Reinforcement Learning itu buruk, atau lebih tepatnya, tidak berfungsi sama sekali dengan dimensi tinggi. Dan juga menghadapi masalah bahwa simulator fisika cukup lambat. Oleh karena itu, baru-baru ini, cara untuk mengatasi keterbatasan ini menjadi populer dengan melatih jaringan saraf terpisah yang menyimulasikan mesin fisika. Ternyata sesuatu seperti analogi imajinasi, di mana pembelajaran dasar lebih lanjut terjadi.
Mari kita lihat seberapa besar kemajuan yang telah dibuat di bidang ini dan melihat arsitektur utamanya.
Gagasan untuk menggunakan jaringan neural daripada simulator fisik bukanlah hal baru, karena simulator sederhana seperti MuJoCo atau Bullet pada CPU modern mampu memberikan setidaknya 100-200 FPS (dan lebih sering pada 60), dan menjalankan simulator jaringan saraf dalam batch paralel dengan mudah menghasilkan 2000-10000 FPS di kualitas yang sebanding. Benar, pada cakrawala kecil 10-100 langkah, tetapi untuk pembelajaran penguatan ini cukup sering.
Namun yang lebih penting, proses melatih jaringan saraf untuk meniru mesin fisika biasanya melibatkan pengurangan dimensi. Karena cara termudah untuk melatih jaringan neural semacam itu adalah dengan menggunakan autoencoder, yang terjadi secara otomatis.
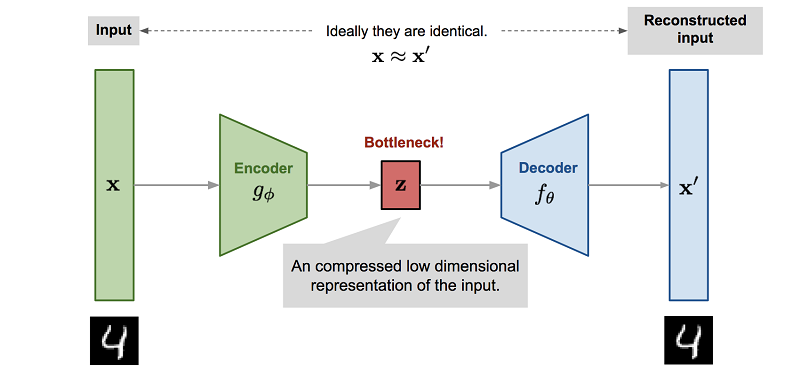
, , . , . - , , , , Z.
Z Reinforcement Learning. , , ( , , ). , .
, — , , . . , Z , model-based , , .
, Reinforcement Learning. "" : , , , .
World Models
( ), 2018 World Models.
: - "" , Z. ( ).
VAE:
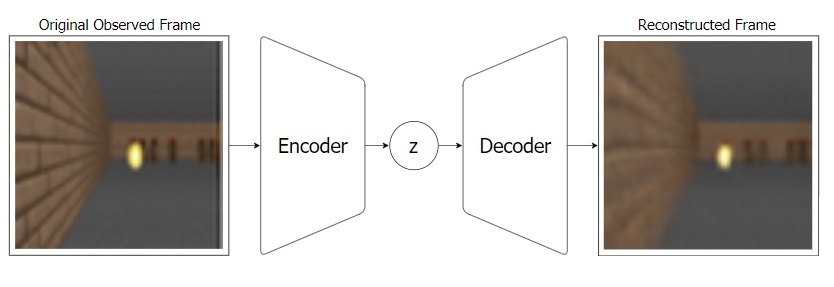
, VAE ( MDN-RNN), . VAE , . , RNN Z . .
:

, : VAE(V) Z MDN-RNN(M) . Z, . MDN-RNN , Z , .
, "" ( - MDN-RNN), . ( ), .
, "" (. ) MDN-RNN (Controller — "", ). , , environment. , C , . VAE(V).
Controller ©, ? ! , -"", Controller. , . , CMA-ES. , Z , . . , , , .
, , .
PlaNet
PlaNet. (, , Controller reinforcement learning), PlaNet Model-Based .
, Model-Based RL — . . , . , , RL , .
Model-Based , , , . (CEM PDDM).
- , ! , .
, . , . .
, . . . (.. state, Reinforcement Learning) , , . Model-Based .
PlaNet, World Models , , Z ( S — state).

Z (, S) , , . , - .
S (, Z) . , , . , .
S , . Model-Based ( ""). .
, , .. -"", A. Model-Based — . , state S . R , state S , ( ). , , ! ( ). Model-Based , .. , , , S R. , World Models, .
Model-Based , PlaNet . 50 . , , , , Model-Free .

Model-Based , (-), . , . . , Model-Based, PlaNet . ( ), .
Dreamer
PlaNet Dreamer. .
PlaNet, Dreamer S, , . Dreamer Value , . Reinforcement Learning. . , . Model-Based ( PlaNet) .

, , Dreamer Actor , . Model-Free , actor-critic.
actor-critic Model-Free , actor , critic ( value, advantage), Dreamer actor . Model-Free .
Dreamer' , . Actor , (. ). Value , , value reward .

, Dreamer Model-Based . Model-Free. model-based ( , ) Actor . Dreamer . , PlaNet Model-Based .
, Dreamer 20 , , Model-Free . , Dreamer 20 , ( ) .

Dreamer Reinforcement Learning . MuJoCo, , .
Plan2Explore
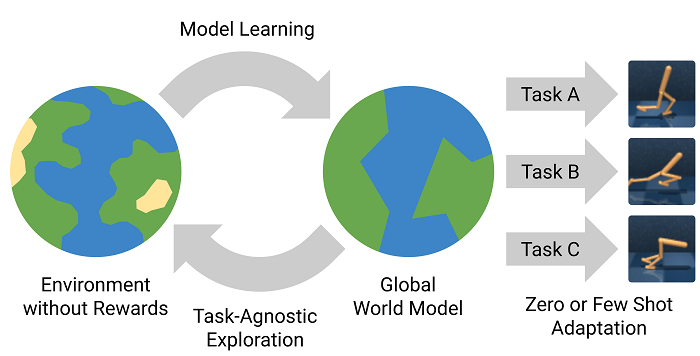
. Reinforcement Learning , .
, - , . , - , , . , , ! Plan2Explore .
Reinforcement Learning , , . , .
, . . , -, . -, , - , .
, . , , Plan2Explore , . , .
Plan2Explore : , . , - , . . . zero-shot . ( , . World Models ), few-shot .
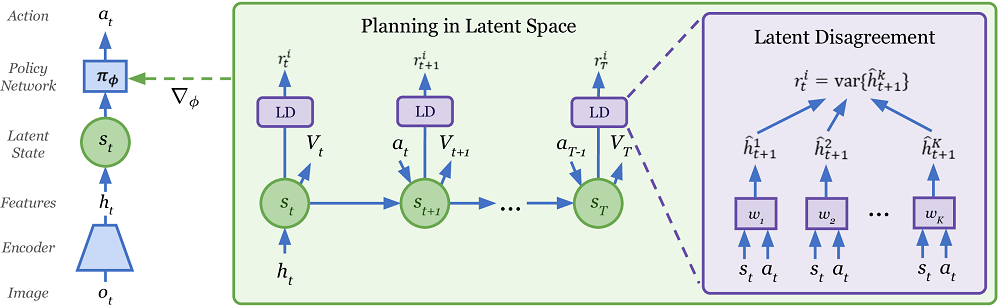
Plan2Explore , Dreamer Model-Free , , . , .
Menariknya, Plan2Explore menggunakan cara yang tidak biasa untuk menilai kebaruan tempat-tempat baru sambil menjelajahi dunia. Untuk ini, serangkaian model yang dilatih hanya pada model dunia dan memprediksi hanya satu langkah maju dilatih. Dikatakan bahwa prediksi mereka berbeda untuk keadaan yang sangat baru, tetapi karena kumpulan data (sering berkunjung ke situs), prediksi mereka mulai sesuai bahkan dalam lingkungan stokastik acak. Karena prediksi satu langkah pada akhirnya bertemu dengan beberapa nilai rata-rata di lingkungan stokastik ini. Jika Anda belum memahami apapun, maka Anda tidak sendiri. Di sana di artikel itu tidak terlalu jelas dijelaskan. Tapi entah bagaimana itu tampaknya berhasil.