Kami di Lyft memutuskan untuk memindahkan infrastruktur server kami ke Kubernetes, sistem orkestrasi container terdistribusi, untuk memanfaatkan keuntungan yang ditawarkan oleh otomatisasi. Mereka menginginkan platform yang kokoh dan andal yang dapat menjadi fondasi untuk pengembangan lebih lanjut, serta mengurangi biaya keseluruhan sekaligus meningkatkan efisiensi.
Sistem terdistribusi bisa jadi sulit untuk dipahami dan dianalisis, tidak terkecuali Kubernetes. Terlepas dari banyak manfaatnya, kami mengidentifikasi beberapa hambatan saat berpindah ke CronJob , sistem yang dibangun ke dalam Kubernetes untuk melakukan tugas berulang sesuai jadwal. Dalam seri dua bagian ini, kami akan membahas kelemahan teknis dan operasional Kubernetes CronJob saat digunakan dalam proyek besar dan berbagi dengan Anda pengalaman kami mengatasinya.
Pertama, saya akan menjelaskan kekurangan dari Kubernetes CronJobs yang kami temui saat menggunakannya di Lyft. Kemudian (di bagian kedua) - kami akan memberi tahu Anda bagaimana kami menghilangkan kekurangan ini di tumpukan Kubernetes, meningkatkan kegunaan, dan meningkatkan keandalan.
Bagian 1. Pendahuluan
Siapa yang akan mendapat manfaat dari artikel ini?
- Pengguna Kubernetes CronJob.
- , Kubernetes.
- , Kubernetes .
- , Kubernetes , .
- Contributor' Kubernetes.
?
- , Kubernetes ( , CronJob) .
- , Kubernetes Lyft , .
:
- cron'.
- , CronJob, — , CronJob, Job' Pod', . CronJob Unix cron' .
- sidecar- , . Lyft sidecar- , runtime- Envoy, statsd .., sidecar-, , .
- ronjobcontroller — Kubernetes, CronJob'.
- , cron , ( ).
- Lyft Engineering , ( «», « », « ») — Lyft ( «», « », «» «»). , , «-» .
CronJob' Lyft
Saat ini, lingkungan produksi multi-tenant kami memiliki hampir 500 cron job yang dipanggil lebih dari 1500 kali per jam.
Tugas berulang dan terjadwal digunakan secara ekstensif oleh Lyft untuk berbagai tujuan. Sebelum pindah ke Kubernetes, mereka berjalan langsung di mesin Linux menggunakan cron Unix biasa. Tim pengembangan bertanggung jawab untuk menulis
crontab-definisi dan menyediakan instance, yang mengeksekusinya menggunakan pipeline Infrastructure As Code (IaC), dan tim infrastruktur bertanggung jawab untuk memeliharanya.
Sebagai bagian dari upaya yang lebih besar untuk membuat container dan memigrasi beban kerja ke platform Kubernetes kami sendiri, kami memutuskan untuk pindah ke CronJob *, mengganti cron Unix klasik dengan rekan Kubernetesnya. Seperti banyak lainnya, Kubernetes dipilih karena keuntungannya yang besar (setidaknya dalam teori), termasuk penggunaan sumber dayanya yang efisien.
Bayangkan tugas cron yang dijalankan seminggu sekali selama 15 menit. Di lingkungan lama kita, mesin yang didedikasikan untuk tugas ini akan selalu menganggur 99,85%. Dalam kasus Kubernetes, sumber daya komputasi (CPU, memori) hanya digunakan selama panggilan. Sisa waktu, kapasitas yang tidak terpakai dapat digunakan untuk meluncurkan lainnya cronjob, atau hanya skala-downgugus. Mengingat cara menjalankan cron job di masa lalu, kami akan mendapat banyak manfaat dari beralih ke model di mana pekerjaan bersifat sementara.

Batasan Tanggung Jawab untuk Pengembang dan Engineer Platform di Lyft Stack
Setelah pindah ke platform Kubernetes, tim pengembangan berhenti mengalokasikan dan mengoperasikan instance komputasi mereka sendiri. Tim platform sekarang bertanggung jawab untuk memelihara dan mengoperasikan sumber daya komputasi dan dependensi waktu proses di tumpukan Kubernetes. Selain itu, dia bertanggung jawab untuk membuat objek CronJob sendiri. Pengembang hanya perlu mengkonfigurasi jadwal tugas dan kode aplikasi.
Namun, semuanya terlihat bagus di atas kertas. Dalam praktiknya, kami telah mengidentifikasi beberapa hambatan saat bermigrasi dari lingkungan cron Unix tradisional yang diteliti dengan baik ke lingkungan CronJob singkat yang terdistribusi di Kubernetes.
* Meskipun CronJob dulu dan masih (sejak Kubernetes v1.18) berstatus beta, kami merasa CronJob cukup memuaskan untuk kebutuhan kami saat itu dan juga sangat cocok dengan perangkat infrastruktur Kubernetes lainnya yang kami miliki ...
Apa perbedaan antara Kubernetes CronJob dan Unix cron?
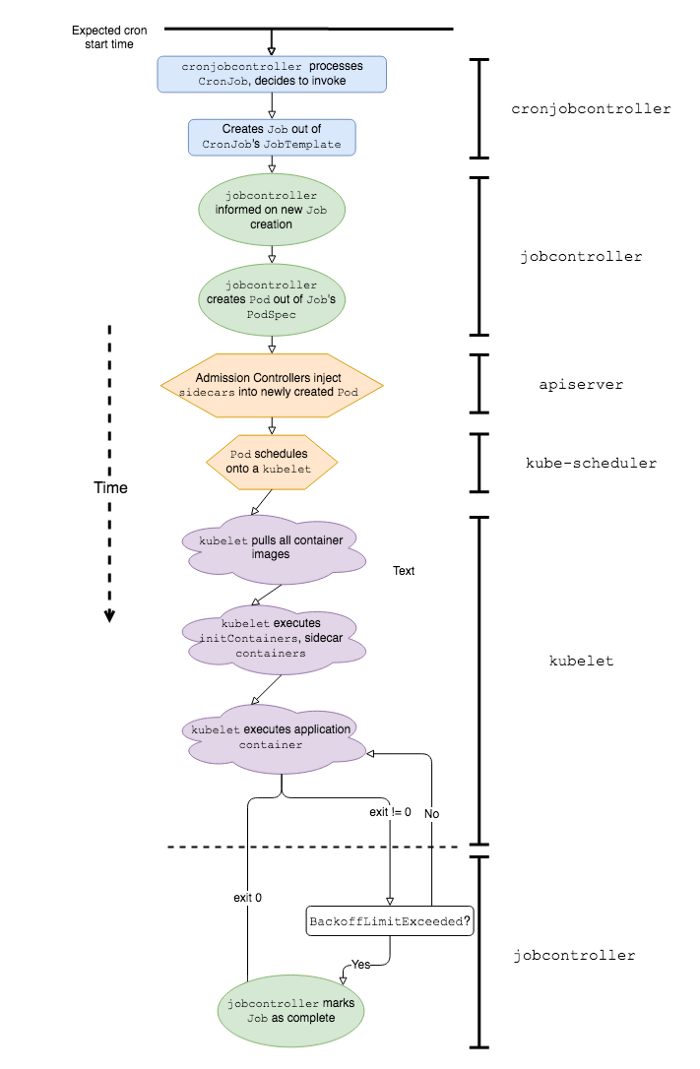
Urutan kejadian yang disederhanakan dan komponen perangkat lunak K8 yang terlibat dalam pekerjaan Kubernetes CronJob
Untuk lebih menjelaskan mengapa bekerja dengan Kubernetes CronJob dalam lingkungan produksi dikaitkan dengan kesulitan tertentu, mari kita tentukan dulu perbedaannya dari yang klasik. CronJob seharusnya bekerja dengan cara yang sama seperti pekerjaan cron Linux atau Unix; namun, sebenarnya ada setidaknya beberapa perbedaan utama dalam perilaku mereka: kecepatan mulai dan penanganan kerusakan .
Kecepatan peluncuran
Penundaan mulai (penundaan mulai) didefinisikan sebagai waktu yang telah berlalu dari cron mulai terjadwal hingga awal sebenarnya dari kode aplikasi. Dengan kata lain, jika cron dijadwalkan untuk mulai pada 00:00:00 dan aplikasi mulai berjalan pada 00:00:22, maka penundaan dalam memulai cron tersebut adalah 22 detik.
Dalam kasus cron Unix klasik, penundaan startup minimal. Ketika waktunya tepat, perintah-perintah ini dijalankan dengan mudah. Mari kita konfirmasikan ini dengan contoh berikut:
# date
0 0 * * * date >> date-cron.log
Dengan konfigurasi cron seperti ini, kemungkinan besar kita akan mendapatkan output berikut
date-cron.log:
Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
Di sisi lain, Kubernetes CronJob dapat mengalami penundaan startup yang signifikan karena aplikasi tersebut didahului oleh sejumlah peristiwa. Berikut beberapa di antaranya:
-
cronjobcontrollermemproses dan memutuskan untuk memanggil CronJob; -
cronjobcontrollermembuat Pekerjaan berdasarkan spesifikasi pekerjaan CronJob; -
jobcontrollermemperhatikan Job baru dan membuat Pod; - Admission Controller memasukkan data kontainer sespan ke dalam spesifikasi Pod *;
-
kube-schedulermerencanakan Pod di kubelet; -
kubeletmeluncurkan Pod (mengambil semua gambar container); -
kubeletmemulai semua kontainer sespan *; -
kubeletmemulai wadah aplikasi *.
* Tahapan ini unik untuk tumpukan Lyft Kubernetes.
Kami menemukan bahwa item 1, 5, dan 7 memberikan kontribusi paling signifikan terhadap latensi setelah kami mencapai skala CronJob tertentu di lingkungan Kubernetes.
Penundaan karena pekerjaan cronjobcontroller'
Untuk lebih memahami dari mana latensi berasal, mari kita periksa kode sumber sebaris
cronjobcontroller'. Di Kubernetes 1.18, itu cronjobcontrollerhanya memeriksa semua CronJob setiap 10 detik dan menjalankan beberapa logika pada masing-masing.
Implementasinya
cronjobcontroller'melakukan ini secara sinkron dengan membuat setidaknya satu panggilan API tambahan untuk setiap CronJob. Ketika jumlah CronJob melebihi angka tertentu, panggilan API ini mulai mengalami kendala sisi klien .
Siklus polling 10 detik dan panggilan API sisi klien menyebabkan peningkatan yang signifikan dalam penundaan peluncuran CronJob.
Menjadwalkan pod dengan cron
Karena sifat dari jadwal cron, kebanyakan dari jadwal tersebut berjalan di awal menit (XX: YY: 00). Misalnya,
@hourlycron (per jam) berjalan pada 01:00:00, 02:00:00, dll. Dalam kasus platform cron multi-tenant dengan banyak crons yang berjalan setiap jam, setiap seperempat jam, setiap 5 menit, dll., Ini menyebabkan kemacetan (hotspot) saat beberapa crons dimulai pada waktu bersamaan. Kami di Lyft memperhatikan bahwa salah satu tempat seperti itu adalah awal jam (XX: 00: 00). Hotspot ini membuat beban dan menyebabkan pembatasan tambahan frekuensi permintaan dalam komponen lapisan kontrol yang terlibat dalam pelaksanaan CronJob, seperti kube-schedulerdan kube-apiserver, yang menyebabkan peningkatan nyata dalam penundaan startup.
Selain itu, jika Anda tidak menyediakan daya komputasi untuk beban puncak (dan / atau menggunakan instance komputasi layanan cloud), dan sebaliknya menggunakan mekanisme penskalaan otomatis cluster untuk menskalakan node secara dinamis, waktu yang dibutuhkan untuk memulai node akan menambah kontribusi tambahan untuk latensi startup. pods CronJob.
Peluncuran Pod: penampung pembantu
Setelah pod CronJob berhasil dijadwalkan
kubelet, pod CronJob akan mengambil dan menjalankan gambar container dari semua sidecars dan aplikasi itu sendiri. Karena spesifikasi peluncuran container di Lyft (container sidecar dimulai sebelum container aplikasi), penundaan dalam memulai sidecar apa pun pasti akan memengaruhi hasil, yang menyebabkan penundaan tambahan dalam memulai tugas.
Dengan demikian, penundaan saat startup, sebelum eksekusi kode aplikasi yang diperlukan, ditambah dengan sejumlah besar CronJob di lingkungan multi-tenant, menyebabkan penundaan startup yang nyata dan tidak dapat diprediksi. Seperti yang akan kita lihat nanti, dalam kehidupan nyata, penundaan seperti itu dapat berdampak negatif pada perilaku CronJob, yang mengancam peluncuran yang terlewat.
Penanganan kecelakaan kontainer
Secara umum, disarankan untuk mengawasi pekerjaan crons. Untuk sistem Unix, ini cukup mudah dilakukan. Crones Unix menafsirkan perintah yang diberikan menggunakan shell yang ditentukan
$SHELL, dan setelah perintah keluar (berhasil atau tidak), panggilan tersebut dianggap selesai. Anda dapat melacak eksekusi cron di Unix menggunakan skrip sederhana seperti ini:
#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
Dalam kasus Unix, cron
stat-and-logakan berjalan tepat sekali untuk setiap panggilan cron - terlepas dari $exitcode. Oleh karena itu, metrik ini dapat digunakan untuk mengatur notifikasi paling sederhana tentang panggilan yang tidak berhasil.
Dalam kasus CronJob Kubernetes, di mana percobaan ulang pada kegagalan ditentukan secara default, dan kegagalan itu sendiri dapat disebabkan oleh berbagai alasan (Kegagalan pekerjaan atau kegagalan kontainer), pemantauan tidak sesederhana dan langsung.
Menggunakan skrip serupa di wadah aplikasi dan dengan Pekerjaan yang dikonfigurasi untuk memulai kembali saat gagal, CronJob akan mencoba menjalankan tugas saat gagal, menghasilkan metrik dan log dalam proses, hingga mencapai BackoffLimit(jumlah percobaan ulang maks.). Dengan demikian, pengembang yang mencoba menentukan penyebab masalah harus memilah banyak "sampah" yang tidak perlu. Selain itu, peringatan dari skrip shell sebagai respons terhadap kegagalan pertama juga dapat berubah menjadi gangguan biasa yang tidak mungkin mendasarkan tindakan lebih lanjut, karena wadah aplikasi dapat memulihkan dan berhasil menyelesaikan tugasnya sendiri.
Anda bisa mengimplementasikan peringatan di level Job, bukan di level container aplikasi. Untuk ini, metrik level API untuk kegagalan Pekerjaan tersedia, seperti
kube_job_status_faileddari kube-state-metrics. Kerugian dari pendekatan ini adalah insinyur yang bertugas hanya menjadi sadar akan masalah setelah Pekerjaan mencapai "tahap kegagalan akhir" dan mencapai batas BackoffLimit, yang dapat terjadi lebih lama dari kegagalan pertama wadah aplikasi.
CronJob'
Siklus penundaan mulai dan mulai ulang yang substansial memperkenalkan latensi tambahan yang dapat mencegah Kubernetes CronJob dijalankan ulang. Dalam kasus CronJob yang sering dipanggil, atau yang waktu runtime jauh lebih lama daripada waktu idle, penundaan tambahan ini dapat menyebabkan masalah dengan panggilan terjadwal berikutnya. Jika CronJob memiliki kebijakan
ConcurrencyPolicy: Forbidyang melarang konkurensi , penundaan mengakibatkan panggilan di masa mendatang tidak diselesaikan tepat waktu dan tertunda.

Contoh garis waktu (dari sudut pandang cronjobcontroller) di mana startingDeadlineSeconds terlampaui untuk CronJob per jam tertentu: ia melewati mulai yang dijadwalkan dan tidak akan dipanggil hingga waktu yang dijadwalkan berikutnya
Ada juga skenario yang lebih tidak menyenangkan (kami menemukannya di Lyft), karena CronJob dapat sepenuhnya melewatkan panggilan, ini adalah saat CronJob diinstal
startingDeadlineSeconds. Dalam skenario ini, jika penundaan startup melebihi startingDeadlineSeconds, CronJob akan melewati mulai seluruhnya.
Selain itu, jika
ConcurrencyPolicyCronJob diatur ke Forbid, restart-on-failure-cycle dari panggilan sebelumnya juga dapat mengganggu panggilan CronJob berikutnya.
Masalah dengan pengoperasian Kubernetes CronJob dalam kondisi dunia nyata
Sejak kami mulai memigrasi tugas kalender yang berulang ke Kubernetes, ditemukan bahwa menggunakan mekanisme CronJob yang tidak berubah mengarah ke momen yang tidak menyenangkan, baik dari sudut pandang pengembang maupun dari sudut pandang tim platform. Sayangnya, mereka mulai meniadakan manfaat dan manfaat yang awalnya kami pilih Kubernetes CronJob. Kami segera menyadari bahwa baik pengembang maupun tim platform tidak memiliki alat yang diperlukan untuk mengeksploitasi CronJob dan memahami siklus hidup mereka yang rumit.
Para pengembang mencoba untuk mengeksploitasi CronJob mereka dan mengkonfigurasinya, tetapi sebagai hasilnya mereka datang kepada kami dengan banyak keluhan dan pertanyaan seperti ini:
- Mengapa cron saya tidak berfungsi?
- Sepertinya cron saya berhenti bekerja. Bagaimana Anda bisa memastikan bahwa itu benar-benar berjalan?
- Saya tidak tahu bahwa cron tidak berfungsi dan saya pikir semuanya baik-baik saja.
- Bagaimana cara "memperbaiki" cron yang hilang? Saya tidak bisa hanya login SSH dan menjalankan perintah sendiri.
- Dapatkah Anda mengetahui mengapa cron ini tampaknya melewatkan beberapa proses antara X hingga Y?
- Kami memiliki X (jumlah besar) cron, masing-masing dengan pemberitahuannya sendiri, dan menjadi sangat membosankan / sulit untuk mempertahankan semuanya.
- Pod, Job, sidecar - omong kosong macam apa ini?
Sebagai tim platform , kami tidak dapat menjawab pertanyaan seperti:
- Bagaimana cara mengukur kinerja platform Kubernetes cron?
- Bagaimana mengaktifkan CronJob tambahan akan memengaruhi lingkungan Kubernetes kita?
- Kubernetes CronJob' ( multi-tenant) single-tenant cron' Unix?
- Service-Level-Objectives (SLOs — ) ?
- , , , ?
Debugging CronJob crash bukanlah tugas yang mudah. Seringkali dibutuhkan intuisi untuk memahami di mana kegagalan terjadi dan di mana mencari bukti. Terkadang petunjuk ini cukup sulit untuk diperoleh - seperti, misalnya, log
cronjobcontroller', yang direkam hanya jika detail tingkat tinggi diaktifkan. Selain itu, jejak bisa hilang begitu saja setelah jangka waktu tertentu, yang membuat debugging mirip dengan game "Kick a mole" (tentang ini - kira-kira. Terjemahan), Misalnya, Acara Kubernetes untuk CronJob, Pekerjaan, dan Pod yang secara default hanya disimpan selama satu jam. Tak satu pun dari metode ini yang mudah digunakan, dan tidak ada yang berskala baik dalam hal dukungan seiring dengan bertambahnya jumlah CronJob di platform.
Juga, terkadang Kubernetes sajaberhenti mencoba menjalankan CronJob jika gagal menjalankan terlalu banyak proses. Dalam kasus ini, itu harus dimulai ulang secara manual. Dalam kehidupan nyata, ini terjadi jauh lebih sering daripada yang Anda bayangkan, dan kebutuhan untuk memperbaiki masalah secara manual setiap kali menjadi sangat menyakitkan.
Ini menyimpulkan bahwa saya menyelami masalah teknis dan operasional yang kami temui saat menggunakan Kubernetes CronJob dalam proyek yang sibuk. Di bagian kedua, kita akan berbicara tentang bagaimana kita menghilangkan Kubernetes di tumpukan kita, meningkatkan kegunaan dan meningkatkan keandalan CronJob.
Bagian 2. Pendahuluan
Menjadi jelas bahwa Kubernetes CronJob dalam bentuknya yang tidak berubah tidak dapat menjadi pengganti yang sederhana dan nyaman untuk rekan Unix mereka. Untuk mentransfer semua crone kami ke Kubernetes dengan percaya diri, kami tidak hanya perlu menghilangkan kekurangan teknis CronJob, tetapi juga meningkatkan kegunaannya . Yaitu:
1. Dengarkan para developer untuk memahami jawaban atas pertanyaan apa saja yang paling mereka khawatirkan tentang crones. Misalnya: Apakah cron saya sudah mulai? Apakah kode aplikasi dijalankan? Apakah peluncurannya berhasil? Berapa lama cron berjalan? (Berapa lama waktu yang dibutuhkan kode aplikasi?)
2. Sederhanakan pemeliharaan platform dengan membuat CronJob lebih mudah dipahami, siklus hidupnya lebih transparan, dan batas platform / aplikasi lebih jelas.
3. Lengkapi platform kami dengan metrik dan peringatan standar untuk mengurangi jumlah konfigurasi peringatan khusus dan mengurangi jumlah duplikat ikatan cron yang harus ditulis dan dipelihara oleh pengembang.
4. Kembangkan alat untuk pemulihan kerusakan mudah dan menguji konfigurasi CronJob baru.
5. Memperbaiki masalah teknis yang sudah berlangsung lama di Kubernetes , seperti bug TooManyMissedStarts yang memerlukan intervensi manual untuk memperbaikinya dan menyebabkan crash dalam satu skenario kegagalan kritis ( saat startingDeadlineSeconds tidak disetel ) tanpa diketahui.
Keputusan
Kami menyelesaikan semua masalah ini sebagai berikut:
- (observability). CronJob', (Service Level Objectives, SLOs) .
- CronJob' « » Kubernetes.
- Kubernetes.
CronJob'

Contoh dasbor yang dibuat oleh platform untuk memantau CronJob tertentu
Kami telah menambahkan metrik berikut ke tumpukan Kubernetes (mereka ditentukan untuk semua CronJob di Lyft):
1.
started.count- penghitung ini bertambah saat wadah aplikasi pertama kali diluncurkan saat CronJob dipanggil. Ini membantu menjawab pertanyaan: “ Apakah kode aplikasi berjalan? ".
2.
{success, failure}.count- penghitung ini bertambah ketika panggilan CronJob tertentu mencapai status terminal (yaitu, Pekerjaan telah menyelesaikan tugasnya dan jobcontrollertidak lagi mencoba untuk menjalankannya). Mereka menjawab pertanyaan: “ Apakah peluncurannya berhasil? ".
3.
scheduling-decision.{invoke, skip}.count- penghitung inimemungkinkan Anda mengetahui tentang keputusan yang dibuat cronjobcontrollersaat menelepon CronJob. Secara khusus, skip.countmenjawab pertanyaan: " Mengapa cron saya tidak berfungsi? ". Label berikut bertindak sebagai parameternya reason:
-
reason = concurrencyPolicy-cronjobcontrollermelewatkan panggilan ke CronJob, karena jika tidak maka akan merusaknyaConcurrencyPolicy; -
reason = missedDeadline-cronjobcontrollermenolak untuk memanggil CronJob, karena tidak terjawab jendela panggilan yang ditentukan.spec.startingDeadlineSeconds; -
reason = errorMerupakan parameter umum untuk semua kesalahan lain yang terjadi saat mencoba memanggil CronJob.
4.
app-container-duration.seconds- Timer ini mengukur umur wadah aplikasi. Ini membantu menjawab pertanyaan: " Berapa lama kode aplikasi berjalan? ". Di timer ini, kami sengaja tidak memasukkan waktu yang dibutuhkan untuk penjadwalan pod, peluncuran kontainer sespan, dll., Karena semuanya adalah tanggung jawab tim platform dan termasuk dalam penundaan peluncuran.
5.
start-delay.seconds- Timer ini mengukur penundaan start. Metrik ini, jika digabungkan ke seluruh platform, memungkinkan teknisi yang memeliharanya tidak hanya untuk mengevaluasi, memantau, dan menyesuaikan kinerja platform, tetapi juga berfungsi sebagai dasar untuk menentukan SLO untuk parameter seperti penundaan startup dan frekuensi jadwal cron maksimum.
Berdasarkan metrik ini, kami telah membuat lansiran default. Mereka memberi tahu pengembang ketika:
- CronJob mereka tidak mulai sesuai jadwal (
rate(scheduling-decision.skip.count) > 0); - CronJob mereka gagal (
rate(failure.count) > 0).
Pengembang tidak perlu lagi menentukan peringatan dan metrik mereka sendiri untuk crons di Kubernetes - platform menyediakan rekan siap pakai mereka.
Menjalankan crons jika perlu
Kami mengadaptasinya
kubectl create job test-job --from=cronjob/<your-cronjob>untuk alat CLI internal kami. Insinyur Lyft menggunakannya untuk berinteraksi dengan layanan mereka di Kubernetes untuk memanggil CronJob saat diperlukan untuk:
- pemulihan dari crash CronJob intermiten;
- runtime- , 3:00 ( , CronJob', Job' Pod' ), — , ;
- runtime- CronJob' Unix cron', , .
TooManyMissedStarts
Kami telah memperbaiki bug dengan TooManyMissedStarts , sehingga sekarang CronJob tidak "hang" setelah 100 kali kesalahan dimulai. Tambalan ini tidak hanya menghilangkan kebutuhan akan intervensi manual, tetapi memungkinkan Anda untuk benar - benar melacak kapan waktu
startingDeadlineSeconds terlampaui . Terima kasih kepada Vallery Lancey untuk merancang dan membangun tambalan ini, Tom Wanielista untuk membantu merancang algoritme. Kami membuka PR untuk membawa tambalan ini ke cabang Kubernetes utama (namun, itu tidak pernah diadopsi, dan ditutup karena tidak aktif - kira-kira. Terjemahan) .
Menerapkan pemantauan cron

Pada tahapan siklus hidup Kubernetes CronJob apa kami menambahkan mekanisme ekspor metrik
Lansiran yang tidak bergantung pada jadwal cron
Bagian tersulit dalam mengimplementasikan notifikasi panggilan cron tidak terjawab adalah menangani jadwal mereka ( crontab.guru berguna untuk menguraikannya ). Misalnya, perhatikan jadwal berikut:
# 5
*/5 * * * *
Anda dapat membuat penghitung untuk kenaikan cron ini setiap kali keluar (atau menggunakan pengikatan cron ). Kemudian, di sistem notifikasi, Anda dapat menulis ekspresi bersyarat dari formulir: "Lihat 60 menit sebelumnya dan beri tahu saya jika penghitung bertambah kurang dari 12". Masalah terpecahkan, bukan?
Tetapi bagaimana jika jadwal Anda terlihat seperti ini:
# 9 17
# .
# , (9-17, -)
0 9–17 * * 1–5
Dalam hal ini, Anda harus mengotak-atik kondisinya (meskipun, mungkin sistem Anda memiliki fungsi notifikasi hanya untuk jam kerja?). Namun, contoh berikut menggambarkan bahwa pemberitahuan yang mengikat ke jadwal cron memiliki beberapa kelemahan:
- Saat Anda mengubah jadwal, Anda harus membuat perubahan pada logika notifikasi.
- Beberapa jadwal cron memerlukan kueri yang cukup kompleks untuk direplikasi menggunakan deret waktu.
- Perlu ada semacam "masa tunggu" bagi crone yang tidak memulai pekerjaannya tepat pada waktunya untuk meminimalkan kesalahan positif.
Langkah 2 saja membuat pembuatan notifikasi secara default untuk semua crone di platform menjadi tugas yang sangat sulit, dan langkah 3 sangat relevan untuk platform terdistribusi seperti Kubernetes CronJob, di mana penundaan peluncuran merupakan faktor yang signifikan. Selain itu, ada solusi yang menggunakan " saklar orang mati ", yang sekali lagi membawa kita kembali ke kebutuhan untuk mengikat pemberitahuan ke jadwal cron, dan / atau algoritma deteksi anomali yang memerlukan beberapa pelatihan dan tidak langsung bekerja untuk CronJob baru atau perubahan pada mereka. jadwal.
Cara lain untuk melihat masalah ini adalah dengan bertanya pada diri sendiri: apa yang dimaksud dengan cron yang seharusnya dimulai tetapi tidak?
Di Kubernetes, jika Anda lupa tentang bug di
cronjobcontroller'atau kemungkinan jatuhnya bidang kontrol itu sendiri (meskipun Anda harus segera melihat ini jika Anda melacak status cluster dengan benar) - ini berarti cronjobcontrollerCronJob mengevaluasi dan memutuskan (sesuai dengan jadwal cron) bahwa ia harus dipanggil, tetapi karena alasan tertentu untuk alasan yang saya sengaja memutuskan untuk tidak melakukannya .
Kedengarannya familiar? Inilah tepatnya yang dilakukan metrik kami
scheduling-decision.skip.count! Sekarang kita hanya perlu melacak perubahan rate(scheduling-decision.skip.count)untuk memberi tahu pengguna bahwa CronJob-nya seharusnya sudah dipicu, tetapi ternyata tidak.
Solusi ini memisahkan jadwal cron dari notifikasi itu sendiri, memberikan beberapa keuntungan:
- Sekarang Anda tidak perlu mengkonfigurasi ulang peringatan saat mengubah jadwal.
- Tidak perlu permintaan dan ketentuan waktu yang rumit.
- Anda dapat dengan mudah membuat peringatan default untuk semua CronJob di platform.
Ini, digabungkan dengan deret waktu dan peringatan lain yang disebutkan sebelumnya, membantu membuat gambaran yang lebih lengkap dan dapat dipahami tentang keadaan CronJob.
Menerapkan Start Delay Timer
Karena sifat kompleks dari siklus hidup CronJob, kami perlu mempertimbangkan dengan cermat titik-titik tertentu dari penempatan toolkit di tumpukan untuk mengukur metrik ini dengan andal dan akurat. Akibatnya, semuanya bermuara untuk memperbaiki dua poin tepat waktu:
- T1: kapan cron harus dimulai (sesuai dengan jadwalnya).
- T2: Ketika kode aplikasi benar-benar mulai dijalankan.
Dalam hal ini
start delay(penundaan mulai) = 2 — 1. Untuk memperbaiki momen T1, kami menyertakan kode dalam logika panggilan cron di cronjobcontroller'. Ini mencatat waktu mulai yang diharapkan seperti .metadata.Annotationobjek Job yang cronjobcontrollerdibuatnya saat CronJob dipanggil. Sekarang dapat diambil menggunakan klien API apa pun menggunakan permintaan normal GET Job.
Dengan T2 semuanya menjadi lebih rumit. Karena kita perlu mendapatkan nilai sedekat mungkin , T2 harus bertepatan dengan saat pertama kali container dengan aplikasi diluncurkan . Jika Anda menembak T2 di setiapketika penampung dimulai (termasuk memulai ulang), maka menunda peluncuran dalam hal ini akan mencakup waktu berjalannya aplikasi itu sendiri. Oleh karena itu, kami memutuskan untuk menetapkan
.metadata.Annotationobjek Job lain setiap kali kami menemukan bahwa wadah aplikasi untuk Job tertentu pertama kali menerima status Running. Jadi, pada dasarnya, kunci terdistribusi telah dibuat, dan permulaan wadah aplikasi di masa mendatang untuk Pekerjaan ini diabaikan (hanya saat permulaan pertama yang disimpan ).
hasil
Setelah meluncurkan fungsionalitas baru dan memperbaiki bug, kami menerima banyak umpan balik positif dari pengembang. Sekarang pengembang menggunakan platform Kubernetes CronJob kami:
- tidak lagi harus memikirkan alat pemantauan dan peringatan mereka sendiri;
- , CronJob' , .. alert' , ;
- CronJob' , CronJob' « »;
- (
app-container-duration.seconds).
Selain itu, teknisi pemeliharaan platform sekarang memiliki parameter baru ( penundaan mulai ) untuk mengukur pengalaman pengguna dan kinerja platform.
Akhirnya (dan mungkin kemenangan terbesar kami), dengan membuat CronJob (dan statusnya) lebih transparan dan dapat dilacak, kami telah sangat menyederhanakan proses debugging untuk pengembang dan insinyur platform. Mereka sekarang dapat men-debug bersama menggunakan data yang sama, sehingga sering terjadi bahwa pengembang menemukan masalahnya sendiri dan menyelesaikannya menggunakan alat yang disediakan oleh platform.
Kesimpulan
Mengatur tugas terdistribusi dan terjadwal tidaklah mudah. CronJob Kubernetes hanyalah salah satu cara untuk mengaturnya. Meskipun jauh dari ideal, CronJob cukup mampu bekerja dalam proyek global, jika, tentu saja, Anda siap menginvestasikan waktu dan upaya untuk memperbaikinya: meningkatkan kemampuan observasi, memahami penyebab dan spesifikasi kegagalan, dan melengkapi dengan alat yang membuatnya lebih mudah digunakan.
Catatan: ada Proposal Peningkatan Kubernetes (KEP) terbuka untuk memperbaiki kekurangan CronJob dan menerjemahkan versi yang diperbarui ke GA.
Terima kasih kepada Rithu John , Scott Lau, Scarlett Perry , Julien Silland, dan Tom Wanielista atas bantuan mereka dalam meninjau rangkaian artikel ini.
PS dari penerjemah
Baca juga di blog kami: