pengantar
Artikel ini adalah kompilasi dari artikel lain . Di dalamnya, saya bermaksud berkonsentrasi pada alat untuk bekerja dengan Big data yang berfokus pada analisis data.
Jadi, katakanlah Anda menerima data mentah, memprosesnya, dan sekarang siap untuk digunakan lebih lanjut.
Ada banyak alat yang digunakan untuk memanipulasi data, masing-masing dengan kelebihan dan kekurangannya sendiri. Sebagian besar berorientasi OLAP, tetapi beberapa juga dioptimalkan OLTP. Beberapa dari mereka menggunakan format standar dan hanya fokus pada eksekusi kueri, yang lain menggunakan format atau penyimpanan mereka sendiri untuk mentransfer data yang diproses ke sumber untuk meningkatkan kinerja. Beberapa dioptimalkan untuk menyimpan data menggunakan skema tertentu, seperti bintang atau kepingan salju, tetapi yang lain lebih fleksibel. Kesimpulannya, kami memiliki pertentangan berikut:
- Gudang Data vs. Danau
- Hadoop vs. Penyimpanan Offline
- OLAP vs OLTP
- Mesin kueri versus mekanisme OLAP
Kami juga akan melihat alat untuk memproses data dengan kemampuan untuk mengeksekusi kueri.
Alat pengolah data
Sebagian besar alat yang disebutkan dapat terhubung ke server metadata seperti Hive dan menjalankan kueri, membuat tampilan, dll. Ini sering digunakan untuk membuat tingkat pelaporan tambahan (ditingkatkan).
Spark SQL menyediakan cara untuk mencampur kueri SQL dengan program Spark dengan mulus, sehingga Anda dapat mencampur DataFrame API dengan SQL. Ini memiliki integrasi Hive dan koneksi JDBC atau ODBC standar, sehingga Anda dapat menghubungkan Tableau, Looker, atau alat BI apa pun ke data Anda melalui Spark.

Apache Flinkjuga menyediakan SQL API. Dukungan SQL Flink didasarkan pada Apache Calcite, yang mengimplementasikan standar SQL. Ini juga terintegrasi dengan Hive melalui HiveCatalog. Misalnya, pengguna dapat menyimpan tabel Kafka atau ElasticSearch di Hive Metastore menggunakan HiveCatalog dan menggunakannya kembali nanti dalam kueri SQL.
Kafka juga menyediakan kemampuan SQL. Secara umum, sebagian besar alat pemrosesan data menyediakan antarmuka SQL.
Alat Kueri
Jenis alat ini difokuskan pada kueri terpadu ke berbagai sumber data dalam format berbeda. Idenya adalah untuk merutekan kueri ke data lake Anda menggunakan SQL seolah-olah itu adalah database relasional biasa, meskipun memiliki beberapa batasan. Beberapa alat ini juga dapat meminta database NoSQL dan banyak lagi. Alat ini menyediakan antarmuka JDBC ke alat eksternal seperti Tableau atau Looker untuk terhubung ke data lake Anda dengan aman. Alat kueri adalah opsi paling lambat, tetapi memberikan fleksibilitas paling besar.
Apache Pig: salah satu alat pertama selain Hive. Memiliki bahasanya sendiri selain SQL. Ciri khas dari program yang dibuat oleh Pig adalah bahwa strukturnya cocok untuk paralelisasi yang signifikan, yang, pada gilirannya, memungkinkan mereka untuk memproses kumpulan data yang sangat besar. Oleh karena itu, sistem ini masih belum ketinggalan zaman dibandingkan dengan sistem berbasis SQL modern.
Presto: Platform open source dari Facebook. Ini adalah mesin kueri SQL terdistribusi untuk melakukan kueri analitik interaktif terhadap sumber data dari berbagai ukuran. Presto memungkinkan Anda untuk menanyakan data di mana pun itu, termasuk Hive, Cassandra, database relasional, dan sistem file. Itu dapat meminta kumpulan data besar dalam hitungan detik. Presto tidak bergantung pada Hadoop, tetapi terintegrasi dengan sebagian besar alatnya, terutama Hive, untuk mengeksekusi kueri SQL.
Apache Drill: Menyediakan mesin kueri SQL tanpa skema untuk Hadoop, NoSQL, dan bahkan penyimpanan cloud. Itu tidak bergantung pada Hadoop, tetapi memiliki banyak integrasi dengan alat ekosistem seperti Hive. Satu kueri dapat menggabungkan data dari beberapa penyimpanan, melakukan pengoptimalan khusus untuk masing-masing penyimpanan. Ini sangat bagus karena memungkinkan analis untuk memperlakukan data apa pun sebagai tabel, meskipun mereka benar-benar membaca file. Bor sepenuhnya mendukung SQL standar. Pengguna bisnis, analis, dan ilmuwan data dapat menggunakan alat kecerdasan bisnis standar seperti Tableau, Qlik, dan Excel untuk berinteraksi dengan penyimpanan data non-relasional menggunakan penggerak Drill JDBC dan ODBC. Selain,pengembang dapat menggunakan REST API Drill sederhana dalam aplikasi kustom mereka untuk membuat visualisasi yang indah.
Database OLTP
Meskipun Hadoop dioptimalkan untuk OLAP, masih ada situasi di mana Anda ingin menjalankan kueri OLTP terhadap aplikasi interaktif.
HBase memiliki sifat ACID yang sangat terbatas berdasarkan desain karena dibuat dengan skala dan tidak menyediakan kemampuan ACID di luar kotak, tetapi dapat digunakan untuk beberapa skenario OLTP.
Apache Phoenix dibangun di atas HBase dan menyediakan cara untuk membuat kueri OTLP di seluruh ekosistem Hadoop. Apache Phoenix terintegrasi penuh dengan produk Hadoop lainnya seperti Spark, Hive, Pig, Flume, dan Map Reduce. Itu juga dapat menyimpan metadata, mendukung pembuatan tabel dan perubahan versi inkremental menggunakan perintah DDL. Ini bekerja cukup cepat, lebih cepat daripada menggunakan Bor atau lainnya
mekanisme permintaan.
Anda dapat menggunakan database berskala besar di luar ekosistem Hadoop seperti Cassandra, YugaByteDB, ScyllaDB untuk OTLP.
Terakhir, sangat umum bahwa database cepat jenis apa pun, seperti MongoDB atau MySQL, memiliki subset data yang lebih lambat, biasanya yang terbaru. Mekanisme kueri yang disebutkan di atas dapat menggabungkan data antara penyimpanan lambat dan cepat dalam satu kueri.
Pengindeksan Terdistribusi
Alat ini menyediakan cara untuk menyimpan dan mengambil data teks tidak terstruktur, dan mereka tinggal di luar ekosistem Hadoop karena mereka memerlukan struktur khusus untuk menyimpan data. Idenya adalah menggunakan indeks terbalik untuk melakukan pencarian cepat. Selain pencarian teks, teknologi ini dapat digunakan untuk berbagai keperluan, seperti menyimpan log, acara, dll. Ada dua opsi utama:
Solr: Ini adalah platform pencarian perusahaan open source yang populer dan sangat cepat yang dibangun di atas Apache Lucene. Solr adalah alat yang tangguh, dapat diskalakan, dan tangguh, menyediakan pengindeksan terdistribusi, kueri replikasi dan penyeimbangan beban, failover dan pemulihan otomatis, konfigurasi terpusat, dan banyak lagi. Ini bagus untuk pencarian teks, tetapi kasus penggunaannya terbatas dibandingkan dengan ElasticSearch.
ElasticSearch: Ini juga merupakan indeks terdistribusi yang sangat populer, tetapi telah tumbuh menjadi ekosistemnya sendiri yang mencakup banyak kasus penggunaan seperti APM, penelusuran, penyimpanan teks, analitik, dasbor, pembelajaran mesin, dan banyak lagi. Ini jelas merupakan alat untuk dimiliki di kotak alat Anda baik untuk DevOps atau pipeline data karena sangat serbaguna. Itu juga dapat menyimpan dan mencari video dan gambar.
ElasticSearchdapat digunakan sebagai lapisan penyimpanan cepat untuk data lake Anda untuk fungsionalitas penelusuran lanjutan. Jika Anda menyimpan data Anda dalam database nilai kunci yang besar seperti HBase atau Cassandra, yang menyediakan kemampuan pencarian sangat terbatas karena kurangnya koneksi, Anda dapat meletakkan ElasticSearch di depannya untuk menjalankan kueri, mengembalikan ID, dan kemudian melakukan pencarian cepat di database Anda.
Ini juga dapat digunakan untuk analitik. Anda dapat mengekspor data Anda, mengindeksnya, dan kemudian menanyakannya menggunakan KibanaDengan membuat dasbor, laporan, dan lainnya, Anda dapat menambahkan histogram, agregasi kompleks, dan bahkan menjalankan algoritme pembelajaran mesin di atas data Anda. Ekosistem ElasticSearch sangat besar dan layak untuk dijelajahi.
Database OLAP
Di sini kita melihat database yang juga dapat menyediakan penyimpanan metadata untuk skema kueri. Dibandingkan dengan sistem eksekusi kueri, alat ini juga menyediakan penyimpanan data dan dapat diterapkan ke skema penyimpanan tertentu (skema bintang). Alat-alat ini menggunakan sintaks SQL. Spark atau platform lain dapat berinteraksi dengannya.
Apache sarang: kita telah membahas Hive sebagai repositori skema pusat untuk Spark dan alat lainnya sehingga mereka dapat menggunakan SQL, tetapi Hive juga dapat menyimpan data, sehingga Anda dapat menggunakannya sebagai repositori. Dia dapat mengakses HDFS atau HBase. Saat diminta oleh Hive, ini menggunakan Apache Tez, Apache Spark, atau MapReduce, yang jauh lebih cepat daripada Tez atau Spark. Ini juga memiliki bahasa prosedural yang disebut HPL-SQL. Hive adalah penyimpanan meta data yang sangat populer untuk Spark SQL.
Apache Impala: Ini adalah database analitik asli untuk Hadoop yang dapat Anda gunakan untuk menyimpan data dan menanyakannya secara efisien. Dia dapat terhubung ke Hive untuk mendapatkan metadata menggunakan Hcatalog. Impala menyediakan latensi rendah dan konkurensi tinggi untuk kecerdasan bisnis dan kueri analitik di Hadoop (yang tidak disediakan oleh platform terpaket seperti Apache Hive). Impala juga menskalakan secara linier, bahkan di lingkungan multi-pengguna, yang merupakan alternatif kueri yang lebih baik daripada Hive. Impala terintegrasi dengan keamanan milik Hadoop dan Kerberos untuk autentikasi, sehingga Anda dapat mengelola akses data dengan aman. Ini menggunakan HBase dan HDFS untuk penyimpanan data.

Apache Tajo: Ini adalah gudang data lain untuk Hadoop. Tajo dirancang untuk melakukan kueri ad-hoc dengan latensi dan skalabilitas rendah, agregasi online, dan ETL untuk kumpulan data besar yang disimpan di HDFS dan sumber data lainnya. Ini mendukung integrasi dengan Hive Metastore untuk mengakses skema umum. Ia juga memiliki banyak pengoptimalan kueri, skalabel, toleran terhadap kesalahan, dan menyediakan antarmuka JDBC.
Apache Kylin: Ini adalah gudang data analitik terdistribusi baru. Kylin sangat cepat, sehingga dapat digunakan untuk melengkapi beberapa database lain seperti Hive untuk kasus penggunaan di mana performa sangat penting, seperti dasbor atau laporan interaktif. Ini mungkin gudang data OLAP terbaik, tetapi sulit digunakan. Masalah lain adalah bahwa lebih banyak ruang penyimpanan diperlukan karena peregangan yang tinggi. Idenya adalah jika mesin kueri atau Hive tidak cukup cepat, Anda dapat membuat "Cube" di Kylin, yang merupakan tabel multidimensi yang dioptimalkan OLAP dengan pra-penghitungan
nilai yang dapat Anda kueri dari dasbor atau laporan interaktif. Itu dapat membuat kubus langsung dari Spark dan bahkan mendekati waktu nyata dari Kafka.
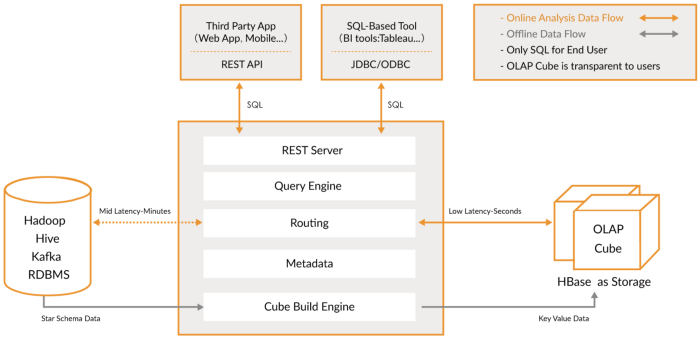
Alat OLAP
Dalam kategori ini, saya menyertakan mesin yang lebih baru, yang merupakan evolusi dari database OLAP sebelumnya, yang menyediakan lebih banyak fungsionalitas, membuat platform analitik yang komprehensif. Faktanya, mereka adalah campuran dari dua kategori sebelumnya yang menambahkan pengindeksan ke database OLAP Anda. Mereka tinggal di luar platform Hadoop tetapi terintegrasi erat. Dalam kasus ini, Anda biasanya melewati langkah pemrosesan dan menggunakan alat tersebut secara langsung.
Mereka mencoba memecahkan masalah kueri data waktu nyata dan data historis dengan cara yang seragam, sehingga Anda dapat segera membuat kueri data waktu nyata segera setelah tersedia, bersama dengan data historis latensi rendah sehingga Anda dapat membangun aplikasi dan dasbor interaktif. Alat ini memungkinkan, dalam banyak kasus, untuk membuat kueri data mentah dengan sedikit atau tanpa transformasi gaya ELT, tetapi dengan kinerja tinggi, lebih baik daripada database OLAP konvensional.
Kesamaan yang mereka miliki adalah bahwa mereka menyediakan tampilan data terpadu, penyerapan data langsung dan batch, pengindeksan terdistribusi, format data asli, dukungan SQL, antarmuka JDBC, dukungan data panas dan dingin, beberapa integrasi, dan penyimpanan metadata.
Apache Druid: Ini adalah mesin OLAP real-time paling terkenal. Ini difokuskan pada data deret waktu, tetapi dapat digunakan untuk data apa pun. Ini menggunakan format kolomnya sendiri yang dapat memampatkan banyak data, dan memiliki banyak pengoptimalan bawaan seperti indeks terbalik, pengkodean teks, data yang menciut secara otomatis, dan banyak lagi. Data dimuat dalam waktu nyata menggunakan Tranquility atau Kafka, yang memiliki latensi sangat rendah, disimpan dalam memori dalam format string yang dioptimalkan untuk penulisan, tetapi segera setelah tiba, data tersedia untuk membuat kueri seperti data yang diunduh sebelumnya. Proses latar belakang bertanggung jawab untuk memindahkan data secara asinkron ke sistem penyimpanan dalam seperti HDFS. Ketika data dipindahkan ke penyimpanan dalam, itu dibagi menjadi beberapa bagian yang lebih kecil,waktu terpisah, yang disebut segmen, yang dioptimalkan dengan baik untuk kueri latensi rendah. Segmen ini memiliki stempel waktu untuk beberapa dimensi yang dapat Anda gunakan untuk memfilter dan menggabungkan, dan metrik, yang merupakan status yang telah dihitung sebelumnya. Dalam penerimaan burst, data disimpan langsung ke dalam segmen. Apache Druid mendukung push and pull swallowing, integrasi dengan Hive, Spark, dan bahkan NiFi. Ini dapat menggunakan penyimpanan metadata Hive dan mendukung kueri SQL Hive, yang kemudian diubah menjadi kueri JSON yang digunakan oleh Druid. Integrasi Hive mendukung JDBC, sehingga Anda dapat menyambungkan alat BI apa pun. Ia juga memiliki repositori metadata sendiri, biasanya MySQL digunakan untuk ini.Ini dapat menerima data dalam jumlah besar dan berskala dengan sangat baik. Masalah utamanya adalah ia memiliki banyak komponen dan sulit untuk dikelola dan diterapkan.
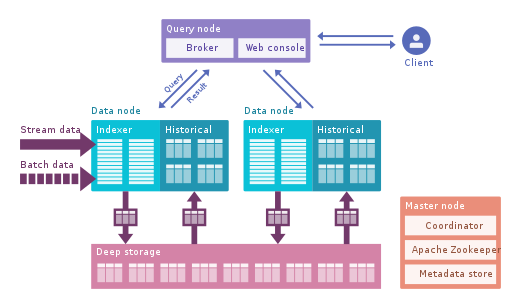
Apache Pinot : Ini adalah alternatif Druid open source yang lebih baru dari LinkedIn. Dibandingkan dengan Druid, ia menawarkan latensi yang lebih rendah berkat indeks Startree, yang melakukan praperhitungan parsial, sehingga dapat digunakan untuk aplikasi yang berpusat pada pengguna (digunakan untuk mendapatkan feed LinkedIn). Ini menggunakan indeks yang diurutkan dan bukan terbalik, yang lebih cepat. Ini memiliki arsitektur plugin yang dapat diperluas dan juga memiliki banyak integrasi, tetapi tidak mendukung Hive. Ini juga mengintegrasikan pemrosesan batch dan real-time, menyediakan pemuatan cepat, indeks pintar, dan menyimpan data dalam segmen. Ini lebih mudah dan lebih cepat untuk diterapkan dibandingkan dengan Druid, tetapi terlihat sedikit belum matang saat ini.
ClickHouse: Ditulis dalam C ++, mesin ini memberikan kinerja luar biasa untuk kueri OLAP, terutama untuk agregat. Ini seperti database relasional, sehingga Anda dapat memodelkan data dengan mudah. Sangat mudah untuk disiapkan dan memiliki banyak integrasi.
Baca artikel ini yang membandingkan 3 mesin secara detail.
Mulailah dari yang kecil dengan memeriksa data Anda sebelum membuat keputusan. Mekanisme baru ini sangat kuat, tetapi sulit digunakan. Jika Anda bisa menunggu berjam-jam, gunakan pemrosesan batch dan database seperti Hive atau Tajo; lalu gunakan Kylin untuk mempercepat kueri OLAP dan membuatnya lebih interaktif. Jika itu tidak cukup dan Anda membutuhkan lebih sedikit latensi dan data waktu nyata, pertimbangkan mesin OLAP. Druid lebih cocok untuk analisis waktu nyata. Kaileen lebih fokus pada kasus OLAP. Druid memiliki integrasi yang baik dengan Kafka sebagai streaming langsung. Kylin menerima data dari Sarang atau Kafka secara berkelompok, meskipun penerimaan langsung direncanakan.
Terakhir, Greenplum Apakah mesin OLAP lain, lebih fokus pada kecerdasan buatan.
Visualisasi data
Ada beberapa alat komersial untuk visualisasi seperti Qlik, Looker, atau Tableau.
Jika Anda lebih suka Open Source, lihat SuperSet. Ini adalah alat hebat yang mendukung semua alat yang kami sebutkan, memiliki editor hebat dan sangat cepat, menggunakan SQLAlchemy untuk memberikan dukungan bagi banyak database.
Alat menarik lainnya adalah Metabase atau Falcon .
Kesimpulan
Ada berbagai macam alat yang dapat digunakan untuk memanipulasi data, dari mesin kueri yang fleksibel seperti Presto hingga penyimpanan berkinerja tinggi seperti Kylin. Tidak ada solusi satu ukuran untuk semua, saya menyarankan Anda untuk meneliti data yang tersedia dan memulai dari yang kecil. Mesin kueri adalah titik awal yang baik karena fleksibilitasnya. Kemudian, untuk kasus penggunaan yang berbeda, Anda mungkin perlu menambahkan alat tambahan untuk mencapai tingkat layanan yang Anda inginkan.
Berikan perhatian khusus pada alat baru seperti Druid atau Pinot, yang menyediakan cara mudah untuk menganalisis data dalam jumlah besar dengan latensi sangat rendah, menjembatani kesenjangan antara OLTP dan OLAP dalam hal kinerja. Anda mungkin tergoda untuk berpikir tentang pemrosesan, penghitungan awal agregat, dan sejenisnya, tetapi pertimbangkan alat ini jika Anda ingin menyederhanakan pekerjaan Anda.