Di Surf, kami menulis penerjemah kami sendiri dan menggunakannya pada klien aplikasi seluler - meskipun pada awalnya, tampaknya, ini umumnya tidak ada hubungannya dengan pengembangan seluler. Faktanya, interpreter dan compiler adalah alat untuk memecahkan masalah yang dapat ditemukan di mana saja. Karena itu, memahami cara kerjanya dan mampu menulis sendiri itu berguna.
Hari ini, dengan menggunakan contoh menerjemahkan topeng dari satu format ke format lain, kita akan berkenalan dengan dasar-dasar membangun interpreter dan melihat bagaimana menggunakan tata bahasa formal, pohon sintaksis abstrak, aturan terjemahan - termasuk untuk memecahkan masalah bisnis.

Sedikit tentang topeng: apa itu dan mengapa Anda membutuhkannya
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
Mengapa Anda tidak bisa mengambil dan mendeskripsikan topengnya saja
Masker itu keren dan nyaman. Tetapi ada masalah yang tidak bisa dihindari dalam kondisi tertentu: ketika klien memiliki satu format topeng, dan server memiliki banyak penyedia data yang berbeda dan masing-masing memiliki format sendiri. Kami tidak dapat mengandalkan fakta bahwa kami akan memiliki format yang sama. Menanyakan ke server: "Sesuaikan masker untuk kami sesuka kami" - juga. Anda harus bisa menerimanya.
Masalahnya muncul: ada spesifikasi backend, Anda perlu menulis frontend - aplikasi seluler. Anda dapat menulis semua masker untuk aplikasi secara manual - dan ini adalah opsi yang baik jika hanya ada satu penyedia dan hanya ada sedikit masker. Programmer, tentu saja, harus meluangkan waktu untuk memahami setidaknya dua spesifikasi untuk mask: backend dan front. Kemudian dia perlu menerjemahkan topeng backend tertentu ke dalam topeng frontend yang sesuai. Ini juga membutuhkan waktu, ada faktor manusia - Anda bisa salah. Ini bukan pekerjaan yang mudah, terjemahan itu sulit: beberapa bahasa topeng ditulis terutama untuk komputer, bukan untuk manusia.
Jika tiba-tiba topeng di server berubah atau yang baru muncul, maka aplikasi, pertama-tama, mungkin berhenti berfungsi. Kedua, kerja keras penerjemahan perlu dilakukan lagi, aplikasi baru harus dirilis, ini membutuhkan waktu, tenaga, dan uang. Timbul pertanyaan: bagaimana cara meminimalkan pekerjaan programmer? Tampaknya semua ini harus dilakukan oleh mesin, tetapi untuk beberapa alasan seseorang melakukannya.
Jawabannya ya, kami punya solusinya. Masker ditulis dalam bahasa komputer - dan inilah salah satu alasan mengapa sulit bagi seseorang untuk bekerja dengannya dan menerjemahkan dari satu bahasa ke bahasa lain. Kita perlu mentransfer pekerjaan ini ke komputer. Karena topeng tampaknya merupakan tata bahasa formal , cara paling pasti untuk menerjemahkan satu tata bahasa ke tata bahasa lainnya adalah:
- memahami aturan untuk membangun tata bahasa asli,
- memahami aturan untuk membangun tata bahasa target,
- tulis aturan terjemahan dari tata bahasa sumber ke target,
- menerapkan semua ini dalam kode.
Untuk inilah penyusun dan penerjemah ditulis.
Sekarang mari kita lihat lebih dekat solusi kami berdasarkan tata bahasa formal.
Latar Belakang
Dalam aplikasi kami, ada beberapa layar berbeda yang dibentuk sesuai dengan prinsip penggerak backend: deskripsi lengkap layar berasal dari server bersama dengan datanya.

Sebagian besar layar berisi berbagai bentuk masukan. Server menentukan bidang apa yang ada di formulir dan bagaimana mereka harus diformat. Masker juga digunakan untuk menjelaskan persyaratan ini.
Mari kita lihat cara kerja topeng.
Contoh topeng dalam berbagai format
Sebagai contoh pertama, mari kita ambil bentuk yang sama dengan memasukkan nomor telepon. Topeng untuk bentuk seperti itu mungkin terlihat seperti ini.

Di satu sisi, topeng itu sendiri menambahkan pembatas, tanda kurung dan melarang memasukkan karakter yang salah. Di sisi lain, mask yang sama mengekstrak informasi yang berguna dari input yang diformat untuk dikirim ke server.
Bagian yang disebut konstanta disorot dengan warna merah. Ini adalah simbol yang akan muncul secara otomatis - pengguna tidak boleh memasukkannya:

Berikutnya adalah bagian dinamis - selalu diapit oleh tanda kurung siku:

Selanjutnya dalam teks saya akan menyebut ungkapan ini "ekspresi dinamis" - atau disingkat DW
Berikut adalah ekspresi yang akan kami

gunakan untuk memformat masukan kami: Potongan yang bertanggung jawab atas konten bagian dinamis disorot dengan warna merah.
\\ d - digit apapun.
+ - pengulang reguler: ulangi setidaknya sekali.
$ {3} adalah simbol informasi meta yang menentukan jumlah pengulangan. Dalam kasus ini, harus ada tiga karakter.
Kemudian ekspresi \\ d + $ {3} berarti harus ada tiga digit.
Dalam format topeng ini, hanya ada satu pengulang di dalam bagian dinamis:

Batasan ini muncul karena suatu alasan - sekarang saya akan menjelaskan alasannya.
Katakanlah kita memiliki DV, di mana ukurannya adalah hard-code: 4 elemen. Dan kami memberinya 2 elemen dengan pengulang: `<! ^ \\ d + \\ v + $ {4}>`. Kombinasi berikut termasuk dalam DV seperti itu:
- 1abc
- 12ab
- 123a
Ternyata DV seperti itu tidak memberi kita jawaban yang tidak ambigu, apa yang diharapkan menggantikan karakter kedua: angka atau huruf.
Ambil topengnya, tambahkan dengan input pengguna. Kami mendapatkan nomor telepon yang diformat:

Pada klien, format topeng mungkin terlihat berbeda. Misalnya, di perpustakaan Input Mask dari Redmadrobot, mask untuk nomor telepon

terlihat seperti ini: Terlihat lebih bagus dan lebih mudah dimengerti.
Ternyata mask untuk server dan mask untuk klien ditulis secara berbeda, tetapi keduanya melakukan hal yang sama.

Mari kita rumuskan kembali masalahnya: bagaimana menggabungkan topeng dari format yang berbeda
Kita perlu menggabungkan topeng ini satu sama lain - atau entah bagaimana mendapatkan yang kedua dari satu.
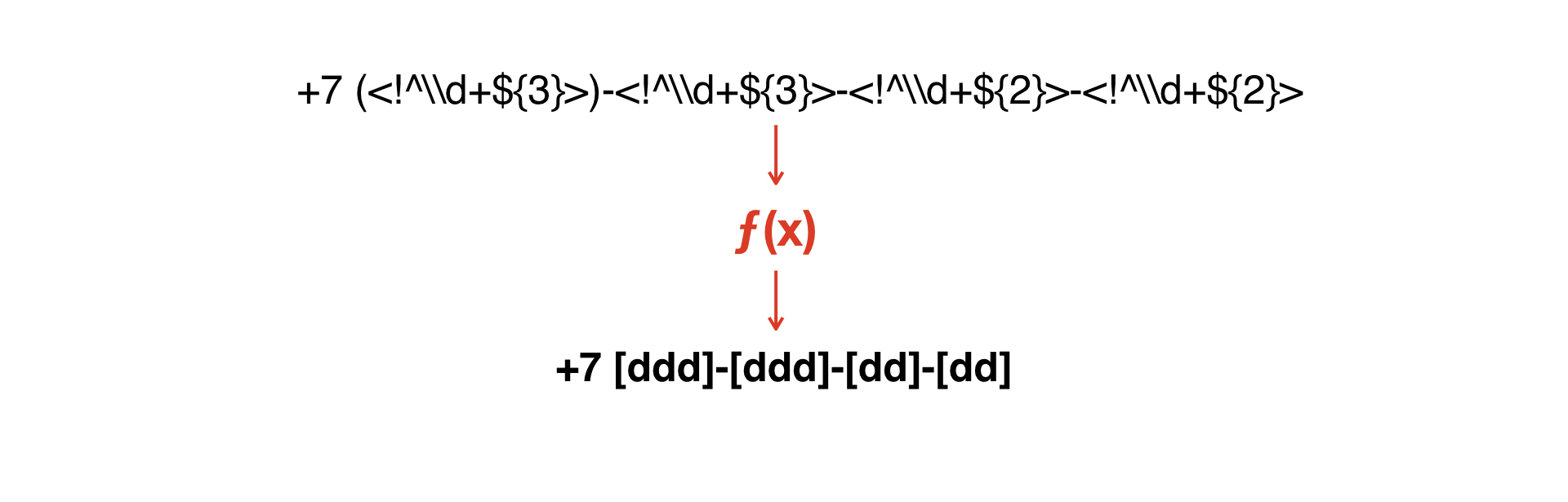
Kita perlu membangun fungsi yang akan mengubah satu topeng menjadi yang kedua.
Dan di sini muncul ide untuk menulis penerjemah yang sangat sederhana yang memungkinkan mendapatkan tata bahasa kedua dari satu tata bahasa.
Sejak kita sampai pada penerjemah, mari kita bicara tentang tata bahasa.
Bagaimana penguraian dilakukan
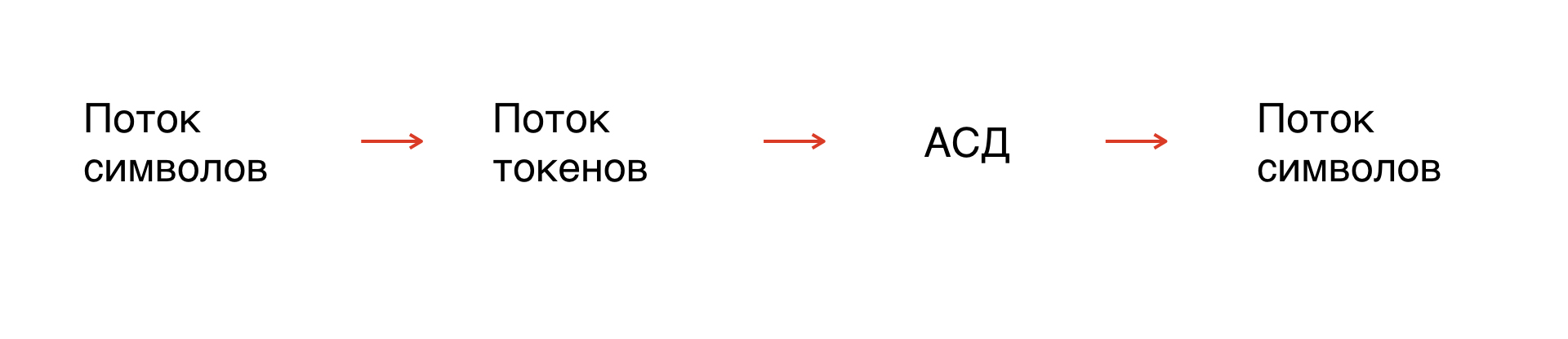
Pertama, kami memiliki aliran karakter - topeng kami. Faktanya, ini adalah string yang kami operasikan. Tetapi karena simbol tidak diformalkan, Anda perlu memformalkan string: pisahkan menjadi elemen yang dapat dimengerti oleh penerjemah.
Proses ini disebut tokenisasi: aliran simbol berubah menjadi aliran token. Jumlah token terbatas, mereka diformalkan, oleh karena itu, dapat dianalisis.
Selanjutnya, berdasarkan aturan tata bahasa, kami membangun pohon sintaks abstrak di sepanjang aliran token. Dari pohon kita mendapatkan aliran simbol dalam tata bahasa yang kita butuhkan.
Ada ekspresi. Kami melihatnya dan melihat bahwa kami memiliki konstanta, yang saya bicarakan di atas: Kami

mewakili semua konstanta sebagai token CS, yang argumennya adalah konstanta itu sendiri:

Jenis token berikutnya adalah permulaan DW:

Selanjutnya, semua token tersebut akan diinterpretasikan sebagai karakter khusus. Dalam contoh kami, tidak banyak dari mereka, dalam topeng sungguhan ada lebih banyak dari mereka.

Lalu kami memiliki repeater.
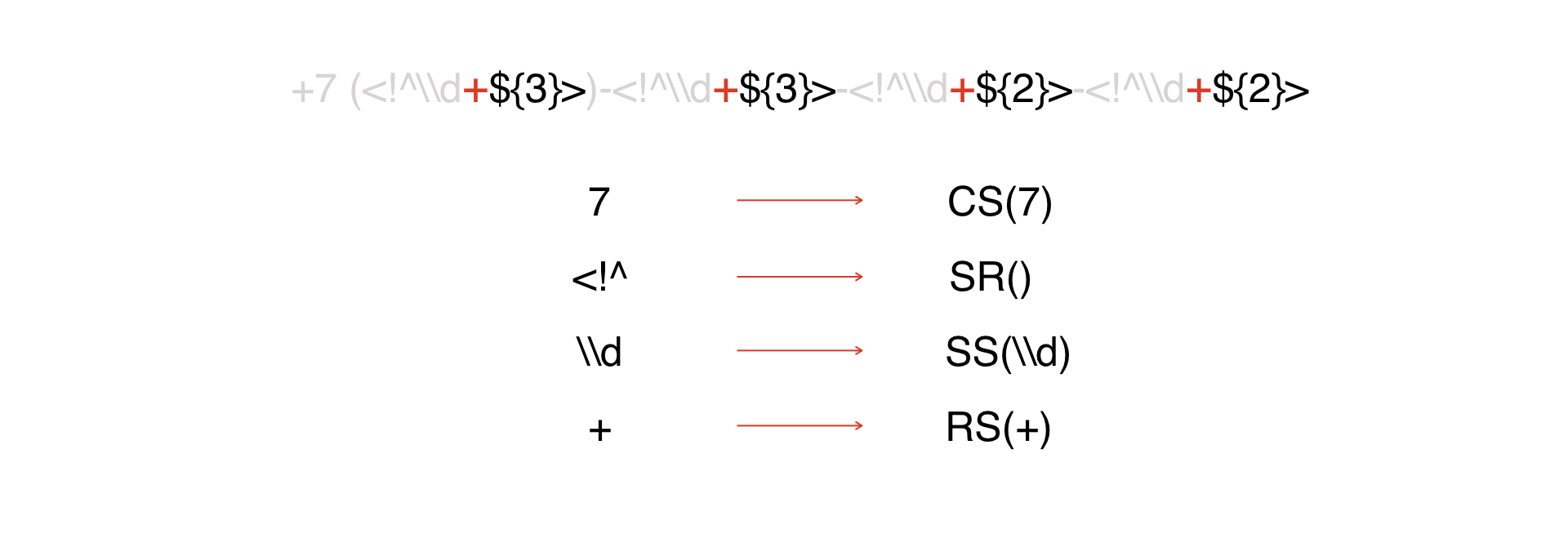
Kemudian - beberapa karakter yang dianggap metadata. Kami akan menipu dan memberi mereka satu token, karena lebih mudah seperti itu.

Akhir dari Timur Jauh. Jadi, kami telah menguraikan semuanya menjadi token.

Contoh tokenisasi topeng untuk nomor telepon
Untuk melihat bagaimana, pada prinsipnya, proses tokenisasi berlangsung dan bagaimana penerjemah akan bekerja, kami mengambil masker untuk nomor telepon dan mengubahnya menjadi aliran token.

Pertama, simbol +. Ubah menjadi + konstan. Kemudian kami melakukan hal yang sama untuk 7 dan untuk semua simbol lainnya. Kami mendapatkan berbagai token. Ini belum menjadi struktur - kami akan menganalisis array ini lebih lanjut.
Lexer dan membangun ASD
Sekarang bagian yang sulit adalah lexer.

Di sebelah kiri, dijelaskan legenda - karakter khusus yang digunakan untuk menjelaskan aturan leksikal. Di sebelah kanan adalah aturannya sendiri.
SymbolRule menggambarkan sebuah simbol. Jika aturan ini berlaku, jika benar, itu berarti kita telah menemukan karakter khusus atau karakter konstan. Kita dapat mengatakan bahwa ini adalah suatu fungsi.
Berikutnya adalah repeaterRule. Aturan ini menjelaskan situasi ketika karakter ditemui, diikuti oleh token pengulang.
Kemudian semuanya terlihat serupa. Jika LW, maka itu adalah simbol atau repeater. Dalam kasus kami, aturan ini lebih luas. Dan pada akhirnya harus ada token dengan metadata.
Aturan terakhir adalah maskRule. Ini adalah urutan simbol dan DV.
Sekarang mari kita bangunpohon sintaksis abstrak (AST) dari larik token.
Berikut adalah daftar tokennya. Simpul pertama dari pohon adalah simpul akar, dari situ kita akan mulai membangun. Tidak masuk akal, ini hanya membutuhkan root.

Kami memiliki token pertama +, jadi kami hanya menambahkan simpul anak, dan hanya itu.

Kami melakukan hal yang sama dengan semua simbol konstanta lainnya, tetapi kemudian ini lebih rumit. Kami menemukan token DV.

Ini bukan hanya situs biasa - kami tahu bahwa situs itu pasti memiliki beberapa jenis konten.

Node konten hanyalah node teknis yang dapat kita tuju di masa mendatang. Ia memiliki simpul anak sendiri dan simpul mana yang akan dimilikinya selanjutnya? Token berikutnya di aliran kami adalah karakter khusus. Apakah itu simpul anak?

Sebenarnya, dalam kasus ini, tidak. Kami akan memiliki repeater sebagai simpul anak.

Mengapa? Karena lebih nyaman bekerja dengan kayu di masa depan. Katakanlah kita ingin mengurai pohon ini dan membangun semacam tata bahasa darinya. Saat mengurai pohon, kami melihat jenis node. Jika kita memiliki node CS, maka kita menguraikannya menjadi node CS yang sama, tetapi untuk tata bahasa yang berbeda. Secara konvensi, kami mengulangi bagian atas pohon dan menjalankan semacam logika.
Logikanya bergantung pada jenis node - atau jenis token yang terletak di node. Untuk penguraian, jauh lebih mudah untuk segera memahami token mana yang ada di depan Anda: komposit, seperti repeater, atau sederhana, seperti CS. Ini diperlukan agar tidak ada interpretasi ganda atau pencarian konstan untuk simpul anak.
Ini akan terlihat terutama pada kelompok karakter: misalnya, [abcde]. Dalam hal ini, tentunya harus ada semacam node GROUP induk yang akan memiliki daftar node anak CS (a) CS (b), dll.
Kembali ke token dengan metadata. Itu tidak termasuk dalam konten, itu ada di samping.

Ini diperlukan untuk membuatnya lebih mudah untuk bekerja dengan pohon, sehingga kita tidak mempertimbangkan konten simpul ini - karena sebenarnya bukan miliknya.
DV berakhir, dan kami tidak menganggapnya sebagai semacam node: itu adalah token yang sekarang dapat dibuang. Kami tidak akan mengubahnya menjadi simpul pohon.
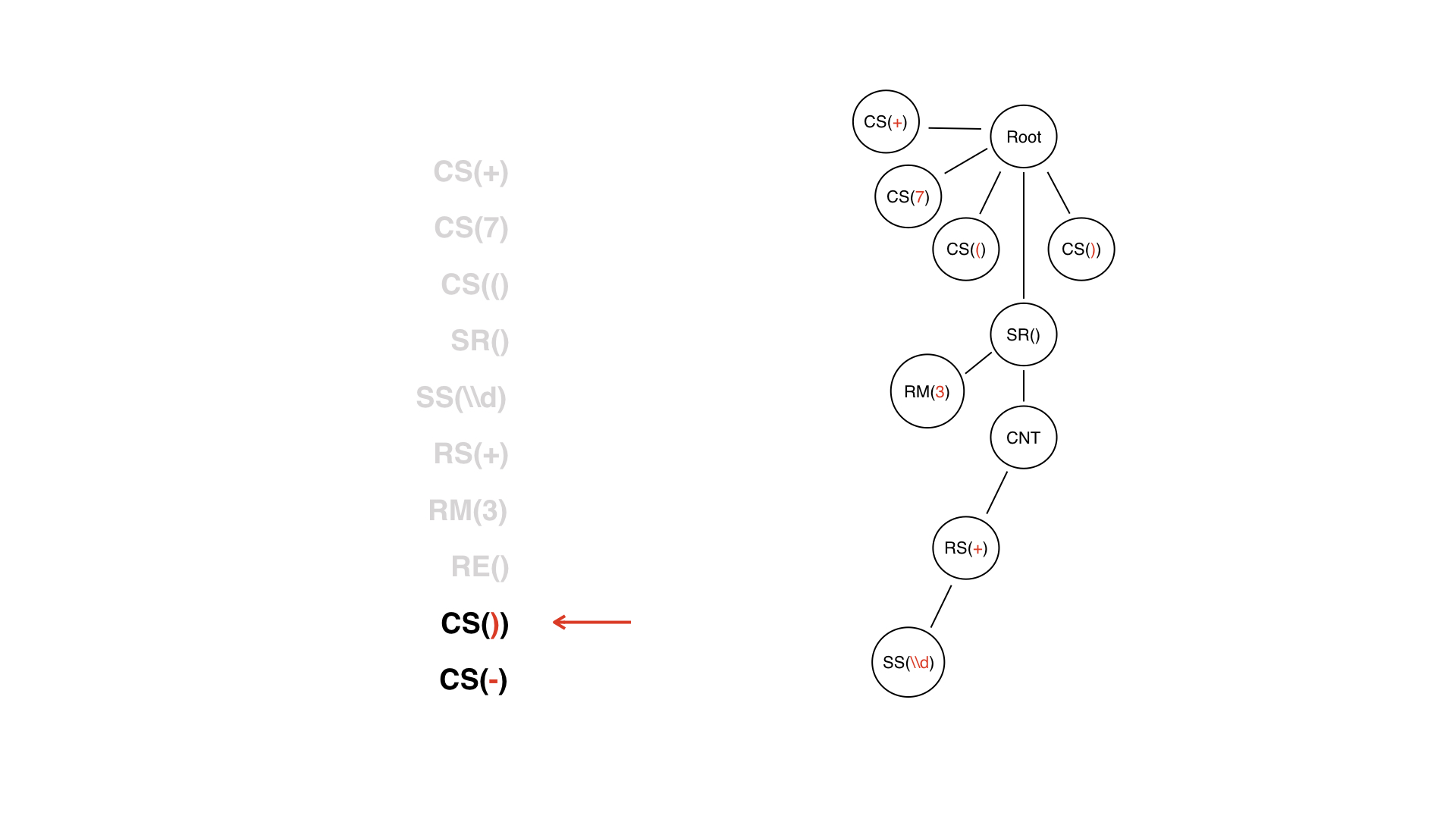
Kami sudah memiliki subpohon, yang akarnya adalah simpul SR - yaitu, bagian yang sangat dinamis. Akhir dari token LW sangat membantu kami dalam proses pembangunan pohon - kami dapat memahami kapan subtree untuk LW selesai. Tetapi token ini tidak memiliki nilai untuk logika: melihat pohon baris demi baris, kita sudah memahami kapan DW akan berakhir, karena DW seolah-olah ditutup oleh simpul SR.
Selanjutnya - hanya simbol konstan biasa.

Kami punya pohon. Sekarang mari kita telusuri pohon ini secara mendalam dan membangun atas dasar beberapa tata bahasa lain: Anda perlu masuk ke sebuah simpul, melihat jenis simpul itu, dan menghasilkan elemen tata bahasa lain dari simpul ini.
Sintaks pustaka InputMask oleh Redmadrobot
Mari kita lihat sintaks pustaka Redmadrobot.

Ini ekspresi yang sama. +7 adalah konstanta yang akan ditambahkan secara otomatis. Di dalam kurung kurawal, DV dijelaskan - bagian dinamis. Di dalam DV ada karakter khusus d. Redmadrobot memiliki notasi default yang menunjukkan digit.
Seperti inilah notasi itu:

Notasi terdiri dari tiga bagian:
- karakter adalah karakter yang akan kita gunakan untuk menulis topeng. Terdiri dari apa alfabet topeng. Misalnya, d.
- characterSet - karakter mana yang diketik oleh pengguna yang cocok dengan notasi ini. Misalnya 0, 1, 2, 3, 4, dan seterusnya.
- isOptional - apakah pengguna harus memasukkan salah satu karakter characterSet atau tidak memasukkan apapun.
Lihat, sekarang kita punya topeng seperti itu.

- Karakter "b" memiliki notasi digit khusus dan bukan opsional.
- Karakter "c" memiliki notasi yang berbeda - CharacterSet berbeda. Ini juga tidak opsional.
- Dan karakter "C" sama dengan "c", hanya saja opsional. Ini diperlukan agar di dalam mask kita melihat metadata dan melihat bahwa tidak ada batasan yang tegas, tetapi yang lemah.
Jika Anda perlu menulis aturan saat terdapat satu hingga sepuluh karakter, maka satu karakter tidak akan menjadi opsional. Dan sembilan karakter akan menjadi opsional. Artinya, pada notasi dari contoh tersebut akan ditulis dengan huruf kapital. Hasilnya, aturan ini akan terlihat seperti ini: [cCCCCCCCCC]
Contoh: menerjemahkan topeng nomor telepon dari format backend ke format InputMask
Ini pohon yang kita dapatkan di langkah terakhir. Kita harus berjalan di atasnya. Hal pertama yang kita dapatkan adalah akarnya.

Lebih jauh dari akarnya, kita menemukan diri kita dalam simbol konstan + - kita segera menghasilkan +. Di sebelah kanan, mask ditulis dalam format InputMask.

Karakter berikutnya dapat dimengerti - hanya 7, diikuti dengan tanda kurung buka.
Kemudian sepotong bagian dinamis dibuat, tetapi belum diisi.

Kami masuk ke dalam, kami memiliki konten, ini adalah simpul teknis. Kami tidak menulis apa pun di mana pun.

Di sini kami memiliki repeater, kami juga tidak menulis apa pun di mana pun, karena tidak ada simbol seperti itu di topeng. Aturan seperti itu tidak dapat ditulis.

Akhirnya, kita sampai pada semacam simbol konten.
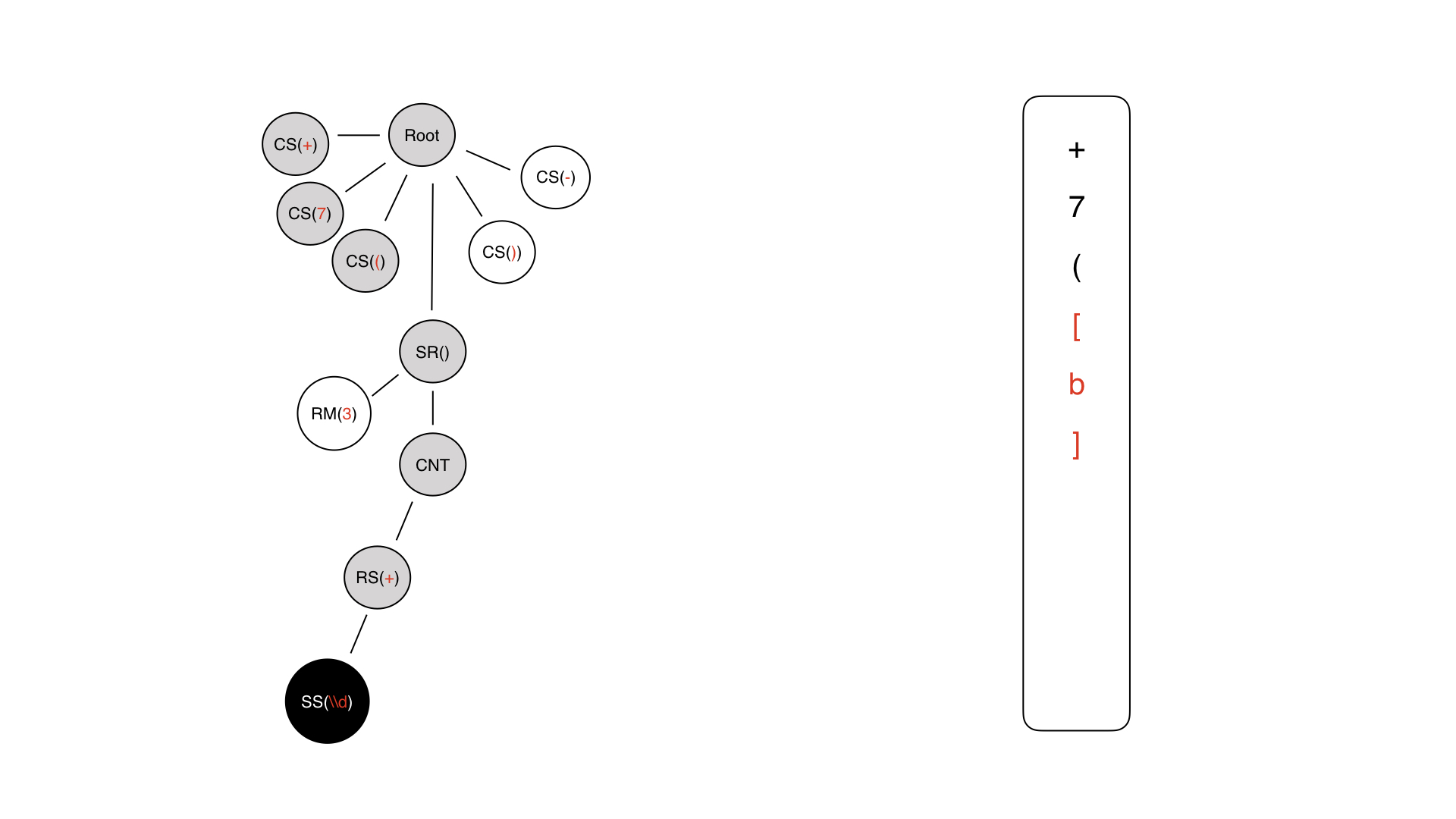
Simbol konten dapat berupa simbol konstan atau simbol khusus. Dalam hal ini, yang khusus digunakan, karena hanya membawa semacam beban semantik untuk input.
Jadi kami menulisnya, kami kembali dan pergi hanya untuk informasi meta.

Mari kita lihat bahwa kami memiliki repeater di sana dan di sini kami memiliki 3 - batas keras. Oleh karena itu, kami mengulanginya tiga kali dan kami mendapatkan karya yang begitu dinamis. Kemudian kami menambahkan simbol konstanta kami.

Hasilnya, kami mendapatkan topeng yang terlihat seperti topeng dalam format robot.
Dalam praktiknya, kami mengambil satu tata bahasa dan menghasilkan tata bahasa lain darinya.
Aturan untuk menghasilkan tata bahasa sisi klien dari sisi server
Sekarang sedikit tentang aturan generasi. Itu penting.
Mungkin ada kasus yang sulit seperti itu: di dalam bagian dinamis ada beberapa DW yang berbeda. Di dalam kurung kurawal: ini sama seperti di DV - satu dari banyak. Mari kita lihat bagaimana penerjemah akan menangani situasi ini.

Pertama, himpunan karakter dan kita harus mengubahnya menjadi semacam notasi dalam istilah InputMask. Mengapa? Karena ini adalah semacam kumpulan karakter terbatas yang perlu kita cocokkan. Kita perlu menggabungkan input pengguna dan karakter, dan oleh karena itu kita akan memiliki beberapa notasi khusus yang tertulis di sini.
Selanjutnya kita memiliki karakter \\ d.
Lebih lanjut - DV dengan ukuran opsional.

Yang pertama, ternyata, adalah beberapa karakter b. Ini akan memiliki Set Karakter yang berisi abcd.
Lebih lanjut, jelas bahwa akan ada simbol yang berbeda, karena Anda tidak akan menambalnya secara berbeda, atau Anda akan menambalnya dengan tidak benar. Dan kemudian ungkapan ini berubah menjadi seperti ini.
Bagian terakhir harus mengandung setidaknya satu simbol. Mari kita tentukan persyaratan ini sebagai d. Tetapi juga pengguna dapat memasukkan dua karakter tambahan, dan kemudian mereka ditetapkan sebagai DD.
Menyatukan semuanya.

Berikut adalah contoh Kumpulan Karakter yang dibuat. Dapat dilihat bahwa b terkait dengan Kumpulan Karakter abcd, untuk angka - Kumpulan Karakter yang telah ditetapkan sebelumnya. Untuk d dan D, Set Karakter yang sesuai berisi 12vf.
Hasil
Kami telah belajar untuk secara otomatis mengonversi satu tata bahasa ke yang lain: sekarang masker sesuai dengan spesifikasi server yang berfungsi dalam aplikasi kami.
Fitur lain yang kami dapatkan secara gratis adalah kemampuan untuk melakukan analisis statis dari topeng yang datang kepada kami. Artinya, kita bisa memahami jenis keyboard apa yang dibutuhkan untuk mask ini dan berapa jumlah maksimal karakter yang bisa di mask ini. Dan bahkan lebih keren lagi, karena sekarang kami tidak menampilkan keyboard yang sama sepanjang waktu untuk setiap elemen formulir - kami menampilkan keyboard yang diperlukan di bawah elemen formulir yang diperlukan. Dan juga kita dapat secara kondisional mendefinisikan dengan tepat bahwa beberapa bidang adalah bidang masukan telepon.
Kiri: di bagian atas bidang input telepon terdapat ikon (sebenarnya adalah tombol) yang akan mengarahkan pengguna ke daftar kontak. Kanan: Contoh keyboard untuk pesan teks biasa.
Perpustakaan kerja untuk menerjemahkan topeng
Anda dapat melihat bagaimana kami menerapkan pendekatan di atas. Perpustakaannya terletak di GitHub .
Contoh menerjemahkan berbagai topeng
Ini adalah topeng pertama yang kami lihat di awal. Itu diinterpretasikan ke dalam representasi RedMadRobot ini.

Dan ini adalah topeng kedua - hanya topeng masukan untuk sesuatu. Itu diubah menjadi representasi seperti itu.
