
Tahun-tahun terakhir pembelajaran mendalam telah menjadi rangkaian pencapaian yang berkelanjutan: mulai dari mengalahkan orang-orang dalam permainan Go to world leadership dalam pengenalan gambar, pengenalan suara, terjemahan teks, dan tugas lainnya. Namun kemajuan ini telah disertai dengan peningkatan yang tak pernah terpuaskan dalam selera daya komputasi. Sekelompok ilmuwan dari MIT, Yeonse University (Korea) dan Brasilia University telah menerbitkan meta-analisis dari 1.058 makalah ilmiah tentang pembelajaran mesin . Ini jelas menunjukkan bahwa kemajuan dalam pembelajaran mesin (ML) adalah turunan dari daya komputasi sistem . Kinerja komputer selalu membatasi fungsionalitas ML, tetapi sekarang kebutuhan model ML baru tumbuh jauh lebih cepat daripada kinerja komputer.
Studi tersebut menunjukkan bahwa kemajuan dalam pembelajaran mesin, pada kenyataannya, sedikit lebih dari konsekuensi dari Hukum Moore. Dan karena alasan ini, banyak masalah ML tidak akan pernah bisa diselesaikan karena keterbatasan fisik komputer.
Para peneliti menganalisis makalah ilmiah tentang Image Classification (ImageNet), Object Recognition (MS COCO), Question Answer (SQuAD 1.1), Named Entity Recognition (COLLN 2003), dan Machine Translation (WMT 2014 En-to-Fr).

Menghitung ML kueri, skala log
Kemajuan di kelima area telah terbukti sangat bergantung pada peningkatan daya komputasi. Ekstrapolasi hubungan ini memperjelas bahwa kemajuan di bidang-bidang ini dengan cepat menjadi tidak berkelanjutan secara ekonomi, teknis, dan lingkungan. Dengan demikian, kemajuan lebih lanjut dalam aplikasi ini akan membutuhkan metode komputasi yang jauh lebih efisien.
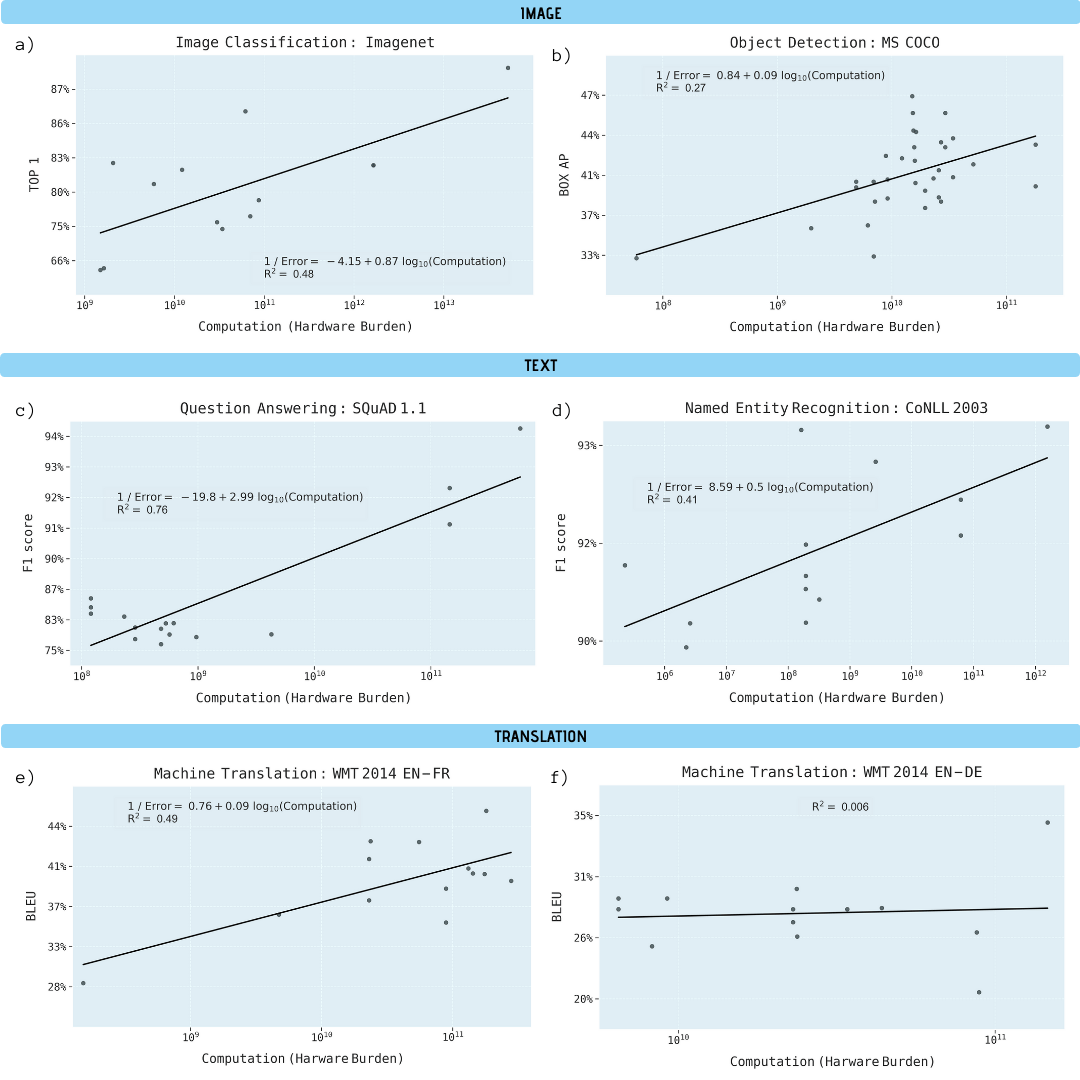
Peningkatan kinerja dalam berbagai tugas pembelajaran mesin sebagai fungsi dari kekuatan komputasi model pembelajaran (dalam gigaflops)
Mengapa pembelajaran mesin sangat bergantung pada daya komputasi
Ada alasan penting untuk meyakini bahwa pembelajaran dalam secara inheren lebih bergantung secara komputasi daripada metode lain. Secara khusus, karena peran hyperparametrization dan bagaimana sistem ditingkatkan, ketika data pelatihan tambahan digunakan untuk meningkatkan kualitas hasil (misalnya, untuk mengurangi frekuensi kesalahan klasifikasi, kesalahan root mean square regresi, dll.).
Terbukti bahwa hyperparametrization memberikan keuntungan yang signifikan, yaitu implementasi jaringan syaraf tiruan dengan parameter yang lebih banyak daripada jumlah titik data yang tersedia untuk melatihnya. Secara klasik, ini akan menyebabkan overfitting. Namun teknik pengoptimalan gradien stokastik memberikan efek pengaturan dengan mengorbankan penghentian awal, menempatkan jaringan neural ke mode interpolasi di mana data pelatihan hampir sama persis, sambil mempertahankan prediksi yang wajar di titik-titik perantara. Contoh jaringan skala besar dengan hyperparametrization adalah salah satu sistem pengenalan pola terbaik NoisyStudent , yang memiliki 480 juta parameter untuk 1,2 juta titik data ImageNet.
Masalah dengan hyperparametrization adalah jumlah parameter pembelajaran mendalam harus bertambah seiring dengan bertambahnya jumlah titik data. Karena biaya pelatihan model pembelajaran mendalam berskala dengan produk dari jumlah parameter dan jumlah titik data, ini berarti bahwa persyaratan komputasi tumbuh setidaknya sebesar kuadrat dari jumlah titik data dalam sistem hyperparametrized. Penskalaan kuadratik belum memperkirakan secara memadai seberapa cepat jaringan deep learning perlu berkembang, karena jumlah data pelatihan harus diskalakan jauh lebih cepat daripada secara linier untuk mendapatkan peningkatan performa linier.
Pertimbangkan model generatif yang memiliki 10 nilai bukan nol dari kemungkinan 1000, dan pertimbangkan empat model untuk mencoba menemukan parameter berikut:
- : 10
- : 9 1
- : 1000 ,
- : , 1000 , ()
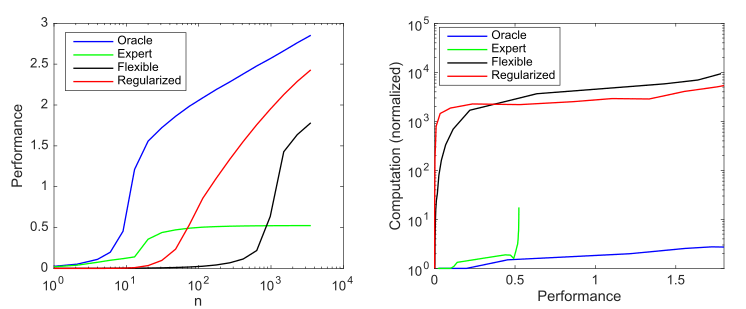
Dampak kompleksitas model dan regularisasi pada kinerja model (diukur sebagai log negatif 10 akar kuadrat rata-rata kesalahan yang dinormalisasi versus prediktor optimal) dan pada persyaratan komputasi yang dirata-rata lebih dari 1000 simulasi per kasus; a) produktivitas rata-rata seiring bertambahnya ukuran sampel; b) Perhitungan rata-rata yang diperlukan untuk meningkatkan kinerja
Grafik ini merangkum prinsip yang diuraikan oleh Andrew Ng: metode pembelajaran mesin tradisional bekerja lebih baik pada data kecil, tetapi model ML fleksibel bekerja lebih baik pada data besar. Fenomena umum model agile adalah bahwa mereka memiliki potensi yang lebih tinggi, tetapi juga membutuhkan lebih banyak data dan kebutuhan komputasi.
Kita dapat melihat bahwa pembelajaran dalam bekerja dengan baik karena menggunakan hiperparametri untuk membuat model yang sangat fleksibel dan regularisasi (implisit) untuk mengurangi kompleksitas sampel ke tingkat yang dapat diterima. Namun, pada saat yang sama, pembelajaran dalam secara signifikan lebih intensif secara komputasi daripada model yang lebih efisien. Jadi, meningkatkan fleksibilitas ML menyiratkan ketergantungan pada sejumlah besar data dan komputasi.
Batas komputasi
Performa komputer selalu membatasi kekuatan sistem ML.
Misalnya, Frank Rosenblatt mendeskripsikan jaringan saraf tiga lapis pertama pada tahun 1960. Diharapkan dia akan "mendemonstrasikan kemungkinan menggunakan perceptron sebagai alat pengenalan pola." Tetapi Rosenblatt menemukan bahwa "dengan bertambahnya jumlah koneksi pada jaringan, beban pada komputer digital biasa segera menjadi berlebihan." Kemudian pada tahun 1969, Minsky dan Papert menjelaskan batasan jaringan 3-lapisan, termasuk ketidakmampuan untuk mempelajari fungsi XOR yang sederhana. Tetapi mereka mencatat solusi potensial: "Para peneliti telah menemukan cara yang menarik untuk mengatasi kesulitan ini dengan memperkenalkan rantai unit perantara yang lebih panjang" (yaitu, dengan membangun jaringan saraf yang lebih dalam). Terlepas dari solusi potensial ini, banyak pekerjaan akademis di bidang ini telah ditinggalkan.karena pada saat itu daya komputasi tidak cukup.
Selama dekade berikutnya, peningkatan perangkat keras memberikan peningkatan kinerja sekitar 50.000 kali lipat, dan jaringan neural secara proporsional meningkatkan kebutuhan komputasi mereka, seperti yang ditunjukkan di KDPV. Karena peningkatan daya komputasi sebesar satu dolar kira-kira sama dengan daya komputasi per chip, biaya ekonomi untuk menjalankan model tersebut sebagian besar tetap stabil dari waktu ke waktu.
Terlepas dari akselerasi CPU yang begitu signifikan, model pembelajaran yang dalam masih terlalu lambat untuk aplikasi skala besar pada tahun 2009. Ini memaksa peneliti untuk fokus pada model skala yang lebih kecil atau menggunakan lebih sedikit contoh pelatihan.
Titik baliknya adalah transfer pembelajaran mendalam ke GPU, yang segera memberikan akselerasi5-15 kali , yang pada tahun 2012 telah berkembang menjadi 35 kali dan membawa kemenangan penting bagi AlexNet di kompetisi Imagenet 2012 . Tetapi pengenalan gambar hanyalah tolok ukur pertama di mana sistem pembelajaran yang dalam menang. Mereka segera menang dalam deteksi objek, pengenalan entitas bernama, terjemahan mesin, penjawab pertanyaan, dan pengenalan ucapan.
Pengenalan pembelajaran mendalam pada GPU (dan kemudian ASIC) menyebabkan adopsi sistem ini secara luas. Namun jumlah daya komputasi dalam sistem ML modern tumbuh lebih cepat, sekitar 10 kali setahun dari 2012 hingga 2019. Kecepatan ini jauh lebih cepat daripada peningkatan keseluruhan dari perpindahan ke GPU, perolehan sederhana dari hembusan nafas terakhir Hukum Moore, atau dari peningkatan efisiensi pelatihan jaringan saraf.
Sebaliknya, peningkatan utama dalam efisiensi ML berasal dari menjalankan model untuk jangka waktu yang lebih lama pada lebih banyak alat berat. Misalnya, pada tahun 2012 AlexNet berlatih menggunakan dua GPU selama 5-6 hari, pada tahun 2017 ResNeXt-101 dilatih pada delapan GPU selama lebih dari 10 hari, dan pada tahun 2019 NoisyStudent melatih sekitar seribu TPU selama 6 hari. Contoh ekstrem lainnya adalah sistem terjemahan mesin Evolved Transformer , yang menggunakan lebih dari 2 juta jam GPU dalam pelatihan, yang menelan biaya jutaan dolar.
Menskalakan komputasi deep learning dengan meningkatkan jam perangkat keras atau jumlah chip bermasalah dalam jangka panjang. Karena ini menyiratkan bahwa skala biaya kira-kira sama dengan peningkatan daya komputasi, dan itu dengan cepat membuat pertumbuhan lebih lanjut menjadi tidak mungkin.
Masa depan
Kesimpulan menyedihkan dari atas.
Tabel berikut menunjukkan seberapa besar daya komputasi dan biaya sistem akan mencapai tujuan tertentu dalam masalah ML, jika kita mengekstrapolasi dari model saat ini. Tugas pembelajaran mesin akan berjalan di superkomputer paling kuat. Penulis karya ilmiah percaya bahwa persyaratan untuk tujuan yang ditetapkan tidak akan terpenuhi . Meskipun mereka sedang mempertimbangkan opsi yang secara teoritis mungkin untuk mencapainya: meningkatkan efisiensi tanpa meningkatkan kinerja, akselerator perangkat keras seperti TPU dan FPGA, komputasi neuromorfik, komputasi kuantum, dan lainnya, tidak satu pun dari teknologi ini (belum) memungkinkan Anda mengatasi batas komputasi ML.

. .
