
Dengan transisi ke isolasi mandiri pada bulan Maret tahun ini, kami, seperti banyak perusahaan, telah memindahkan semua acara grosir kami ke online. Nah, Anda ingat gambar indah tentang webinar dengan monyet. Selama enam bulan terakhir, hanya pada topik pusat data, yang menjadi tanggung jawab tim saya, kami telah mengumpulkan sekitar 25 rekaman webinar berdurasi 2 jam, total 50 jam video. Masalah yang meningkat dalam pertumbuhan penuh adalah bagaimana memahami di video mana untuk mencari jawaban atas pertanyaan tertentu. Katalog, tag, deskripsi singkat bagus, kami akhirnya menemukan bahwa ada 4 video berdurasi dua jam tentang topik tersebut, lalu apa? Tonton di rewind? Apakah mungkin dengan cara yang berbeda? Dan jika Anda bertindak dengan cara yang modis dan mencoba mengacaukan AI?
Spoiler untuk yang tidak sabar : Saya tidak dapat menemukan sistem keajaiban yang lengkap atau merakitnya di atas lutut saya, dan kemudian tidak ada gunanya dalam artikel ini. Tetapi sebagai hasil dari beberapa hari (atau lebih tepatnya malam hari), penelitian, saya mendapat MVP yang berfungsi, yang ingin saya ceritakan kepada Anda. Tujuan artikel ini adalah untuk melihat tingkat minat terhadap masalah tersebut, mendapatkan saran dari orang yang berpengetahuan, dan mungkin menemukan orang lain yang memiliki masalah yang sama.
Apa yang ingin saya lakukan
Sekilas, semuanya tampak sederhana - Anda merekam video, menjalankannya melalui jaringan neural, mendapatkan teks, lalu mencari bagian dalam teks yang menjelaskan topik yang menarik. Akan lebih mudah untuk mencari semua video di katalog sekaligus. Faktanya, telah diciptakan untuk mengunggah transkrip teks bersama dengan video untuk waktu yang lama, Youtube dan sebagian besar platform pendidikan dapat melakukan ini, meskipun jelas bahwa orang-orang di sana mengedit teks-teks ini. Anda dapat dengan cepat memindai teks dengan mata Anda dan memahami jika ada jawaban untuk pertanyaan yang diinginkan. Mungkin dari fungsionalitas yang nyaman, tidak ada salahnya untuk bisa menyodok di tempat yang menarik di teks dan mendengarkan apa yang dosen katakan dan tunjukkan di sana, ini juga tidak sulit jika ada markup kata dalam waktu, di mana kata-kata itu ada di teks. Nah, saya bermimpi tentang kemungkinan arah pengembangan, mari kita bicara di bagian akhir,dan sekarang mari kita coba untuk mengimplementasikan rantai seefisien mungkin
file video -> fragmen teks -> pencarian teks fuzzy .
Awalnya saya pikir, karena semuanya sangat sederhana, dan kasus ini telah dibahas di semua konferensi AI selama 4 tahun, sistem seperti itu harus ada yang sudah jadi. Beberapa jam mencari dan membaca artikel menunjukkan bahwa bukan itu masalahnya. Video terutama digunakan untuk mencari wajah, mobil dan objek visual lainnya (topeng / helm), dan audio - lagu, trek, serta nada / intonasi speaker, sebagai bagian dari solusi untuk call center. Kami hanya berhasil menemukan penyebutan sistem Deepgram ini . Tapi sayangnya, dia tidak memiliki dukungan untuk bahasa Rusia. Selain itu, Microsoft memiliki fungsi yang sangat mirip di Streams , tetapi saya tidak menemukan dukungan untuk bahasa Rusia, ternyata, itu juga tidak ada.
Oke, mari kita temukan kembali. Saya bukan pemrogram profesional (dan, omong-omong, saya akan dengan senang hati menerima kritik yang membangun pada kode), tetapi dari waktu ke waktu saya menulis sesuatu "untuk diri saya sendiri". Jaringan saraf yang dapat mengubah ucapan menjadi teks disebut (kejutan-kejutan), ucapan-ke-teks . Jika Anda dapat menemukan layanan ucapan-ke-teks publik, Anda dapat menggunakannya untuk "mendigitalkan" ucapan di semua webinar, dan kemudian melakukan pencarian tidak jelas dalam teks - tugas yang lebih mudah. Saya akui bahwa pada awalnya saya tidak berpikir untuk "naik ke awan", saya ingin mengumpulkan semuanya secara lokal, tetapi setelah membaca artikel ini di Habré, saya memutuskan bahwa pengenalan ucapan benar-benar lebih baik dilakukan di awan.
Mencari layanan cloud untuk ucapan-ke-teks
Pencarian layanan yang mampu melakukan speech-to-text menunjukkan bahwa ada banyak sistem seperti itu, termasuk yang dikembangkan di Rusia, ada juga penyedia cloud global seperti Google , Amazon , MS Azure di antaranya . Deskripsi dari beberapa layanan, termasuk yang berbahasa Rusia , ada di sini . Secara umum, 20 baris pertama dalam hasil mesin pencari akan unik. Namun ada halangan lain - Saya ingin meluncurkan sistem ini ke produksi di masa mendatang, ini adalah biaya, dan saya bekerja untuk Cisco, yang secara global memiliki kontrak dengan cloud terkemuka. Jadi dari keseluruhan daftar, saya memutuskan untuk mempertimbangkannya saja untuk saat ini.
Jadi daftar saya telah dikurangi menjadi Google , Amazon , Azure ,IBM Watson (tautan ke judul sama seperti pada tabel di bawah). Semua layanan memiliki API yang dapat digunakan untuk menggunakannya. Setelah menganalisis kemungkinan lainnya, saya menyusun tabel kecil:

IBM Watson meninggalkan perlombaan pada tahap ini, karena semua rekaman yang saya miliki dalam bahasa Rusia, diputuskan untuk menguji penyedia lainnya dalam kutipan singkat dari webinar. Saya menyiapkan akun di AWS dan Azure. Ke depan, saya akan mengatakan bahwa Microsoft ternyata adalah orang yang sulit untuk dipecahkan dalam hal menyiapkan akun. Saya bekerja dari jaringan perusahaan yang "mendarat" di Internet di suatu tempat di Amsterdam, selama proses pendaftaran saya ditanya dua kali apakah saya yakin alamat saya adalah Rusia, setelah itu sistem menampilkan pesan bahwa akun diblokir secara administratif "menunggu klarifikasi" ... Setelah 5 hari, saat saya menulis artikel ini, situasinya tidak berubah, jadi saya belum bisa menguji Azure, yang sangat disayangkan! Saya mengerti - keamanan, tetapi ini belum memungkinkan saya untuk mencoba layanan. Saya akan mencoba melakukan ini nanti, ketika situasinya teratasi.
Secara terpisah, saya ingin menguji fungsi ini di Yandex.Cloud, pengenalan ucapan Rusia mereka, secara teori, harus menjadi yang terbaik. Namun sayangnya, pada halaman akses uji coba layanan tersebut hanya terdapat kemampuan untuk "mengucapkan" teks, tidak disediakan download file. Jadi, kami akan menunda bersama Azure di tempat kedua.
Nah, ada Google dan Amazon, yuk segera uji! Sebelum menulis kode apa pun, Anda dapat memeriksa dan membandingkan semuanya dengan tangan, kedua penyedia, selain API, memiliki antarmuka administratif. Untuk pengujian, saya pertama-tama menyiapkan fragmen 10 menit yang bersifat umum, jika memungkinkan, dengan minimal terminologi khusus. Tetapi ternyata Google mendukung fragmen hingga 1 menit dalam mode uji coba, jadi saya menggunakan fragmen sepanjang 57 detik ini untuk membandingkan layanan .
Berdasarkan hasil pekerjaan, kedua layanan mengeluarkan teks yang dikenali, Anda dapat membandingkan hasil pekerjaan mereka dalam interval satu menit.
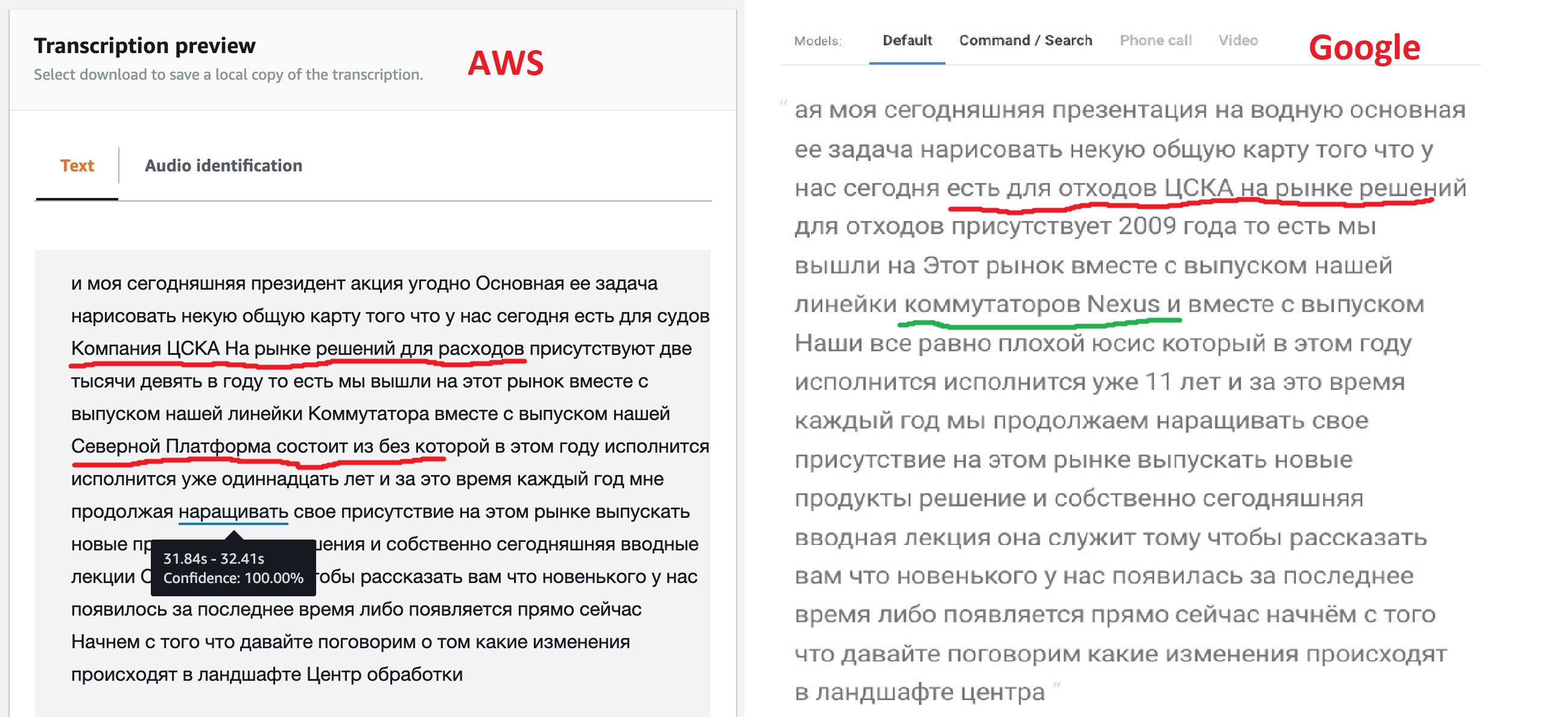
Hasilnya, sejujurnya, tidak seperti yang diharapkan, tetapi bukan tanpa alasan bahwa model memberikan opsi berbeda untuk penyesuaian mereka. Seperti yang dapat kita lihat, mesin Google "di luar kotak" mengenali sebagian besar teks dengan lebih jelas, ia juga berhasil melihat nama-nama beberapa produk, meskipun tidak semua. Ini menunjukkan bahwa model mereka memungkinkan teks multibahasa. Amazon (kemudian dikonfirmasi) tidak memiliki kesempatan seperti itu - mereka berkata dalam bahasa Rusia, yang berarti kami akan bernyanyi: "Kin babe lom", titik!
Tetapi kemampuan untuk mendapatkan tag JSON yang disediakan Amazon sepertinya sangat menarik bagi saya. Bagaimanapun, ini akan memungkinkan di masa depan untuk menerapkan transisi langsung ke bagian file tempat fragmen yang diinginkan ditemukan. Mungkin Google juga memiliki fungsi seperti itu, karena semua jaringan saraf pengenal ucapan bekerja dengan cara ini, tetapi pencarian sepintas dalam dokumentasi tidak berhasil menemukan fitur ini.

Melihat JSON ini, Anda dapat melihat bahwa itu terdiri dari tiga bagian: teks terjemahan (transkrip), larik kata (item), dan sekumpulan segmen (segmen). Untuk larik kata dan segmen untuk setiap elemen, waktu mulai dan berakhirnya ditunjukkan, serta keyakinan (keyakinan) jaringan neural bahwa ia mengenalinya dengan benar.
Mengajar jaringan saraf untuk memahami pusat data
Jadi, di akhir tahap ini, saya memutuskan untuk memilih Amazon Transcribe untuk eksperimen lebih lanjut dan mencoba menyiapkan model pembelajaran. Dan jika Anda tidak dapat memperoleh pengakuan yang stabil, berurusan dengan Google. Tes lebih lanjut dilakukan pada fragmen 10 menit.
AWS Transcribe memiliki dua opsi untuk menyesuaikan apa yang dikenali oleh jaringan saraf, dan beberapa fitur lainnya untuk teks pasca-pemrosesan:
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
Jadi, saya memutuskan untuk membuat kata-kata saya sendiri untuk teks tersebut. Jelas, itu akan mencakup kata-kata seperti "jaringan, server, profil, pusat data, perangkat, pengontrol, infrastruktur." Setelah 2-3 tes, kosakata saya bertambah menjadi 60 kata. Kamus ini harus dibuat dalam file teks biasa, satu kata per baris, semuanya menggunakan huruf kapital. Ada juga opsi yang lebih kompleks ( dijelaskan di sini ) dengan kemampuan untuk menentukan bagaimana kata itu diucapkan, tetapi pada tahap awal saya memutuskan untuk melakukannya dengan daftar sederhana.
Sebelum menggunakan kamus, Anda perlu membuatnya. Pada tab Custom vocabulary di Amazon Transcribe, klik Create Vocabulary , muat teks file kami, tentukan bahasa Rusia, jawab pertanyaan lainnya, dan proses pembuatan kamus dimulai. Begitu dia keluarPemrosesan menjadi Siap - kamus dapat digunakan.
Pertanyaannya tetap - bagaimana mengenali istilah "bahasa Inggris"? Izinkan saya mengingatkan Anda bahwa kamus hanya mendukung satu bahasa. Awalnya saya berpikir untuk membuat kamus terpisah dengan istilah bahasa Inggris, dan menjalankan teks yang sama di dalamnya. Ketika istilah seperti Cisco , VLAN , UCS terdeteksidll. c tingkat probabilitas 100% - ambillah untuk fragmen waktu tertentu. Tetapi saya akan langsung mengatakan bahwa itu tidak berhasil, penganalisis bahasa Inggris tidak mengenali lebih dari setengah istilah dalam teks. Setelah berpikir, saya memutuskan bahwa ini logis, karena kami mengucapkan semua istilah ini dengan "aksen Rusia", bahkan orang Anglo-Amerika tidak memahami kami untuk pertama kalinya. Hal ini mendorong ide untuk menambahkan istilah-istilah ini ke dalam kamus Rusia sesuai dengan prinsip "seperti yang didengar, demikianlah tertulis." Cisco , usies , eisiai , vilan , viikslan - bagaimanapun juga, sejujurnya, kami mengatakannya saat berkomunikasi satu sama lain. Ini meningkatkan kamus beberapa lusin kata, tetapi melihat ke depan, itu meningkatkan kualitas pengenalan dengan urutan besarnya!
Seperti kata pepatah, "pikiran yang baik datang setelah" , kamus pertama telah dibuat, jadi saya memutuskan untuk membuat yang lain, menambahkan semua singkatannya, dan membandingkan apa yang terjadi.
Memulai pengenalan dengan kamus sama sederhananya, di layanan Transkripsikan pada tab Pekerjaan Transkripsi , pilih Buat pekerjaan , tentukan bahasa Rusia, dan jangan lupa untuk menentukan kamus yang kita butuhkan. Tindakan berguna lainnya - Anda dapat meminta jaringan saraf untuk memberi kami beberapa hasil pencarian alternatif, hasil Alternatif - Ya item , saya menetapkan 3 opsi alternatif. Nanti, ketika saya melakukan pencarian teks fuzzy, ini akan berguna.
Penyiaran sepotong teks 10 menit membutuhkan waktu 4-5 menit, agar tidak membuang waktu, saya memutuskan untuk menulis alat kecil yang akan memfasilitasi proses membandingkan hasil. Saya akan menampilkan teks terakhir dari file JSON di browser, secara bersamaan menyoroti "keandalan" dari deteksi kata-kata individu oleh jaringan saraf (parameter keyakinan yang sama ). Saya memiliki tiga opsi untuk teks yang dihasilkan - terjemahan default, kamus tanpa istilah, dan kamus dengan istilah. Biarkan ketiga teks ditampilkan secara bersamaan dalam tiga kolom. Saya menyoroti kata-kata dengan keandalan di atas 95% dengan warna hijau, dari 95% menjadi 70% dengan warna kuning, di bawah 70% dengan warna merah. Kode yang dikompilasi dengan tergesa-gesa dari halaman HTML yang dihasilkan ada di bawah, file JSON harus berada di direktori yang sama dengan file tersebut. Nama file ditentukan dalam variabel FILENAME1, dll.
Kode halaman HTML untuk melihat hasil
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
Saya mengunduh file asrOutput.json untuk ketiga tugas, mengganti namanya seperti yang tertulis dalam skrip HTML, dan inilah yang terjadi.

Terlihat jelas bahwa penambahan istilah bahasa Rusia memungkinkan jaringan saraf mengenali istilah tertentu dengan lebih akurat - " profil layanan ", dll. Dan penambahan transkripsi Rusia pada langkah kedua mengubah CSKA menjadi cisco . Teksnya masih agak "kotor", tetapi untuk tugas pencarian konteks saya seharusnya sudah sesuai. Saat webinar baru ditambahkan dan dibaca, kosakata akan berkembang secara bertahap, ini adalah proses mempertahankan sistem yang tidak boleh dilupakan.
Pencarian fuzzy dalam teks yang dikenali
Mungkin ada selusin pendekatan untuk memecahkan masalah pencarian fuzzy, sebagian besar didasarkan pada sekumpulan kecil algoritma matematika, seperti, misalnya, jarak Levenshtein. artikel bagus tentang ini , satu lagi dan satu lagi . Tapi saya ingin menemukan sesuatu yang siap, seperti diluncurkan dan berfungsi.
Dari solusi siap pakai untuk pencarian dokumen lokal, setelah sedikit penelitian, saya menemukan proyek SPHINX yang relatif lama , dan kemungkinan pencarian teks lengkap, tampaknya, ada di PostgreSQL, ada tertulis tentangnya DI SINI . Tetapi sebagian besar materi, termasuk dalam bahasa Rusia, ditemukan tentang Elasticsearch . Setelah membaca panduan start-up dan pengaturan yang baik sepertiPosting ini atau pelajaran ini , ini yang lain , serta dokumentasi dan panduan API untuk Python , saya memutuskan untuk menggunakannya.
Untuk semua eksperimen lokal saya telah menggunakan Docker untuk waktu yang lama , dan saya sangat merekomendasikan semua orang yang karena alasan tertentu belum memahaminya, untuk melakukan ini. Sebenarnya, saya mencoba untuk tidak menjalankan apa pun selain lingkungan pengembangan, browser, dan "pemirsa" di sistem operasi lokal. Terlepas dari tidak adanya masalah kompatibilitas, dll. ini memungkinkan Anda dengan cepat mencoba produk baru dan melihat apakah itu berfungsi dengan baik.
Kami mengunduh kontainer dengan Elasticsearch dan menjalankannya dengan dua perintah:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
Setelah memulai penampung,
http://localhost:9200antarmuka elastis muncul di alamat , dapat diakses menggunakan browser atau REST API dari alat POSTMAN. Tapi saya menemukan plugin Chrome yang berguna .
Seperti inilah tampilan jendela plugin dengan contoh tentang anak kucing lucu yang dijelaskan di salah satu panduan di atas .
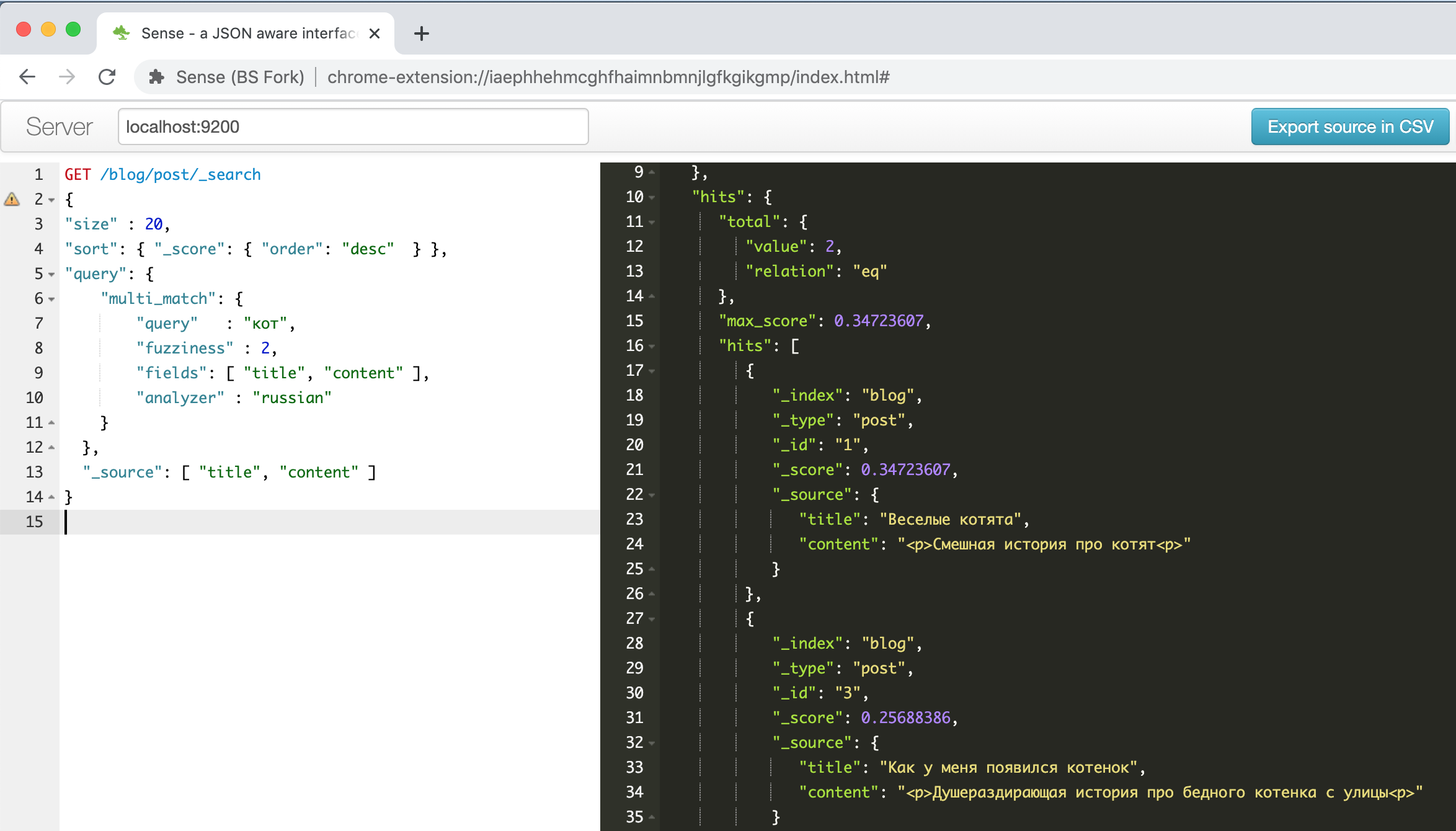
Di sebelah kiri adalah kueri - di sebelah kanan adalah jawaban, pelengkapan otomatis, penyorotan sintaks, pemformatan otomatis - apa lagi yang diperlukan untuk menjadi produktif! Selain itu, plugin ini dapat mengenali format baris perintah CURL dalam teks yang ditempelkan dari papan klip dan memformatnya dengan benar, misalnya, coba tempel baris
" curl -X GET $ ES_URL " dan lihat apa yang terjadi. Suatu hal yang berguna, secara umum.
Apa dan bagaimana saya akan menyimpan dan mencari?Elasticsearch mengambil semua dokumen JSON dan menyimpannya dalam struktur yang disebut indeks. Ada banyak indeks berbeda yang Anda suka, tetapi satu indeks dapat berisi data dan dokumen yang homogen, dengan struktur bidang yang serupa dan pendekatan penelusuran yang sama.
Untuk menyelidiki kemungkinan pencarian fuzzy, saya memutuskan untuk mendownload dan mencari bagian frase (segmen) dari file transkripsi yang diperoleh pada langkah sebelumnya. Di bagian segmen file JSON, data disimpan dalam format berikut:
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
Saya ingin meningkatkan kemungkinan pencarian berhasil, jadi saya akan mengunggah semua opsi alternatif ke database untuk pencarian, dan kemudian memilih satu dengan keyakinan total yang lebih tinggi dari fragmen yang ditemukan.
Untuk memformat ulang dan memuat dokumen JSON ke Elasticsearch, saya menggunakan skrip Python kecil, logika skripnya adalah sebagai berikut:
- Pertama, kita melihat semua elemen bagian segmen dan semua opsi transkripsi alternatif
- Untuk setiap opsi transkripsi, kami mempertimbangkan kepercayaan pengenalan totalnya, saya hanya mengambil rata-rata aritmatika untuk setiap kata, meskipun, mungkin, di masa mendatang ini perlu didekati dengan lebih hati-hati
- Untuk setiap opsi transkripsi alternatif, muat catatan formulir ke Elasticsearch
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
Skrip Python yang memuat catatan dari file JSON ke Elasticsearch
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
Jika Anda tidak memiliki Python, jangan berkecil hati, Docker akan membantu kami lagi. Saya biasanya menggunakan container dengan notebook Jupyter - Anda dapat menghubungkannya dengan browser biasa dan melakukan apa pun yang perlu Anda lakukan, satu-satunya hal yang perlu Anda pikirkan untuk menyimpan hasil, karena semua informasi akan hilang saat container dihancurkan. Jika Anda belum pernah menggunakan alat ini sebelumnya, berikut adalah artikel yang bagus untuk pemula , ngomong-ngomong, Anda dapat melewati bagian tentang instalasi dengan aman. Kami
memulai container dengan notebook Python dengan perintah:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
Dan kami menghubungkannya dengan browser apa pun di alamat yang kami lihat di layar setelah peluncuran skrip yang berhasil, ini
http://127.0.0.1:8888dengan kunci keamanan yang ditentukan.
Kami membuat notebook baru, di sel pertama kami menulis:
!pip install elasticsearch
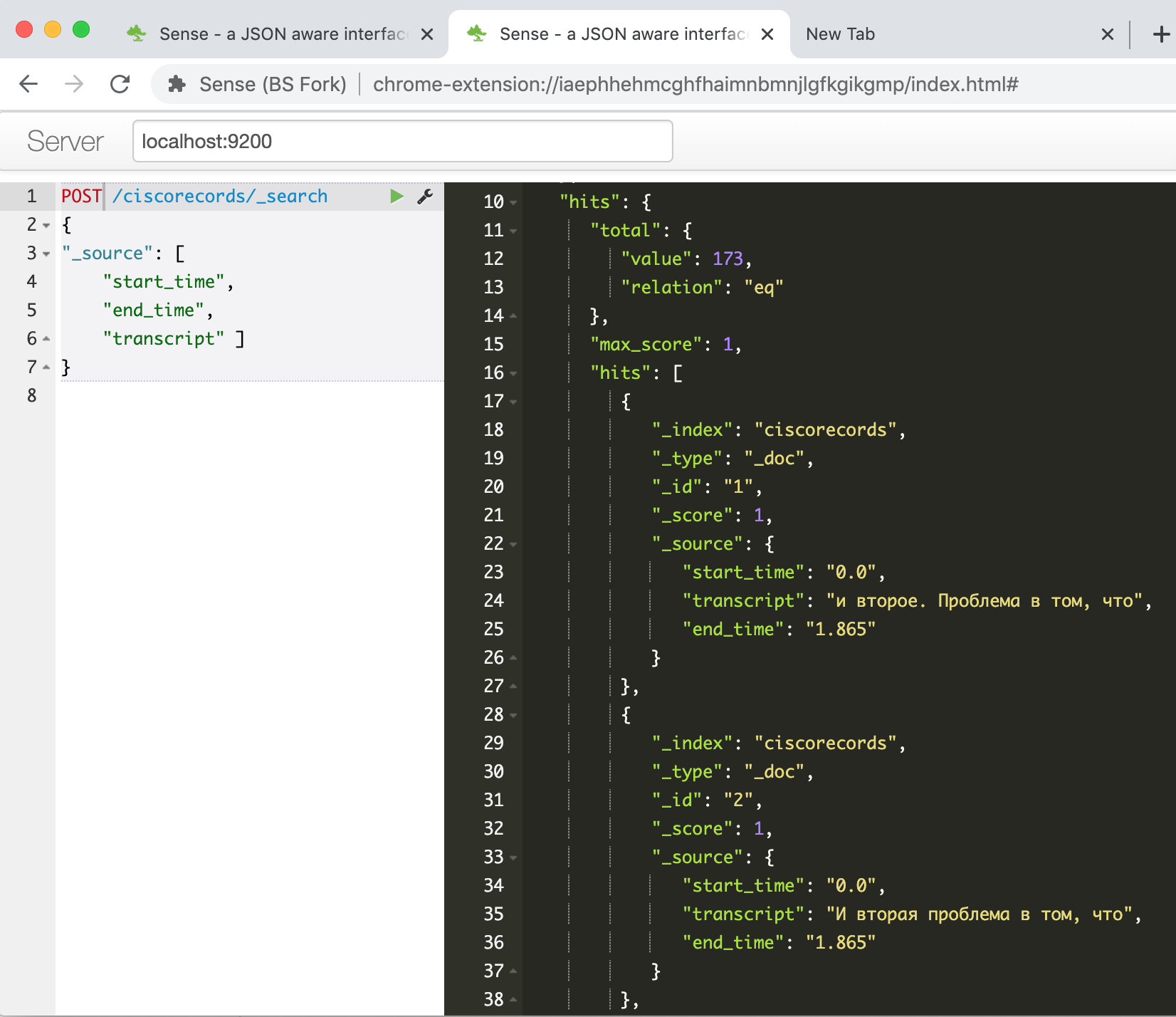
Jalankan, tunggu hingga paket untuk bekerja dengan ES melalui API diinstal, salin skrip kami ke sel kedua dan jalankan. Setelah berhasil, jika semuanya berhasil, kita dapat memeriksa di konsol Elasticsearch apakah data kita telah berhasil dimuat. Kami memasukkan perintah
GET /ciscorecords/_searchdan melihat rekaman yang kami muat di jendela respons, total 173 buah, seperti yang dikatakan bidang hits.total.value kepada kami .
Sekaranglah waktunya untuk mencoba pencarian fuzzy - itu semua tentang itu. Misalnya, untuk mencari frasa "inti dari jaringan pusat data", Anda perlu memberikan perintah berikut:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
Kami mendapatkan sebanyak 47 hasil!

Tidak heran, karena kebanyakan dari mereka adalah variasi yang berbeda dari fragmen yang sama. Mari tulis skrip lain untuk memilih dari setiap segmen satu catatan dengan nilai kepercayaan tertinggi.
Skrip Python untuk menanyakan database Elasticsearch
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
Contoh keluaran:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
Kami melihat bahwa hasilnya menjadi jauh lebih kecil, dan sekarang kami dapat melihatnya dan memilih salah satu yang paling menarik bagi kami.
Selain itu, karena kita memiliki waktu mulai dan akhir dari fragmen video, kita dapat membuat laman dengan pemutar video dan secara terprogram "memundurkan" ke bagian yang diinginkan.
Tetapi saya akan meletakkan tugas ini di artikel terpisah jika ada minat untuk publikasi lebih lanjut tentang topik ini.
Alih-alih kesimpulan
Jadi, dalam kerangka artikel ini, saya menunjukkan bagaimana saya memecahkan masalah membangun sistem pencarian teks menggunakan alat video dengan rekaman webinar tentang topik teknis. Hasilnya adalah apa yang biasa disebut MVP, yaitu algoritma kerja minimum yang memungkinkan Anda mendapatkan hasil dan membuktikan bahwa hasilnya, pada prinsipnya, dapat dicapai dengan teknologi yang ada.
Masih panjang jalan menuju produk akhir, dari ide-ide yang bisa diimplementasikan dalam waktu dekat:
- Sekrup pada pemutar video sehingga Anda dapat mendengarkan, melihat fragmen yang ditemukan
- Pikirkan tentang kemungkinan pengeditan teks, sementara Anda dapat meninggalkan jangkar ke teks kata-kata yang dikenali oleh 100%, edit hanya fragmen di mana kualitas pengenalan "melorot"
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
Jika Anda memiliki pertanyaan / komentar, saya akan dengan senang hati menjawabnya, dan saya juga akan senang mendengar saran untuk meningkatkan atau menyederhanakan proses secara keseluruhan. Ini adalah artikel teknis saya yang pertama untuk Habr, semoga bermanfaat dan menarik.
Semoga berhasil untuk semua orang dalam pencarian kreatif Anda, dan semoga Force menyertai Anda!