
Halo!
Nama saya Nikita, dan saya mengawasi pengembangan beberapa proyek di DomClick. Hari ini saya ingin melanjutkan tema "gambar lucu" di dunia RabbitMQ. Dalam artikelnya, Alexey Kazakov menganggap alat yang ampuh sebagai antrean yang ditangguhkan dan implementasi yang berbeda dari strategi Coba Lagi. Hari ini kita akan berbicara tentang cara menggunakan RabbitMQ untuk menjadwalkan tugas berkala.
Mengapa kami perlu membuat sepeda sendiri dan mengapa kami meninggalkan Celery dan alat manajemen tugas lainnya? Faktanya adalah bahwa mereka tidak sesuai dengan tugas dan persyaratan kami untuk toleransi kesalahan, yang cukup ketat di perusahaan kami.
Saat beralih ke Docker dan Kubernetes, banyak developer menghadapi masalah dalam mengatur tugas periodik, crown diluncurkan dengan rebana, dan kontrol proses membuat banyak hal yang diinginkan. Dan kemudian ada masalah dengan beban puncak pada siang hari.
Tugas saya adalah mengimplementasikan dalam proyek tersebut sebuah sistem yang dapat diandalkan untuk memproses tugas-tugas berkala, sementara dengan mudah dapat diskalakan dan toleran terhadap kesalahan. Proyek kami menggunakan Python, jadi masuk akal untuk melihat bagaimana Celery cocok untuk kami. Ini adalah alat yang bagus, tetapi dengannya kami sering mengalami masalah keandalan, skalabilitas, dan rilis yang mulus. Satu pod - satu grup proses. Saat menskalakan Celery, Anda harus meningkatkan resource dari satu pod, karena tidak ada sinkronisasi antar pod, yang berarti menghentikan pemrosesan tugas, meskipun untuk sementara. Dan jika tugasnya juga berjangka panjang, maka Anda sudah bisa menebak betapa sulitnya mengelolanya. Kelemahan kedua yang jelas: di luar kotak tidak ada dukungan untuk asynchrony, tetapi bagi kami ini penting, karena tugas terutama berisi operasi I / O, dan Celery berjalan di thread.
Saat itu (2018), kami tidak menemukan alat siap pakai yang cocok, dan mulai mengembangkan milik kami sendiri. Mengambil sebagai dasar fungsionalitas pelaksanaan tugas yang ditangguhkan dan Pertukaran Surat Mati, kami memutuskan untuk membuat sistem untuk memproses tugas-tugas berkala. Konsepnya terlihat seperti ini:
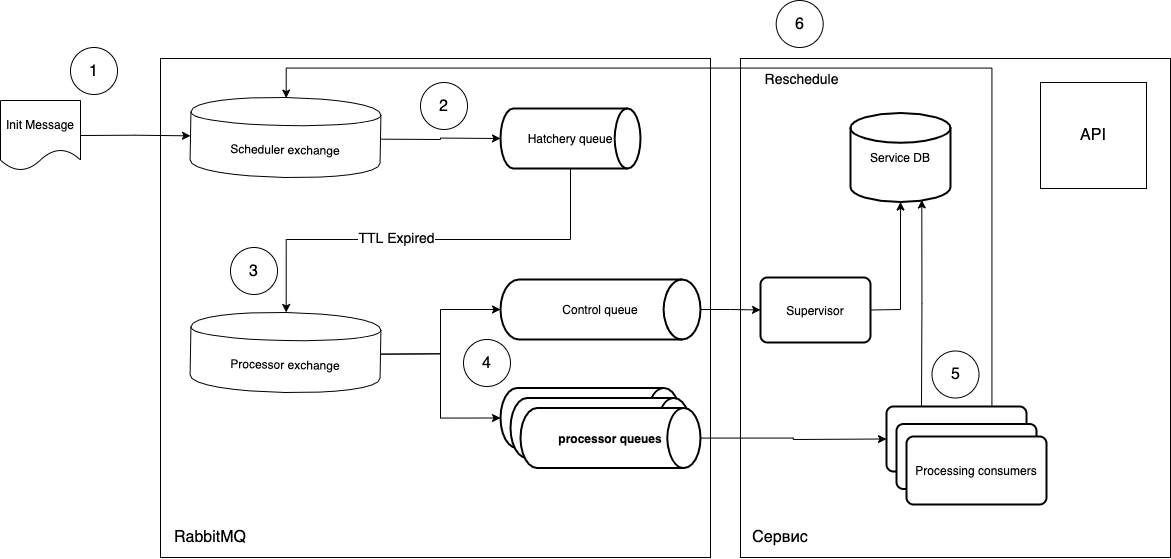
Saya akan mencoba menjelaskan apa itu apa.
- Tugas dikirim dalam bentuk pesan ke pertukaran Penjadwal.
- Perangkat
routing_keylunak masuk ke antrian Hatchery yang diperlukan, yang memiliki parametermessage_ttl, serta koneksi dengan pertukaran Prosesor sebagai pertukaran surat kesepakatan. Antrian "jatuh tempo" tidak terkait dengan jenis tugas, ini hanya memainkan peran "timer", yaitu, Anda dapat membuat antrian sebanyak yang Anda butuhkan dan mengelolanyarouting_key. - Karena antrian tidak memiliki pendengar, pesan, setelah "jatuh tempo" dalam antrian, pergi ke pertukaran Prosesor.
- Kemudian konsumen bebas (Pemrosesan konsumen) mengambil pesan dan menjalankannya. Setelah eksekusi, siklus diulangi jika perlu.
Apa keuntungan dari skema seperti itu?
- Eksekusi bertahap, yaitu tugas baru tidak akan diproses jika tugas sebelumnya belum diselesaikan.
- Seorang pendengar tunggal (konsumen), yaitu, Anda dapat membuat pekerja universal dan pekerja khusus. Diskalakan dengan hanya meningkatkan jumlah pod yang dibutuhkan.
- Terapkan tugas baru tanpa mengganggu pekerjaan yang sudah ada. Yang perlu Anda lakukan adalah memperbarui pod listener secara perlahan dan mengirim pesan yang sesuai ke antrean. Artinya, Anda dapat membuat pod dengan kode baru, yang akan menangani pesan baru, dan proses saat ini akan terus berjalan di pod lama. Ini memberi kami pembaruan yang mulus.
- Anda dapat menggunakan kode asinkron dan infrastruktur apa pun, sembari tidak bergantung pada tumpukan.
- Anda dapat mengontrol pelaksanaan tugas di native
ack/ levelreject, dan juga mendapatkan antrian opsional tambahan (antrian kontrol) yang dapat melacak siklus hidup tugas.
Sirkuitnya sebenarnya cukup sederhana, kami dengan cepat membuat prototipe yang berfungsi. Dan kodenya indah. Cukup menandai fungsi panggilan balik dengan dekorator sederhana yang mengontrol siklus hidup pesan.
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
Sekarang kami menggunakan skema ini untuk melakukan hanya tugas berurutan berkala, tetapi juga dapat digunakan ketika penting untuk mulai menjalankan tugas pada waktu tertentu, tanpa mengalihkan waktu ke eksekusi itu sendiri. Untuk melakukan ini, cukup jadwalkan ulang tugas setelah pesan mengenai supervisor.
Benar, pendekatan ini memiliki biaya overhead tambahan. Anda perlu memahami bahwa jika terjadi kesalahan, pesan akan kembali ke antrean, pekerja lain akan mengambilnya dan segera mulai menjalankannya. Oleh karena itu, Anda perlu memisahkan penanganan kesalahan sesuai dengan tingkat kekritisannya dan memikirkan terlebih dahulu apa yang harus dilakukan dengan pesan tersebut jika terjadi kesalahan tertentu.
Opsi yang memungkinkan:
- Kesalahan akan teratasi sendiri (misalnya, ini adalah kesalahan sistem): kirim
noackdan ulangi penanganan kesalahan. - Kesalahan logika bisnis: Anda perlu menghentikan siklus - kirim
ack. - Kesalahan dari poin 1 terlalu sering diulang: kami meracuni
rejectdan memberi sinyal pada pengembang. Ada beberapa opsi di sini. Anda dapat membuat antrian surat kesepakatan untuk menyimpan pesan untuk mengembalikan pesan setelah penguraian, atau Anda dapat menggunakan teknik coba lagi (sebutkanmessage_ttl).
Contoh dekorator:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
Skema ini telah bekerja dengan kami selama setengah tahun, cukup dapat diandalkan dan praktis tidak memerlukan perhatian. Aplikasi crash tidak mengganggu penjadwal dan hanya sedikit menunda pelaksanaan tugas.
Tidak ada plus tanpa minus. Skema ini juga memiliki kerentanan kritis. Jika sesuatu terjadi pada RabbitMQ dan pesan hilang, maka Anda perlu melihat secara manual apa yang hilang dan memulai loop lagi. Tetapi ini adalah situasi yang sangat tidak mungkin di mana Anda harus memikirkan layanan ini terakhir :)
PS Jika topik penjadwalan tugas periodik tampaknya menarik bagi Anda, maka di artikel berikutnya, saya akan memberi tahu Anda lebih detail bagaimana kami mengotomatiskan pembuatan antrian, serta tentang Supervisor.
Tautan: