
Apa itu metrik pendek dan panjang?
Model pemeringkatan mencoba memperkirakan kemungkinan bahwa pengguna akan berinteraksi dengan berita (posting): dia akan memperhatikannya, memberi tanda "Suka", menulis komentar. Model kemudian mendistribusikan catatan dalam urutan kemungkinan ini menurun. Karenanya, dengan meningkatkan peringkat, kita bisa mendapatkan peningkatan CTR (rasio klik-tayang) dari tindakan pengguna: suka, komentar, dan lainnya. Metrik ini sangat sensitif terhadap perubahan dalam model peringkat. Saya akan menyebutnya pendek .
Tetapi ada jenis metrik lain. Diyakini, misalnya, bahwa waktu yang dihabiskan dalam aplikasi, atau jumlah sesi pengguna, mencerminkan sikapnya yang jauh lebih baik terhadap layanan. Kami akan menyebut metrik seperti itu panjang .
Mengoptimalkan metrik panjang secara langsung melalui algoritme peringkat bukanlah tugas yang sepele. Dengan metrik pendek, ini jauh lebih mudah: RKT suka, misalnya, secara langsung berkaitan dengan seberapa baik kami memperkirakan kemungkinannya. Namun jika kita mengetahui hubungan kausal (atau kausal) antara metrik pendek dan panjang, maka kita dapat fokus untuk mengoptimalkan hanya metrik pendek yang dapat diprediksi memengaruhi metrik panjang. Saya mencoba mengekstrak hubungan kausal semacam itu - dan menulis tentangnya dalam pekerjaan saya, yang saya selesaikan sebagai diploma di ITMO's Bachelor of Science (CT). Kami melakukan penelitian di laboratorium Machine Learning ITMO bersama dengan VKontakte.
Tautan ke kode, set data, dan kotak pasir
Anda dapat menemukan semua kodenya di sini: AnverK .
Untuk menganalisis hubungan antara metrik, kami menggunakan kumpulan data yang mencakup hasil lebih dari 6.000 pengujian A / B nyata yang dilakukan oleh tim VK pada waktu yang berbeda. Dataset juga tersedia di repositori .
Di sandbox, Anda dapat melihat cara menggunakan wrapper yang diusulkan: pada data sintetis .
Dan di sini - cara menerapkan algoritme ke kumpulan data: pada kumpulan data yang diusulkan .
Berurusan dengan korelasi palsu
Tampaknya untuk menyelesaikan masalah kita, cukup dengan menghitung korelasi antara metrik. Tetapi ini tidak sepenuhnya benar: korelasi tidak selalu menjadi sebab akibat. Katakanlah kita hanya mengukur empat metrik dan hubungan sebab akibatnya terlihat seperti ini:

Tanpa kehilangan keumuman, anggap saja ada pengaruh positif ke arah panah: semakin banyak suka, semakin banyak SPU. Dalam hal ini, komentar pada foto tersebut dapat memberikan efek positif pada SPU. Dan putuskan bahwa jika Anda "meningkatkan" metrik ini, SPU akan meningkat. Fenomena ini disebut korelasi palsu.: koefisien korelasi cukup tinggi, tetapi tidak ada hubungan sebab akibat. Korelasi palsu tidak terbatas pada dua efek dari penyebab yang sama. Dari grafik yang sama, seseorang dapat membuat kesimpulan yang salah bahwa suka berpengaruh positif pada jumlah bukaan foto.
Bahkan dengan contoh sederhana seperti itu, menjadi jelas bahwa analisis korelasi sederhana akan menghasilkan banyak kesimpulan yang salah. Inferensi kausal (metode inferensi hubungan) memungkinkan untuk memulihkan hubungan kausal dari data. Untuk menerapkannya dalam tugas, kami telah memilih algoritme inferensi kausal yang paling sesuai, mengimplementasikan antarmuka python untuknya, dan juga menambahkan modifikasi algoritme yang dikenal yang bekerja lebih baik dalam kondisi kami.
Algoritme klasik untuk tautan inferensi
Kami telah mempertimbangkan beberapa metode inferensi kausal: PC (Peter dan Clark), FCI (Fast Causal Inference) dan FCI + (mirip dengan FCI dari sudut pandang teoretis, tetapi jauh lebih cepat). Anda dapat membacanya secara rinci di sumber-sumber ini:
- Kausalitas (J. Pearl, 2009),
- Penyebab, Prediksi dan Pencarian (P. Spirtes et al., 2000),
- Model Penyebab Jarang Belajar tidak NP-hard (T. Claassen et al., 2013).
Tetapi penting untuk dipahami bahwa metode pertama (PC) mengasumsikan bahwa kita mengamati semua kuantitas yang memengaruhi dua atau lebih metrik - hipotesis ini disebut Kecukupan Kausal. Dua algoritme lainnya memperhitungkan bahwa mungkin ada faktor yang tidak dapat diamati yang memengaruhi metrik yang dipantau. Artinya, pada kasus kedua, representasi kausal dianggap lebih natural dan memungkinkan adanya faktor-faktor yang tidak dapat diamati : Semua implementasi dari algoritma ini disajikan dipcalglibrary. Ini indah dan fleksibel, tetapi dengan satu "kekurangan" - ditulis dalam R (saat mengembangkan fungsi komputasi yang paling berat, paket RCPP digunakan). Oleh karena itu, untuk metode yang tercantum di atas, saya menulis pembungkus di kelas CausalGraphBuilder, menambahkan contoh penggunaannya. Saya akan menjelaskan kontrak fungsi inferensi tautan, yaitu antarmuka dan hasil yang dapat diperoleh pada output. Anda dapat lulus fungsi pengujian untuk independensi bersyarat. Ini adalah tes seperti ini yang kembali

bawah hipotesis nol bahwa nilai-nilai dan bergantung secara kondisional untuk kumpulan kuantitas yang diketahui . Defaultnya adalahuji korelasi parsial. Saya memilih fungsi dengan tes ini karena ini adalah default di pcalg dan diimplementasikan di RCPP - ini membuatnya cepat dalam praktiknya. Anda juga dapat mentransfer , dimulai dari mana simpul akan dianggap bergantung. Untuk algoritme PC dan FCI, Anda juga dapat menyetel jumlah inti CPU, jika Anda tidak perlu menulis log operasi pustaka. Tidak ada opsi seperti itu untuk FCI +, tetapi saya merekomendasikan menggunakan algoritma khusus ini - ini menang dalam kecepatan. Peringatan lain: FCI + saat ini tidak mendukung algoritme orientasi tepi yang diusulkan - intinya ada dalam batasan pustaka pcalg. Berdasarkan hasil kerja semua algoritma, dibuat PAG (parsial grafik leluhur) dalam bentuk daftar edge. Dengan algoritma PC, itu harus ditafsirkan sebagai grafik kausal dalam pengertian klasik (atau jaringan Bayesian): berorientasi tepi dari
dalam berarti pengaruh pada . Jika tepinya non-directional atau dua arah, maka kita tidak dapat mengorientasikannya secara unik, yang artinya:
- atau data yang tersedia tidak cukup untuk menentukan arah,
- atau tidak mungkin, karena grafik sebab akibat yang sebenarnya, dengan hanya menggunakan data yang dapat diamati, hanya dapat dibuat hingga kelas ekivalen.
Algoritme FCI juga akan menghasilkan PAG, tetapi jenis edge baru akan muncul di dalamnya - dengan "o" di bagian akhir. Ini berarti panah mungkin ada atau mungkin tidak ada. Dalam hal ini, perbedaan terpenting antara algoritma FCI dan PC adalah bahwa tepi dua arah (dengan dua panah) memperjelas bahwa simpul yang dihubungkannya merupakan konsekuensi dari beberapa simpul yang tidak dapat diamati. Karenanya, tepi ganda dalam algoritme PC sekarang terlihat seperti tepi dengan dua ujung "o". Ilustrasi untuk kasus seperti itu ada di kotak pasir dengan contoh sintetis.
Memodifikasi algoritma orientasi tepi
Metode klasik memiliki satu kekurangan yang signifikan. Mereka mengakui bahwa mungkin ada faktor-faktor yang tidak diketahui, tetapi pada saat yang sama mereka mengandalkan asumsi lain yang terlalu serius. Esensinya adalah bahwa fungsi pengujian untuk independensi bersyarat harus sempurna. Jika tidak, algoritme tidak bertanggung jawab untuk dirinya sendiri dan tidak menjamin kebenaran atau kelengkapan grafik (fakta bahwa lebih banyak tepi tidak dapat diorientasikan tanpa melanggar kebenaran). Apakah Anda tahu banyak tes independensi bersyarat sampel terbatas yang ideal? Saya tidak.
Terlepas dari kekurangan ini, kerangka grafik dibuat dengan cukup meyakinkan, tetapi berorientasi terlalu agresif. Jadi saya menyarankan modifikasi pada algoritma orientasi tepi. Bonus: ini memungkinkan Anda untuk secara implisit menyesuaikan jumlah tepi berorientasi. Untuk menjelaskan esensinya dengan jelas, perlu untuk membicarakan secara rinci di sini tentang algoritme untuk penurunan hubungan sebab akibat. Oleh karena itu, saya akan melampirkan teori algoritma ini dan modifikasi yang diusulkan secara terpisah - tautan ke materi akan ada di akhir posting.
Bandingkan Model - 1: Estimasi Kemungkinan Grafik
Anehnya, salah satu kesulitan serius dalam mendapatkan hubungan sebab akibat adalah perbandingan dan evaluasi model. Bagaimana hal itu terjadi? Intinya adalah bahwa biasanya representasi kausal sebenarnya dari data nyata tidak diketahui. Selain itu, kita tidak dapat mengetahuinya dalam istilah distribusi dengan begitu akurat untuk menghasilkan data nyata darinya. Artinya, kebenaran dasar tidak diketahui untuk sebagian besar kumpulan data. Oleh karena itu, muncul dilema: gunakan data sintetik (semi-) dengan kebenaran dasar yang diketahui atau coba lakukan tanpa kebenaran dasar, tetapi uji pada data nyata. Dalam pekerjaan saya, saya mencoba menerapkan dua pendekatan untuk pengujian.
Yang pertama adalah perkiraan kemungkinan grafik:

Di sini - himpunan orang tua dari puncak , - informasi gabungan jumlah dan , dan adalah entropi kuantitas . Faktanya, suku kedua tidak bergantung pada struktur grafik, oleh karena itu, sebagai aturan, hanya yang pertama yang dipertimbangkan. Tetapi Anda dapat melihat bahwa kemungkinan tidak berkurang dengan penambahan tepi baru - ini harus diperhitungkan saat membandingkan. Penting untuk dipahami bahwa penilaian semacam itu hanya berfungsi untuk membandingkan jaringan Bayesian (keluaran algoritme PC), karena dalam PAG nyata (keluaran algoritme FCI, FCI +), tepi ganda memiliki semantik yang sama sekali berbeda. Oleh karena itu, saya membandingkan orientasi tepi dengan algoritme saya dan PC klasik: Orientasi tepi yang dimodifikasi memungkinkan peningkatan kemungkinan yang signifikan dibandingkan dengan algoritme klasik. Tapi sekarang penting untuk membandingkan jumlah edge:
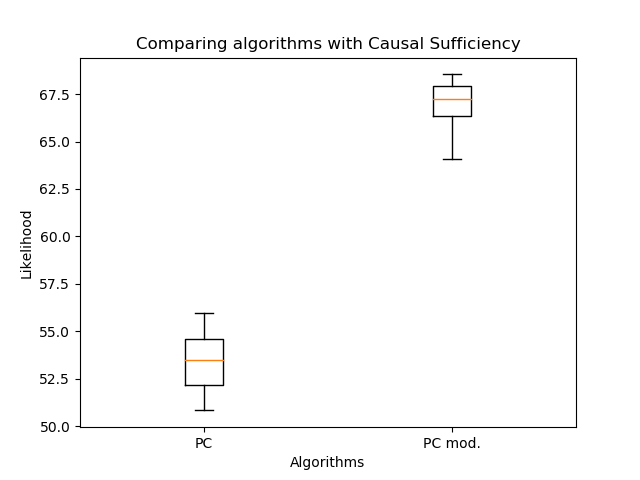
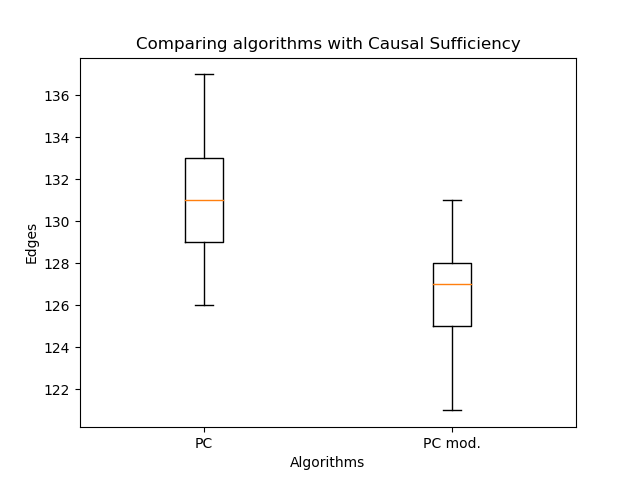
Jumlah mereka bahkan lebih sedikit - ini yang diharapkan. Jadi, meskipun dengan tepi yang lebih sedikit, dimungkinkan untuk memulihkan struktur grafik yang lebih masuk akal! Di sini Anda mungkin berpendapat bahwa kemungkinan tidak berkurang dengan jumlah tepi. Intinya adalah bahwa grafik yang dihasilkan pada kasus umum bukanlah subgraf dari grafik yang diperoleh dengan algoritma PC klasik. Tepi ganda mungkin muncul sebagai pengganti satu sisi, dan satu sisi dapat berubah arah. Jadi tidak ada kerajinan tangan!
Membandingkan Model - 2: Menggunakan Pendekatan Klasifikasi
Mari beralih ke cara perbandingan yang kedua. Kami akan menggunakan algoritma PC untuk membuat grafik kausal dan memilih grafik asiklik acak darinya. Setelah itu, kami akan menghasilkan data pada setiap simpul sebagai kombinasi linier dari nilai-nilai pada simpul induk dengan koefisien dengan menambahkan derau Gaussian. Saya mengambil ide untuk generasi seperti itu dari artikel "Menuju Penemuan Kausal yang Kuat dan Serbaguna untuk Aplikasi Bisnis" (Borboudakis et al., 2016). Simpul yang tidak memiliki orang tua dihasilkan dari distribusi normal - dengan parameter seperti pada dataset untuk simpul terkait.
Saat data diterima, kami menerapkan algoritme yang ingin kami evaluasi. Selain itu, kami sudah memiliki grafik sebab akibat yang sebenarnya. Tetap hanya untuk memahami bagaimana membandingkan grafik yang dihasilkan dengan yang sebenarnya. Dalam "Rekonstruksi yang kuat dari model grafis kausal berdasarkan informasi bersyarat 2 poin dan 3 poin" (Affeldt et al., 2015), disarankan untuk menggunakan terminologi klasifikasi. Kita akan berasumsi bahwa tepi yang digambar adalah kelas Positif, dan yang tidak ditarik adalah kelas Negatif. Kemudian Benar Positif ( ) adalah ketika kita menggambar tepi yang sama seperti pada grafik kausal benar, dan False Positive ( ) - jika tepi ditarik, yang tidak ada dalam grafik sebab-akibat yang sebenarnya. Kami akan mengevaluasi nilai-nilai ini dari sudut pandang kerangka. Untuk memperhitungkan petunjuk arah, kami perkenalkan
untuk tepi yang ditampilkan dengan benar, tetapi dengan arah yang salah. Setelah itu, kami akan mempertimbangkannya seperti ini:
Kemudian Anda bisa membaca -mengukur baik untuk kerangka maupun dengan mempertimbangkan orientasinya (jelas, dalam hal ini, tidak akan lebih tinggi dari pada kerangka). Namun, dalam kasus algoritme PC, tepi ganda ditambahkan hanya , bukan , karena salah satu sisi nyata masih disimpulkan (tanpa Kecukupan Kausal, ini akan salah). Terakhir, mari kita bandingkan algoritme: Dua grafik pertama adalah perbandingan kerangka algoritme PC: yang klasik dan dengan orientasi tepi yang baru. Mereka dibutuhkan untuk menunjukkan batas atas

-ukuran. Dua yang kedua membandingkan algoritma ini dalam kaitannya dengan orientasi. Seperti yang Anda lihat, tidak ada kemenangan.
Bandingkan Model - 3: Matikan Kecukupan Kausal
Sekarang mari kita "menutup" beberapa variabel dalam grafik sebenarnya dan dalam data sintetis setelah pembuatan. Ini akan mematikan Kecukupan Kausal. Tetapi perlu untuk membandingkan hasil tidak dengan grafik yang sebenarnya, tetapi dengan yang diperoleh sebagai berikut:
- tepi dari orang tua simpul tersembunyi akan ditarik ke anak-anaknya,
- hubungkan semua anak dari simpul tersembunyi dengan tepi ganda.
Kita sudah akan membandingkan algoritma FCI + (dengan orientasi tepi yang dimodifikasi dan dengan yang klasik):

Dan sekarang, ketika Kecukupan Kausal tidak terpenuhi, hasil dari orientasi baru menjadi jauh lebih baik.
Pengamatan penting lainnya telah muncul - algoritma PC dan FCI membangun kerangka yang hampir identik dalam praktiknya. Oleh karena itu, saya membandingkan hasilnya dengan orientasi tepi, yang saya usulkan dalam pekerjaan saya.
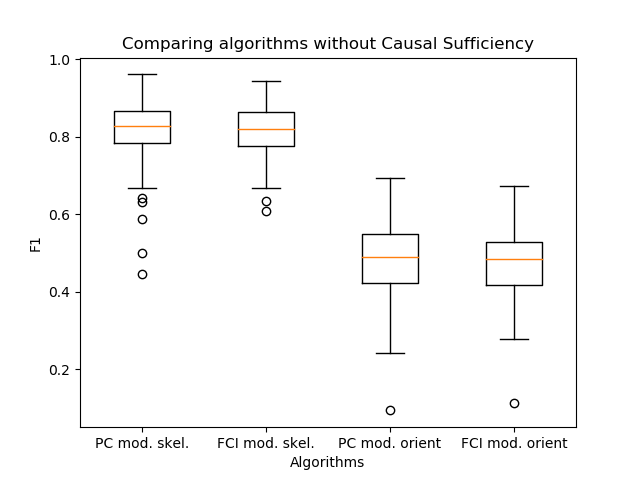
Ternyata algoritma secara praktis tidak berbeda dalam kualitas. Dalam hal ini, PC adalah langkah dari algoritma konstruksi kerangka di dalam FCI. Jadi, menggunakan algoritma PC orientasi, seperti pada algoritma FCI, adalah solusi yang baik untuk meningkatkan kecepatan inferensi tautan.
Keluaran
Saya akan meringkas secara singkat apa yang kita bicarakan di artikel ini:
- Bagaimana tugas memperoleh hubungan sebab akibat dapat muncul di perusahaan IT besar.
- Apa korelasi palsu dan bagaimana mereka dapat mengganggu Pilihan Fitur.
- Algoritme apa untuk tautan inferensi ada dan paling sering digunakan.
- Kesulitan apa yang bisa muncul saat mendapatkan grafik sebab akibat?
- Apa perbandingan grafik kausal dan bagaimana mengatasinya.
Jika Anda tertarik dengan topik kesimpulan kausal, lihat artikel saya yang lain - ada lebih banyak teori. Di sana saya menulis secara rinci tentang istilah dasar yang digunakan dalam inferensi tautan, serta cara kerja algoritma klasik dan orientasi tepi yang saya usulkan.