
PostgreSQL telah membuktikan nilainya - berfungsi dengan baik, digunakan oleh bisnis digital trendi seperti Alibaba dan TripAdvisor, dan kurangnya royalti menjadikannya alternatif yang menggoda untuk monster seperti MS SQL atau Oracle DB. Namun begitu kami mulai memikirkan tentang PostgreSQL di lanskap Perusahaan, kami segera menemukan persyaratan yang ketat: “Tapi bagaimana dengan toleransi kesalahan konfigurasi? tahan bencana? Dimana pemantauan komprehensifnya? bagaimana dengan pencadangan otomatis? bagaimana dengan menggunakan perpustakaan pita, baik penyimpanan langsung maupun sekunder? "
Di satu sisi, PostgreSQL tidak memiliki fasilitas backup built-in, seperti DBMS "dewasa" seperti RMAN untuk Oracle DB atau SAP Database Backup. Di sisi lain, pemasok sistem cadangan perusahaan (Veeam, Veritas, Commvault), meskipun mereka mendukung PostgreSQL, pada kenyataannya hanya bekerja dengan konfigurasi tertentu (biasanya mandiri) dan dengan serangkaian berbagai batasan.
Sistem cadangan yang dirancang khusus untuk PostgreSQL, seperti Barman, Wal-g, pg_probackup, sangat populer di instalasi PostgreSQL kecil atau di mana cadangan besar elemen lain dari lanskap TI tidak diperlukan. Misalnya, selain PostgreSQL, infrastruktur dapat memiliki server fisik dan virtual, OpenShift, Oracle, MariaDB, Cassandra, dll. Semua ini harus didukung dengan alat umum. Menempatkan solusi terpisah khusus untuk PostgreSQL adalah ide yang buruk: data akan disalin di suatu tempat ke disk, dan kemudian perlu dipindahkan ke tape. Duplikasi cadangan ini meningkatkan waktu pencadangan, dan juga, yang lebih penting, pemulihan.
Dalam solusi perusahaan, penginstalan didukung dengan sejumlah node dalam cluster khusus. Pada saat yang sama, misalnya, Commvault hanya dapat bekerja dengan cluster dua node, di mana Primer dan Sekunder ditetapkan secara kaku ke node tertentu. Dan masuk akal untuk mencadangkan hanya dengan Primer, karena mencadangkan dengan Sekunder memiliki batasannya. Karena kekhasan DBMS, dump tidak dibuat di Secondary, dan oleh karena itu hanya kemungkinan cadangan file yang tersisa.
Untuk mengurangi risiko waktu henti, membuat sistem yang toleran terhadap kesalahan akan membuat konfigurasi pengelompokan langsung dan Utama dapat bermigrasi secara bertahap di antara server yang berbeda. Misalnya, perangkat lunak Patroni sendiri meluncurkan Primer pada node cluster yang dipilih secara acak. SRK tidak memiliki cara untuk melacak ini di luar kotak, dan jika konfigurasi berubah, proses akan rusak. Artinya, pengenalan kontrol eksternal mencegah SRK bekerja secara efektif, karena server kontrol tidak memahami dari mana dan dari mana data perlu disalin.
Masalah lainnya adalah implementasi backup di Postgres. Hal ini dimungkinkan melalui dump, dan bekerja pada basis kecil. Namun dalam database besar, dump membutuhkan waktu lama, membutuhkan banyak sumber daya dan dapat menyebabkan kegagalan pada instance database.
Pencadangan file memperbaiki situasi ini, tetapi pada database besar berjalan lambat karena bekerja dalam mode single-threaded. Selain itu, vendor memiliki sejumlah batasan tambahan. Anda tidak dapat menggunakan file dan dump backup pada saat yang sama, atau deduplikasi tidak didukung. Ada banyak masalah, dan seringkali lebih mudah untuk memilih DBMS yang mahal tapi terbukti daripada Postgres.
Tidak ada tempat untuk mundur! Di belakang pengembang Moskow !
Namun, baru-baru ini tim kami menghadapi tantangan yang sulit: dalam proyek pembuatan AIS OSAGO 2.0, di mana kami membuat infrastruktur TI, pengembang untuk sistem baru memilih PostgreSQL.
Jauh lebih mudah bagi pengembang perangkat lunak besar untuk menggunakan solusi sumber terbuka yang "trendi". Facebook memiliki cukup banyak pakar untuk mendukung pekerjaan DBMS ini. Dan dalam kasus PCA, semua tugas "hari kedua" berada di pundak kami. Kami diminta untuk memberikan toleransi kesalahan, merakit cluster, dan, tentu saja, membuat cadangan. Logika tindakannya adalah sebagai berikut:
- Ajarkan SRK untuk membuat cadangan dari node utama cluster. Untuk melakukan ini, SRK harus menemukannya, yang berarti perlu integrasi dengan satu atau solusi lain untuk mengelola cluster PostgreSQL. Dalam kasus PCA, perangkat lunak Patroni digunakan untuk ini.
- Tentukan jenis cadangan berdasarkan jumlah data dan persyaratan pemulihan. Misalnya, saat perlu memulihkan halaman secara terperinci, gunakan dump, dan jika database besar dan pemulihan terperinci tidak diperlukan, bekerjalah di tingkat file.
- Lampirkan fitur pencadangan blok ke solusi untuk membuat cadangan multi-utas.
Pada saat yang sama, kami awalnya berangkat untuk membuat sistem yang efektif dan sederhana tanpa pengikat yang mengerikan dari komponen tambahan. Semakin sedikit kruk, semakin sedikit beban kerja pada staf dan semakin rendah risiko kegagalan IBS. Kami segera mengesampingkan pendekatan yang menggunakan Veeam dan RMAN, karena sekumpulan dua solusi sudah mengisyaratkan sistem tidak dapat diandalkan.
Sedikit keajaiban untuk perusahaan
Jadi, kami perlu menjamin cadangan yang andal untuk 10 kluster yang masing-masing terdiri dari 3 node, sementara infrastruktur yang sama dicerminkan di pusat data cadangan. Pusat data dalam paket PostgreSQL bekerja dengan prinsip aktif-pasif. Jumlah total database adalah 50 TB. SRC tingkat perusahaan mana pun dapat dengan mudah menangani ini. Tetapi nuansanya adalah pada awalnya Postgres tidak memiliki kaitan untuk kompatibilitas penuh dan mendalam dengan sistem cadangan. Oleh karena itu, kami harus mencari solusi yang awalnya memiliki fungsionalitas maksimum sehubungan dengan PostgreSQL, dan menyempurnakan sistem.
Kami melakukan 3 "hackathon" internal - kami melihat lebih dari lima puluh perkembangan, mengujinya, membuat perubahan sehubungan dengan hipotesis kami, dan mengujinya lagi. Setelah menganalisis opsi yang tersedia, kami memilih Commvault. Di luar kotak, produk ini dapat bekerja dengan instalasi terkelompok PostgreSQL yang paling sederhana, dan arsitektur terbukanya menimbulkan harapan (yang menjadi kenyataan) untuk penyempurnaan dan integrasi yang sukses. Commvault juga dapat membuat cadangan log PostgreSQL. Misalnya, Veritas NetBackup di bagian PostgreSQL hanya dapat membuat cadangan penuh.
Pelajari lebih lanjut tentang arsitektur. Server manajemen Commvault dipasang di masing-masing dari dua pusat data dalam konfigurasi CommServ HA. Sistem dicerminkan, dikelola melalui satu konsol, dan dari sudut pandang HA, sistem memenuhi semua persyaratan perusahaan.
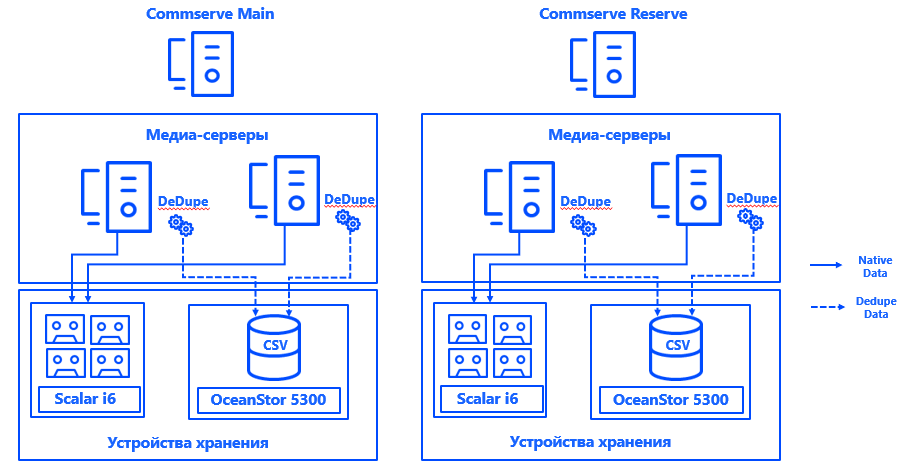
Kami juga meluncurkan dua server media fisik di setiap pusat data, yang kami hubungkan dengan susunan disk dan perpustakaan pita yang didedikasikan khusus untuk pencadangan melalui SAN melalui Fibre Channel. Basis deduplikasi yang diperluas memastikan ketahanan server media, dan menghubungkan setiap server ke setiap CSV memastikan operasi berkelanjutan jika terjadi kegagalan komponen apa pun. Arsitektur sistem memungkinkan pencadangan dilanjutkan meskipun salah satu pusat data jatuh.
Patroni mendefinisikan simpul utama untuk setiap cluster. Ini bisa berupa node gratis di pusat data - tetapi hanya di utama. Di backup, semua node adalah Secondary.
Agar Commvault memahami node cluster mana yang merupakan Primer, kami mengintegrasikan sistem (berkat arsitektur solusi terbuka) dengan Postgres. Untuk melakukan ini, skrip dibuat yang melaporkan lokasi node utama saat ini ke server manajemen Commvault.
Secara umum, prosesnya terlihat seperti ini:
Patroni memilih Primary → Keepalived menampilkan cluster IP dan menjalankan skrip → Commvault agent pada node cluster yang dipilih menerima pemberitahuan bahwa itu adalah Primary → Commvault secara otomatis mengkonfigurasi ulang backup dalam pseudo-client.
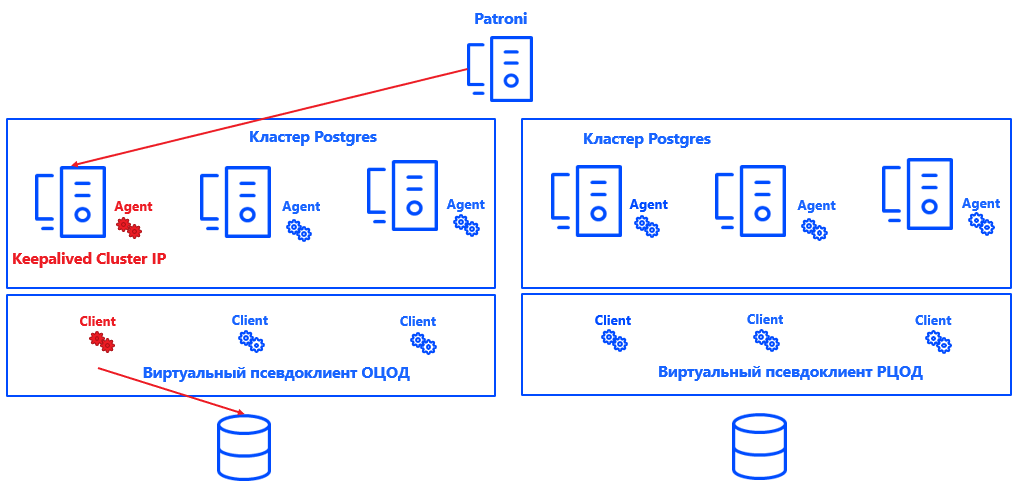
Keuntungan dari pendekatan ini adalah bahwa solusinya tidak mempengaruhi konsistensi, atau kebenaran log, atau pemulihan instance Postgres. Ini juga mudah diskalakan, karena sekarang tidak perlu memperbaiki node Primer dan Sekunder untuk Commvault. Sudah cukup bahwa sistem memahami di mana Primer berada, dan jumlah node dapat ditingkatkan ke hampir semua nilai.
Solusinya tidak berpura-pura menjadi ideal dan memiliki nuansa tersendiri. Commvault hanya dapat mencadangkan seluruh instance, bukan database individu. Oleh karena itu, contoh terpisah telah dibuat untuk setiap database. Klien nyata digabungkan menjadi klien palsu virtual. Setiap klien palsu Commvault adalah kluster UNIX. Ia menambahkan node cluster tempat agen Commvault untuk Postgres diinstal. Hasilnya, semua node virtual klien semu dicadangkan sebagai satu instance.
Dalam setiap klien-semu, node aktif dari cluster ditunjukkan. Inilah yang didefinisikan oleh solusi integrasi kami untuk Commvault. Prinsip operasinya cukup sederhana: jika IP cluster naik pada sebuah node, skrip menetapkan parameter "node aktif" dalam biner agen Commvault - pada kenyataannya, skrip menetapkan "1" di bagian memori yang diperlukan. Agen mengirimkan data ini ke CommServe, dan Commvault membuat cadangan dari node yang diinginkan. Selain itu, kebenaran konfigurasi diperiksa di tingkat skrip, membantu menghindari kesalahan saat memulai pencadangan.
Pada saat yang sama, database besar dicadangkan dalam blok di beberapa utas, memenuhi persyaratan RPO dan jendela cadangan. Beban pada sistem tidak signifikan: Salinan lengkap tidak terlalu sering muncul, pada hari-hari lain hanya log yang dikumpulkan, terlebih lagi, selama periode muatan rendah.
Ngomong-ngomong, kami telah menerapkan kebijakan terpisah untuk mencadangkan log yang diarsipkan PostgreSQL - mereka disimpan sesuai dengan aturan yang berbeda, disalin sesuai dengan jadwal yang berbeda dan deduplikasi tidak diaktifkan untuknya, karena log ini berisi data unik.
Untuk memastikan konsistensi dari seluruh infrastruktur TI, klien file Commvault terpisah diinstal di setiap node cluster. Mereka mengecualikan file Postgres dari backup dan dimaksudkan hanya untuk OS dan backup aplikasi. Bagian data ini juga memiliki kebijakannya sendiri, dan periode penyimpanannya sendiri.

Sekarang SRK tidak memengaruhi layanan produktif, tetapi jika situasinya berubah, sistem pembatas beban dapat diaktifkan di Commvault.
Apakah itu bagus Baik!
Jadi, kami tidak hanya mendapatkan yang bisa diterapkan, tetapi juga cadangan yang sepenuhnya otomatis untuk instalasi PostgreSQL berkerumun, yang memenuhi semua persyaratan panggilan perusahaan.
Parameter RPO dan RTO pada 1 jam dan 2 jam tumpang tindih dengan margin, yang berarti sistem akan mematuhinya bahkan dengan peningkatan signifikan dalam volume data yang disimpan. Meskipun banyak keraguan, PostgreSQL dan lingkungan perusahaan cukup kompatibel. Dan sekarang kami tahu dari pengalaman kami sendiri bahwa backup untuk DBMS dapat dilakukan dalam berbagai konfigurasi.
Tentu saja, di sepanjang perjalanan, kami harus memakai tujuh pasang sepatu besi, mengatasi sejumlah kesulitan, menginjak beberapa garu dan memperbaiki sejumlah kesalahan. Namun sekarang pendekatan tersebut telah diuji dan dapat digunakan untuk mengimplementasikan Open Source sebagai ganti DBMS berpemilik di lingkungan perusahaan yang keras.
Sudahkah Anda mencoba PostgreSQL di lingkungan perusahaan?
Penulis:
Oleg Lavrenov, Insinyur Desain sistem penyimpanan data Jet Infosystems
Dmitry Erykin, Insinyur Desain Sistem Komputasi Jet Infosystems