
Kami kembali mengudara dan melanjutkan rangkaian catatan Data Scientist, dan hari ini saya menyajikan daftar periksa subjektif saya untuk memilih model pembelajaran mesin.
Ini adalah 10 properti teratas dari masalah dan hanya poin (tanpa urutan di dalamnya), dari sudut pandang mana saya mulai memilih model dan, secara umum, memodelkan tugas analisis data.
Sama sekali tidak perlu bahwa Anda akan memilikinya - semuanya subjektif di sini, tetapi saya berbagi pengalaman saya dari kehidupan.
Apa tujuan kita secara umum? Interpretabilitas dan akurasi - spektrum

Sumber
Mungkin pertanyaan paling penting yang dihadapi oleh Ilmuwan Data sebelum memulai pemodelan adalah:
Apa sebenarnya tugas bisnis itu?
Atau penelitian, jika kita berbicara tentang akademi, dll.
Misalnya, kami memerlukan analitik berdasarkan model data, atau sebaliknya, kami hanya tertarik pada prediksi kualitatif tentang kemungkinan email adalah spam.
Keseimbangan klasik yang saya lihat adalah spektrum antara interpretabilitas metode dan akurasinya (seperti pada grafik di atas).
Namun nyatanya, Anda tidak hanya perlu mengendarai Catboost / Xgboost / Random Forest dan memilih model, tetapi untuk memahami apa yang diinginkan bisnis, data apa yang kami miliki, dan bagaimana penerapannya.
Dalam praktik saya, ini akan segera menentukan spektrum interpretabilitas dan akurasi (apa pun artinya di sini). Dan berdasarkan ini, seseorang sudah dapat memikirkan metode untuk memodelkan masalah.
Jenis tugas itu sendiri
Selanjutnya, setelah kita memahami apa yang diinginkan bisnis - kita perlu memahami jenis matematika dari masalah pembelajaran mesin milik kita, misalnya
- Analisis eksplorasi - analisis murni dari data yang tersedia dan sangat bermanfaat
- Pengelompokan - kumpulkan data menjadi beberapa kelompok berdasarkan beberapa atribut umum
- Regresi - Anda perlu mengembalikan hasil bilangan bulat atau ada kemungkinan suatu peristiwa
- Klasifikasi - Anda perlu mengembalikan satu label kelas
- Multi-label - Anda perlu mengembalikan satu atau lebih label kelas untuk setiap entri
Contoh
Data: ada dua kelas dan kumpulan data tidak berlabel:

Dan Anda perlu membuat model yang akan menandai data ini:

Atau, sebagai opsi, tidak ada label dan Anda harus memilih grup:

Seperti di sini:
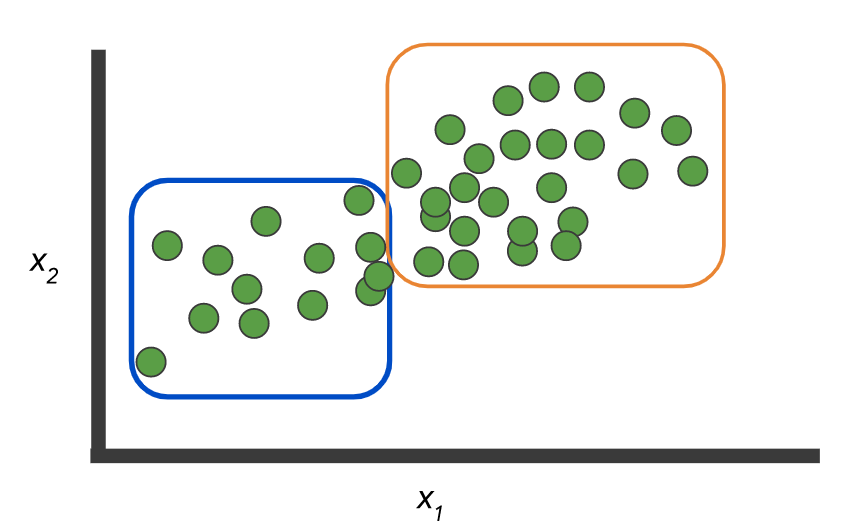
Gambar dari sini .
Tetapi contoh itu sendiri menggambarkan perbedaan antara dua konsep: klasifikasi, ketika N> 2 kelas - kelas jamak vs. multi label
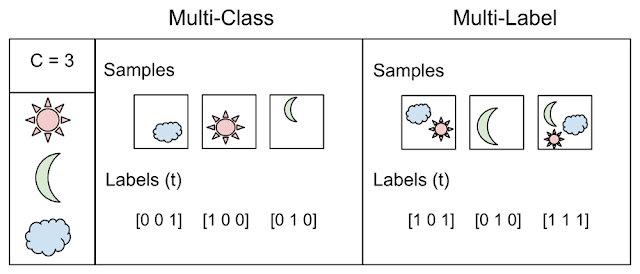
Diambil dari sini
Anda akan terkejut, tetapi seringkali poin ini juga bermanfaat untuk dibicarakan langsung dengan bisnis - ini benar-benar dapat menghemat banyak waktu dan tenaga. Jangan ragu untuk menggambar dan memberikan contoh sederhana (tetapi tidak terlalu sederhana).
Akurasi dan cara menentukannya
Saya akan mulai dengan contoh sederhana, jika Anda adalah bank dan menerbitkan pinjaman, maka pada pinjaman yang tidak berhasil kita kehilangan lima kali lebih banyak daripada yang kita dapatkan pada pinjaman yang sukses.
Oleh karena itu, pertanyaan tentang mengukur kualitas pekerjaan adalah yang utama! Atau bayangkan Anda memiliki ketidakseimbangan yang signifikan dalam data, kelas A = 10%, dan kelas B = 90%, maka pengklasifikasi yang mengembalikan B selalu akurat 90%! Kemungkinan besar ini bukan yang ingin Anda lihat saat melatih model.
Oleh karena itu, sangat penting untuk menentukan metrik penilaian model termasuk:
- kelas berat - seperti pada contoh di atas, kredit buruk adalah 5 dan kredit baik adalah 1
- matriks biaya - adalah mungkin untuk mengacaukan risiko rendah dan menengah - ini tidak masalah, tetapi risiko rendah dan risiko tinggi sudah menjadi masalah
- Haruskah metrik mencerminkan keseimbangan? seperti ROC AUC
- Apakah kita biasanya menghitung probabilitas atau apakah label kelas sudah lurus?
- Atau mungkin kelas umumnya "satu" dan kami memiliki presisi / penarikan kembali dan aturan main lainnya?
Secara umum, pilihan metrik ditentukan oleh tugas dan formulasinya - dan bagi mereka yang menetapkan tugas ini (biasanya pebisnis) semua detail ini perlu diklarifikasi dan diklarifikasi, jika tidak akan ada jahitan pada output.
Analisis posting model
Seringkali perlu melakukan analitik berdasarkan model itu sendiri. Misalnya, apa kontribusi fitur yang berbeda ke hasil asli: biasanya, sebagian besar metode dapat menghasilkan sesuatu yang mirip dengan ini:
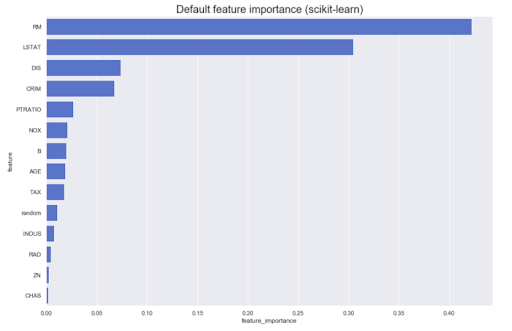
Namun, bagaimana jika kita perlu mengetahui arah - nilai besar atribut A meningkatkan kepunyaan kelas Z, atau sebaliknya? Sebut saja kepentingan fitur terarah - dapat diperoleh dari beberapa model, misalnya, model linier (melalui koefisien pada data yang dinormalisasi).
Untuk sejumlah model yang didasarkan pada pohon dan peningkatan, misalnya, metode eksPlanasi Aditif SHapley cocok.
BENTUK
Ini adalah salah satu metode analisis model yang memungkinkan Anda untuk melihat di balik model.
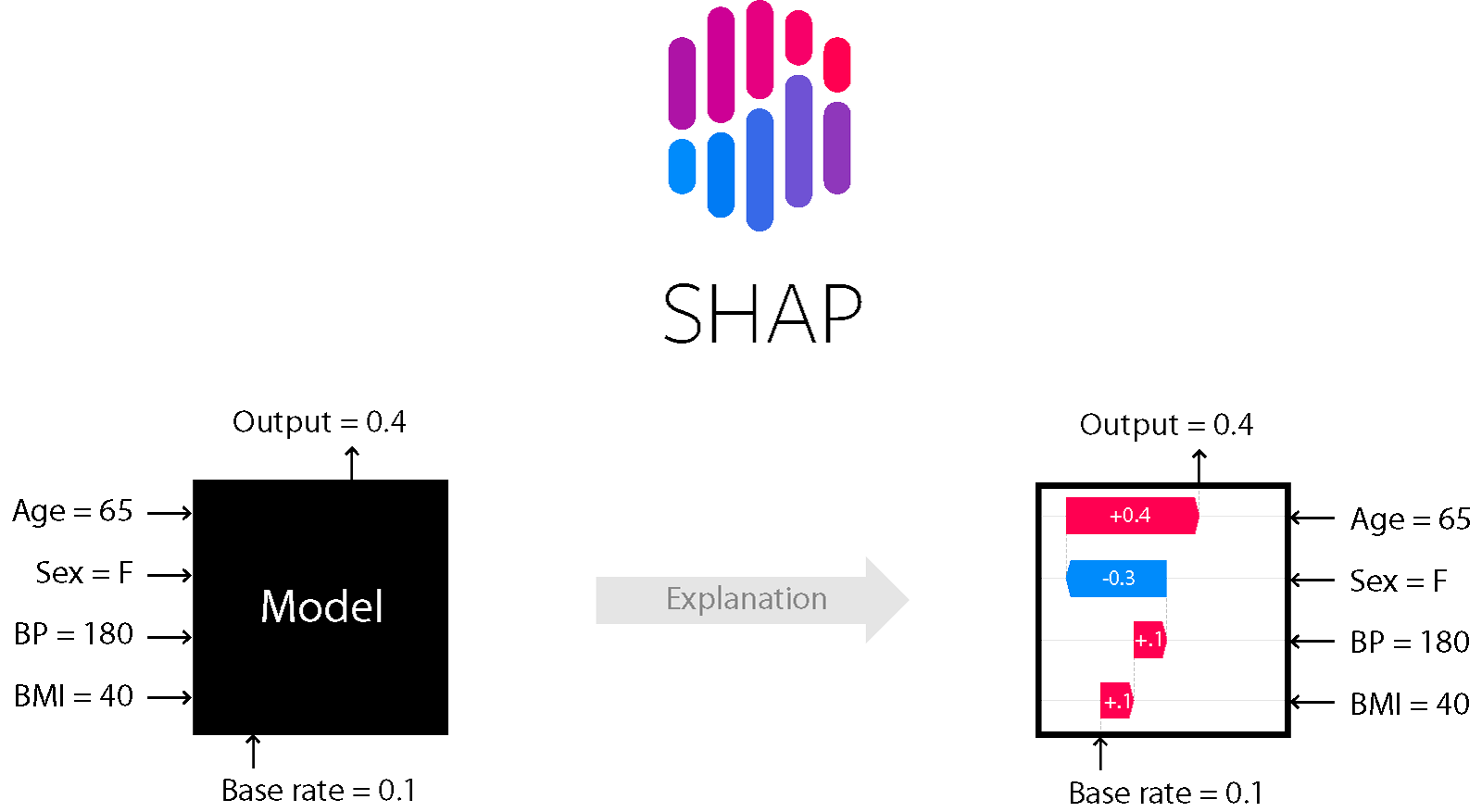
Ini memungkinkan Anda untuk menilai arah efek:

Selain itu, untuk pohon (dan metode yang didasarkan padanya) akurat. Baca lebih lanjut di sini .
Tingkat kebisingan - stabilitas, ketergantungan linier, deteksi outlier, dll.
Ketahanan terhadap kebisingan dan semua kegembiraan hidup ini adalah topik yang terpisah dan Anda perlu menganalisis tingkat kebisingan dengan cermat, serta memilih metode yang sesuai. Jika Anda yakin akan ada pencilan dalam data, Anda perlu membersihkannya dengan kualitas tinggi dan menerapkan metode tahan bising (bias tinggi, regularisasi, dll.).
Juga, tanda bisa collinear dan tanda yang tidak berarti bisa ada - model yang berbeda bereaksi berbeda terhadap ini. Mari kita berikan contoh pada dataset klasik Data Kredit Jerman (UCI) dan tiga model pembelajaran sederhana (relatif):
- Pengklasifikasi regresi Ridge: regresi klasik dengan regulator Tikhonov
- Pohon keputusan
- CatBoost dari Yandex
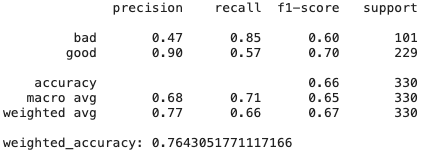
Regresi tinggi
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
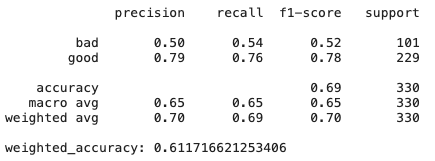
Pohon Keputusan
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Seperti yang dapat kita lihat, hanya model regresi ridge, yang memiliki bias dan regularisasi tinggi, menunjukkan hasil yang lebih baik daripada CatBoost - ada banyak fitur yang tidak terlalu berguna dan collinear, oleh karena itu metode yang resisten terhadapnya menunjukkan hasil yang baik.
Lebih lanjut tentang DT - bagaimana jika kita sedikit mengubah dataset? Tingkat kepentingan fitur dapat bervariasi karena pohon keputusan umumnya merupakan metode yang sensitif, bahkan untuk pengacakan data.
Kesimpulan: terkadang lebih mudah lebih baik dan lebih efektif.
Skalabilitas
Apakah Anda benar-benar membutuhkan Spark atau jaringan neural dengan miliaran parameter?
Pertama, Anda perlu mengevaluasi jumlah data dengan bijaksana, kita telah melihat penggunaan percikan besar-besaran pada tugas-tugas yang dengan mudah masuk ke dalam memori satu mesin.
Spark memperumit proses debug, menambahkan overhead, dan memperumit pengembangan - Anda tidak boleh menggunakannya di tempat yang tidak diperlukan. Klasik .
Kedua, tentu saja, Anda perlu mengevaluasi kompleksitas model dan mengaitkannya dengan tugas. Jika pesaing Anda menunjukkan hasil yang sangat baik dan mereka menjalankan RandomForest, mungkin ada baiknya berpikir dua kali jika Anda membutuhkan jaringan saraf dengan miliaran parameter.
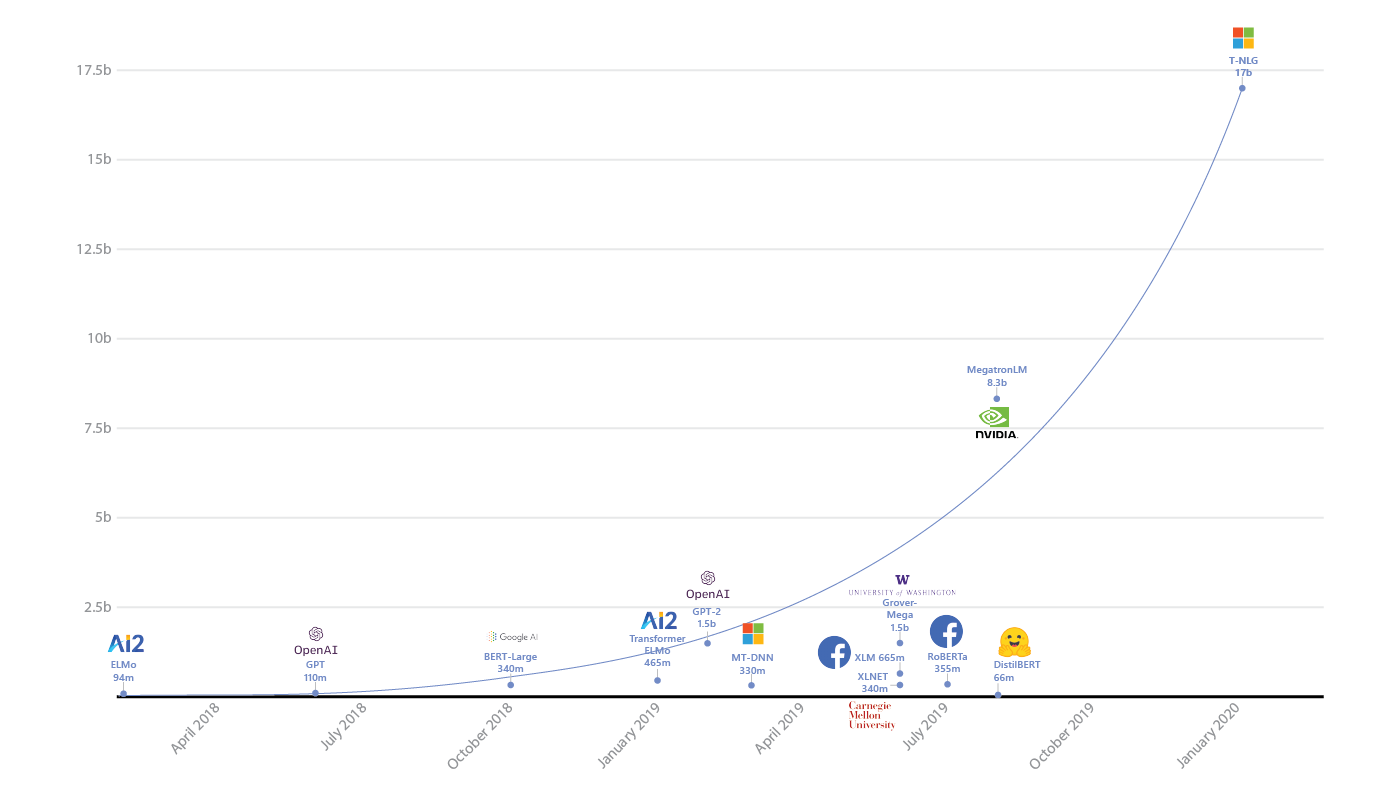
Dan tentu saja, Anda perlu memperhitungkan bahwa jika Anda benar-benar memiliki data yang besar, maka model tersebut harus dapat mengerjakannya - cara belajar dari kumpulan, atau memiliki semacam mekanisme pembelajaran terdistribusi (dan sebagainya). Dan di tempat yang sama, jangan terlalu banyak kehilangan kecepatan saat jumlah data bertambah. Misalnya, kita tahu bahwa metode kernel memerlukan kuadrat memori untuk penghitungan dalam ruang ganda - jika Anda mengharapkan peningkatan ukuran data 10 kali lipat, maka Anda harus berpikir dua kali tentang apakah Anda cocok dengan sumber daya yang tersedia.
Ketersediaan model yang sudah jadi
Detail penting lainnya adalah pencarian model yang sudah terlatih yang dapat dilatih sebelumnya, ideal jika:
- Tidak banyak data, tetapi sangat spesifik untuk tugas kita - misalnya, teks medis.
- Topik secara umum relatif populer - misalnya, menyoroti topik teks - banyak karya di NLP.
- Pendekatan Anda pada prinsipnya memungkinkan pra-pembelajaran - seperti misalnya dengan beberapa jenis jaringan saraf.
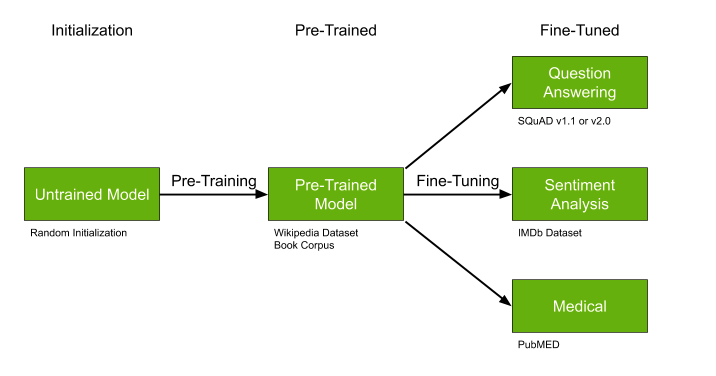
Model yang sudah dilatih sebelumnya seperti GPT-2 dan BERT dapat secara signifikan menyederhanakan solusi dari masalah Anda, dan jika model yang sudah terlatih sudah ada, saya sangat menyarankan agar Anda tidak melewatkan kesempatan ini.
Interaksi fitur dan model linier
Beberapa model berperforma lebih baik jika tidak ada interaksi yang kompleks antar fitur - misalnya, seluruh kelas model linier - Model Aditif Umum. Ada perpanjangan model ini untuk kasus interaksi antara dua fitur yang disebut GA2M - Model Aditif Umum dengan Interaksi Berpasangan.
Biasanya, model tersebut menunjukkan hasil yang baik pada data tersebut, diatur dengan sangat baik, dapat diinterpretasikan, dan tahan terhadap noise. Karena itu, sangat penting untuk memperhatikan mereka.
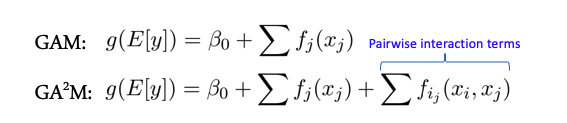
Namun, jika tanda aktif berinteraksi dalam kelompok lebih dari 2, maka metode ini tidak lagi menunjukkan hasil yang baik.
Dukungan paket dan model
Banyak algoritma dan model keren dari artikel datang dalam bentuk modul atau paket untuk python, R, dll. Perlu benar-benar berpikir dua kali sebelum menggunakan dan mengandalkan solusi semacam itu dalam jangka panjang (saya katakan ini, sebagai orang yang telah menulis banyak artikel tentang ML dengan kode semacam itu). Kemungkinan bahwa dalam setahun tidak akan ada dukungan nol sangat tinggi, karena penulis kemungkinan besar sekarang perlu terlibat dalam proyek lain, tidak ada waktu, dan tidak ada insentif untuk berinvestasi dalam pengembangan modul atau repositori.
Dalam hal ini, perpustakaan a la scikit learn adalah baik karena mereka sebenarnya memiliki sekelompok penggemar yang terjamin dan jika ada sesuatu yang benar-benar rusak, cepat atau lambat akan diperbaiki.
Bias dan Keadilan
Bersamaan dengan pengambilan keputusan otomatis, orang-orang yang tidak puas dengan keputusan tersebut menjadi hidup - bayangkan bahwa kita memiliki semacam sistem peringkat untuk aplikasi beasiswa atau hibah penelitian di universitas. Universitas kami tidak biasa - hanya ada dua kelompok siswa: sejarawan dan ahli matematika. Jika tiba-tiba sistem, berdasarkan data dan logikanya, tiba-tiba memberikan semua hibah kepada sejarawan dan tidak memberikannya kepada ahli matematika mana pun, ini mungkin tidak akan menyinggung ahli matematika. Mereka akan menyebut sistem seperti itu bias. Sekarang hanya pemalas yang tidak membicarakan hal ini, dan perusahaan serta orang-orang saling menuntut.
Secara konvensional, bayangkan model yang disederhanakan yang hanya menghitung kutipan artikel dan membiarkan sejarawan mengutip satu sama lain secara aktif - rata-rata adalah 100 kutipan, tetapi tidak ada matematika, mereka memiliki rata-rata 20 - dan mereka menulis sedikit sekali, kemudian sistem mengakui semua sejarawan sebagai "baik" karena tingkat kutipan tinggi 100> 60 (rata-rata), dan matematikawan disebut "buruk" karena mereka semua memiliki tingkat kutipan yang jauh di bawah rata-rata 20 <60. Sistem seperti itu tampaknya tidak memadai bagi seseorang.
Klasik sekarang menyajikan logika pengambilan keputusan dan model pelatihan yang melawan pendekatan bias semacam itu. Jadi, untuk setiap keputusan, Anda memiliki penjelasan (secara kondisional) mengapa itu dibuat dan bagaimana Anda benar-benar berusaha untuk memastikan bahwa model tidak melakukan omong kosong (ELI5 GDPR).

Baca lebih lanjut dari Google di sini, atau dalam artikel di sini .
Secara umum, banyak perusahaan telah memulai aktivitas seperti itu, terutama setelah dirilisnya GDPR - tindakan dan pemeriksaan semacam itu dapat membantu menghindari masalah di masa mendatang.
Jika beberapa topik lebih menarik daripada yang lain - tulis di komentar, kami akan membahas lebih dalam. (DFS)!
