindih dan menetapkannyaarea ini adalah kelas. Mari kita visualisasikan ini. Karena otak kita kesulitan mengutak-atik dimensi tinggi, kita akan tetap menggunakan contoh 2D dan masalah dua kelas yang sangat sederhana, seperti:

Anda melihat kumpulan data yang sangat sederhana yang terdiri dari dua dimensi (ciri / atribut) dan dua kelas. Titik data yang dihasilkan didistribusikan secara normal di tengah. Sebuah jalan yang merupakan fungsi linier
f(x) = ymemisahkan dua kelas: Kelas 1 (kanan bawah) dan Kelas 2 (kiri atas). Beberapa gangguan acak juga telah ditambahkan (titik data biru berwarna oranye dan sebaliknya) untuk mengilustrasikan efek overfitting di kemudian hari. Tugas algoritme klasifikasi seperti HDTree (meskipun juga dapat digunakan untuk masalah regresi ) adalah mencari tahu kelas mana yang dimiliki setiap titik data. Dengan kata lain diberi sepasang koordinat (x, y)seperti(6, 2)... Tujuannya adalah untuk mengetahui apakah koordinat ini termasuk dalam kelas oranye 1 atau kelas biru 2. Model diskriminan akan mencoba membagi ruang objek (di sini adalah sumbu (x, y)) menjadi teritori biru dan oranye, masing-masing.
Dengan adanya data ini, keputusan (aturan) tentang bagaimana data akan diklasifikasikan nampaknya sangat sederhana. Orang yang berakal sehat akan berkata "pikirkan dirimu sendiri dulu.""Ini adalah kelas 1 jika x> y, jika tidak kelas 2." Fungsi
y=xtitik - titik akan menciptakan pemisahan yang sempurna . Memang, pengklasifikasi margin maksimum seperti mesin vektor dukungan [8] akan menyarankan solusi serupa. Tapi mari kita lihat pohon keputusan mana yang menyelesaikan masalah secara berbeda:

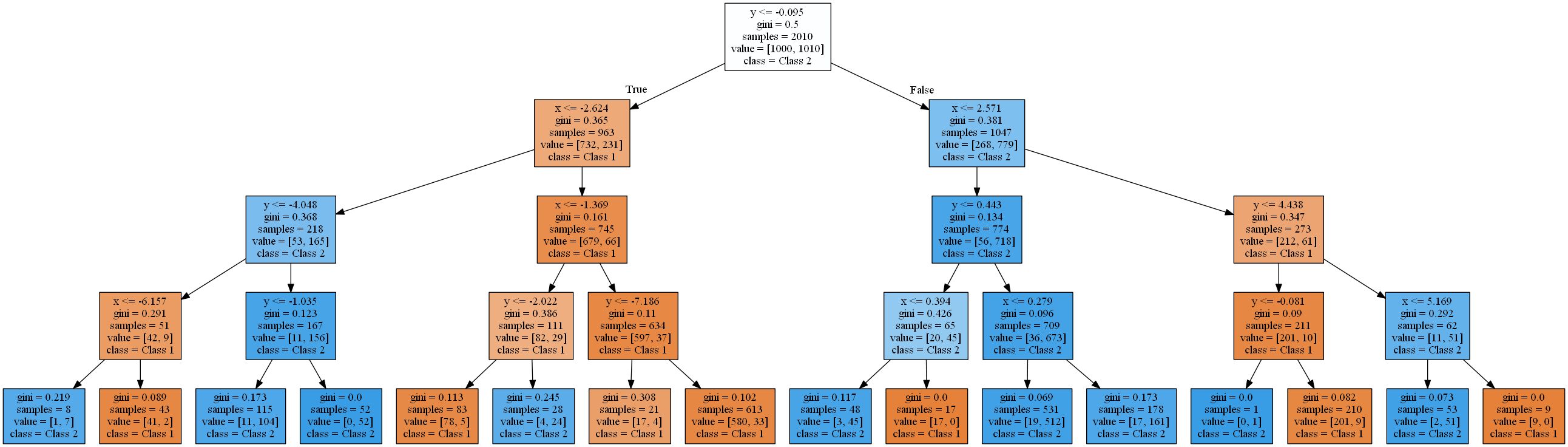
Gambar menunjukkan area di mana pohon keputusan standar dengan kedalaman yang meningkat mengklasifikasikan titik data sebagai kelas 1 (oranye) atau kelas 2 (biru).
Pohon keputusan mendekati fungsi linier menggunakan fungsi langkah.Ini karena jenis aturan validasi dan partisi yang digunakan pohon keputusan. Semuanya bekerja dalam pola
attribute < thresholdyang akan menghasilkan hyperplanes yang sejajar dengan sumbu . Dalam ruang 2D, persegi panjang "dipotong". Dalam 3D, ini akan menjadi kubus dan seterusnya. Selain itu, pohon keputusan mulai memodelkan kebisingan dalam data ketika sudah ada 8 level, yaitu terjadi pelatihan ulang. Namun, ia tidak pernah menemukan pendekatan yang baik untuk fungsi linier nyata. Untuk memverifikasi ini, saya menggunakan pembagian data pelatihan dan pengujian 2-ke-1 dan menghitung keakuratan pepohonan. Ini adalah 93,84%, 93,03%, 90,81% untuk set tes dan 94,54%, 96,57%, 98,81% untuk set pelatihan(diurutkan berdasarkan kedalaman pohon 4, 8, 16). Sementara akurasi dalam tes menurun , akurasi pelatihan meningkat .
Peningkatan efisiensi pelatihan dan penurunan hasil tes merupakan tanda overtraining.Pohon keputusan yang dihasilkan cukup kompleks untuk fungsi sederhana tersebut. Yang paling sederhana dari ini (kedalaman 4) yang dirender dengan scikit learn sudah terlihat seperti ini:
Aku akan lebih sulit menyingkirkanmu dari pepohonan. Di bagian selanjutnya, kita akan mulai dengan menyelesaikan masalah ini menggunakan paket HDTree. HDTree akan memungkinkan pengguna untuk menerapkan pengetahuan tentang data (seperti pengetahuan tentang pemisahan linier dalam contoh). Ini juga akan memungkinkan Anda menemukan solusi alternatif untuk masalah tersebut.
Penerapan paket HDTree
Bagian ini akan memperkenalkan Anda pada dasar-dasar HDTree. Saya akan mencoba menyentuh beberapa bagian API-nya. Silakan bertanya di komentar atau hubungi saya jika Anda memiliki pertanyaan tentang ini. Dengan senang hati saya akan menjawab dan, jika perlu, melengkapi artikel tersebut. Menginstal HDTree sedikit lebih rumit daripada
pip install hdtree. Maaf. Pertama, Anda membutuhkan Python 3.5 atau yang lebih baru.
- Buat direktori kosong dan di dalamnya folder bernama hdtree (
your_folder/hdtree) - Clone repositori ke direktori hdtree (bukan subdirektori lain).
- Instal dependensi yang diperlukan:
numpy,pandas,graphviz,sklearn. - Tambahkan
your_folderkePYTHONPATH. Ini akan menyertakan direktori di mesin impor Python. Anda akan dapat menggunakannya seperti paket Python biasa.
Atau tambahkan
hdtreeke folder site-packagesinstalasi Anda python. Saya dapat menambahkan file instalasi nanti. Pada saat penulisan, kode tidak tersedia di repositori pip. Semua kode yang menghasilkan grafik dan output di bawah ini (serta yang ditampilkan sebelumnya) ada di repositori, dan langsung diposting di sini . Memecahkan masalah linier dengan pohon saudara
Mari kita mulai langsung dengan kode:
from hdtree import HDTreeClassifier, SmallerThanSplit, EntropyMeasure
hdtree_linear = HDTreeClassifier(allowed_splits=[SmallerThanSplit.build()], # Split rule in form a < b
information_measure=EntropyMeasure(), # Use Information Gain for the scores attribute_names=['x', 'y' ]) # give the
attributes some interpretable names # standard sklearn-like interface hdtree_linear.fit(X_street_train,
y_street_train) # create tree graph hdtree_linear.generate_dot_graph() 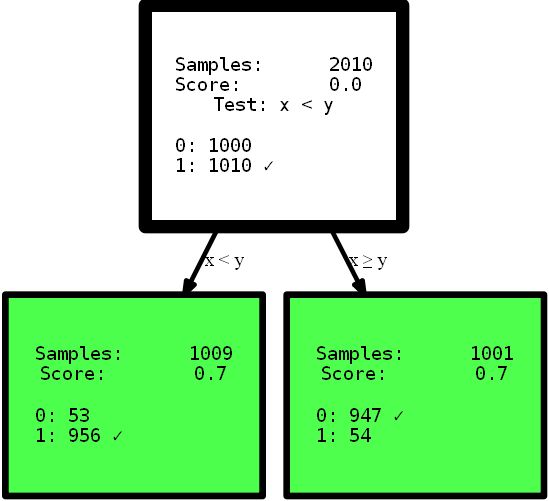
Ya, pohon yang dihasilkan hanya setinggi satu tingkat dan menawarkan solusi sempurna untuk masalah ini. Ini adalah contoh buatan untuk menunjukkan efeknya. Namun, saya harap ini menjelaskan maksudnya: memiliki tampilan data yang intuitif, atau sederhananya memberikan pohon keputusan dengan opsi berbeda untuk mempartisi ruang fitur, yang mungkin menawarkan solusi yang lebih sederhana dan terkadang bahkan lebih akurat . Bayangkan Anda perlu menafsirkan aturan dari pepohonan yang disajikan di sini untuk mendapatkan informasi yang berguna. Interpretasi mana yang dapat Anda pahami terlebih dahulu, dan mana yang lebih Anda percayai? Penafsiran yang kompleks menggunakan fungsi multi-langkah, atau pohon kecil yang tepat? Saya pikir jawabannya cukup sederhana. Tapi mari selami lebih dalam kode itu sendiri. Saat menginisialisasi,
HDTreeClassifierhal terpenting yang harus Anda sediakan adalah allowed_splits. Di sini Anda memberikan daftar yang berisi aturan partisi yang mungkin dicoba oleh algoritme selama pelatihan untuk setiap node guna menemukan partisi lokal yang baik dari data. Dalam hal ini, kami telah menyediakan secara eksklusif SmallerThanSplit. Pemisahan ini melakukan persis seperti yang Anda lihat: dibutuhkan dua atribut (mencoba kombinasi apa pun) dan membagi data sesuai dengan skema a_i < a_j. Yang mana (tidak terlalu acak) cocok dengan data kita sebaik mungkin.
Jenis pemisahan ini disebut sebagai pemisahan multivariasiArtinya pemisahan menggunakan lebih dari satu fitur untuk mengambil keputusan. Ini tidak seperti partisi satu arah yang digunakan di kebanyakan pohon lain, seperti
scikit-tree(lihat di atas untuk lebih jelasnya) yang memperhitungkan hanya satu atribut . Tentu saja, ia HDTreejuga memiliki opsi untuk mencapai "pemartisian normal" seperti yang ada di pohon scikit - keluarga QuantileSplit. Saya akan menunjukkan lebih banyak kepada Anda seiring kemajuan artikel. Hal asing lainnya yang mungkin Anda lihat dalam kode adalah hyperparameter information_measure. Parameter ini mewakili dimensi yang digunakan untuk mengevaluasi nilai node tunggal atau pemisahan lengkap (node induk dengan node turunannya). Opsi yang dipilih didasarkan pada entropi [10]. Anda mungkin juga pernah mendengar tentangkoefisien Gini , yang akan menjadi opsi valid lainnya. Tentu saja, Anda dapat memberikan dimensi Anda sendiri hanya dengan menerapkan antarmuka yang sesuai. Jika Anda suka, terapkan gini-Index , yang dapat Anda gunakan di pohon tanpa menerapkan ulang apa pun. Cukup salin EntropyMeasure()dan sesuaikan untuk diri Anda sendiri. Mari kita gali lebih dalam tentang bencana Titanic . Saya senang belajar dari contoh saya sendiri. Sekarang Anda akan melihat beberapa fungsi HDTree dengan contoh spesifik, bukan pada data yang dihasilkan.
Himpunan data
Kami akan bekerja dengan kumpulan data pembelajaran mesin yang terkenal untuk kursus tempur muda: kumpulan data bencana Titanic. Ini adalah kumpulan yang cukup sederhana yang tidak terlalu besar, tetapi berisi beberapa tipe data berbeda dan nilai yang hilang, meskipun tidak sepenuhnya sepele. Selain itu, dapat dimengerti oleh manusia, dan banyak orang telah mengerjakannya. Datanya terlihat seperti ini:

Anda dapat melihat bahwa ada semua jenis atribut. Numerik, kategorikal, tipe integer dan bahkan nilai yang hilang (lihat kolom Cabin). Tantangannya adalah memprediksi apakah seorang penumpang selamat dari bencana Titanic berdasarkan informasi penumpang yang tersedia. Anda dapat menemukan deskripsi atribut nilai di sini . Dengan mempelajari tutorial ML dan menerapkan kumpulan data ini, Anda melakukan semua jenispreprocessing agar dapat bekerja dengan model pembelajaran mesin yang umum, misalnya, menghapus nilai yang hilang
NaNdengan mengganti nilai [12], menghapus baris / kolom, menyandikan [13] data kategori (misalnya, Embarkeddan Sexatau mengelompokkan data untuk mendapatkan set data yang valid yang menerima model ML. Pembersihan semacam ini secara teknis tidak diperlukan oleh HDTree. Anda dapat menyajikan data apa adanya dan model akan dengan senang hati menerimanya. Ubah data hanya saat mendesain objek nyata. Saya menyederhanakan semuanya untuk memulai.
Melatih data HDTree pertama pada Titanic
Mari kita ambil data apa adanya dan memasukkannya ke model. Kode dasarnya mirip dengan kode di atas, namun, dalam contoh ini, lebih banyak pemisahan data akan diizinkan.
hdtree_titanic = HDTreeClassifier(allowed_splits=[FixedValueSplit.build(), # e.g., Embarked = 'C'
SingleCategorySplit.build(), # e.g., Embarked -> ['C', 'Q', 'S']
TwentyQuantileRangeSplit.build(), # e.g., IN Quantile 3-5
TwentyQuantileSplit.build()], # e.g., BELOW Quantile 7
information_measure=EntropyMeasure(),
attribute_names=col_names,
max_levels=3) # restrict to grow to a max of 3 levels
hdtree_titanic.fit(X_titanic_train.values, y_titanic_train.values)
hdtree_titanic.generate_dot_graph()
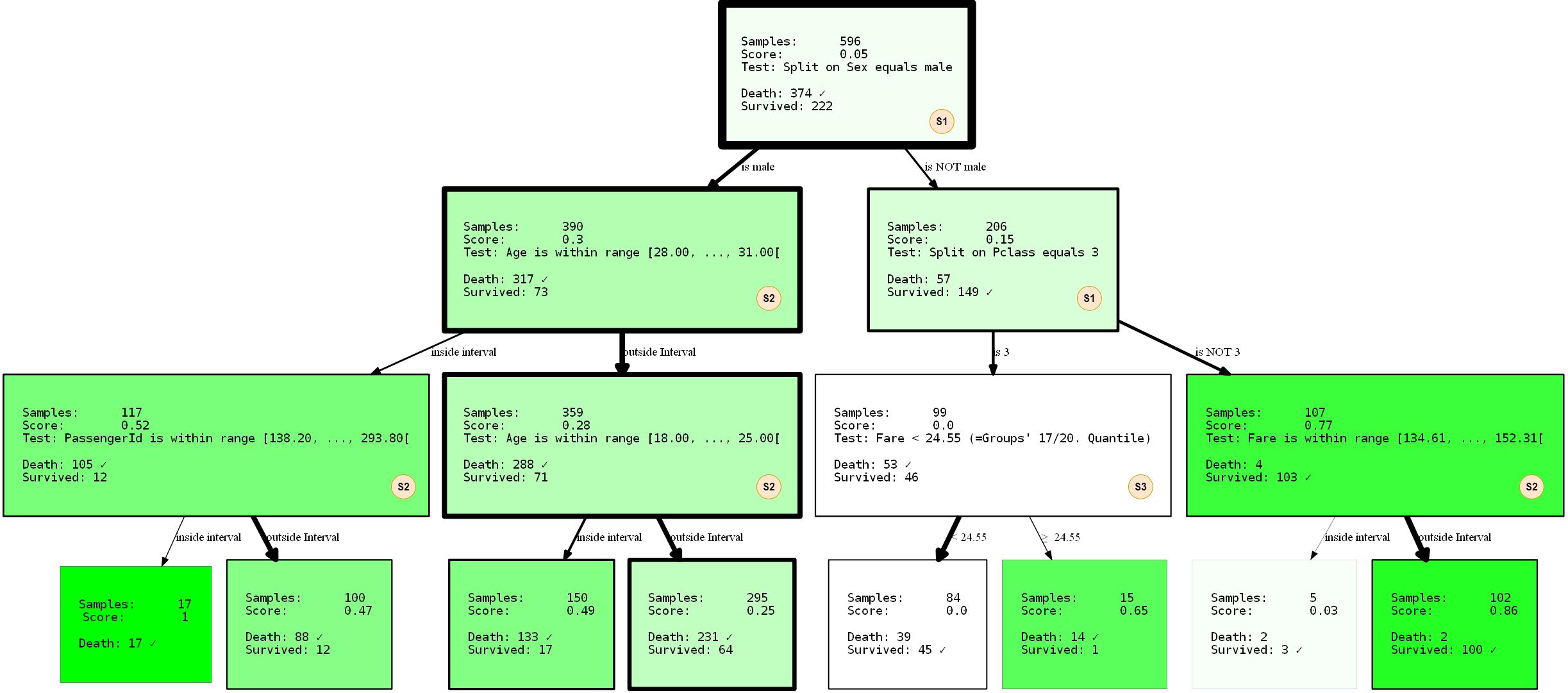
Mari kita lihat lebih dekat apa yang terjadi. Kami membuat pohon keputusan dengan tiga tingkat, yang kami pilih untuk menggunakan 3 dari 4 kemungkinan SplitRules. Mereka ditandai dengan huruf S1, S2, S3. Saya akan menjelaskan secara singkat apa yang mereka lakukan.
- S1:
FixedValueSplit. Divisi ini bekerja dengan data kategorikal dan memilih salah satu nilai yang mungkin. Data tersebut kemudian dipecah menjadi satu bagian yang memiliki nilai ini dan bagian lain yang tidak memiliki kumpulan nilai. Misalnya, PClass = 1 dan Pclass ≠ 1 . - S2: ()
QuantileRangeSplit. . , . 1 5 . ( ) (measure_information). (i) (ii) — . . - S3: (Dua Puluh)
QuantileSplit. Mirip dengan Split Range (S2), tetapi membagi data dengan ambang batas. Ini pada dasarnya adalah apa yang dilakukan pohon keputusan biasa, kecuali bahwa mereka biasanya mencoba semua ambang yang mungkin, bukan angka tetap.
Anda mungkin menyadari bahwa Anda
SingleCategorySplittidak terlibat. Saya akan mengambil kesempatan untuk mengklarifikasi, karena kelalaian divisi ini akan muncul nanti:
- S4:
SingleCategorySplitAkan bekerja dengan cara yang samaFixedValueSplit, tetapi akan membuat simpul anak untuk setiap nilai yang mungkin, misalnya: untuk atribut PClass akan menjadi 3 simpul anak (masing-masing untuk Kelas 1, Kelas 2 dan Kelas 3 ). Perhatikan bahwa ituFixedValueSplitidentikSingleValueSplitjika hanya ada dua kemungkinan kategori.
Divisi individu agak "pintar" sehubungan dengan tipe data / nilai yang "menerima". Sampai beberapa perpanjangan, mereka tahu dalam keadaan apa mereka melamar dan tidak melamar. Pohon itu juga dilatih dengan pembagian data pelatihan dan pengujian 2-ke-1 Performa - akurasi 80,37% pada data pelatihan dan 81,69 pada data uji. Tidak begitu buruk.
Membatasi perpecahan
Mari kita asumsikan bahwa Anda tidak terlalu senang dengan solusi yang ditemukan karena suatu alasan. Mungkin Anda memutuskan bahwa pemisahan pertama di bagian atas pohon terlalu sepele (dipisahkan berdasarkan atribut
sex). HDTree memecahkan masalah. Solusi paling sederhana adalah mencegah FixedValueSplit(dan, dalam hal ini, padanannya SingleCategorySplit) muncul di atas. Ini sangat mudah. Ubah inisialisasi pemisahan seperti ini:
- SNIP -
...allowed_splits=[FixedValueSplit.build_with_restrictions(min_level=1),
SingleCategorySplit.build_with_restrictions(min_level=1),...],
- SNIP -
Saya akan menyajikan HDTree yang dihasilkan secara keseluruhan, karena kita dapat mengamati split yang hilang (S4) di dalam pohon yang baru dibuat.
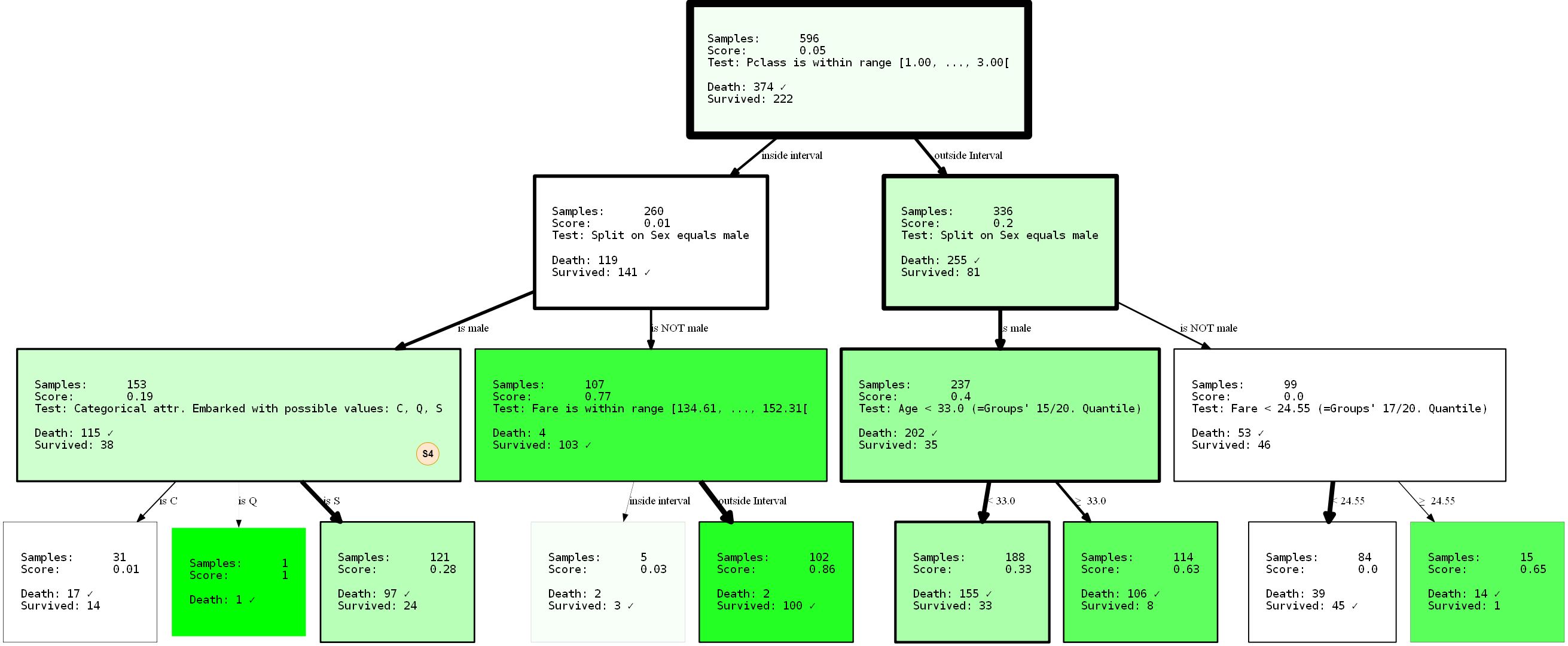
Dengan mencegah pemisahan agar tidak
sexmuncul di root berkat parameter min_level=1(petunjuk: tentu saja Anda juga dapat memberikan max_level), kami telah sepenuhnya menata ulang pohon. Kinerjanya sekarang 80,37% dan 81,69% (pelatihan / tes). Itu tidak berubah sama sekali, bahkan jika kita mengambil pemisahan yang seharusnya lebih baik pada simpul akar.
Karena pohon keputusan serakah, mereka hanya akan menemukan partisi _ terbaik lokal untuk setiap simpul, yang belum tentu merupakan pilihan _ terbaik _ sama sekali. Faktanya, menemukan solusi ideal untuk masalah pohon keputusan adalah masalah NP-complete, seperti yang dibuktikan dalam [15].Jadi yang terbaik yang bisa kami minta adalah heuristik. Kembali ke contoh: perhatikan bahwa kita sudah mendapatkan representasi data yang tidak sepele? Tapi itu sepele. untuk mengatakan bahwa pria hanya akan memiliki kesempatan yang rendah untuk bertahan hidup, pada tingkat yang lebih rendah, dapat disimpulkan bahwa menjadi orang kelas satu atau dua yang
PClassterbang keluar dari Cherbourg ( Embarked=C) dapat meningkatkan peluang Anda untuk bertahan hidup. Atau bagaimana jika Anda seorang pria di PClass 3bawah 33 tahun, peluang Anda juga meningkat? Ingat: wanita dan anak - anak dulu. Menarik kesimpulan ini sendiri dengan menafsirkan visualisasi merupakan latihan yang baik. Kesimpulan ini hanya mungkin karena keterbatasan pohon. Siapa yang tahu apa lagi yang bisa terungkap dengan menerapkan batasan lain? Cobalah!
Sebagai contoh terakhir dari jenis ini, saya ingin menunjukkan kepada Anda bagaimana membatasi partisi ke atribut tertentu. Ini berlaku tidak hanya untuk mencegah pembelajaran pohon pada korelasi yang tidak diinginkan atau alternatif yang dipaksakan , tetapi juga mempersempit ruang pencarian. Pendekatan ini secara dramatis dapat mengurangi waktu eksekusi, terutama saat menggunakan partisi multivariasi. Jika Anda kembali ke contoh sebelumnya, Anda mungkin menemukan node yang memeriksa atribut
PassengerId. Mungkin kita tidak ingin memodelkannya, karena setidaknya itu tidak boleh berkontribusi pada informasi tentang kelangsungan hidup. Memeriksa ID penumpang bisa menjadi tanda overtraining. Mari kita ubah situasi dengan parameter blacklist_attribute_indices.
- SNIP -
...allowed_splits=[TwentyQuantileRangeSplit.build_with_restrictions(blacklist_attribute_indices=['PassengerId']),
FixedValueSplit.build_with_restrictions(blacklist_attribute_indices=['Name Length']),
...],
- SNIP -
Anda mungkin bertanya mengapa
name lengthitu muncul. Ingatlah bahwa nama yang panjang (nama ganda atau gelar [mulia]) dapat menunjukkan masa lalu yang kaya, meningkatkan peluang Anda untuk bertahan hidup.
Tip tambahan: Anda selalu dapat menambahkan hal yang samaSplitRuledua kali. Jika Anda hanya ingin memblokir atribut untuk level HDTree tertentu, tambahkan sajaSplitRuletanpa batas level.
Prediksi Titik Data
Seperti yang mungkin telah Anda ketahui, antarmuka generik scikit-learn dapat digunakan untuk prediksi. Ini
predict(), predict_proba()juga score(). Tapi Anda bisa melangkah lebih jauh. Ada explain_decision()satu yang akan menampilkan representasi tekstual dari solusi tersebut.
print(hdtree_titanic_3.explain_decision(X_titanic_train[42]))
Ini diasumsikan sebagai perubahan terakhir pada pohon. Kode akan menampilkan ini:
Query:
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': 'female', 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Survived" because of:
Explanation 1:
Step 1: Sex doesn't match value male
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
Ini berfungsi bahkan untuk data yang hilang. Mari kita atur indeks atribut 2 (
Sex) menjadi hilang (None):
passenger_42 = X_titanic_train[42].copy()
passenger_42[2] = None
print(hdtree_titanic_3.explain_decision(passenger_42))
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': None, 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Death" because of:
Explanation 1:
Step 1: Sex has no value available
Step 2: Age is OUTSIDE range [28.00, ..., 31.00[(41.00 is above range)
Step 3: Age is OUTSIDE range [18.00, ..., 25.00[(41.00 is above range)
Step 4: Leaf. Vote for {'Death'}
---------------------------------
Explanation 2:
Step 1: Sex has no value available
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
---------------------------------
Ini akan mencetak semua jalur keputusan (ada lebih dari satu, karena pada beberapa node keputusan tidak dapat dibuat!). Hasil akhirnya akan menjadi kelas paling umum dari semua daun.
... hal berguna lainnya
Anda dapat melanjutkan dan mendapatkan tampilan hierarki sebagai teks:
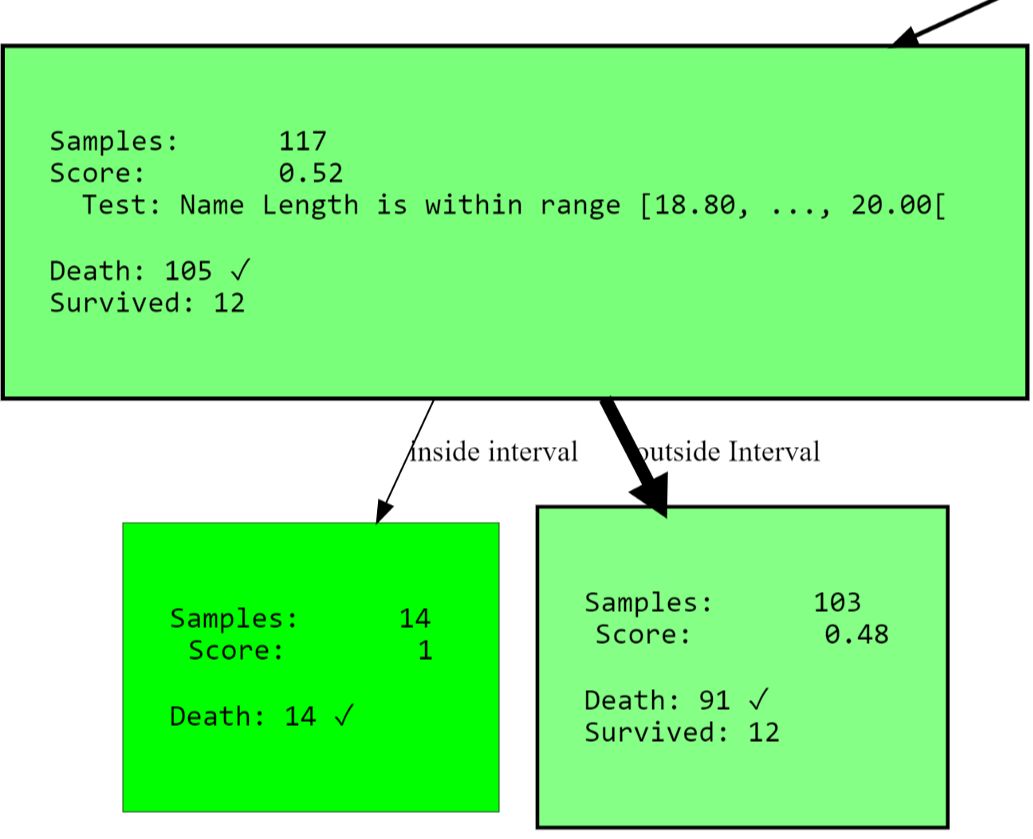
Level 0, ROOT: Node having 596 samples and 2 children with split rule "Split on Sex equals male" (Split Score:
0.251)
-Level 1, Child #1: Node having 390 samples and 2 children with split rule "Age is within range [28.00, ..., 31.00["
(Split Score: 0.342)
--Level 2, Child #1: Node having 117 samples and 2 children with split rule "Name Length is within range [18.80,
..., 20.00[" (Split Score: 0.543)
---Level 3, Child #1: Node having 14 samples and no children with
- SNIP -
Atau akses semua node bersih (dengan skor tinggi):
[str(node) for node in hdtree_titanic_3.get_clean_nodes(min_score=0.5)]
['Node having 117 samples and 2 children with split rule "Name Length is within range [18.80, ..., 20.00[" (Split
Score: 0.543)',
'Node having 14 samples and no children with split rule "no split rule" (Node Score: 1)',
'Node having 15 samples and no children with split rule "no split rule" (Node Score: 0.647)',
'Node having 107 samples and 2 children with split rule "Fare is within range [134.61, ..., 152.31[" (Split Score:
0.822)',
'Node having 102 samples and no children with split rule "no split rule" (Node Score: 0.861)']
Ekstensi HDTree
Hal terpenting yang mungkin ingin Anda tambahkan ke sistem adalah milik Anda sendiri
SplitRule. Aturan pemisahan benar-benar dapat melakukan apa pun yang ingin dipisahkan ... Menerapkan SplitRulemelalui implementasi AbstractSplitRule. Ini agak rumit karena Anda harus menangani sendiri penyerapan data, estimasi performa, dan semua itu sendiri. Untuk alasan ini, ada mixin dalam paket yang dapat Anda tambahkan ke implementasi, bergantung pada jenis pemisahannya. Mixin melakukan sebagian besar bagian yang sulit untuk Anda.
Bibliografi
- [1] Wikipedia article on Decision Trees
- [2] Medium 101 article on Decision Trees
- [3] Breiman, Leo, Joseph H Friedman, R. A. Olshen and C. J. Stone. “Classification and Regression Trees.” (1983).
- [4] scikit-learn documentation: Decision Tree Classifier
- [5] Cython project page
- [6] Wikipedia article on pruning
- [7] sklearn documentation: plot a Decision Tree
- [8] Wikipedia article Support Vector Machine
- [9] MLExtend Python library
- [10] Wikipedia Article Entropy in context of Decision Trees
- [12] Wikipedia Article on imputing
- [13] Hackernoon article about one-hot-encoding
- [14] Wikipedia Article about Quantiles
- [15] Hyafil, Laurent; Rivest, Ronald L. “Constructing optimal binary decision trees is NP-complete” (1976)
- [16] Hackernoon Article on Decision Trees
Cari tahu detail tentang cara mendapatkan profesi profil tinggi dari awal atau Naik Level dalam keterampilan dan gaji dengan mengikuti kursus online SkillFactory:
- Kursus Machine Learning (12 minggu)
- Kursus Lanjutan "Machine Learning Pro + Deep Learning" (20 minggu)
- « Machine Learning Data Science» (20 )
- «Python -» (9 )
E
