 Halo para Penduduk! Buku Site Reliability Engineering memicu diskusi hangat. Apa itu eksploitasi saat ini, dan mengapa masalah keandalan begitu mendasar? Sekarang teknisi Google di balik buku terlaris ini mengusulkan untuk beralih dari teori ke praktik - Buku Kerja Keandalan Situs menunjukkan bagaimana prinsip dan praktik SRE diterjemahkan ke dalam produksi Anda Keahlian Google dilengkapi dengan kasus pengguna Google Cloud Platform. Perwakilan dari Evernote, The Home Depot, The New York Times, dan perusahaan lain menggambarkan pengalaman tempur mereka, memberi tahu praktik mana yang telah mereka adopsi dan mana yang tidak. Buku ini akan membantu Anda menyesuaikan SRE dengan realitas praktik Anda sendiri, tidak peduli seberapa besar perusahaan Anda. Anda akan belajar untuk:
Halo para Penduduk! Buku Site Reliability Engineering memicu diskusi hangat. Apa itu eksploitasi saat ini, dan mengapa masalah keandalan begitu mendasar? Sekarang teknisi Google di balik buku terlaris ini mengusulkan untuk beralih dari teori ke praktik - Buku Kerja Keandalan Situs menunjukkan bagaimana prinsip dan praktik SRE diterjemahkan ke dalam produksi Anda Keahlian Google dilengkapi dengan kasus pengguna Google Cloud Platform. Perwakilan dari Evernote, The Home Depot, The New York Times, dan perusahaan lain menggambarkan pengalaman tempur mereka, memberi tahu praktik mana yang telah mereka adopsi dan mana yang tidak. Buku ini akan membantu Anda menyesuaikan SRE dengan realitas praktik Anda sendiri, tidak peduli seberapa besar perusahaan Anda. Anda akan belajar untuk:
- Pastikan keandalan layanan di cloud dan lingkungan yang tidak Anda kendalikan sepenuhnya;
- menerapkan berbagai metode pembuatan, peluncuran dan pemantauan layanan, dengan fokus pada SLO;
- mengubah tim admin menjadi teknisi SRE;
- menerapkan metode memulai SRE dari awal dan berdasarkan sistem yang ada. Betsy Beyer, Neil Richard Murphy, David Renzin, Kent Kawahara, dan Stephen Thorne semuanya terlibat dalam memastikan keandalan sistem Google.
Manajemen sistem pemantauan
Sistem pemantauan Anda sama pentingnya dengan layanan lain yang Anda gunakan. Oleh karena itu, pemantauan harus dilakukan dengan hati-hati.
Perlakukan konfigurasi Anda sebagai kode Memperlakukan
konfigurasi sistem Anda sebagai kode dan menyimpannya dalam sistem kontrol versi adalah praktik umum, dengan opsi seperti menyimpan riwayat perubahan, menautkan perubahan spesifik ke sistem manajemen tugas, rollback yang disederhanakan, analisis kode statis untuk kesalahan, dan prosedur pemeriksaan kode paksa.
Kami juga sangat menyarankan untuk memperlakukan konfigurasi pemantauan sebagai kode (untuk informasi lebih lanjut tentang konfigurasi, lihat Bab 14). Sistem pemantauan yang mendukung penyesuaian menggunakan deskripsi tujuan dan fungsi yang dibentuk dengan baik, daripada sistem yang hanya menyediakan antarmuka web atau API gaya CRUD (http://bit.ly/1G4WdV1). Pendekatan konfigurasi ini standar untuk banyak biner open source yang hanya membaca file konfigurasi. Beberapa solusi pihak ketiga seperti grafanalib (http://bit.ly/2so5Wrx) mendukung pendekatan ini untuk komponen yang secara tradisional dapat disesuaikan menggunakan UI.
Dorong konsistensi
Perusahaan besar dengan banyak tim proyek yang menggunakan pemantauan perlu mencapai keseimbangan yang rumit: di satu sisi, pendekatan terpusat memastikan konsistensi, tetapi di sisi lain, tim individu mungkin ingin memiliki kendali penuh atas cara kerja konfigurasi mereka.
Keputusan yang tepat tergantung pada jenis organisasi Anda. Seiring waktu, pendekatan Google telah berkembang untuk menyatukan semua perkembangan dalam satu platform yang berfungsi sebagai layanan terpusat. Ini adalah keputusan yang bagus bagi kami, dan ada beberapa alasan untuk ini. Infrastruktur umum memungkinkan teknisi untuk berpindah dari satu tim ke tim lain dengan lebih cepat dan lebih mudah serta mempermudah kolaborasi saat debugging. Selain itu, ada layanan dasbor terpusat di mana setiap dasbor tim terbuka dan dapat diakses. Jika Anda memahami dengan baik informasi yang diberikan oleh tim lain, Anda dapat dengan cepat memperbaiki masalah Anda sendiri dan masalah tim lain.
Jika memungkinkan, pertahankan cakupan pemantauan dasar sesederhana mungkin. Jika semua layanan Anda mengekspor kumpulan garis dasar yang konsisten, Anda dapat secara otomatis mengumpulkan metrik tersebut di seluruh organisasi Anda dan menyediakan kumpulan dasbor yang konsisten. Pendekatan ini berarti bahwa ada pemantauan dasar untuk setiap komponen baru yang Anda luncurkan secara otomatis. Dengan cara ini, banyak tim di perusahaan Anda - bahkan bukan tim teknisi - dapat menggunakan data pemantauan.
Lebih Memilih Koneksi Longgar
Perubahan persyaratan bisnis dan sistem produksi Anda akan terlihat berbeda dalam satu tahun. Sama seperti layanan yang Anda kendalikan, sistem pemantauan Anda harus berkembang dan berkembang seiring waktu, melewati berbagai masalah umum.
Kami menganjurkan agar kopling antar komponen sistem kontrol Anda tidak terlalu kuat. Anda harus memiliki antarmuka yang andal untuk mengonfigurasi setiap komponen dan mentransfer data pemantauan. Komponen yang berbeda harus bertanggung jawab untuk mengumpulkan, menyimpan, mengingatkan dan memvisualisasikan data pemantauan Anda. Antarmuka yang stabil memudahkan penggantian komponen tertentu dengan alternatif yang paling sesuai.
Di dunia open source, memecah fungsionalitas menjadi beberapa komponen menjadi populer. Sepuluh tahun yang lalu, sistem pemantauan seperti Zabbix (https://www.zabbix.com/) menggabungkan semua fungsi menjadi satu komponen. Desain modern biasanya melibatkan memisahkan pengumpulan dan pelaksanaan aturan (menggunakan solusi seperti server Prometheus (https://prometheus.io/)), jangka panjang penyimpanan time series (InfluxDB, www.influxdata.com ), agregasi alert ( Alertmanager, bit.ly/2soB22b ) dan membuat dasbor (Grafana, grafana.com ).
Pada saat penulisan ini, setidaknya ada dua standar terbuka populer yang memungkinkan Anda melengkapi perangkat lunak dengan alat yang diperlukan dan menyediakan metrik:
- statsd — , Etsy, ;
- Prometheus — , . Prometheus OpenMetrics (https://openmetrics.io/).
Sistem dasbor terpisah yang menggunakan beberapa sumber data memberikan tampilan layanan Anda yang terpusat dan terpadu. Google baru-baru ini mengalami keuntungan ini dalam praktiknya: sistem pemantauan lawas kami (Borgmon1) menggabungkan dasbor dalam konfigurasi yang sama seperti aturan pemberitahuan. Saat beralih ke sistem baru (Monarch, youtu.be/LlvJdK1xsl4 ), kami memutuskan untuk memindahkan dasbor ke layanan terpisah (Viceroy, bit.ly/2sqRwad ). Raja Muda bukanlah komponen Borgmon atau Monarch, jadi Monarch memiliki lebih sedikit kebutuhan fungsional. Karena pengguna dapat menggunakan Viceroy untuk menampilkan grafik berdasarkan data dari kedua sistem pemantauan, mereka dapat bermigrasi secara bertahap dari Borgmon ke Monarch.
Metrik Berarti
Bab 5 menjelaskan bagaimana Anda dapat menggunakan metrik kualitas layanan (SLI) untuk melacak dan melaporkan ancaman terhadap anggaran Anda. Metrik SLI adalah metrik pertama yang diperiksa ketika peringatan dipicu berdasarkan target Quality of Service (SLO). Metrik ini akan muncul di dasbor layanan Anda, idealnya di halaman depan.
Saat menyelidiki akar penyebab pelanggaran SLO, Anda kemungkinan besar tidak akan mendapatkan informasi yang cukup dari panel SLO. Panel-panel ini menunjukkan bahwa ada pelanggaran, tetapi Anda kemungkinan tidak tahu tentang alasan yang menyebabkannya. Data lain apa yang harus ditampilkan di dasbor?
Kami yakin pedoman berikut akan membantu saat menerapkan metrik: Metrik ini harus memberikan pemantauan yang berarti yang memungkinkan Anda menyelidiki masalah operasional dan memberikan berbagai informasi tentang layanan Anda.
Perubahan yang disengaja
Saat mendiagnosis lansiran terkait SLO, Anda harus dapat beralih dari metrik lansiran yang memberi tahu Anda tentang masalah yang memengaruhi pengguna ke metrik yang memperingatkan Anda tentang akar penyebab masalah tersebut. Alasan tersebut mungkin saja perubahan yang disengaja baru-baru ini pada layanan Anda. Tambahkan pemantauan yang memberi tahu Anda tentang setiap perubahan dalam produksi. Untuk mendeteksi fakta bahwa perubahan telah dilakukan, kami merekomendasikan hal berikut:
- memantau versi file biner;
- , ;
- , .
Jika salah satu dari komponen ini tidak memiliki versi, Anda perlu melacak kapan komponen terakhir dirakit atau dikemas.
Saat mencoba menghubungkan masalah layanan yang muncul dengan penerapan, jauh lebih mudah untuk melihat bagan atau panel yang direferensikan dalam peringatan daripada membalik-balik log CI / CD setelah fakta.
Dependensi
Meskipun layanan Anda tidak berubah, semua dependensinya dapat berubah. Oleh karena itu, Anda juga perlu melacak respons yang berasal dari dependensi langsung.
Sebaiknya ekspor permintaan dan ukuran respons dalam byte, waktu respons, dan kode respons untuk setiap dependensi. Saat memilih metrik untuk diagram, perhatikan keempat sinyal emas berikut (lihat bagian"Empat Sinyal Emas," Bab 6 dari Rekayasa Keandalan Situs ).
Anda dapat menggunakan label tambahan dalam metrik untuk memisahkannya dengan kode respons, nama metode RPC (panggilan prosedur jarak jauh), dan nama layanan yang dipanggil.
Idealnya, daripada meminta setiap pustaka klien RPC untuk mengekspor label tersebut, Anda dapat menggunakan pustaka klien RPC tingkat yang lebih rendah untuk tujuan ini sekali. Ini memberikan konsistensi yang lebih baik dan memungkinkan Anda memantau dependensi baru dengan mudah.
Ada dependensi yang menawarkan API yang sangat terbatas, di mana semua fungsionalitas tersedia melalui metode RPC tunggal yang disebut Get, Query, atau sama tidak informatifnya, dan perintah sebenarnya ditetapkan sebagai argumen untuk metode tersebut. Pendekatan titik tunggal untuk alat di pustaka klien tidak berfungsi untuk jenis ketergantungan ini: Anda akan melihat banyak variabilitas dalam latensi dan persentase kesalahan tertentu yang mungkin atau mungkin tidak menunjukkan bahwa beberapa bagian dari "berlumpur" ini API benar-benar tidak berfungsi. Jika ketergantungan ini kritis, pemantauan yang baik untuk itu dapat diimplementasikan dengan cara berikut.
- Ekspor metrik terpisah yang dirancang khusus untuk dependensi ini, tempat permintaan akan dibuka untuk mendapatkan sinyal yang valid.
- Minta pemilik dependensi untuk menulis ulang untuk mengekspor API yang diperluas yang mendukung pemisahan fungsi antara metode dan layanan RPC individual.
Tingkat beban
Disarankan untuk mengontrol dan melacak penggunaan semua sumber daya yang dengannya layanan bekerja. Beberapa sumber daya memiliki batas keras yang tidak dapat Anda lampaui. Misalnya, ukuran RAM, hard disk yang dialokasikan untuk aplikasi Anda, atau kuota CPU. Sumber daya lain, seperti deskriptor file terbuka, utas aktif di kumpulan utas apa pun, waktu tunggu antrean, atau jumlah log yang ditulis, mungkin tidak memiliki batasan tegas yang jelas, tetapi masih perlu dikelola.
Bergantung pada bahasa pemrograman yang Anda gunakan, Anda perlu melacak beberapa sumber tambahan:
- di Java, heap dan meta space (http://bit.ly/2J9g3Ha), dan metrik yang lebih spesifik bergantung pada jenis pengumpulan sampah yang digunakan;
- di Go, jumlah goroutine.
Bahasa pemrograman itu sendiri menyediakan berbagai dukungan untuk melacak sumber daya ini.
Selain untuk memperingatkan Anda tentang peristiwa penting, seperti yang dijelaskan di Bab 5, Anda mungkin juga ingin mengatur peringatan yang dipicu ketika sumber daya tertentu mendekati penipisan kritis. Ini berguna, misalnya, dalam situasi berikut:
- ketika sumber daya memiliki batas yang ketat;
- ketika penurunan kinerja terjadi ketika ambang penggunaan terlampaui.
Pemantauan penting untuk semua sumber daya, bahkan yang dikelola layanan dengan baik. Metrik ini sangat penting saat merencanakan sumber daya dan kemampuan.
Status lalu lintas yang diterbitkan
Direkomendasikan untuk menambahkan metrik atau label metrik pada dasbor yang akan memungkinkan Anda untuk memecah lalu lintas yang dikeluarkan dengan kode status (jika metrik yang digunakan oleh layanan Anda untuk tujuan SLI tidak berisi informasi ini). Berikut beberapa pedoman.
- Lacak semua kode respons untuk lalu lintas HTTP, bahkan yang, karena kemungkinan perilaku klien yang salah, bukanlah alasan untuk mengeluarkan peringatan.
- Jika Anda menerapkan batas waktu atau batas kuota untuk pengguna Anda, pantau terus jumlah permintaan yang ditolak karena kurangnya kuota.
Plot data ini dapat membantu Anda menentukan kapan tingkat kesalahan berubah secara nyata selama perubahan produksi.
Penerapan metrik target
Setiap metrik harus memenuhi tujuannya. Jangan tergoda untuk mengekspor beberapa metrik hanya karena mudah dibuat. Sebaliknya, pikirkan tentang bagaimana mereka akan digunakan. Arsitektur metrik (atau ketiadaan) memiliki implikasi. Idealnya, nilai metrik yang digunakan untuk memberi tahu berubah secara tiba-tiba hanya ketika terjadi masalah dalam sistem, tetapi selama operasi normal nilai tersebut tetap tidak berubah. Di sisi lain, persyaratan ini tidak diberlakukan pada metrik debug - persyaratan ini harus memberikan gambaran tentang apa yang terjadi saat peringatan dipicu. Metrik debug yang baik akan menunjukkan bagian sistem yang berpotensi bermasalah. Saat menulis postmortem, pertimbangkan metrik tambahan apa yang memungkinkan Anda mendiagnosis masalah lebih cepat.
Menguji logika peringatan
Dalam dunia yang ideal, kode pemantauan dan peringatan harus mengikuti standar pengujian yang sama seperti kode pengembangan. Saat ini tidak ada sistem yang diterima secara luas yang memungkinkan Anda menerapkan konsep seperti itu. Salah satu tanda pertama adalah fungsionalitas pengujian unit aturan yang baru ditambahkan ke Prometheus.
Di Google, kami menguji sistem pemantauan dan peringatan kami menggunakan bahasa khusus domain yang memungkinkan kami membuat deret waktu sintetis. Kami kemudian memeriksa nilai dalam deret waktu turunan, atau kami mengklarifikasi apakah lansiran tertentu telah diaktifkan dan memiliki label yang diperlukan.
Memantau dan mengeluarkan peringatan sering kali merupakan proses multi-langkah, sehingga diperlukan beberapa unit tes.
Meskipun area ini sebagian besar masih belum berkembang, jika Anda ingin menerapkan pengujian pemantauan di beberapa titik, kami merekomendasikan pendekatan tiga tingkat, seperti yang ditunjukkan pada Gambar 1. 4.1.
- File biner. Pastikan variabel metrik yang diekspor mengubah nilai seperti yang diharapkan dalam kondisi tertentu.
- Pemantauan infrastruktur. Pastikan bahwa aturan diikuti dan kondisi spesifik adalah peringatan yang diharapkan.
- Manajer peringatan. Verifikasikan bahwa pemberitahuan yang dihasilkan diarahkan ke tujuan yang telah ditentukan berdasarkan nilai label.
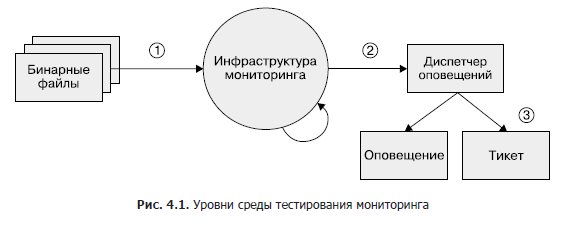
Jika Anda tidak dapat menguji sistem pemantauan Anda dengan alat sintetis, atau jika suatu langkah tidak dapat diuji sama sekali, pertimbangkan untuk membuat sistem produksi yang mengekspor metrik yang diketahui seperti permintaan dan kesalahan. Anda dapat menggunakan sistem ini untuk memeriksa deret waktu dan peringatan. Tampaknya aturan lansiran Anda tidak akan aktif selama berbulan-bulan atau bertahun-tahun setelah Anda menyiapkannya, dan Anda perlu memastikan bahwa saat metrik melewati ambang tertentu, lansiran tetap bermakna dan dikirimkan kepada teknisi yang dituju.
Ringkasan Bab
Karena insinyur SR harus bertanggung jawab atas keandalan sistem produksi, spesialis ini sering kali diminta untuk memahami sistem pemantauan dan fungsinya serta berinteraksi secara dekat dengannya. Tanpa data ini, SRE mungkin tidak tahu ke mana harus mencari dan bagaimana mengidentifikasi perilaku sistem yang tidak normal atau bagaimana menemukan informasi yang mereka butuhkan selama keadaan darurat.
Kami berharap dengan menunjukkan fungsi sistem pemantauan yang bermanfaat dari sudut pandang kami dan membenarkan pilihan kami, kami dapat membantu Anda menilai bagaimana sistem pemantauan Anda memenuhi kebutuhan Anda. Selain itu, kami akan membantu Anda menjelajahi beberapa fitur tambahan yang dapat Anda gunakan dan meninjau perubahan yang mungkin ingin Anda lakukan. Anda kemungkinan besar akan merasa berguna untuk menggabungkan sumber metrik dan log dalam strategi pemantauan Anda. Campuran metrik dan log yang tepat sangat bergantung pada konteks.
Pastikan untuk mengumpulkan metrik yang memiliki tujuan tertentu. Ini adalah tujuan seperti meningkatkan penjadwalan bandwidth, debugging, atau masalah pelaporan yang muncul.
Jika Anda memiliki pemantauan, itu harus visual dan berguna. Untuk melakukan ini, kami sarankan untuk menguji pengaturannya. Sistem pemantauan yang baik membayar dividen. Perencanaan awal yang menyeluruh tentang solusi yang akan digunakan untuk memenuhi kebutuhan spesifik Anda dengan sebaik-baiknya, serta perbaikan berulang yang berkelanjutan pada sistem pemantauan, merupakan investasi yang akan membuahkan hasil.
»Rincian lebih lanjut tentang buku dapat ditemukan di situs web penerbit
» Daftar Isi
» Kutipan
Untuk Habitants diskon 25% untuk kupon - Google
Setelah pembayaran untuk versi kertas buku, sebuah e-book dikirim ke email.