
Pada artikel ini saya akan menjelaskan:
- Jenis binatang apa Aliran Udara ini, terdiri dari komponen apa dan bagaimana mereka berinteraksi satu sama lain
- tentang entitas utama Aliran Udara: saluran pipa yang disebut DAG, Operator, dan beberapa hal lainnya
- bagaimana berhasil dalam pengembangan di Airflow
- bagaimana kami menerapkan pembuatan pipelines dan apa yang disebut "penulisan deklaratif pipelines"
- tentang pro dan kontra menggunakan Airflow
Apa itu Airflow
Aliran udara adalah platform untuk membuat, memantau, dan mengatur jalur pipa. Proyek open source ini, ditulis dengan Python, dibuat pada tahun 2014 di Airbnb. Pada 2016, Airflow berada di bawah naungan Apache Software Foundation, melalui inkubator, dan pada awal 2019 menjadi proyek Apache tingkat atas.
Dalam dunia pengolahan data, ada yang menyebutnya sebagai ETL tool, tapi sebenarnya ini bukan ETL dalam pengertian klasik, seperti Pentaho, Informatica PowerCenter, Talend dan lain-lain sejenisnya. Airflow adalah orkestrator, "cron on battery": Airflow tidak melakukan tugas berat transfer dan pemrosesan data itu sendiri, tetapi memberi tahu sistem dan kerangka kerja lain apa yang harus dilakukan dan memantau status eksekusi. Kami terutama menggunakannya untuk menjalankan kueri di pekerjaan Hive atau Spark.
Spoiler
Airflow, worker ( ), . , , .
Rentang tugas yang diselesaikan dengan Airflow tidak terbatas pada menjalankan sesuatu di cluster Hadoop. Ia dapat menjalankan kode Python, menjalankan perintah Bash, menghosting container dan pod Docker di Kubernetes, menjalankan kueri terhadap database favorit Anda, dan banyak lagi.
Arsitektur aliran udara
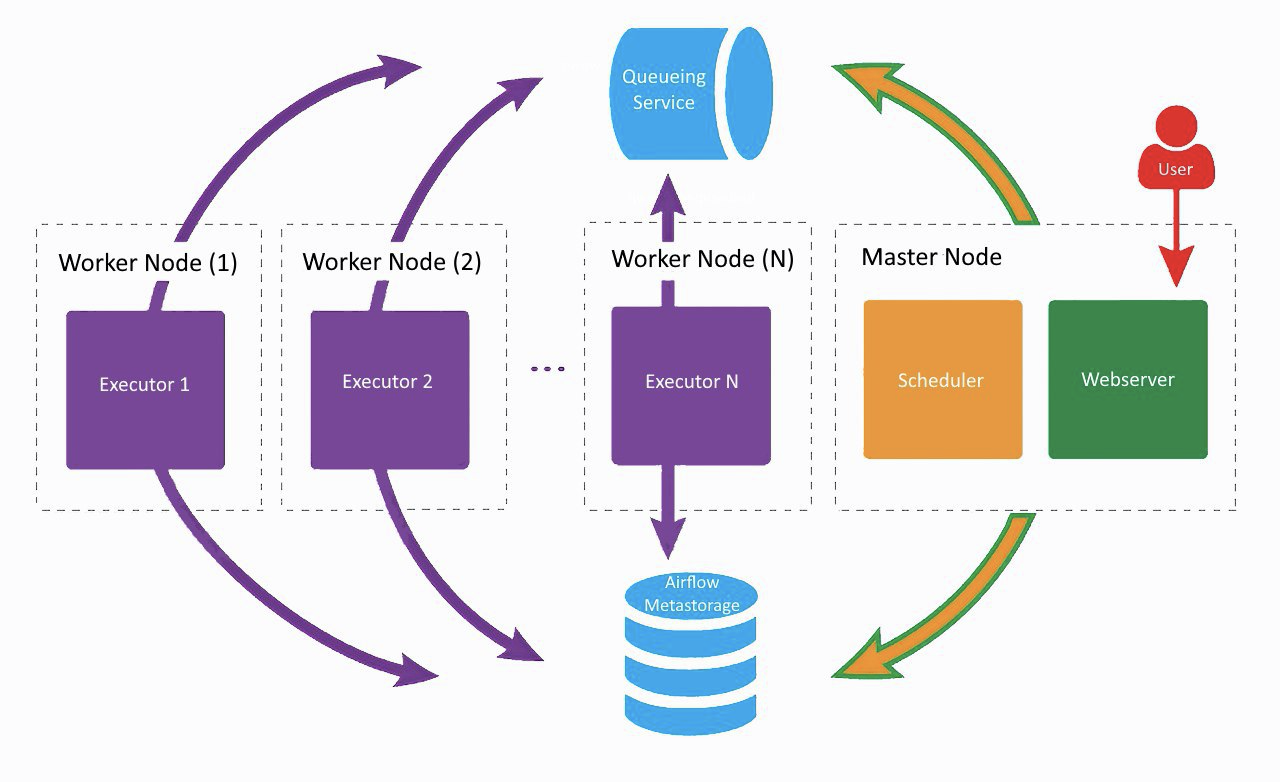
Seperti inilah pengaturan Aliran Udara kami saat ini, hanya Lamoda yang menggunakan dua pekerja. Pada mesin terpisah, server web dan penjadwal berputar, para pekerja sibuk mengerjakan yang tetangga. Satu dibuat untuk tugas-tugas biasa, yang kedua diadaptasi untuk menjalankan pelatihan model ML menggunakan Vowpal Wabbit. Semua komponen berkomunikasi satu sama lain melalui antrian tugas dan basis metadata.
Pada awal pengembangan Airflow di perusahaan, semua komponen (kecuali database) bekerja pada mesin yang sama, tetapi pada titik tertentu hal ini menyebabkan kurangnya sumber daya di server dan penundaan pengoperasian penjadwal. Oleh karena itu, kami memutuskan untuk mendistribusikan layanan ke server yang berbeda dan menggunakan arsitektur yang ditunjukkan pada gambar di atas.
Komponen aliran udara
Webserver
Webserver adalah antarmuka web yang menunjukkan apa yang terjadi dengan pipeline. Halaman ini
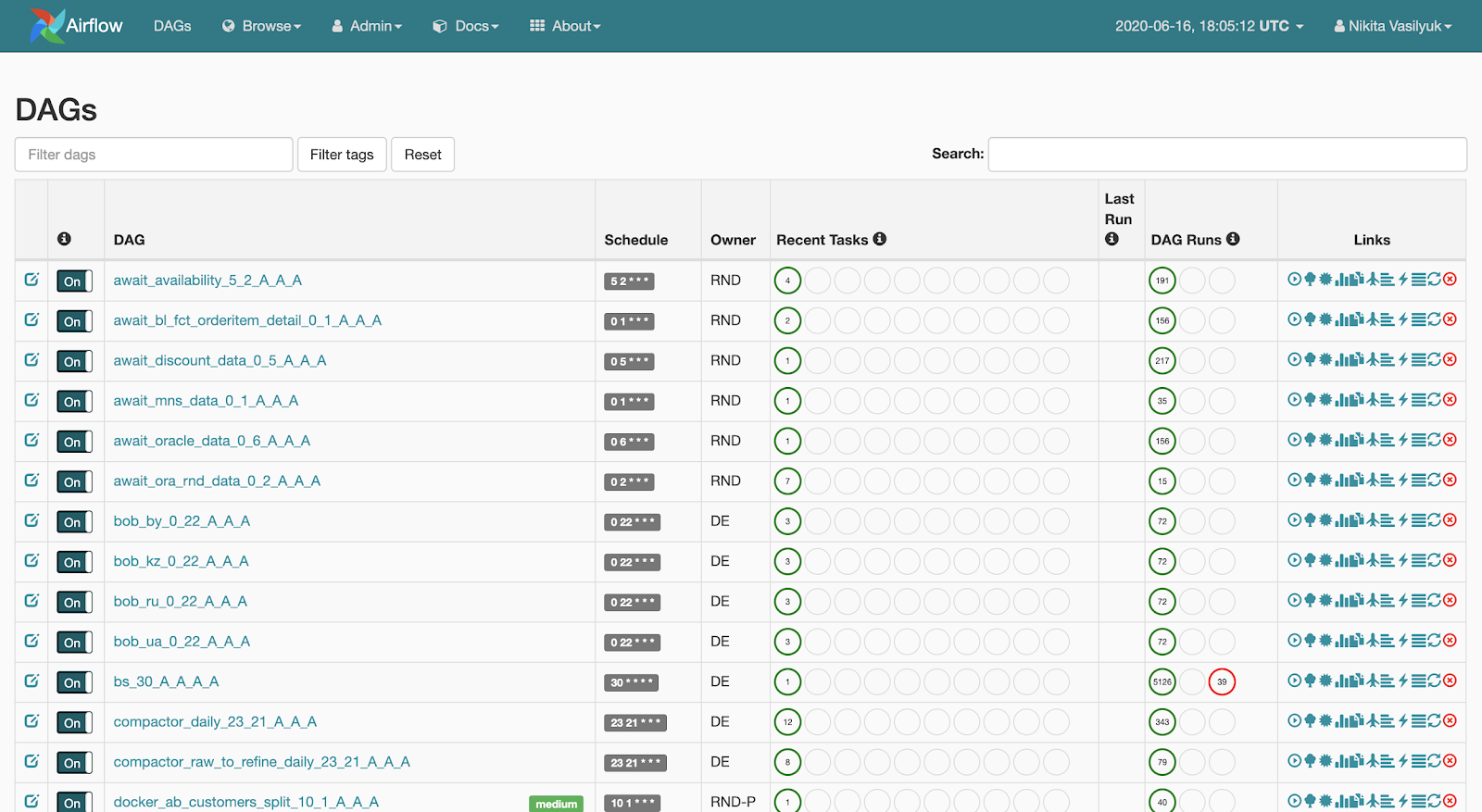
dapat dilihat oleh pengguna: Server web memungkinkan untuk melihat daftar pipeline yang tersedia. Statistik singkat peluncuran ditampilkan di samping setiap jalur pipa. Ada juga beberapa tombol yang secara paksa meluncurkan pipeline atau menampilkan informasi mendetail: statistik peluncuran, kode sumber pipeline, visualisasinya dalam bentuk grafik atau tabel, daftar tugas, dan riwayat peluncurannya.
Jika kita mengklik pipeline, kita akan masuk ke menu Graph View. Tugas dan tautan di antara mereka ditampilkan di sini.
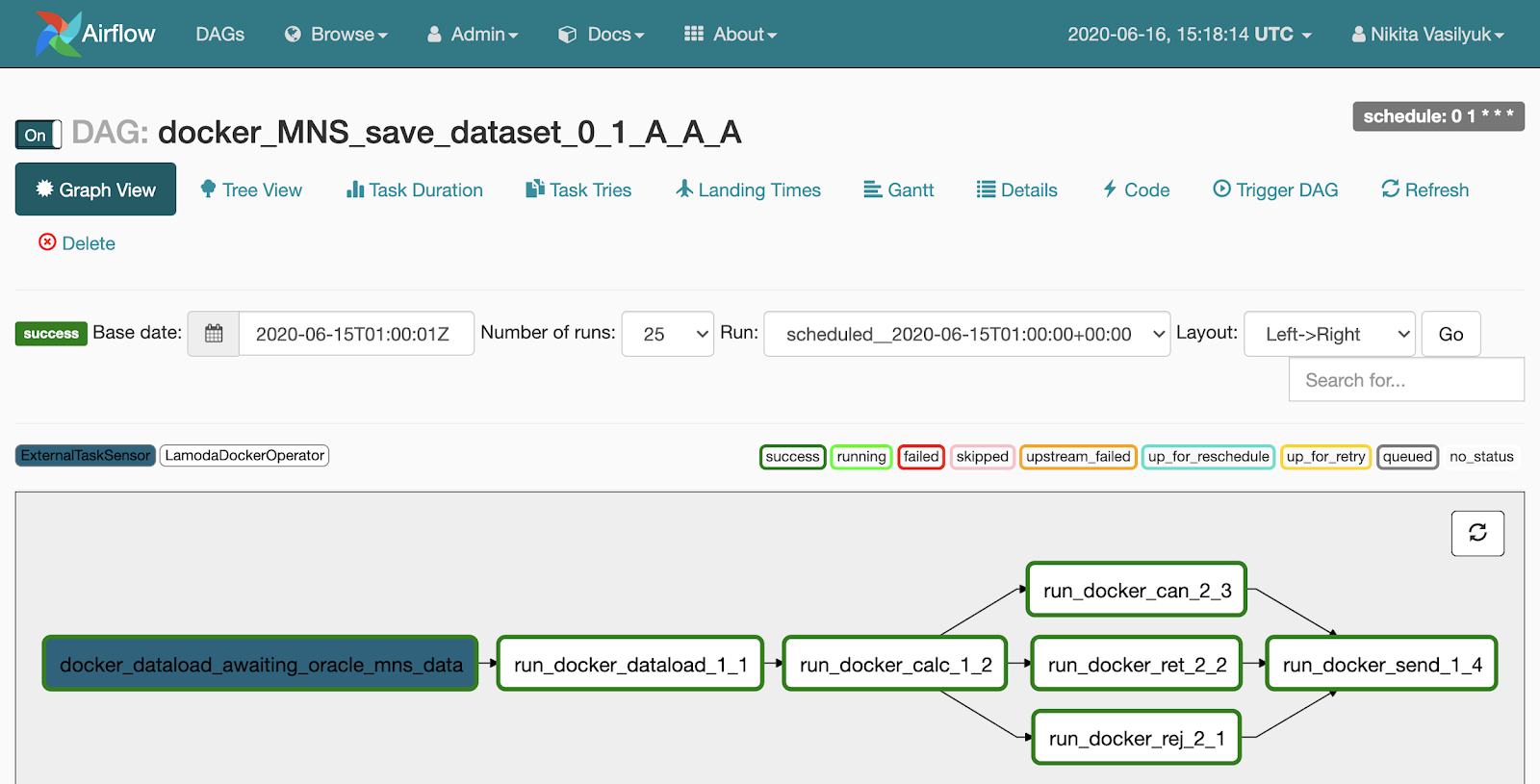
Ada menu Tampilan Pohon di sebelah Tampilan Grafik. Itu dibuat untuk memulai kembali tugas, melihat statistik dan log. Tampilan grafik seperti pohon ditampilkan di sisi kiri, di seberangnya adalah tabel dengan riwayat peluncuran tugas.
Setiap baris dari tabel menakutkan ini adalah satu tugas, setiap kolom adalah salah satu permulaan pipa. Di persimpangan mereka ada kotak dengan peluncuran tugas tertentu untuk tanggal tertentu. Jika Anda mengkliknya, sebuah menu akan muncul di mana Anda dapat melihat informasi rinci dan log dari tugas ini, memulai atau memulai ulang, dan juga menandainya sebagai berhasil atau tidak berhasil.

Scheduler - seperti namanya, meluncurkan pipeline saat waktunya tiba. Ini adalah proses Python yang secara berkala masuk ke direktori dengan pipeline, menarik statusnya saat ini dari sana, memeriksa status, dan memulainya. Secara umum, Scheduler adalah yang paling menarik dan sekaligus menjadi penghambat dalam arsitektur Airflow.
- Peringatan pertama adalah bahwa hanya satu instance Scheduler yang dapat berjalan dalam satu waktu. Ini berarti bahwa saat ini tidak mungkin untuk beroperasi dalam Ketersediaan Tinggi (pengembang berencana menambahkan Scheduler HA ke Airflow versi 2.0).
- : , - . , - , .
Hingga beberapa saat, penundaan disetel oleh parameter file konfigurasi Airflow, tetapi penundaan peluncuran masih tetap ada. Oleh karena itu, Aliran Udara bukan tentang pemrosesan data waktu nyata. Jika Anda bertindak secara tidak sengaja dan menetapkan interval peluncuran yang terlalu sering (setiap beberapa menit sekali), Anda dapat mengalami penundaan dalam pipeline Anda. Pengalaman menunjukkan bahwa sekali setiap 5 menit sudah cukup sering, dan beberapa tidak merekomendasikan menjalankan pipa setiap 10 menit. Kami memiliki beberapa pipeline yang dimulai setiap 10 menit, mereka cukup sederhana dan sejauh ini tidak ada masalah dengan mereka.
Worker
Worker adalah tempat kode kami dijalankan dan tugas diselesaikan. Aliran udara mendukung beberapa pelaksana:
- Yang pertama, yang paling sederhana, adalah SequentialExecutor. Ini secara berurutan meluncurkan tugas-tugas masuk, dan menjeda penjadwal selama pelaksanaannya.
- LocalExecutor , , LocalExecutor . : - SQLite, LocalExecutor SequentialExecutor.
- CeleryExecutor , . Celery – , RabbitMQ Redis. , .
- DaskExecutor Dask – .
- KubernetesExecutor pod Kubernetes.
- DebugExecutor IDE.
Entitas Apache Airflow
Pipeline, atau DAG
Esensi terpenting dari Airflow adalah DAG, alias pipa, alias grafik asiklik terarah. Untuk memperjelas cara memasaknya dan mengapa Anda membutuhkannya, saya akan menganalisis sebuah contoh kecil.
Katakanlah seorang analis mendatangi kita dan meminta kita untuk mengisi data ke dalam tabel tertentu sekali sehari. Dia menyiapkan semua informasi: apa yang didapat dari mana, kapan harus memulai, dengan SLA apa. Berikut adalah contoh bagaimana kami dapat mendeskripsikan pipeline kami.
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
Dag_id berisi nama unik pipeline. Selanjutnya, kami menggunakan schedule_interval untuk menentukan seberapa sering ini harus dijalankan.
Poin yang sangat penting: karena Airflow dikembangkan oleh perusahaan internasional, Airflow hanya berfungsi di UTC. Saat ini, tidak ada cara yang masuk akal untuk membuat Aliran Udara berfungsi di zona waktu yang berbeda, jadi Anda harus terus mengingat tentang perbedaan antara zona waktu kita dan UTC. Di versi 1.10.10, dimungkinkan untuk mengubah zona waktu di UI, tetapi ini hanya berlaku untuk antarmuka web, pipeline akan tetap berjalan dalam UTC.
Parameter default_args adalah kamus yang menjelaskan argumen default untuk semua tugas dalam pipeline ini. Nama-nama sebagian besar parameter menggambarkan diri mereka sendiri dengan baik, saya tidak akan memikirkannya.
Operator
Operator adalah kelas Python yang menjelaskan tindakan apa yang perlu dilakukan dalam tugas harian kita untuk menyenangkan analis.
Kita dapat menggunakan HiveOperator, yang, anehnya, dirancang untuk mengirim permintaan eksekusi ke Hive. Untuk memulai operator, Anda perlu menentukan nama tugas, pipeline, ID koneksi ke Hive dan permintaan yang sedang dijalankan.
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
Ada bagian dari template Jinja dalam permintaan yang kita berikan ke konstruktor operator. Jinja adalah pustaka template Python.
Setiap peluncuran pipeline menyimpan informasi tentang tanggal peluncuran. Itu terletak pada variabel yang disebut execution_date. {{ds}} adalah makro yang akan menggunakan tanggal_eksekusi hanya dalam format% Y-% m-% d. Pada saat tertentu sebelum memulai operator, Airflow akan membuat string kueri, mengganti tanggal yang diperlukan di sana, dan mengirim permintaan untuk eksekusi.
ds bukan satu-satunya makro, ada sekitar 20 makro (daftar semua makro yang tersedia) . Mereka menyertakan format tanggal yang berbeda dan beberapa fungsi untuk bekerja dengan tanggal - tambahkan atau kurangi beberapa hari.
Ketika saya berkenalan dengan Airflow, saya tidak mengerti mengapa semua jenis makro diperlukan, ketika Anda cukup memasukkan panggilan datetime.now () di sana dan menikmati hidup. Namun dalam beberapa kasus, hal ini dapat sangat merusak kehidupan kita dan analis. Misalnya, jika kita ingin menghitung ulang sesuatu untuk beberapa tanggal di masa lalu, Airflow tidak akan menggantikan tanggal ketika pipeline diluncurkan, tetapi waktu eksekusi sebenarnya. Dan dalam beberapa kasus, kita mungkin tidak mendapatkan apa yang kita harapkan.
Misalnya, jika kita ingin memulai ulang pipeline untuk hari Selasa lalu, saat menggunakan datetime.now (), kita sebenarnya akan menghitung ulang pipeline untuk hari ini, dan bukan untuk tanggal yang diperlukan. Plus, data hari ini bahkan mungkin belum siap pada saat ini.
Setelah berhasil menyelesaikan request tersebut, kita bisa mengirimkan notifikasi ke slack tentang loading data. Selanjutnya, kami memerintahkan Airflow, di mana untuk memulai tugas. Berkat operator yang kelebihan beban di Airflow, saya dengan mudah menggunakan >> operator untuk menentukan urutan langkah dalam pipa. Dalam contoh saya, kami mengatakan bahwa pertama-tama kami akan mulai menjalankan permintaan, kemudian mengirimkan notifikasi ke slack.
Idempotensi
Tidak mungkin membicarakan Aliran Udara tanpa menyebutkan idempotensi. Untuk berjaga-jaga, izinkan saya mengingatkan Anda: idempotensi adalah properti suatu objek, ketika Anda menerapkan kembali operasi ke suatu objek, selalu mengembalikan hasil yang sama.
Dalam konteks Airflow, ini berarti jika hari ini adalah hari Jumat, dan kami memulai ulang tugas pada Selasa lalu, maka tugas akan dimulai seolah-olah hari Selasa lalu, dan tidak ada yang lain. Artinya, peluncuran atau mulai ulang tugas untuk beberapa tanggal di masa lalu tidak akan bergantung pada kapan tugas ini benar-benar diluncurkan. Idempotensi diimplementasikan menggunakan variabel execution_date yang disebutkan di atas.
Aliran udara dikembangkan sebagai alat untuk menyelesaikan tugas pemrosesan data. Di dunia ini, kami biasanya memproses sebagian besar data hanya jika sudah siap, yaitu pada hari berikutnya. Dan pencipta Airflow awalnya meletakkan konsep seperti itu dalam produk mereka.
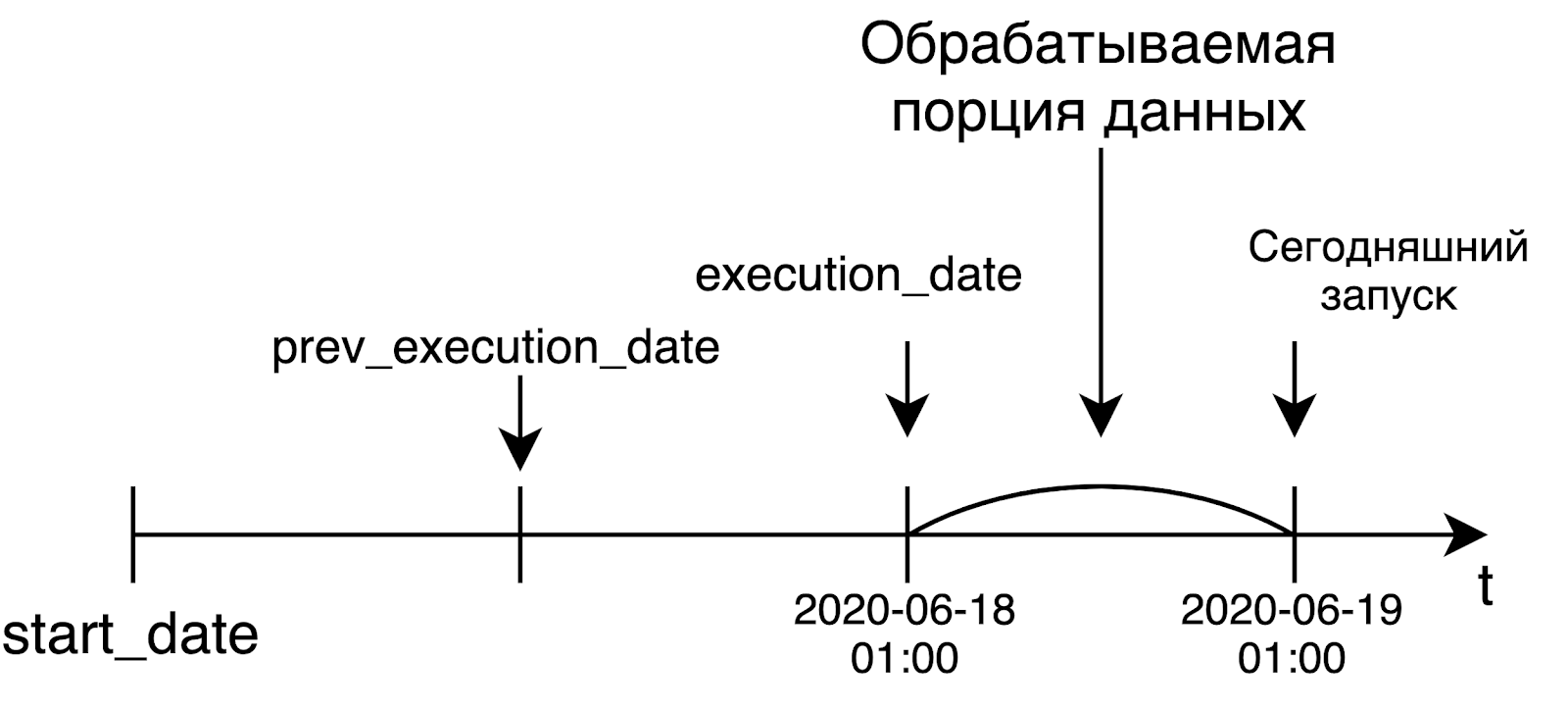
Saat kami meluncurkan saluran harian, kemungkinan besar kami ingin memproses data dari kemarin. Itulah mengapa execution_date akan sama dengan batas kiri dari interval yang datanya kami proses. Misalnya, peluncuran hari ini, yang dimulai pada jam 1 pagi UTC, akan menerima tanggal kemarin sebagai tanggal_eksekusi. Dalam kasus pipeline per jam, situasinya sama: untuk memulai pipeline pada pukul 6 pagi, waktu di execution_date akan sama dengan 5 pagi. Pikiran ini pada awalnya tidak terlalu jelas, tetapi bagaimanapun sangat berarti dan penting.
Operator aliran udara yang paling umum
Di Airflow, tidak hanya operator yang pergi ke Hive dan mengirim sesuatu untuk dikendurkan. Faktanya, ada banyak sekali operator di luar sana. Dalam artikel tersebut, saya menampilkan yang paling populer dan berguna.
- BashOpetator dan PythonOperator. Semuanya jelas dengan mereka: mereka masing-masing mengirim perintah bash dan fungsi python untuk eksekusi.
- Ada berbagai macam operator untuk mengirimkan pertanyaan ke berbagai database. Postgres standar, MySQL, Oracle, Hive, Presto didukung. Jika karena alasan tertentu tidak ada operator untuk database favorit Anda, Anda dapat menggunakan JdbcOperator yang lebih umum atau menulis sendiri, Airflow mengizinkannya.
- Sensor – , . , - . , , . , : 3 , . . , , .
- BranchPythonOperator – , , python , , .
- DockerOpetator Docker- . , Docker- , . , .
- KubernetesPodOperator pod Kubernetes.
- DummyOperator , .
Lamoda
- – LamodaDockerOperator. , : - Hadoop, . LamodaDockerOperator Spark- , python.
- LamodaHiveperator – , . Hive. , - , , . , , HiveCliHook HiveServer2Hook, .
- – ExternalTaskSensor. . , Hadoop . , , , - , , . , - HDFS, Airflow.
- BashOperator, PythonOperator – , bash- python .
- , . - , .
Airflow
- Variables – , , , . , . , Hive, HDFS, . dev- prod-, .
- Connections – , . Airflow : http ftp, .
- Hooks – , .
- SLA -. , . SLA , , - - . - : - , Airflow .
- – XCom, cross-communication. : , json-. – 48 .
- – , . , . , 5, , , , .

Selanjutnya, Anda dapat melihat bagaimana durasi tugas berubah sepanjang hari. Dalam kasus kami, ini adalah proses mentransfer data dari Kafka ke Hive dengan verifikasi kualitas data. Selain itu, Anda dapat melacak kapan tugas karena alasan tertentu membutuhkan waktu lebih lama dari biasanya.

Bagaimana Berhasil dalam Pengembangan Aliran Udara
Di bawah ini adalah beberapa tip untuk membantu Anda menghindari tertembak di kaki saat menggunakan Airflow:
- Berguna untuk menyimpan setiap pipeline (atau generator pipeline, lebih lanjut di bawah) dalam file terpisah. Saya segera tahu file mana yang harus saya tuju untuk melihat pipeline atau generator yang diperlukan.
- , , . , -, . , - , . : , , .
- – schedule_interval start_date dag_id. , Airflow , - -. DAGS , Scheduler, . , , dag_id. , .
- catchup. True, Airflow , start_date . , . False Airflow . , Airflow True ( -).
- – . , python , airflow DAG, , DAG. . , , . REST API, requests.get() .
:
Sejak awal menggunakan Airflow, kami telah memisahkan konfigurasi pipeline dari kode. Awalnya, ini karena kekhasan skema penerapan, tetapi lambat laun pendekatan ini berakar. Dan sekarang kami menggunakan konfigurasi di mana pun ada petunjuk boilerplate. Ini terutama menyangkut pekerjaan Spark yang kami jalankan dari Docker. Dari sinilah muncul cerita dengan penulisan deklaratif pipeline.
Pendekatannya adalah kita memiliki direktori dengan konfigurasi. Setiap file konfigurasi berisi satu atau beberapa pipeline dengan deskripsinya: bagaimana mereka harus bekerja, kapan memulai, tugas apa yang ada di dalamnya dan dalam urutan apa mereka harus dilakukan.
Saya akan menunjukkan seperti apa kode untuk memanggil generator pipa kita. Di pintu masuk, dia menerima direktori dengan konfigurasi, awalan dan kelas yang akan bertanggung jawab untuk mengisi pipa dengan tugas. Di balik terpal, generator membuka direktori yang ditentukan, menemukan file konfigurasi di sana, dan membuat tugas di file ini untuk setiap pipeline dan menghubungkannya.
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag #
Seperti inilah tampilan file konfigurasi pada umumnya. Untuk mendeskripsikan konfigurasi, kami menggunakan format HOCON , yang merupakan superset dari JSON. Ini mendukung impor file HOCON lain dan dapat merujuk ke nilai variabel lain.
Dalam konfigurasi di level pipeline (blok atribusi), Anda dapat menentukan banyak parameter, tetapi yang paling penting adalah name, start_date, dan schedule_interval.
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
Di sini Anda dapat menentukan konkurensi - berapa banyak tugas yang akan dijalankan secara bersamaan dalam satu proses. Baru-baru ini, kami telah menambahkan blok dengan deskripsi penurunan harga singkat dari pipa di sini. Kemudian, bersama dengan informasi lainnya tentang pipeline, akan dikirim ke Confluence (kami menerapkan pengiriman menggunakan Foliant ). Ternyata sangat nyaman: dengan cara ini kami menghemat waktu bagi developer gali untuk membuat halaman di Confluence.
Berikutnya adalah bagian yang bertanggung jawab atas pembentukan tugas. Pertama, di blok koneksi, kami menunjukkan dari koneksi mana di Airflow kami perlu mengambil parameter untuk menghubungkan ke sumber eksternal - dalam contoh, ini adalah DWH kami.
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
Semua informasi yang diperlukan seperti pengguna, kata sandi, URL, dan sebagainya akan diteruskan ke penampung buruh pelabuhan sebagai variabel lingkungan. Di blok Containers, kami menunjukkan tugas mana yang akan kami luncurkan. Di dalamnya ada nama gambar, daftar koneksi yang digunakan dan daftar variabel lingkungan.
Anda mungkin memperhatikan bahwa template Jinja muncul dalam nilai beberapa variabel lingkungan. Untuk menentukan antrian di YARN, kami menggunakan sintaks Airflow standar untuk mengambil nilai variabel. Untuk menunjukkan tanggal peluncuran, kami menggunakan makro {{ds_nodash}}, yang mewakili tanggal tanggal_eksekusi tanpa tanda hubung. Konfigurasi berisi 3 tugas serupa lainnya, mereka disembunyikan untuk kejelasan.
Selanjutnya, menggunakan tugas, kami menunjukkan bagaimana tugas ini akan diluncurkan. Anda akan melihat bahwa mereka terdaftar sebagai daftar dalam daftar. Ini berarti bahwa keempat tugas ini akan berjalan secara paralel satu sama lain.
Dan satu hal terakhir: kami menentukan pada pipa dasar mana DAG kami saat ini bergantung. Angka dan huruf aneh di akhir nama dag dasar adalah jadwal yang kami sematkan di nama pipeline. Dengan demikian, pipeline kami akan mulai terisi hanya setelah dag dasar dan tugas yang ditentukan di dalamnya selesai.
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Teks lengkap dari file konfigurasi
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
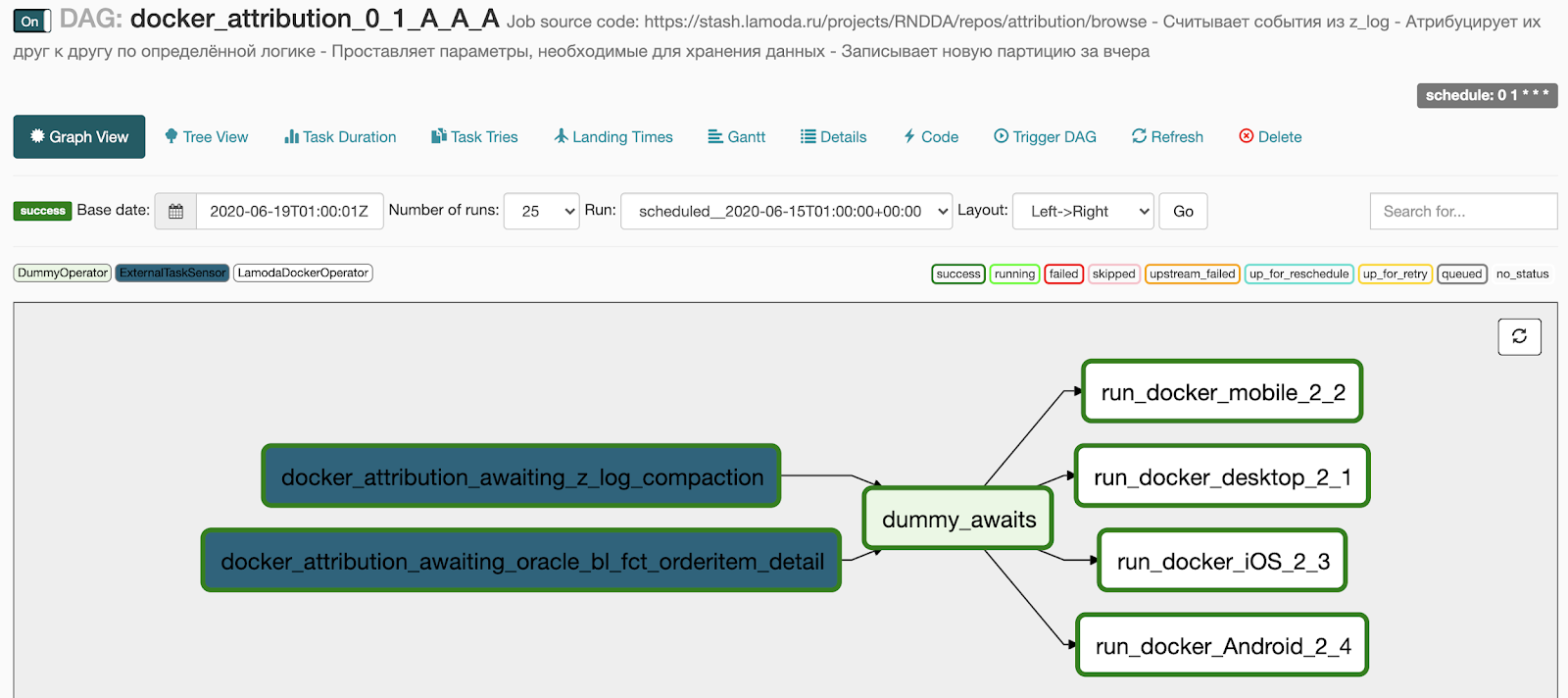
Inilah yang kita dapatkan setelah generasi:
- 2 titik di blok menunggu berubah menjadi dua sensor yang menunggu eksekusi pipa dasar,
- 4 tugas yang kami tentukan di blok buruh pelabuhan berubah menjadi 4 tugas yang berjalan secara paralel,
- kami menambahkan DummyOperator antara dua blok operator sehingga tidak ada jaringan koneksi antar tugas.
Apa yang ingin kami lakukan selanjutnya
Pertama, buat lingkungan Fitur lengkap. Kami sekarang memiliki satu dudukan pengembangan untuk menguji semua jaringan pipa kami. Dan sebelum menguji, Anda perlu memastikan lanskap dev sekarang gratis.
Baru-baru ini, tim kami telah berkembang, dan jumlah pelamar meningkat. Kami telah menemukan solusi sementara untuk masalah tersebut dan sekarang beri tahu kami di Slack saat kami menggunakan dev. Ini berfungsi, tetapi masih menjadi hambatan dalam pengembangan dan pengujian.
Salah satu opsinya adalah pindah ke Kubernetes. Misalnya, saat membuat pull-request di master, Anda dapat membuat namespace terpisah di Kubernetes, tempat untuk menerapkan Airflow, menerapkan kode, lalu menyebarkan variabel, koneksi. Setelah penerapan, pengembang akan membuka instans Airflow yang baru dibuat dan menguji saluran pipanya. Kami memiliki beberapa dasar tentang topik ini, tetapi tangan kami tidak sampai ke klaster Kubernetes pertempuran, di mana kami dapat menjalankan semuanya.
Opsi kedua untuk mengimplementasikan lingkungan Fitur adalah mengatur repositori dengan cabang pengembangan umum, tempat kode developer digabungkan dan secara otomatis diluncurkan ke lanskap developer. Sekarang kami secara aktif mencari skema ini.
Kami juga ingin mencoba menerapkan plugin - hal-hal untuk memperluas fungsionalitas antarmuka web. Tujuan utama penerapan plug-in adalah untuk membuat bagan Gantt pada tingkat seluruh Aliran Udara, yaitu pada tingkat semua saluran pipa, serta membuat grafik ketergantungan di antara berbagai saluran pipa.
Mengapa kami memilih Airflow
- Pertama, ini adalah Python, di mana dengan bantuan dua loop dan beberapa kondisi, Anda dapat membuat pipeline yang elegan dan berfungsi dengan benar. Dan itu tidak perlu dijelaskan dalam XML yang sangat besar. Plus, hampir seluruh ekosistem Python dan seluruh perpustakaan kebun binatangnya tersedia di luar kotak, yang dapat digunakan sesuka Anda.
- Tidak adanya XML sangat menyederhanakan tinjauan kode. Kami menulis kode pipeline dan konfigurasinya, dan semuanya bagus, semuanya berfungsi. Sebenarnya, Anda dapat menyeret XML atau format konfigurasi lainnya, tapi itu masalah selera.
- unit-, , .
- , «», . Airflow . , , .
- Airflow ( ).
- Active Directory RBAC (role-based access control, )
- Worker Celery Kubernetes.
- open source-, , .
- Airflow , . .
- : statsd , Sentry – , Airflow , . Airflow-exporter Prometheus.
Airflow,
- – : , , execution_date – , .
- - -, , , Apache NiFi. – code-review diff- , .
- Scheduler - .
- – , . – .
- Airflow : . , , . RBAC ( ) , UI (, , ). RBAC – security Flask, .
- : , , -, , . , .
Airflow
- crontab’a cron .
- Python.
- - Docker, , .
- , , real time.
- Airflow , “, , , Z – ”.