
Kembali pada April 2020, Citizenlab melaporkan enkripsi yang cukup lemah untuk Zoom dan menyatakan bahwa Zoom menggunakan codec audio SILK. Sayangnya, artikel tersebut tidak berisi data awal untuk mengonfirmasi hal ini dan memberi saya kesempatan untuk merujuknya di masa mendatang. Namun, terima kasih kepada Natalie Silvanovich dari Google Project Zerodan ke alat penelusuran Frida, saya bisa mendapatkan dump dari beberapa frame SILK mentah. Analisis mereka menginspirasi saya untuk melihat bagaimana WebRTC menangani audio. Dalam hal kualitas panggilan yang dirasakan secara umum, kualitas audio yang paling berpengaruh, karena kami cenderung melihat gangguan kecil sekalipun. Analisis sepuluh detik saja sudah cukup untuk memulai petualangan nyata - mencari opsi untuk meningkatkan kualitas suara yang disediakan oleh WebRTC.
Saya berurusan dengan klien Zoom asli pada tahun 2017 (sebelum posting DataChannel ) dan memperhatikan bahwa paket audionya terkadang sangat besar dibandingkan dengan paket solusi berbasis WebRTC:

Grafik di atas menunjukkan jumlah paket dengan panjang payload UDP tertentu. Paket antara 150 dan 300 byte tidak biasa jika dibandingkan dengan panggilan WebRTC biasa. Mereka lebih panjang dari paket yang biasanya kami dapatkan dari Opus. Kami menduga ada forward error control (FEC) atau redundansi, tetapi tanpa akses ke frame yang tidak dienkripsi, sulit untuk menarik kesimpulan lebih lanjut atau melakukan sesuatu.
Frame SILK yang tidak terenkripsi di dump baru menunjukkan distribusi yang sangat mirip. Setelah mengubah frame menjadi file dan kemudian memutar pesan singkat (terima kasih kepada Giacomo Vacca untuk posting blog yang sangat membantumenjelaskan langkah-langkah yang diperlukan) Saya kembali ke Wireshark dan melihat paket. Berikut adalah contoh tiga paket yang menurut saya sangat menarik:
packet 7:
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f
packet 8:
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
packet 9:
e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc
854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbaefPaket 9 berisi dua paket sebelumnya, paket 8 - 1 paket sebelumnya. Redundansi ini disebabkan oleh penggunaan LBRR - format Redundansi Bit-Rate Rendah, yang ditunjukkan oleh studi mendalam tentang decoder SILK (dapat ditemukan di proyek Internet yang disediakan oleh tim Skype , atau di repositori di GitHub ):

Zoom menggunakan SKP_SILK_LBRR_VER1 tetapi dengan dua paket fallback. Jika setiap paket UDP tidak hanya berisi bingkai audio saat ini, tetapi juga dua yang sebelumnya, itu akan kuat bahkan jika Anda kehilangan dua dari tiga paket. Jadi, mungkin kunci kualitas suara Zoom adalah resep rahasia Skype Nenek?
Opus FEC
Bagaimana saya bisa mencapai hal yang sama dengan WebRTC? Langkah nyata berikutnya adalah mempertimbangkan Opus FEC.
LBRR SILK (Low Rate Reservation) juga ditemukan di Opus (ingat bahwa Opus adalah codec hybrid yang menggunakan SILK untuk ujung bawah kisaran bitrate). Namun, Opus SILK sangat berbeda dengan SILK asli, yang kode sumbernya pernah ditemukan oleh Skype, seperti bagian dari LBRR yang digunakan dalam mode kontrol kesalahan.
Dalam Opus, kontrol kesalahan tidak hanya ditambahkan setelah bingkai audio asli, melainkan mendahuluinya dan dikodekan dalam bitstream. Kami mencoba bereksperimen dengan menambahkan kontrol kesalahan kami sendiri menggunakan API Stream yang Dapat Disisipkan , tetapi ini memerlukan transcoding lengkap untuk memasukkan informasi ke bitstream sebelum paket sebenarnya.
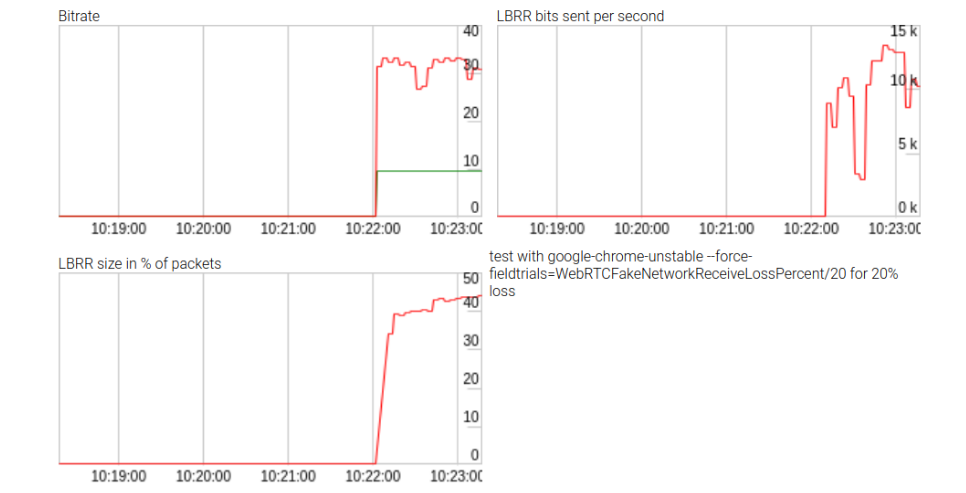
Meskipun upaya tersebut tidak berhasil, namun beberapa statistik mengenai dampak LBRR telah dihasilkan, seperti terlihat pada gambar di atas. LBRR menggunakan bitrate hingga 10 kbps (atau dua pertiga dari kecepatan data) untuk kehilangan paket yang tinggi. Repositori tersedia di sini . Statistik ini tidak ditampilkan saat memanggil
getStats() API WebRTC , jadi hasilnya cukup menarik.
Kebutuhan transcoding bukan satu-satunya masalah dengan Opus FEC. Ternyata, pengaturannya di WebRTC agak tidak berguna:
- , , - . Slack 2016 . , .
- 25%. .
- FEC (. ).
Mengurangi bitrate FEC dari bitrate maksimum target sama sekali tidak masuk akal - FEC secara aktif mengurangi bitrate aliran utama. Aliran bitrate yang lebih rendah biasanya menghasilkan kualitas yang lebih rendah. Jika tidak ada packet loss yang dapat diperbaiki dengan FEC, maka FEC hanya akan menurunkan kualitas, bukan memperbaikinya. Mengapa ini terjadi? Teori utamanya adalah bahwa kemacetan adalah salah satu penyebab hilangnya paket. Jika Anda mengalami kemacetan, Anda tidak ingin mengirim lebih banyak data karena itu hanya akan memperburuk masalah. Namun, seperti yang dijelaskan Emil Ivov dalam ceramah KrankyGeek 2017 yang luar biasa, kemacetan tidak selalu menjadi penyebab hilangnya paket. Selain itu, pendekatan ini juga mengabaikan aliran video yang menyertainya. Strategi FEC berbasis kemacetan untuk audio Opus tidak masuk akal ketika Anda mengirim ratusan kilobit video bersama aliran Opus 50kbps yang relatif kecil. Mungkin di masa depan kita akan melihat beberapa perubahan pada libopus, tetapi untuk saat ini saya ingin mencoba menonaktifkannya, karena saat ini telah diaktifkan di WebRTC secara default .
Kami menyimpulkan bahwa ini tidak cocok untuk kami ...
MERAH
Jika kita menginginkan redundansi nyata, RTP memiliki solusi yang disebut RTP Payload for Redundant Audio Data, atau RED. Cukup tua, RFC 2198 ditulis tahun 1997 . Solusi ini memungkinkan beberapa payload RTP dengan cap waktu berbeda untuk dimasukkan ke dalam paket RTP yang sama dengan biaya yang relatif rendah.
Menggunakan RED untuk meletakkan satu atau dua frame audio redundan di setiap paket akan jauh lebih kuat terhadap packet loss daripada Opus FEC. Tapi ini hanya bisa dilakukan dengan menggandakan atau melipatgandakan bitrate audio dari 30 kbps menjadi 60 atau 90 kbps (dengan tambahan 10 kbps untuk header). Dibandingkan dengan lebih dari 1 megabit data video per detik, itu tidak terlalu buruk.
Pustaka WebRTC menyertakan encoder dan decoder kedua untuk RED, yang sekarang sudah mubazir! Meskipun ada upaya untuk menghapus audio-RED-code yang tidak digunakan , saya dapat menerapkan encoder ini dengan sedikit usaha. Sejarah lengkap dari solusi tersebut tersedia di sistem pelacakan bug WebRTC.
Dan itu tersedia sebagai uji coba, yang disertakan saat Anda memulai Chrome dengan tanda berikut:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/Kemudian RED dapat diaktifkan melalui negosiasi SDP; itu akan ditampilkan seperti ini:
a=rtpmap:someid red/48000/2Ini tidak diaktifkan secara default karena ada lingkungan di mana menggunakan bandwidth ekstra bukanlah ide yang baik. Untuk menggunakan RED, ubah urutan codec sehingga muncul sebelum codec Opus. Ini dapat dilakukan dengan menggunakan API
RTCRtpTransceiver.setCodecPreferencesseperti yang ditunjukkan di sini . Jelas alternatif lain adalah mengubah SDP secara manual. Format SDP juga dapat menyediakan cara untuk mengonfigurasi tingkat redundansi maksimum, tetapi semantik respons penawaran RFC 2198 tidak sepenuhnya jelas, jadi saya memutuskan untuk menunda ini untuk sementara waktu.
Anda dapat mendemonstrasikan bagaimana ini semua bekerja dengan menjalankannya dalam contoh audio . Seperti inilah tampilan versi awal dengan satu paket cadangan:
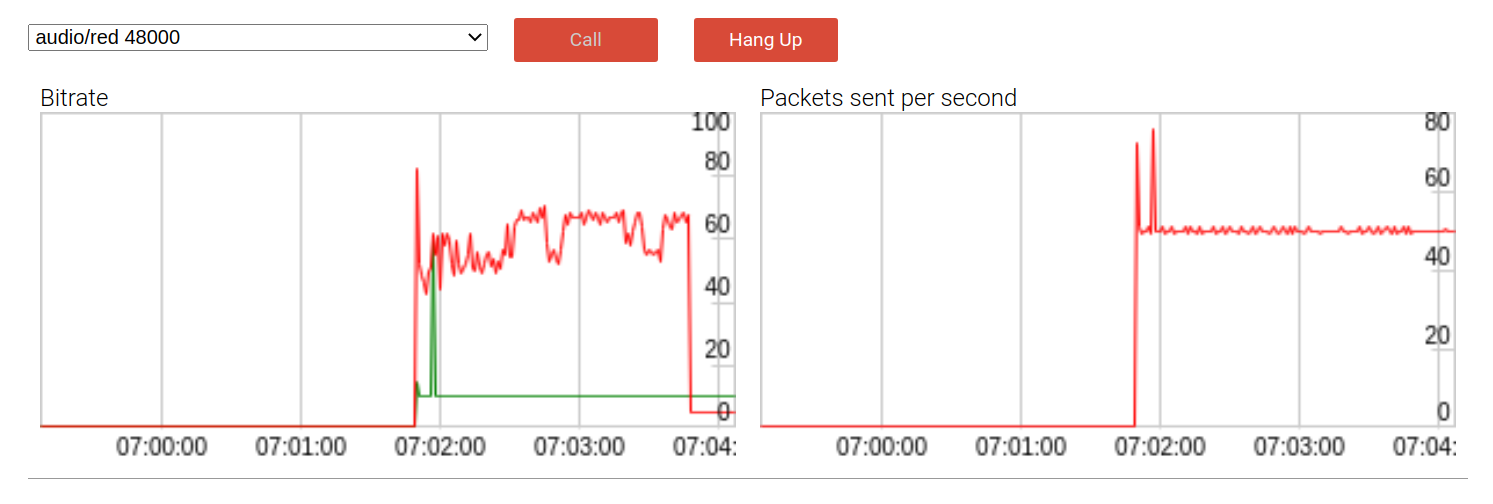
Secara default, bitrate payload (garis merah) hampir dua kali lebih tinggi daripada tanpa redundansi, hampir 60 kbps. DTX (Discontinuous Transfer) adalah mekanisme penghematan bandwidth yang hanya mengirim paket ketika suara terdeteksi. Seperti yang diharapkan, saat menggunakan DTX, efek bitrate agak melunak, seperti yang dapat kita lihat di akhir panggilan.
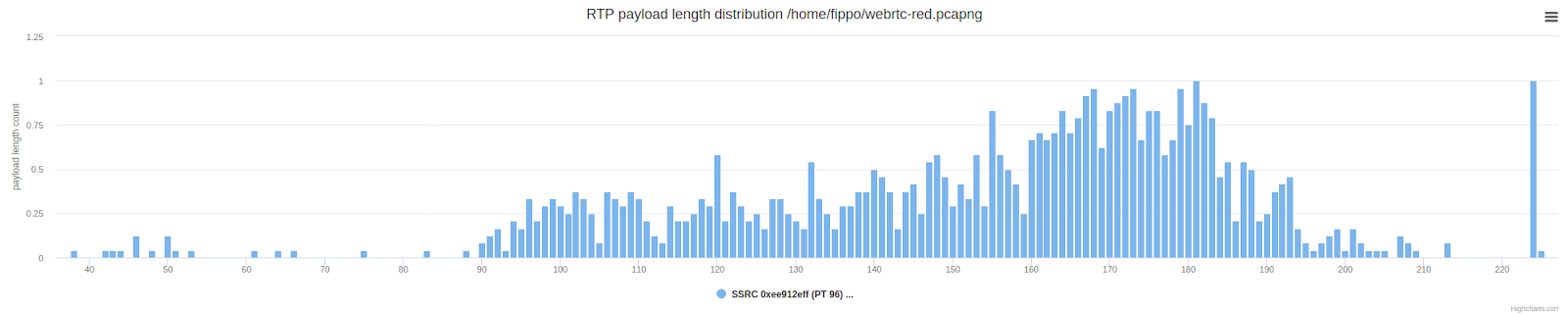
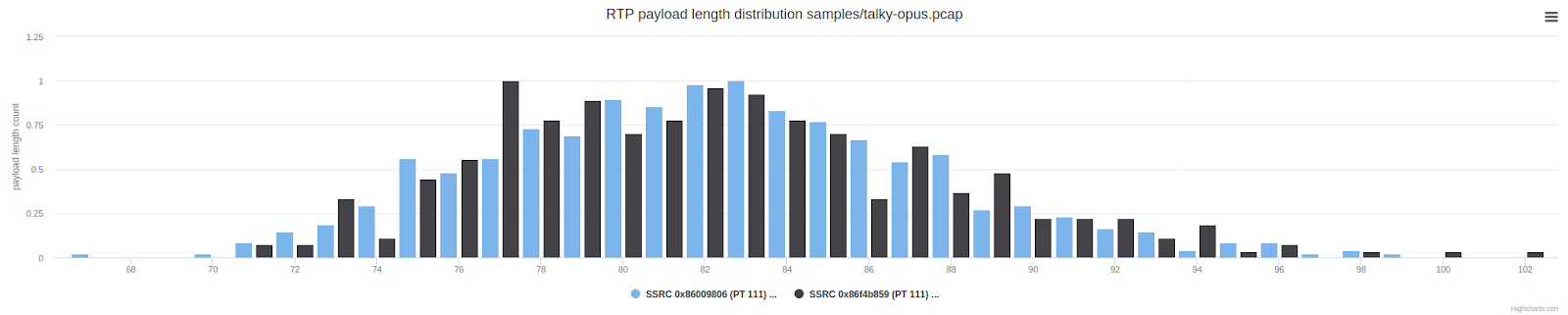
Memeriksa panjang paket menunjukkan hasil yang diharapkan: rata-rata paket tersebut dua kali lebih panjang (lebih tinggi) dibandingkan dengan distribusi normal panjang muatan yang ditunjukkan di bawah ini.
Ini masih sedikit berbeda dari apa yang dilakukan Zoom, di mana kami melihat reservasi pecahan. Mari kita lihat kembali grafik panjang paket Zoom yang ditunjukkan sebelumnya untuk melihat perbandingan:
Menambahkan Dukungan Deteksi Aktivitas Suara (VAD)
Opus FEC hanya mengirimkan data backup jika ada aktivitas suara di dalam paket. Hal yang sama harus diterapkan pada implementasi RED. Untuk ini, encoder Opus harus diubah untuk menampilkan informasi VAD yang benar , yang ditentukan di level SILK. Dengan pengaturan ini, bitrate mencapai 60 kbps hanya dengan adanya ucapan (dibandingkan dengan 60+ kbps konstan):

dan "spektrum" menjadi lebih seperti yang kita lihat dengan Zoom:

Perubahan untuk mencapai ini belum muncul.
Menemukan jarak yang tepat
Jarak adalah jumlah paket cadangan, yaitu jumlah paket sebelumnya pada paket saat ini. Dalam proses mencari jarak yang tepat, kami menemukan bahwa jika MERAH pada jarak 1 sejuk, maka MERAH pada jarak 2 bahkan lebih dingin. Perkiraan laboratorium kami mensimulasikan kehilangan paket acak sebesar 60%. Dalam lingkungan ini, Opus + RED menampilkan suara yang sangat bagus, sedangkan Opus tanpa RED memiliki performa yang jauh lebih buruk. API getStats () WebRTC memberikan kemampuan yang sangat berguna untuk mengukur ini dengan membandingkan persentase sampel tersembunyi yang diperoleh dengan membagi sampel tersembunyi dengan totalSamplesReceived .
Pada halaman sampel audio, data ini dapat dengan mudah diambil dengan menempelkan cuplikan JavaScript ke konsol:
(await pc2.getReceivers()[0].getStats()).forEach(report => {
if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)})Saya menjalankan beberapa tes kehilangan paket menggunakan tanda yang tidak terlalu terkenal tapi sangat berguna
WebRTCFakeNetworkReceiveLossPercent:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/Pada 20% packet loss dan FEC diaktifkan secara default, tidak ada banyak perbedaan dalam kualitas audio, tetapi ada sedikit perbedaan dalam metrik:
| skenario | persentase kerugian |
|---|---|
| tanpa merah | delapan belas% |
| tidak ada merah, FEC dinonaktifkan | 20% |
| merah dengan jarak 1 | 4% |
| merah dengan jarak 2 | 0,7% |
Tanpa RED atau FEC, metrik hampir sama dengan packet loss yang diminta. Ada efek FEC, tapi kecil.
Tanpa RED, pada kehilangan 60%, kualitas suara menjadi agak buruk, sedikit metalik, dan kata-kata sulit dimengerti:
| skenario | persentase kerugian |
|---|---|
| tanpa merah | 60% |
| merah dengan jarak 1 | 32% |
| merah dengan jarak 2 | delapan belas% |
Ada beberapa artefak yang dapat didengar di RED dengan jarak = 1, tetapi suara yang hampir sempurna dengan jarak 2 (yang merupakan jumlah redundansi yang sedang digunakan).
Ada perasaan bahwa otak manusia dapat menahan tingkat keheningan tertentu yang terjadi secara tidak teratur. (Dan Google Duo tampaknya menggunakan algoritma pembelajaran mesin untuk mengisi keheningan.)
Mengukur kinerja di dunia nyata
Kami berharap masuknya RED ke dalam Opus akan meningkatkan kualitas suara, meski dalam beberapa kasus justru bisa memperburuknya. Emil Ivov menawarkan diri untuk melakukan beberapa tes mendengarkan menggunakan metode POLQA-MOS. Ini sudah dilakukan untuk Opus, jadi kami memiliki dasar untuk perbandingan.
Jika tes awal menunjukkan hasil yang menjanjikan, maka kami akan melakukan eksperimen skala besar pada pemindaian utama Jitsi Meet, dengan menerapkan metrik persentase kerugian yang kami gunakan di atas.
Perhatikan bahwa untuk server media dan SFU, mengaktifkan RED sedikit lebih sulit karena server mungkin perlu mengelola relai RED untuk memilih klien, seolah-olah tidak semua klien mendukung konferensi RED. Juga, beberapa klien mungkin berada di saluran bandwidth terbatas di mana RED tidak diperlukan. Jika titik akhir tidak mendukung RED, SFU dapat menghapus pengkodean yang tidak perlu dan mengirim Opus tanpa pembungkus. Selain itu, ia dapat mengimplementasikan RED itu sendiri dan menggunakannya saat mengirim ulang paket dari titik akhir yang mentransmisikan Opus ke titik akhir yang mendukung RED.
Terima kasih banyak kepada Jitsi / 8 × 8 Inc yang telah mensponsori petualangan yang mengasyikkan ini dan orang-orang di Google yang menganalisis dan memberikan umpan balik tentang perubahan yang diperlukan.
Dan tanpa Natalie Silvanovich, saya akan duduk melihat byte yang dienkripsi!