Hampir semua bisnis dihadapkan pada beban mengambang: sekarang diam, lalu badai. Anda tidak perlu pergi jauh untuk contoh:
- lalu lintas toko online dapat berfluktuasi secara signifikan tergantung pada waktu atau musim;
- layanan internal perusahaan bisa "kosong" selama berminggu-minggu, dan pada malam penyampaian laporan triwulanan, kehadiran mereka akan melonjak tajam.
Di bawah pemotongan, kami akan berbicara tentang bagaimana kami membantu pelanggan kami memecahkan masalah ini dengan memperkenalkan tingkat penyimpanan baru dengan IOPS khusus.
Beberapa kata tentang disk
Semua klien kami menginginkan plus atau minus satu hal - untuk mendapatkan infrastruktur andal yang memenuhi persyaratan proses bisnis dengan harga yang bagus. Oleh karena itu, kami sebagai penyedia cloud dihadapkan pada tugas membangun layanan dan layanan sedemikian rupa sehingga kami dapat dengan mudah menemukan solusi optimal untuk setiap klien.
Sebelumnya, kami memiliki dua tingkatan penyimpanan: st2 dan gp2. Angka "2" dalam terminologi internal kami berarti versi yang lebih baru dan lebih baik.
st2: Standar (HDD) - Media HDD SAS yang santai dan murah. Sangat bagus untuk layanan di mana IOPS tidak penting, tetapi bandwidth itu penting.
Parameternya adalah sebagai berikut: waktu respons - tidak lebih dari 10 ms, kinerja disk hingga 2000 GB - 500 IOPS, dari 2000 GB - 1000 IOPS, dan throughput tumbuh dengan setiap gigabyte dan mencapai 500 MB / dtk untuk 2000 GB yang sama.
gp2: Universal (SSD) - Drive SAS SSD yang lebih mahal dan lebih cepat. Cocok untuk pelanggan yang aplikasinya lebih menuntut dalam hal IOPS. Misalnya - database toko online.
Parameter Gp2 ditentukan di SLA. Kinerja di IOPS dihitung berdasarkan volume - ada 10 IOPS per GB. Bilah atas adalah 10.000 IOPS. Dan waktu respons dari disk tersebut tidak lebih dari 2 ms. Ini adalah kinerja yang cukup tinggi, mampu menyelesaikan 97% tugas bisnis.
Selama bertahun-tahun bekerja, kami telah mengumpulkan banyak statistik dan keahlian terkait dengan pelanggan dan memperhatikan bahwa beberapa dari mereka tidak sepenuhnya nyaman memilih di antara dua opsi drive. Misalnya, seseorang mungkin menginginkan kinerja yang lebih baik daripada 10 IOPS per gigabyte. Atau beban mengambang tidak memungkinkan untuk berhenti di salah satu jenis, dan membayar siap untuk jam sibuk, tetapi kapasitas idle secara berkala juga bukan merupakan pilihan.
Anda dapat mensimulasikan kasus topikal sederhana. Selama pandemi, satu perusahaan perlu mengeluarkan kartu izin untuk karyawan. Agar mereka bisa berkeliling Moskow dengan aman. Stafnya besar, dua ribu orang. Perintah dikeluarkan untuk segera memperbarui data pribadi di sistem CRM perusahaan. Tidak lebih cepat diucapkan daripada dilakukan. Lebih dari seribu orang secara bersamaan bergegas untuk memperbarui informasi. Tetapi orang-orang yang hemat terlibat dalam CRM. Kapasitas kecil telah dialokasikan. Tidak ada yang menyangka bahwa lebih dari sepuluh orang akan naik ke dalamnya pada saat yang bersamaan! Semuanya jatuh dan tidak bisa bangkit untuk hari lain. Proses bisnis telah terganggu, orang hanya duduk di rumah dan takut denda. Dan jika ada kesempatan untuk secara fleksibel "mengubah" kinerja disk di cloud, mereka akan menaikkan IOPS untuk waktu yang singkat, dan kemudian mengembalikannya seperti semula, menghilangkan atau secara signifikan mengurangi waktu henti CRM.
Di satu sisi, situasinya mengerikan; persentase pelanggan dengan kebutuhan seperti itu tidak terlalu besar. Penyedia kecil bahkan akan menganggap keberadaan mereka sebagai anomali statistik dan tidak akan mengambil tindakan apa pun. Di sisi lain, mengatur tingkat penyimpanan baru akan memungkinkan kami meningkatkan fleksibilitas layanan untuk semua klien. Itu artinya kita harus melakukannya.
Jika Anda telah mengikuti blog kami untuk waktu yang lama, Anda mungkin ingat artikel di mana kami berbicara tentang serangkaian eksperimen dengan Dell EMC ScaleIO (sekarang PowerFlex OS) dan implementasinya di CROC Cloud. Bagaimanapun, kami menyarankan Anda untuk membiasakan diri dengannya untuk pemahaman umum.
Secara umum, katakanlah: ScaleIO (DellEMC mengganti nama ScaleIO terlebih dahulu menjadi VxFlex OS, dan dari tanggal 25 Juni 2020 menjadi PowerFlex OS) adalah Software-Defined Storage, SDS yang sangat serbaguna dan andal. Keandalan adalah persyaratan kami # 0. Oleh karena itu, setiap node yang merupakan bagian dari Storage Pool dipasang di rak terpisah, yang mengecualikan kemungkinan kehilangan data jika terjadi kehilangan sebagian daya di pusat data atau secara lokal di rak.
Jika disk, server, atau seluruh rak gagal, kami akan memiliki cukup waktu untuk mereplikasi data ke host lain dan kemudian mengganti elemen yang gagal. Jika dua rak mati sekaligus, toh tidak akan ada yang hilang. Dalam situasi ini, cluster akan masuk ke mode darurat, menulis dan membaca data dari disk akan dibatasi, tetapi setelah pemulihan konektivitas dengan rak "jatuh", PowerFlex OS dengan sendirinya akan mengambil alih proses pembangunan kembali data dan pemulihan cluster. Omong-omong, proses ini paling sering memakan waktu tidak lebih dari beberapa menit.
Ini, tentu saja, situasi darurat - aplikasi yang tidak dapat membaca dan menulis akan segera "jatuh", tetapi hilangnya sebagian besar infrastruktur tidak akan merusak data. Meskipun kemungkinan kegagalan dua rak di bagian berbeda dari aula turbin sangat kecil, ini tidak berarti bahwa itu tidak boleh diperhitungkan.
Dalam hal keserbagunaan, PowerFlex OS (sebelumnya ScaleIO) juga ideal untuk kebutuhan kami. Faktanya, ini adalah konstruktor, siap menerima beban kerja apa pun dan mampu "menerima" HDD SATA / SAS lambat, SSD cepat, dan drive NVME ultra-cepat. Dan ini benar - telah diuji pada berbagai tahap dan pengujian tim pengembangan dan pemeliharaan, Anda dapat merakit cluster secara praktis dari
Musik dari lima sampai enam
Mari kita lihat salah satu skenario di mana pelanggan mungkin membutuhkan kinerja yang fleksibel dengan contoh dunia nyata. Di antara klien kami ada jaringan toko alat musik. Teknisi perusahaan melacak berapa banyak pengunjung yang mengunjungi situs mereka setiap hari dan jam. Ini bahkan tercermin dalam SLA kami: dari pukul 17:00 hingga 18:00 toko menerima jumlah pelanggan maksimum, jadi seharusnya tidak ada pekerjaan teknis atau waktu henti.
Praktik penghitungan standar adalah ketika 100% beban dibagi dalam 24 jam. Ternyata sekitar 4% untuk setiap jam. Untuk jaringan toko musik, jam khusus ini "berbobot" bukan 4, tetapi 10% - ini adalah puluhan ribu pengunjung dan pelanggan.
Oleh karena itu, akan sangat nyaman bagi pelanggan jika dalam jam "emas" ini, disk mereka menjadi lebih cepat seperti sulap,
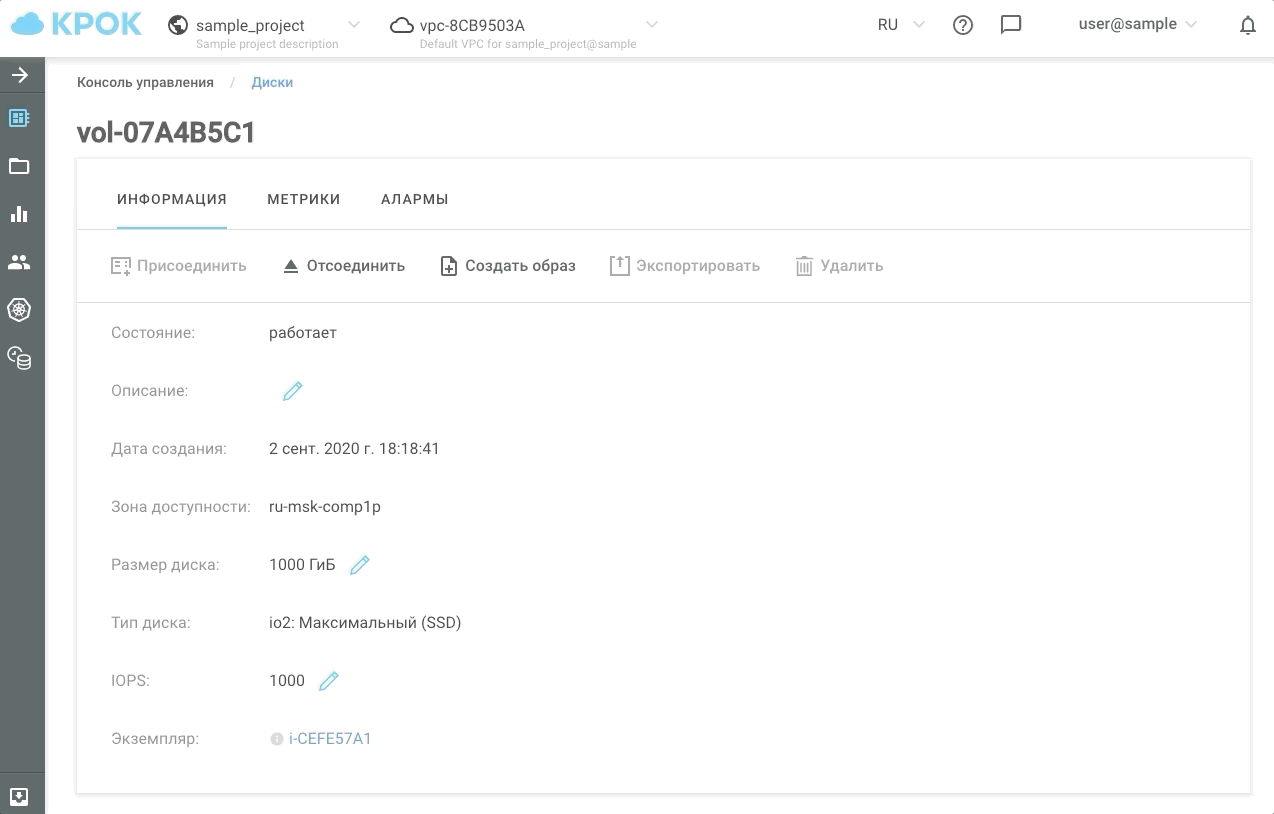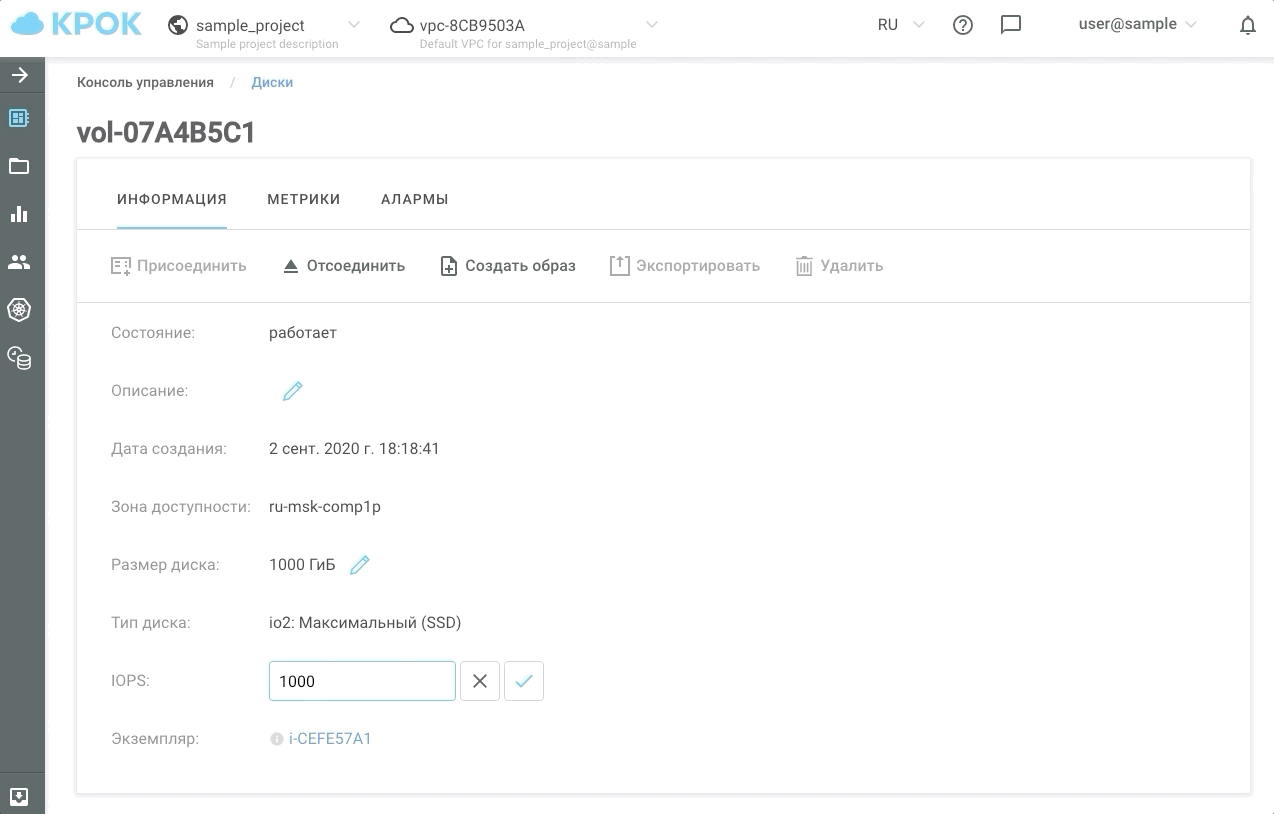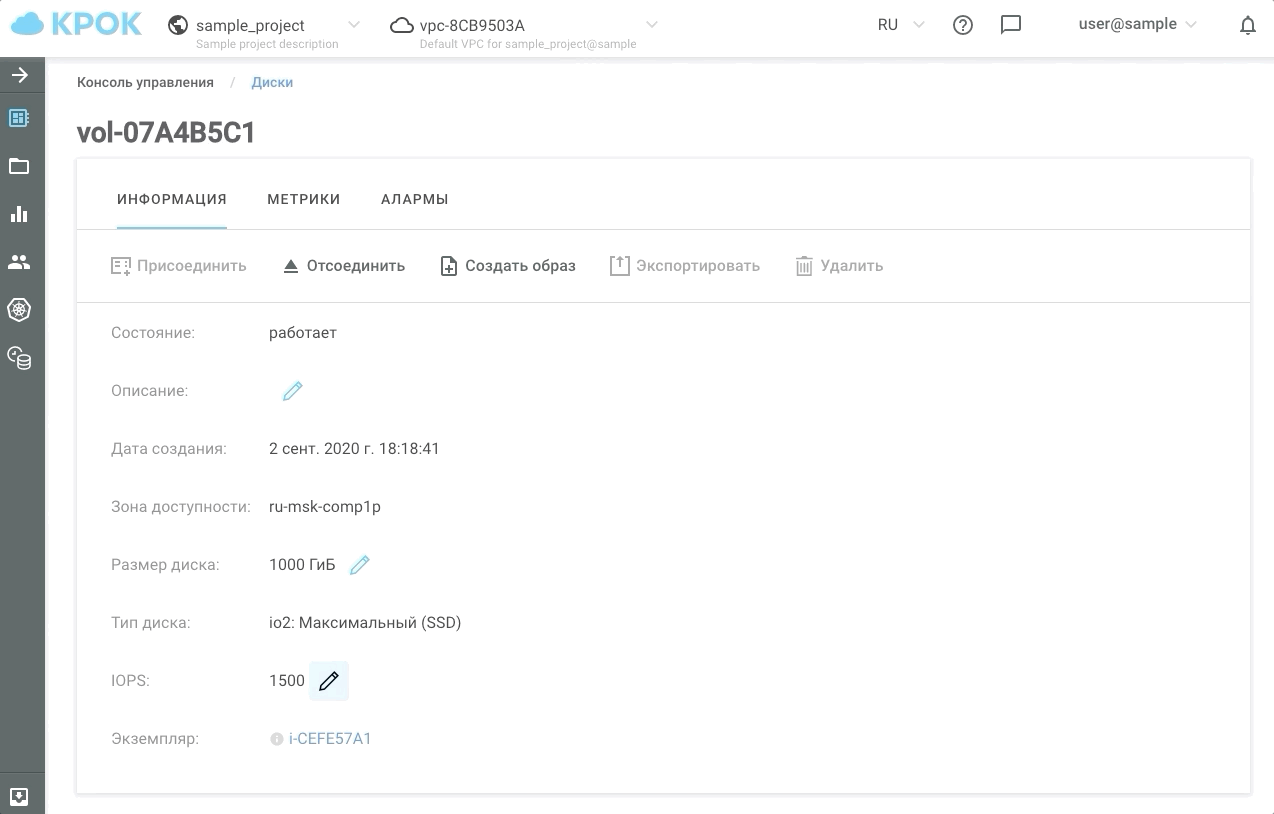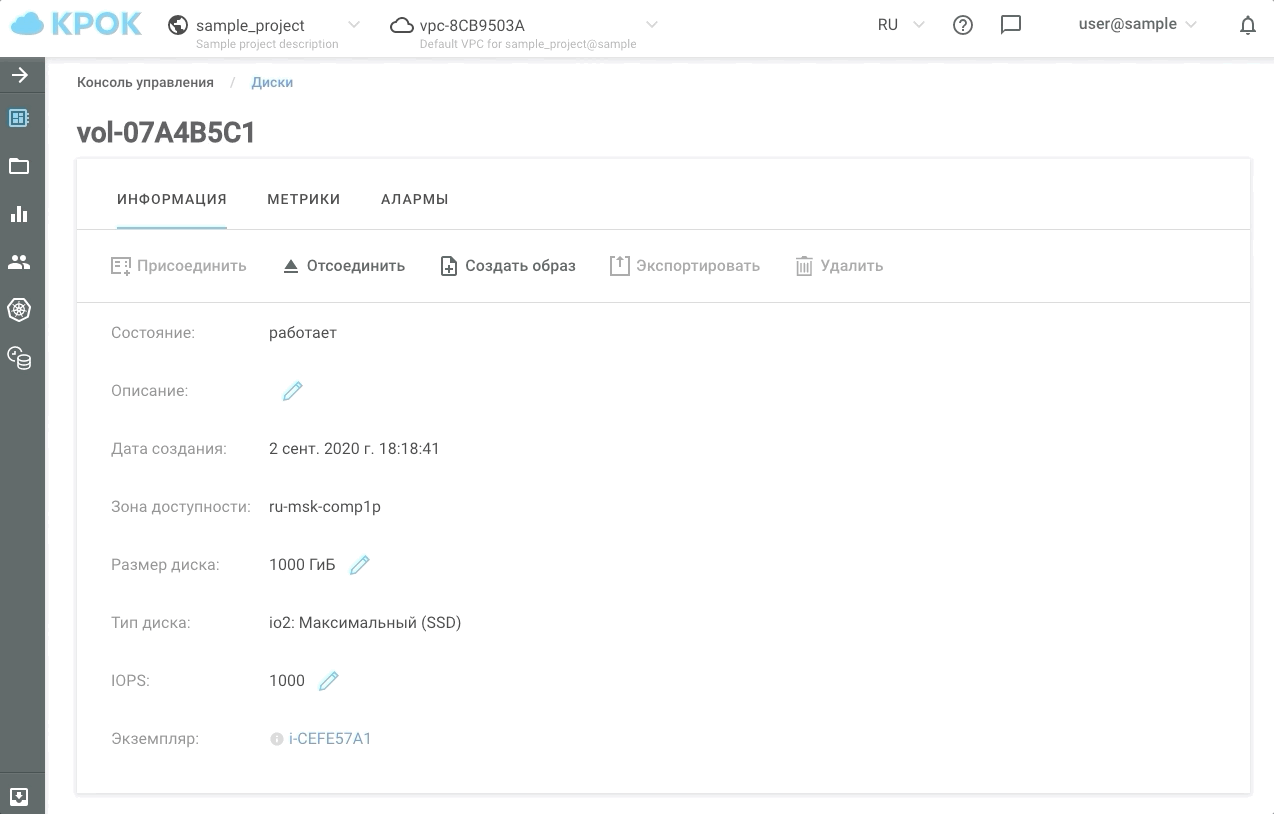
Sekarang kami memiliki kesempatan untuk memberi klien setidaknya 30, setidaknya 50 ribu IOPS selama jam-jam tersibuk, dan sisanya untuk menjaga kinerja pada level biasa. Kami menyebut jenis penyimpanan ini io2: Ultimate (SSD). Waktu respons disk berdasarkan jenis penyimpanan ini tidak lebih dari 1 md!
Dan lagi tentang keandalan: st2, gp2, dan io2 baru adalah independen, independen dari satu sama lain Storage Pools dalam cluster PowerFlex.
Jika sebelumnya klien memilih disk dan menerima kinerja tetap, sekarang dia dapat memilih dan mengkonfigurasinya, kinerja. Terlepas dari volumenya. Filosofinya adalah sebagai berikut: Anda bisa mendapatkan disk yang besar dan cepat dari banyak penyedia, tetapi apakah Anda siap membayarnya 100% setiap saat?
Bagaimana mengelola
Ada dua cara untuk mengelola kinerja: cara lama, melalui antarmuka web, dan menggunakan API. Hal ini memungkinkan untuk menulis skrip sederhana yang akan "mempercepat" atau "memperlambat" disk sesuai jadwal dan, karenanya, menghemat uang Anda.
Jika sebelumnya kami dapat mengambil beban apa pun yang diminta oleh klien, kini kami dapat melakukannya dengan harga terbaik.
Ini terlihat dalam praktiknya.
Meningkatkan ketangkasan infrastruktur cloud adalah tren yang relevan dan sangat tepat. Anda tidak dapat memberi tahu pelanggan: "Ambil apa yang mereka berikan, atau bahkan ini tidak akan terjadi!" Dia harus bisa memutuskan sumber daya apa, kapan dan berapa banyak yang dia butuhkan. Masa depan terletak pada solusi yang fleksibel dan andal.
Kami menjamin layanan kami: semua parameter dijabarkan dalam SLA, dan Anda dapat mengandalkan fakta bahwa angka "kertas" tidak akan menyimpang dari yang asli.
Dan cara memeriksa penyedia cloud Anda, kami sudah menulis di artikel sebelumnya .