
Hari ini kami akan memberi tahu Anda bagaimana kami mengembangkan sistem pencarian untuk kandidat sumur untuk rekahan hidrolik (HF) menggunakan pembelajaran mesin (selanjutnya - ML) dan apa hasilnya. Mari kita cari tahu mengapa rekahan hidraulik diperlukan, apa kaitannya ML dengannya, dan mengapa pengalaman kami mungkin berguna tidak hanya bagi tukang minyak.
Di bawah potongan, pernyataan rinci masalah, deskripsi solusi TI kami, pilihan metrik, pembuatan pipeline ML, pengembangan arsitektur untuk rilis model dalam prod.
Kami menulis tentang mengapa rekahan dilakukan di artikel kami sebelumnya di sini dan di sini .
Mengapa pembelajaran mesin ada di sini? Di satu sisi, rekahan hidraulik lebih murah daripada pengeboran, tetapi biayanya masih mahal, dan di sisi lain, rekahan hidraulik tidak mungkin dilakukan di setiap sumur - tidak akan ada pengaruhnya. Seorang ahli geologi sedang mencari tempat yang cocok. Karena jumlah perusahaan yang beroperasi banyak (puluhan ribu), opsi sering diabaikan, dan perusahaan tidak menerima kemungkinan keuntungan. Penggunaan pembelajaran mesin secara signifikan dapat mempercepat analisis informasi. Namun, membuat model ML hanyalah setengah dari pertempuran. Anda perlu membuatnya bekerja dalam mode konstan, menghubungkannya ke layanan data, menggambar antarmuka yang indah dan membuatnya sangat nyaman bagi pengguna untuk masuk ke aplikasi dan menyelesaikan masalahnya dalam dua klik.
Mengabstraksi dari industri minyak, orang dapat melihat bahwa tugas serupa sedang diselesaikan di semua perusahaan. Setiap orang ingin:
A. Mengotomatiskan pemrosesan dan analisis aliran data besar.
B. Mengurangi biaya dan tidak melewatkan keuntungan.
C. Membuat sistem seperti itu cepat dan efisien.
Dari artikel ini, Anda akan mempelajari bagaimana kami menerapkan sistem seperti itu, alat apa yang kami gunakan, dan juga kendala apa yang kami dapatkan di jalur sulit dalam memperkenalkan ML ke dalam produksi. Kami yakin bahwa pengalaman kami dapat menarik bagi semua orang yang ingin mengotomatiskan rutinitas - apa pun bidang aktivitasnya.
Bagaimana sumur dipilih untuk rekahan hidrolik dengan cara "tradisional"
Saat memilih kandidat sumur untuk rekahan hidraulik, tukang minyak mengandalkan pengalamannya yang luas dan melihat berbagai grafik dan tabel, setelah itu ia memprediksi di mana harus melakukan rekahan hidraulik. Namun, tepercaya, tidak ada yang tahu apa yang terjadi di kedalaman beberapa ribu meter, karena tidak mudah untuk melihat ke bawah tanah (Anda dapat membaca lebih lanjut di artikel sebelumnya ). Analisis data dengan metode "tradisional" membutuhkan biaya tenaga kerja yang signifikan, tetapi sayangnya, hal itu tidak menjamin perkiraan akurat dari hasil rekahan hidrolik (spoiler - dengan ML juga).
Jika kita mendeskripsikan proses identifikasi kandidat sumur untuk rekah hidrolik saat ini, maka akan terdiri dari tahapan sebagai berikut: membongkar data sumur dari sistem informasi perusahaan, memproses data yang diperoleh, melakukan analisis ahli, menyetujui solusi, melakukan rekahan hidrolik, dan menganalisis hasilnya. Terlihat sederhana, tapi tidak cukup.
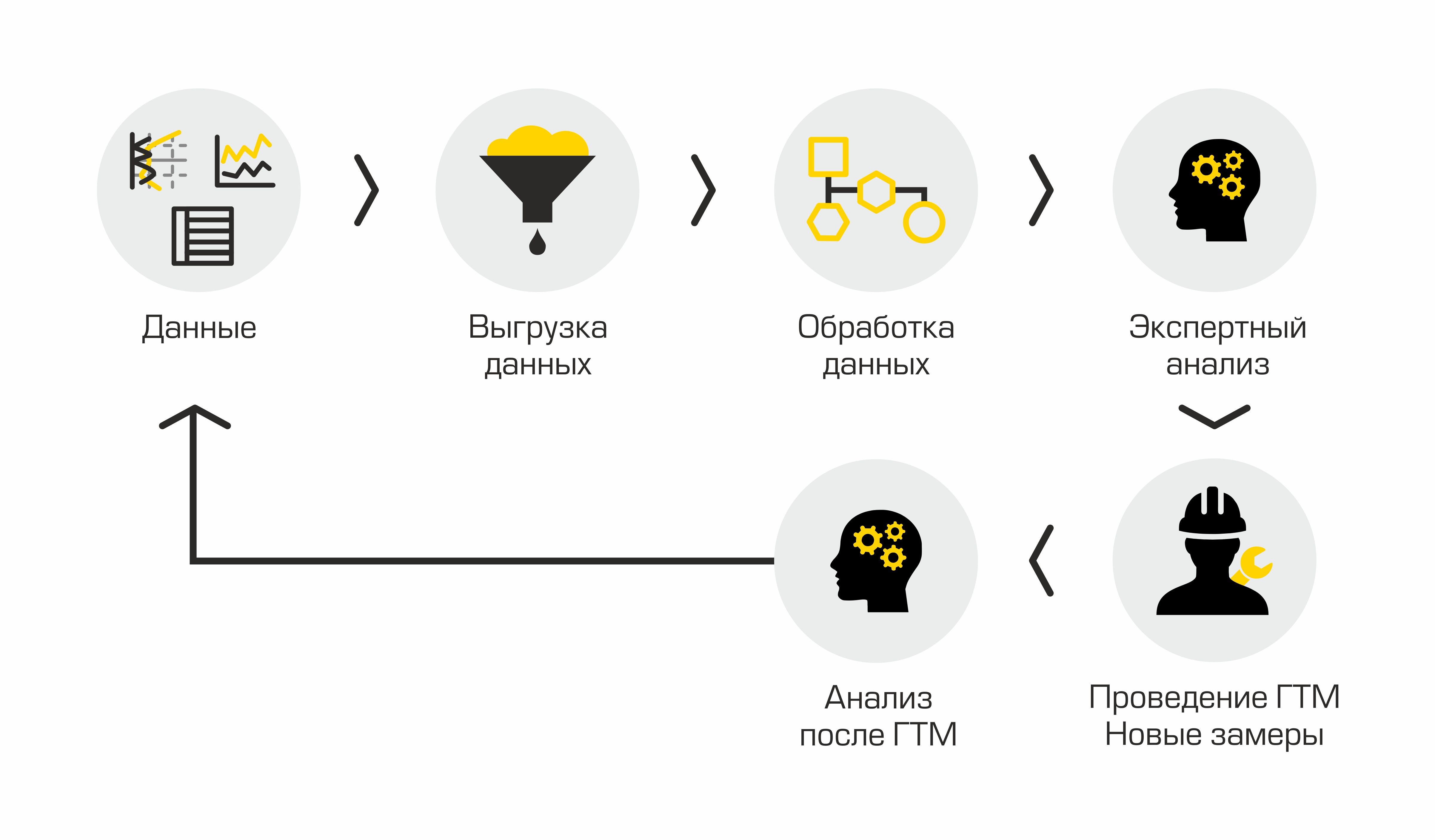
Proses pemilihan calon sumur saat ini
Kekurangan utama dari pendekatan “manual” ini adalah banyaknya rutinitas, volume bertambah, orang-orang mulai tenggelam dalam pekerjaan, tidak ada transparansi dalam proses dan metode.
Rumusan masalah
Pada tahun 2019, tim analisis data kami menghadapi tugas untuk membuat sistem otomatis untuk memilih kandidat sumur untuk rekahan hidrolik. Bagi kami, kedengarannya seperti ini - untuk mensimulasikan keadaan semua sumur, dengan asumsi bahwa saat ini perlu untuk melakukan operasi rekahan hidraulik pada mereka, dan kemudian memberi peringkat sumur berdasarkan peningkatan produksi minyak terbesar dan memilih sumur Top-N yang akan dituju armada dan mengambil tindakan untuk meningkatkan perolehan minyak.
Dengan menggunakan model ML, terbentuk indikator yang menunjukkan kelayakan rekahan hidraulik pada sumur tertentu: produksi oli setelah rekahan hidraulik yang direncanakan dan keberhasilan acara ini.
Dalam kasus kami, laju produksi minyak adalah jumlah minyak yang diproduksi dalam meter kubik per bulan. Indikator ini dihitung berdasarkan dua nilai: laju aliran cairan dan penghentian air. Tukang minyak menyebut cairan sebagai campuran minyak dan air - campuran inilah yang merupakan produk dari sumur. Dan potongan air adalah proporsi kadar air dalam campuran tertentu. Untuk menghitung laju produksi minyak yang diharapkan setelah rekahan, dua model regresi digunakan: satu memprediksi laju aliran fluida setelah rekahan, yang lain memprediksi pemotongan air. Menggunakan nilai yang dikembalikan oleh data model, perkiraan produksi minyak dihitung menggunakan rumus:

Keberhasilan fraktur adalah variabel target biner. Ini ditentukan dengan menggunakan nilai aktual dari peningkatan produksi minyak, yang diperoleh setelah rekahan hidrolik. Jika keuntungan lebih besar dari ambang batas tertentu yang ditentukan oleh seorang ahli di area domain, maka nilai atribut sukses sama dengan satu, jika tidak sama dengan nol. Jadi, kami membentuk markup untuk memecahkan masalah klasifikasi.
Adapun metrik ... Metrik harus berasal dari bisnis dan mencerminkan minat pelanggan, setiap kursus pembelajaran mesin memberi tahu kami. Menurut kami, di sinilah letak keberhasilan atau kegagalan utama dari sebuah proyek pembelajaran mesin. Sekelompok ilmuwan data dapat meningkatkan kualitas model selama yang mereka inginkan, tetapi jika model tersebut tidak meningkatkan nilai bisnis pelanggan dengan cara apa pun, model seperti itu akan gagal. Bagaimanapun, penting bagi pelanggan untuk mendapatkan kandidat yang tepat dengan prediksi "fisik" dari parameter kinerja sumur setelah rekahan hidraulik.
Untuk masalah regresi, metrik berikut dipilih:

Mengapa tidak ada satu metrik pun, Anda bertanya - masing-masing mencerminkan kebenarannya sendiri. Untuk lapangan di mana tingkat produksi rata-rata tinggi, MAE akan berukuran besar dan MAPE akan kecil. Jika kita mengambil bidang dengan rata-rata produksi rendah, gambarannya akan sebaliknya.
Metrik berikut dipilih untuk masalah klasifikasi:

( wiki ),
Area di bawah kurva KOP - AUC ( wiki ).
Kesalahan yang kami temui
Kesalahan # 1 - untuk membangun satu model universal untuk semua bidang.
Setelah menganalisis dataset, menjadi jelas bahwa data berubah dari satu bidang ke bidang lainnya. Ini tidak mengherankan, karena endapan, pada umumnya, memiliki struktur geologi yang berbeda.
Asumsi kami bahwa jika kami mengambil dan mengarahkan semua data yang tersedia untuk pelatihan ke dalam model, maka itu sendiri akan mengungkapkan keteraturan struktur geologi, telah gagal. Model yang dilatih pada data bidang tertentu menunjukkan kualitas prediksi yang lebih tinggi daripada model, yang dibuat menggunakan informasi tentang semua bidang yang tersedia.
Untuk setiap bidang, algoritme pembelajaran mesin yang berbeda diuji dan, berdasarkan hasil validasi silang, dipilih satu dengan MAPE terendah.
Kesalahan # 2 - Kurangnya pemahaman mendalam tentang data.
Jika Anda ingin membuat model pembelajaran mesin yang baik untuk proses fisik yang nyata, pahami bagaimana proses ini terjadi.
Awalnya, tim kami tidak memiliki pakar domain, dan kami bergerak dengan kacau. Sayangnya, kami tidak melihat kesalahan model saat menganalisis perkiraan, mereka menarik kesimpulan yang salah berdasarkan hasil.
Kesalahan # 3 - kurangnya infrastruktur.
Pada awalnya, kami mengunduh banyak file csv berbeda untuk bidang berbeda dan parameter berbeda. Pada titik tertentu, sejumlah besar file dan model telah terkumpul. Eksperimen yang telah dilakukan tidak dapat direproduksi, file hilang, dan timbul kebingungan.
1. BAGIAN TEKNIS
Saat ini sistem pemilihan otomatis kandidat terlihat seperti ini:
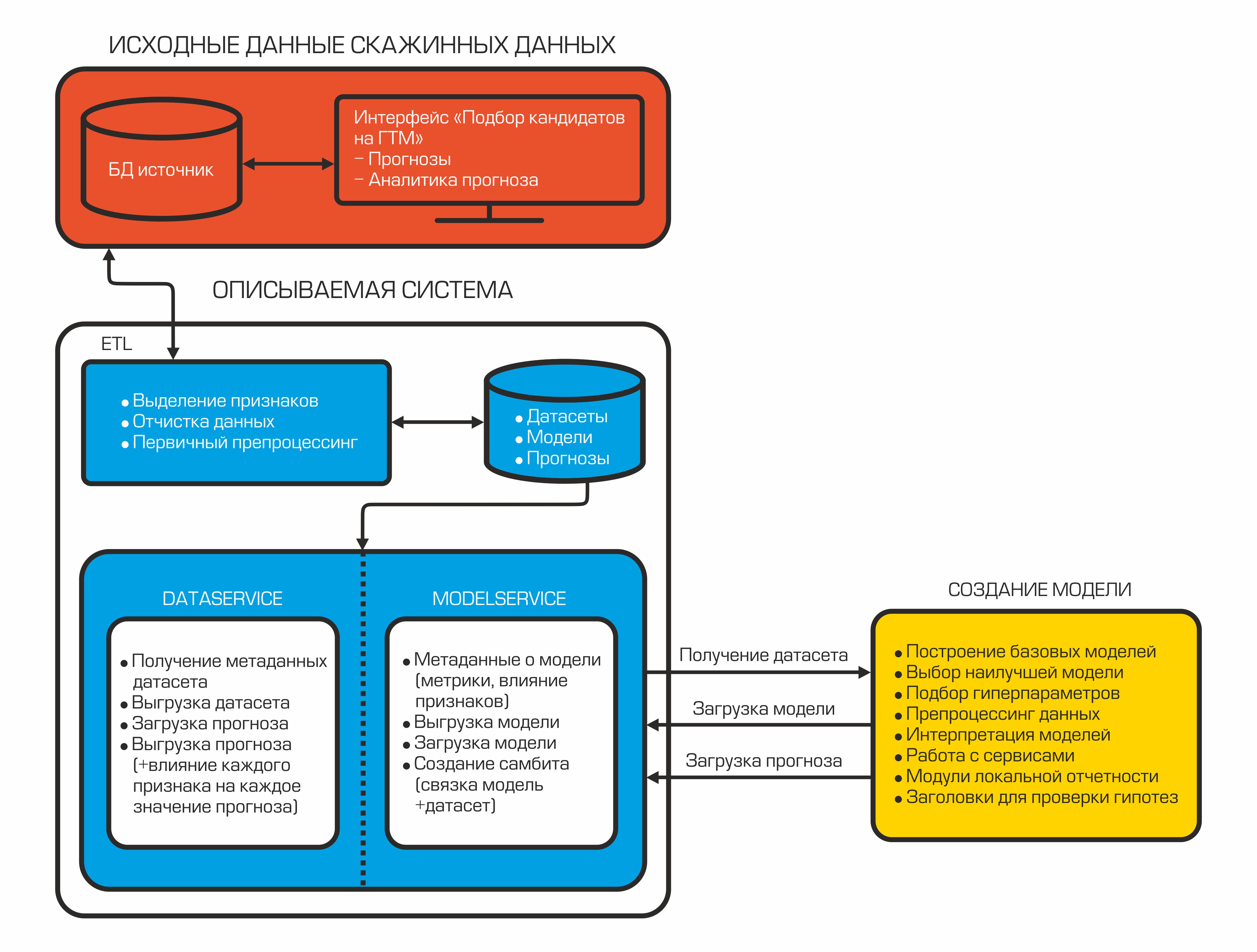
Setiap komponen adalah wadah terisolasi yang menjalankan fungsi tertentu.
2.1 ETL = Pemuatan Data
Semuanya dimulai dengan data. Apalagi jika kita ingin membangun model pembelajaran mesin. Kami memilih Pentaho Data Integration sebagai sistem integrasi.

Tangkapan layar dari salah satu transformasi
Keuntungan utama:
- sistem bebas;
- banyak pilihan komponen untuk menghubungkan ke berbagai sumber data dan mengubah aliran data;
- ketersediaan antarmuka web;
- kemampuan untuk mengelola melalui REST API;
- penebangan.
Selain semua hal di atas, kami memiliki pengalaman luas dalam mengembangkan integrasi untuk produk ini. Mengapa integrasi data diperlukan dalam proyek ML? Dalam proses menyiapkan kumpulan data, selalu diperlukan untuk mengimplementasikan perhitungan yang kompleks, untuk membawa data ke satu bentuk, untuk menghitung indikator baru "di sepanjang jalan", perubahan parameter dari waktu ke waktu, dll.
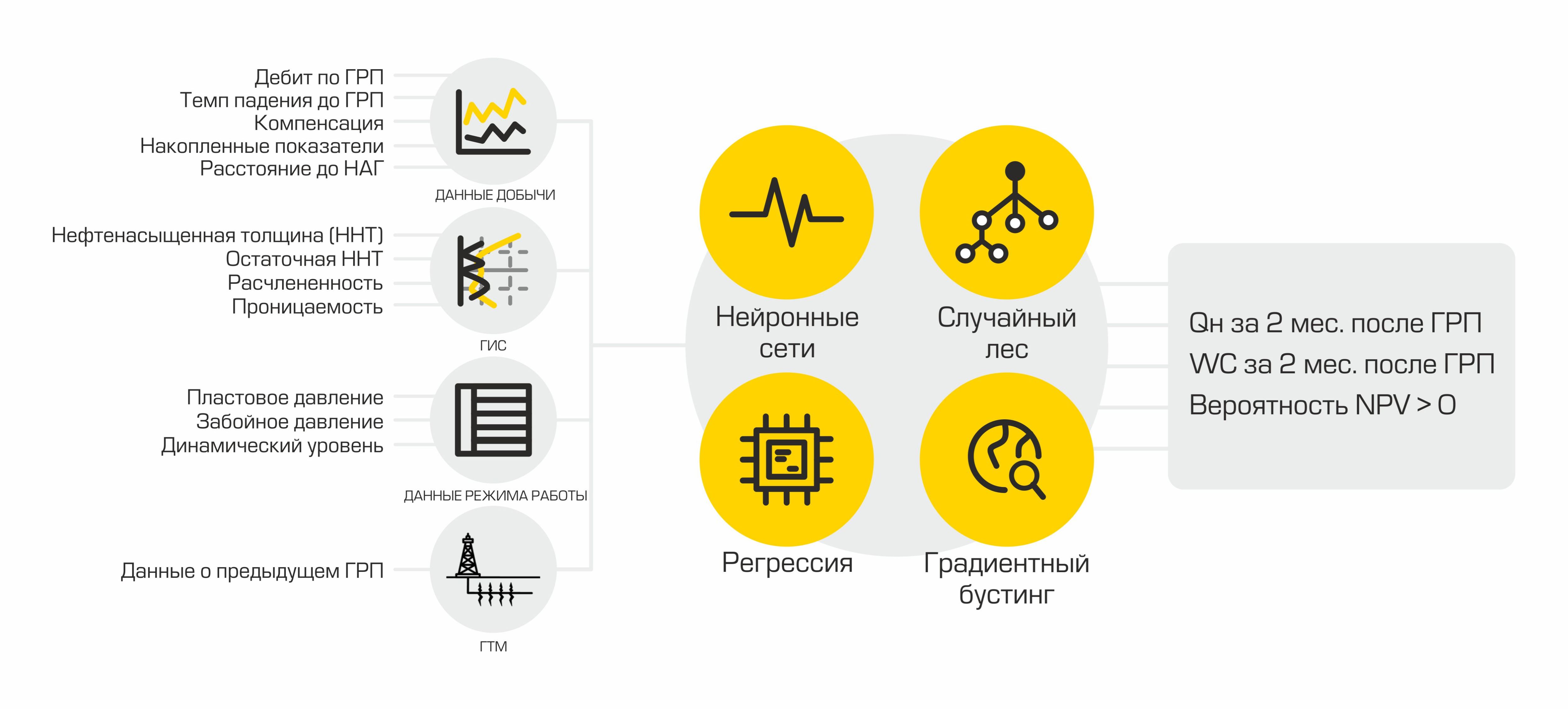
Untuk setiap fakta rekahan hidrolik, lebih dari 400 parameter dibongkar yang menggambarkan pengoperasian sumur pada saat pelaksanaan kegiatan, pengoperasian sumur yang berdekatan, serta informasi tentang rekahan hidrolik yang dilakukan sebelumnya. Selanjutnya, transformasi data dan preprocessing terjadi.
Kami memilih PostgreSQL sebagai repositori untuk data yang diproses. Ini memiliki banyak metode untuk bekerja dengan json. Karena kami menyimpan kumpulan data akhir dalam format ini, ini menjadi faktor yang menentukan.
Proyek pembelajaran mesin dikaitkan dengan perubahan konstan dalam data input karena penambahan fitur baru, oleh karena itu, Data Vault digunakan sebagai skema database (tautan ke wiki). Skema desain penyimpanan ini memungkinkan Anda dengan cepat menambahkan data baru tentang suatu objek dan tidak melanggar integritas tabel dan kueri.
2.2 Layanan Data dan Model
Setelah menyisir dan menghitung indikator yang diperlukan, data diunggah ke database. Mereka disimpan di sini dan menunggu dari mesin data untuk membawa mereka membuat model ML. Untuk ini, ada DataService - layanan yang ditulis dengan Python dan menggunakan protokol gRPC. Ini memungkinkan Anda untuk mendapatkan kumpulan data dan metadatanya (jenis fitur, deskripsinya, ukuran kumpulan data, dll.), Memuat dan menurunkan perkiraan, mengelola pemfilteran dan parameter pembagian dengan melatih / menguji. Perkiraan dalam database disimpan dalam format json, yang memungkinkan Anda menerima data dengan cepat dan menyimpan tidak hanya nilai perkiraan, tetapi juga pengaruh setiap fitur pada perkiraan khusus ini.
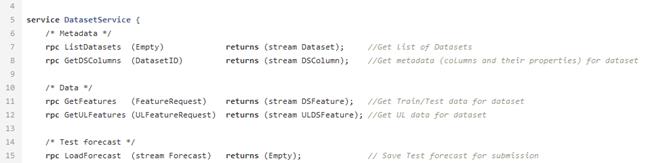
Contoh file proto untuk layanan data.
Saat model dibuat, model tersebut harus disimpan - untuk tujuan ini, ModelService digunakan, juga ditulis dengan Python dengan gRPC. Kemampuan layanan ini tidak terbatas pada menyimpan dan memuat model. Selain itu, ini memungkinkan Anda untuk memantau metrik, pentingnya fitur, dan juga menerapkan model + koneksi set data untuk pembuatan perkiraan otomatis berikutnya ketika data baru muncul.

Struktur layanan model kami terlihat seperti ini.
2.3 Model ML
Pada titik tertentu, tim kami menyadari bahwa otomatisasi juga harus memengaruhi pembuatan model ML. Kebutuhan ini didorong oleh kebutuhan untuk mempercepat proses pembuatan prakiraan dan pengujian hipotesis. Dan kami membuat keputusan untuk mengembangkan dan menerapkan pustaka AutoML kami sendiri ke dalam pipeline kami.
Awalnya, kemungkinan menggunakan pustaka AutoML yang sudah jadi dipertimbangkan, tetapi solusi yang ada ternyata tidak cukup fleksibel untuk tugas kami dan tidak memiliki semua fungsi yang diperlukan sekaligus (atas permintaan pekerja, kami dapat menulis artikel terpisah tentang AutoML kami). Kami hanya mencatat bahwa kerangka kerja yang kami kembangkan berisi kelas yang digunakan untuk preprocessing set data, menghasilkan dan memilih fitur. Sebagai model pembelajaran mesin, kami menggunakan sekumpulan algoritme yang paling berhasil kami gunakan sebelumnya: implementasi peningkatan gradien dari xgboost, pustaka catboost, forest acak dari Sklearn, jaringan neural yang terhubung sepenuhnya di Pytorch, dll. Setelah pelatihan, AutoML mengembalikan pipeline sklearn yang menyertakan kelas yang disebutkan, serta model ML,yang menunjukkan hasil terbaik dalam validasi silang untuk metrik yang dipilih.
Selain model, sebuah laporan dibentuk tentang pengaruh tanda apapun pada ramalan tertentu. Laporan semacam itu memungkinkan ahli geologi untuk melihat di balik tudung kotak hitam misterius. Jadi, AutoML menerima set data yang diberi tag menggunakan DataService dan, setelah pelatihan, membentuk model akhir. Selanjutnya, kita bisa mendapatkan estimasi akhir kualitas model dengan memuat set data pengujian, menghasilkan perkiraan, dan menghitung metrik kualitas. Tahap terakhir adalah mengupload file biner dari model yang dihasilkan, deskripsinya, metriknya ke ModelService, sedangkan perkiraan dan informasi tentang pengaruh fitur dikembalikan ke DataService.
Jadi, model kami ditempatkan dalam tabung reaksi dan siap diluncurkan ke prod. Kami dapat menggunakannya kapan saja untuk membuat perkiraan berdasarkan data baru yang relevan.
2.4 Antarmuka
Pengguna akhir produk kami adalah ahli geologi, dan entah bagaimana dia perlu berinteraksi dengan model ML. Cara paling nyaman baginya adalah modul dalam perangkat lunak khusus. Kami telah menerapkannya.
Bagian depan, tersedia untuk pengguna kami, terlihat seperti toko online: Anda dapat memilih bidang yang diinginkan dan mendapatkan daftar sumur yang paling mungkin berhasil. Di kartu sumur, pengguna melihat perkiraan pertumbuhan setelah rekahan hidraulik dan memutuskan sendiri apakah ia ingin menambahkannya ke "keranjang" dan mempertimbangkannya secara lebih rinci.

Antarmuka modul dalam aplikasi.

Beginilah tampilan kartu sumur di lampiran.
Selain perolehan minyak dan cairan yang diprediksi, pengguna juga dapat mengetahui fitur mana yang memengaruhi hasil yang diusulkan. Pentingnya fitur dihitung pada tahap pembuatan model menggunakan metode shap , lalu dimuat ke antarmuka perangkat lunak dengan DataService.

Aplikasi tersebut dengan jelas menunjukkan fitur mana yang paling penting untuk prediksi model.
Pengguna juga dapat melihat analog dari sumur yang diinginkan. Pencarian analog diimplementasikan di sisi klien menggunakan algoritma pohon Kd .
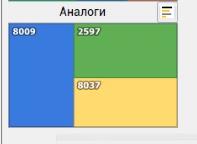
Modul menampilkan sumur dengan parameter geologi serupa.
2. BAGAIMANA KAMI MENINGKATKAN MODEL ML

Tampaknya menjalankan AutoML pada data yang tersedia layak dilakukan, dan kami akan senang. Namun kebetulan kualitas ramalan yang didapat otomatis tidak bisa dibandingkan dengan hasil datainters. Intinya adalah untuk memperbaiki model, analis sering mengedepankan dan menguji berbagai hipotesis. Jika gagasan meningkatkan keakuratan perkiraan pada data nyata, maka gagasan itu diimplementasikan di AutoML. Jadi, dengan menambahkan fitur baru, kami telah meningkatkan perkiraan otomatis yang cukup untuk beralih ke pembuatan model dan perkiraan dengan keterlibatan analis yang minimal. Berikut beberapa hipotesis yang telah diuji dan diterapkan di AutoML kami:
1. Mengubah metode pengisian
Pada model pertama, kami mengisi hampir semua celah dalam karakteristik dengan mean, kecuali yang kategoris - bagi mereka arti yang paling umum digunakan. Kemudian, dengan kerja bersama analis dan pakar, di area domain, dimungkinkan untuk memilih nilai yang paling sesuai untuk mengisi celah di 80% fitur. Kami juga mencoba beberapa metode pengisian lagi menggunakan pustaka sklearn dan missingpy. Hasil terbaik diperoleh dengan pengisian konstan dan KNNImputer - hingga 5% MAPE.

Hasil percobaan mengisi celah dengan metode yang berbeda.
2. Generasi fitur
Menambahkan fitur baru adalah proses berulang bagi kami. Untuk menyempurnakan model, kami mencoba menambahkan fitur baru berdasarkan rekomendasi pakar domain, berdasarkan pengalaman dari artikel ilmiah dan kesimpulan kami sendiri dari data tersebut.

Menguji hipotesis yang diajukan oleh tim membantu memperkenalkan fitur baru.
Salah satu yang pertama adalah fitur yang diidentifikasi berdasarkan pengelompokan. Faktanya, kami hanya memilih cluster dalam kumpulan data berdasarkan parameter geologi dan menghasilkan statistik dasar untuk atribut lain berdasarkan cluster - hal ini memberikan sedikit peningkatan kualitas.
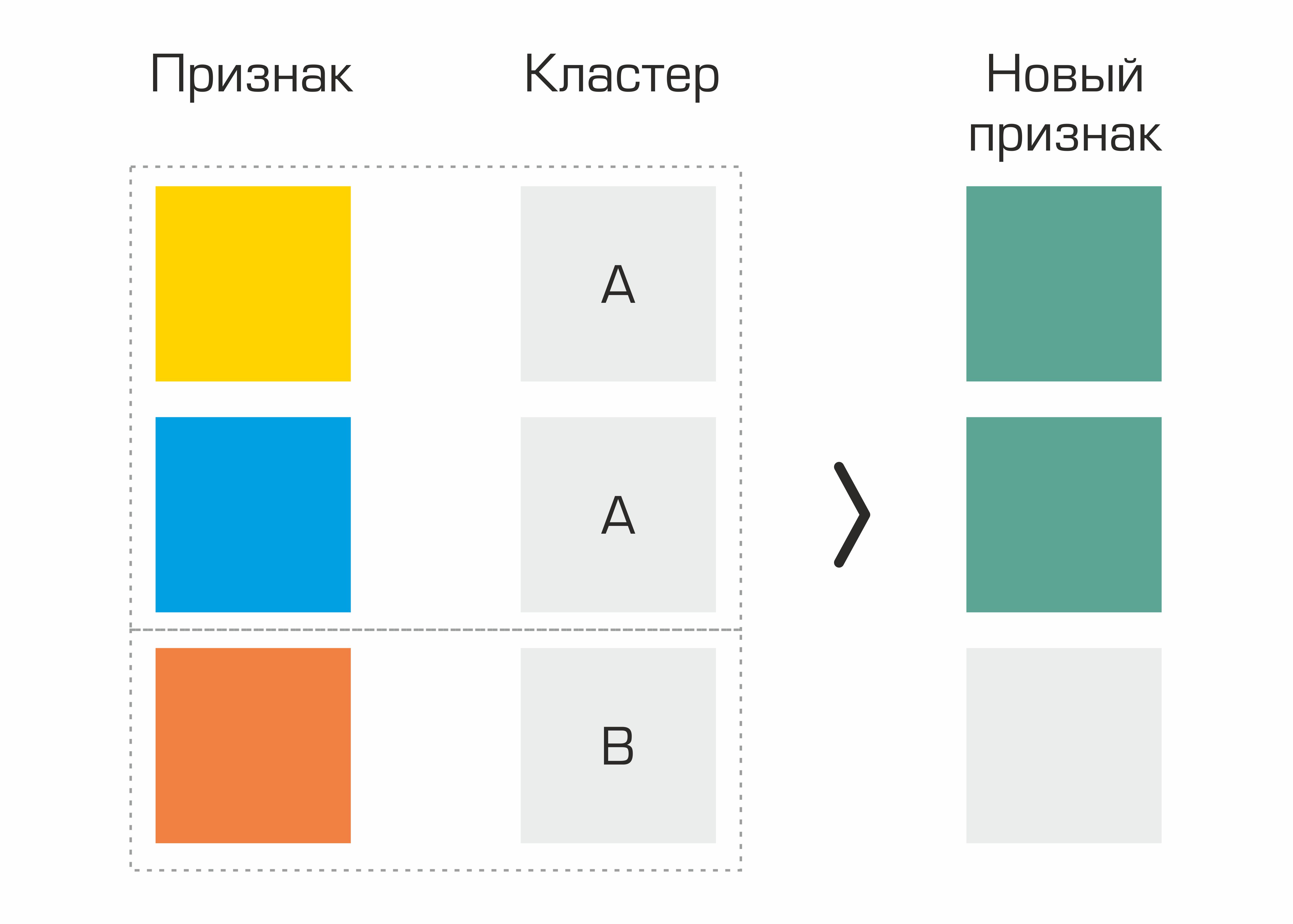
Proses pembuatan fitur berdasarkan pemilihan cluster.
Kami juga menambahkan tanda yang kami temukan saat direndam di wilayah domain: produksi minyak kumulatif dinormalisasi ke usia sumur dalam beberapa bulan, injeksi kumulatif dinormalisasi ke usia sumur dalam berbulan-bulan, parameter yang disertakan dalam rumus Dupuis. Tetapi pembuatan set standar dari PolynomialFeatures dari sklearn tidak memberi kami peningkatan kualitas.
3.
Pemilihan fitur Kami melakukan pemilihan fitur beberapa kali: baik secara manual bersama dengan pakar domain dan menggunakan metode pemilihan fitur standar. Setelah beberapa kali pengulangan, kami memutuskan untuk menghapus beberapa fitur yang tidak mempengaruhi target dari data. Karenanya, kami berhasil mengurangi ukuran kumpulan data, dengan tetap mempertahankan kualitas yang sama, yang memungkinkan untuk mempercepat pembuatan model secara signifikan.
Dan sekarang tentang metrik yang diterima ...
Pada salah satu lapangan didapatkan indikator kualitas model sebagai berikut:

Perlu diperhatikan bahwa hasil hydraulic fracturing juga bergantung pada sejumlah faktor eksternal yang tidak dapat diprediksi. Oleh karena itu, kita tidak dapat berbicara tentang mengurangi MAPE menjadi 0.
Kesimpulan
Pemilihan kandidat sumur untuk rekahan hidrolik menggunakan ML adalah proyek ambisius yang mempertemukan 7 orang: insinyur data, ilmuwan data, ahli domain dan manajer. Saat ini, proyek tersebut sebenarnya sudah siap diluncurkan dan sudah diujicobakan di beberapa anak perusahaan Perseroan.
Perusahaan terbuka untuk eksperimen, jadi sekitar 20 sumur dipilih dari daftar dan dibuat retak. Penyimpangan perkiraan dengan nilai aktual laju produksi minyak awal (MAPE) sekitar 10%. Dan ini adalah hasil yang sangat bagus!
Jangan licik: terutama pada tahap awal, beberapa sumur yang kami usulkan ternyata merupakan opsi yang tidak sesuai.
Tulis pertanyaan dan komentar - kami akan mencoba menjawabnya.
Berlangganan ke blog kami, kami memiliki lebih banyak ide dan proyek menarik, yang pasti akan kami tulis!