Misalkan kita memiliki daftar dokumen yang digunakan oleh operator atau akuntan di VLSI , seperti ini: Secara tradisional, tampilan seperti itu menggunakan pengurutan langsung (baru dari bawah) atau sebaliknya (baru dari atas) berdasarkan tanggal dan pengenal ordinal yang ditetapkan saat dokumen dibuat - atau ... Saya telah membahas masalah khas yang muncul dalam kasus ini di artikel PostgreSQL Antipatterns: Menjelajahi Registri . Tetapi bagaimana jika pengguna karena alasan tertentu ingin "tidak biasa" - misalnya, mengurutkan satu bidang "seperti ini", dan lainnya "seperti itu" -

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC? Tetapi kami tidak ingin membuat indeks kedua, karena memperlambat penyisipan dan volume ekstra dalam database.
Apakah mungkin untuk menyelesaikan masalah ini secara efektif hanya dengan menggunakan indeks
(dt, id)?
Pertama, mari kita
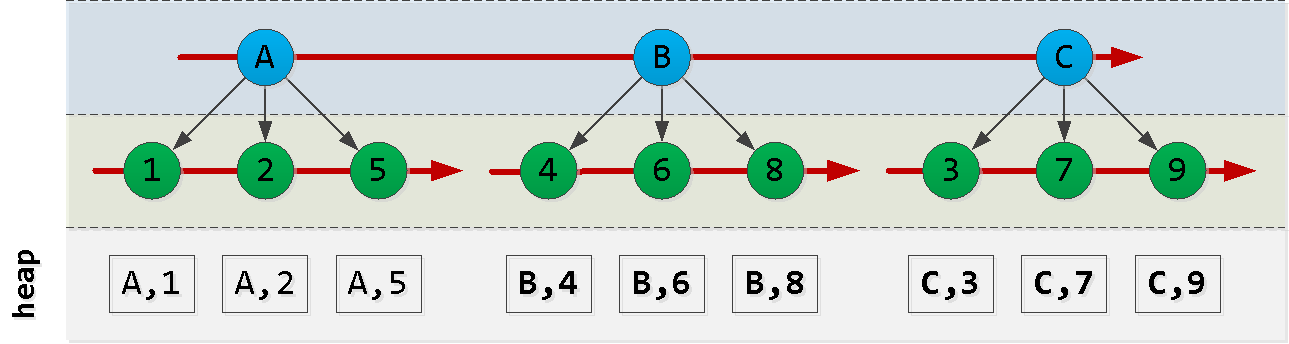
buat sketsa bagaimana indeks kita diurutkan: Perhatikan bahwa urutan entri id dibuat tidak harus sesuai dengan urutan dt, jadi kita tidak dapat mengandalkannya, dan kita harus menciptakan sesuatu.
Sekarang misalkan kita berada di titik (A, 2) dan ingin membaca 6 entri "berikutnya" di sortir : Aha! Kami telah memilih beberapa "potongan" dari node pertama , "potongan" lainnya dari node terakhir dan semua catatan dari node di antara mereka ( ). Setiap blok seperti itu cukup berhasil dibaca oleh indeks , meskipun urutannya kurang sesuai. Mari kita coba membuat kueri seperti ini:
ORDER BY dt, id DESC
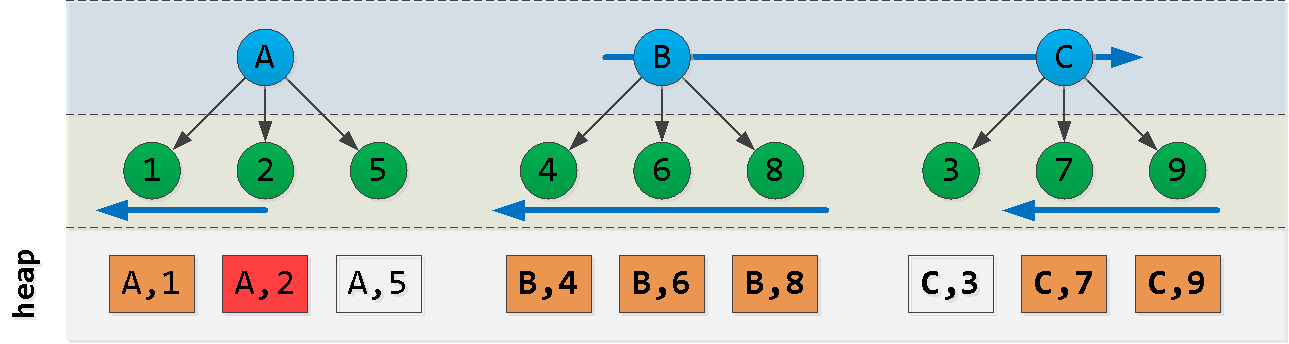
ACB(dt, id)
- pertama kita membaca dari blok A "ke kiri" dari catatan awal - kita mendapatkan
Ncatatan - selanjutnya kita membaca
L - N"di sebelah kanan" dari nilai A - kami menemukan di blok terakhir kunci maksimum C
- saring semua rekaman dari pilihan sebelumnya dengan kunci ini dan kurangi "di sebelah kanan"
Sekarang mari kita coba gambarkan dalam kode dan periksa modelnya:
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);Agar tidak menghitung jumlah record yang sudah dibaca dan perbedaan antara itu dan nomor target, mari kita paksa PostgreSQL untuk melakukan ini menggunakan "hack"
UNION ALLdan LIMIT:
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100Sekarang, mari kumpulkan pembacaan 100 record berikut dengan jenis target dari nilai terakhir yang diketahui:
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;Mari kita lihat apa yang terjadi dalam hal:

[lihat menjelaskan.tensor.ru]
- Jadi,
A = '2019-09-07'kami membaca 3 record menggunakan kunci pertama . - Mereka selesai membaca 97 lainnya oleh
BdanCkarena hit yang tepatIndex Scan. - Di antara semua catatan, 18 disaring oleh kunci maksimum
C. - Kami membaca 23 catatan (bukan 18 yang dicari
Bitmap Scan) menggunakan kunci maksimum. - Semua disortir ulang dan dipangkas 100 record target.
- ... dan semuanya memakan waktu kurang dari satu milidetik!
Metode ini tentu saja tidak universal dan dengan indeks pada sejumlah besar bidang itu akan berubah menjadi sesuatu yang sangat buruk, tetapi jika Anda benar-benar ingin memberikan pengguna penyortiran "non-standar" tanpa "menciutkan" basis menjadi
Seq Scantabel besar, Anda dapat menggunakannya dengan hati-hati.