Faktanya adalah bahwa semua tim kami dibangun di sekitar sistem informasi, layanan mikro, dan front yang terpisah, sehingga tim tidak melihat kesehatan keseluruhan sistem secara keseluruhan. Misalnya, mereka mungkin tidak tahu bagaimana bagian kecil di bagian belakang yang dalam memengaruhi bagian depan. Kisaran kepentingan mereka terbatas pada sistem yang terintegrasi dengan sistem mereka. Jika tim dan layanannya A hampir tidak ada hubungannya dengan layanan B, maka layanan seperti itu hampir tidak terlihat oleh tim.
Tim kami, pada gilirannya, bekerja dengan sistem yang sangat terintegrasi satu sama lain: ada banyak koneksi di antara mereka, ini adalah infrastruktur yang sangat besar. Dan pekerjaan toko online bergantung pada semua sistem ini (omong-omong, kami memiliki jumlah yang sangat besar).
Jadi ternyata departemen kita bukan milik tim manapun, tapi agak menyendiri. Sepanjang cerita ini, tugas kita adalah untuk memahami secara kompleks bagaimana sistem informasi bekerja, fungsinya, integrasi, perangkat lunak, jaringan, perangkat keras, dan bagaimana semua ini saling berhubungan.
Platform tempat toko online kami beroperasi terlihat seperti ini:
- depan
- kantor Tengah
- back-office
Sebanyak yang kami inginkan, tetapi tidak ada hal yang membuat semua sistem bekerja dengan lancar dan sempurna. Intinya, sekali lagi, adalah jumlah sistem dan integrasi - seperti yang kami miliki, beberapa insiden tidak dapat dihindari, terlepas dari kualitas pengujiannya. Apalagi baik dalam sistem tersendiri maupun dalam hal integrasinya. Dan Anda perlu memantau status seluruh platform secara komprehensif, dan bukan bagian yang terpisah darinya.
Idealnya, pemantauan kesehatan seluruh platform harus dilakukan secara otomatis. Dan kami sampai pada pemantauan sebagai bagian yang tak terhindarkan dari proses ini. Awalnya, itu dibangun hanya untuk bagian depan, sementara penggiat jaringan, administrator perangkat lunak dan perangkat keras memiliki sistem pemantauan mereka sendiri berdasarkan lapisan. Semua orang ini mengikuti pemantauan hanya di tingkat mereka sendiri; tidak ada yang memiliki pemahaman yang komprehensif juga.
Misalnya, jika mesin virtual rusak, dalam banyak kasus hanya administrator yang bertanggung jawab atas perangkat keras dan mesin virtual yang tahu tentang itu. Dalam kasus seperti itu, tim depan melihat fakta sebenarnya dari aplikasi yang mogok, tetapi mereka tidak memiliki data tentang kerusakan mesin virtual. Dan administrator dapat mengetahui siapa pelanggan tersebut, dan secara kasar membayangkan apa yang sedang berjalan di mesin virtual ini sekarang, asalkan ini adalah semacam proyek besar. Dia mungkin tidak tahu tentang anak kecil. Bagaimanapun, administrator harus pergi ke pemilik, menanyakan apa yang ada di mesin ini, apa yang perlu dipulihkan dan apa yang harus diubah. Dan jika sesuatu yang sangat serius rusak, mereka mulai berputar-putar - karena tidak ada yang melihat sistem secara keseluruhan.
Pada akhirnya, cerita yang berbeda ini memengaruhi seluruh front-end, pengguna, dan fungsi bisnis inti kami, penjualan online. Karena kami bukan bagian dari tim, tetapi terlibat dalam pengoperasian semua aplikasi e-niaga sebagai bagian dari toko online, kami mengambil tugas untuk membuat sistem pemantauan terintegrasi untuk platform e-niaga.
Struktur dan tumpukan sistem
Kami mulai dengan mengidentifikasi beberapa lapisan pemantauan untuk sistem kami, yang dalam konteksnya kami perlu mengumpulkan metrik. Dan semua ini harus digabungkan, yang kami lakukan pada tahap pertama. Sekarang, pada tahap ini, kami menyelesaikan kumpulan metrik kualitas tertinggi untuk semua lapisan kami untuk membangun korelasi dan memahami bagaimana sistem saling mempengaruhi.
Kurangnya pemantauan yang komprehensif pada tahap awal peluncuran aplikasi (sejak kami mulai membangunnya ketika sebagian besar sistem beroperasi) menyebabkan fakta bahwa kami memiliki hutang teknis yang signifikan untuk menyiapkan pemantauan seluruh platform. Kami tidak dapat fokus pada pengaturan pemantauan satu IS dan untuk melakukan pemantauan secara detail, karena sistem lainnya akan tetap tanpa pemantauan selama beberapa waktu. Untuk mengatasi masalah ini, kami telah mengidentifikasi daftar metrik yang paling diperlukan untuk menilai keadaan sistem informasi berdasarkan lapisan dan mulai menerapkannya.
Karena itu, mereka memutuskan untuk memakan gajah tersebut sebagian.
Sistem kami terdiri dari:
- perangkat keras;
- sistem operasi;
- perangkat lunak;
- Bagian UI dalam aplikasi pemantauan;
- metrik bisnis;
- aplikasi integrasi;
- informasi keamanan;
- jaringan;
- penyeimbang lalu lintas.
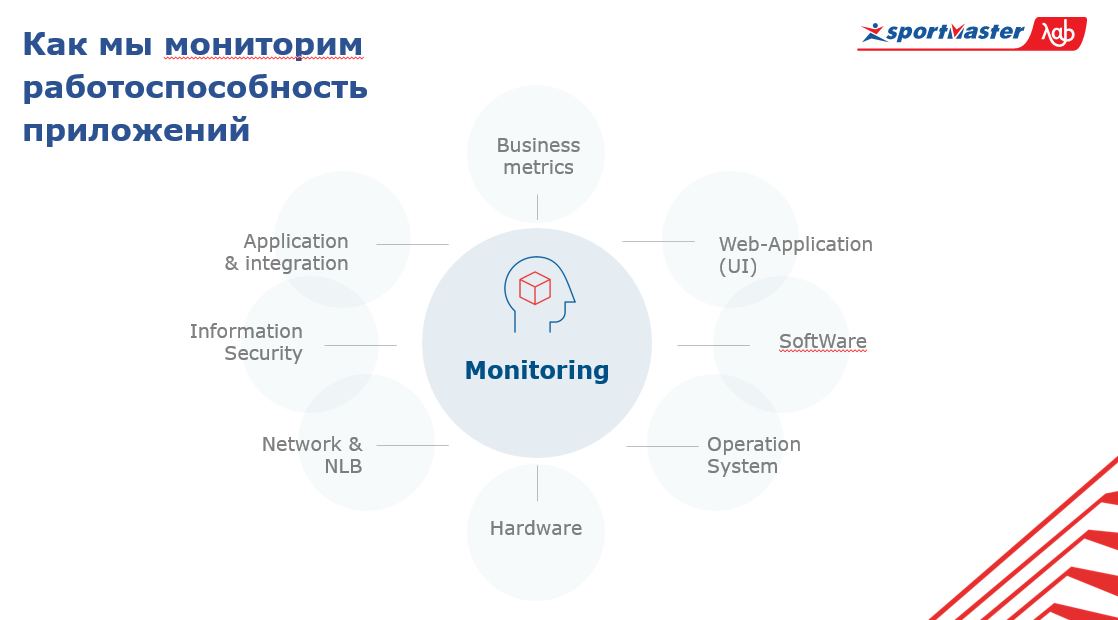
Pusat dari sistem ini adalah pemantauan itu sendiri. Untuk memahami keadaan seluruh sistem secara umum, Anda perlu mengetahui apa yang terjadi dengan aplikasi pada semua lapisan ini dan dalam konteks seluruh rangkaian aplikasi.
Jadi, tentang tumpukan.

Kami menggunakan perangkat lunak open source. Di pusat kami memiliki Zabbix, yang kami gunakan terutama sebagai sistem peringatan. Semua orang tahu bahwa ini ideal untuk memantau infrastruktur. Apa artinya ini? Ini adalah metrik tingkat sangat rendah yang dimiliki setiap perusahaan yang memiliki pusat datanya sendiri (dan Sportmaster memiliki pusat datanya sendiri) - suhu server, status memori, serangan, metrik perangkat jaringan.
Kami telah mengintegrasikan Zabbix dengan Telegram messenger dan Microsoft Teams, yang secara aktif digunakan dalam tim. Zabbix mencakup lapisan jaringan aktual, perangkat keras, dan sebagian perangkat lunak, tetapi ini bukan obat mujarab. Kami memperkaya data ini dari beberapa layanan lain. Misalnya, dalam hal tingkat perangkat keras, kami terhubung langsung melalui API ke sistem virtualisasi kami dan mengumpulkan data.
Apa lagi. Selain Zabbix, kami menggunakan Prometheus, yang memungkinkan metrik pemantauan dalam aplikasi lingkungan dinamis. Artinya, kami dapat menerima metrik aplikasi melalui titik akhir HTTP dan tidak khawatir tentang metrik mana yang akan dimuat ke dalamnya dan mana yang tidak. Berdasarkan data ini, Anda bisa mengerjakan kueri analitik.
Sumber data untuk lapisan lain, misalnya metrik bisnis, dibagi menjadi tiga komponen.
Pertama, ini adalah sistem bisnis eksternal, Google Analytics, kami mengumpulkan metrik dari log. Dari mereka kami mendapatkan data tentang pengguna aktif, konversi, dan segala sesuatu yang terkait dengan bisnis. Kedua, ini adalah sistem pemantauan UI. Ini harus dijelaskan lebih detail.
Sekali waktu, kami mulai dengan pengujian manual, dan itu telah berkembang menjadi pengujian otomatis fungsional dan integrasi. Kami memantaunya, hanya menyisakan fungsionalitas utama, dan terikat pada marker yang seestabil mungkin dan tidak sering berubah seiring waktu.
Struktur tim yang baru menyiratkan bahwa semua aktivitas aplikasi dikunci ke dalam tim produk, jadi kami berhenti melakukan pengujian murni. Sebagai gantinya, kami membuat pemantauan UI dari pengujian, yang ditulis di Java, Selenium, dan Jenkins (digunakan sebagai sistem untuk meluncurkan dan menghasilkan laporan).
Kami menjalani banyak pengujian, tetapi pada akhirnya kami memutuskan untuk pergi ke jalan utama, metrik tingkat atas. Dan jika kita memiliki banyak tes khusus, akan sulit untuk memperbarui datanya. Setiap rilis berikutnya akan merusak seluruh sistem secara signifikan, dan kami hanya akan memperbaikinya. Oleh karena itu, kami terikat pada hal-hal yang sangat mendasar yang jarang berubah, dan hanya memantaunya.
Terakhir, ketiga, sumber data adalah sistem pencatatan terpusat. Untuk log, kami menggunakan Elastic Stack, lalu kami dapat menyeret data ini ke sistem pemantauan kami untuk metrik bisnis. Selain semua ini, layanan API Pemantauan kami sendiri, yang ditulis dengan Python, berfungsi, yang mengumpulkan semua layanan melalui API dan mengambil data dari mereka ke Zabbix.
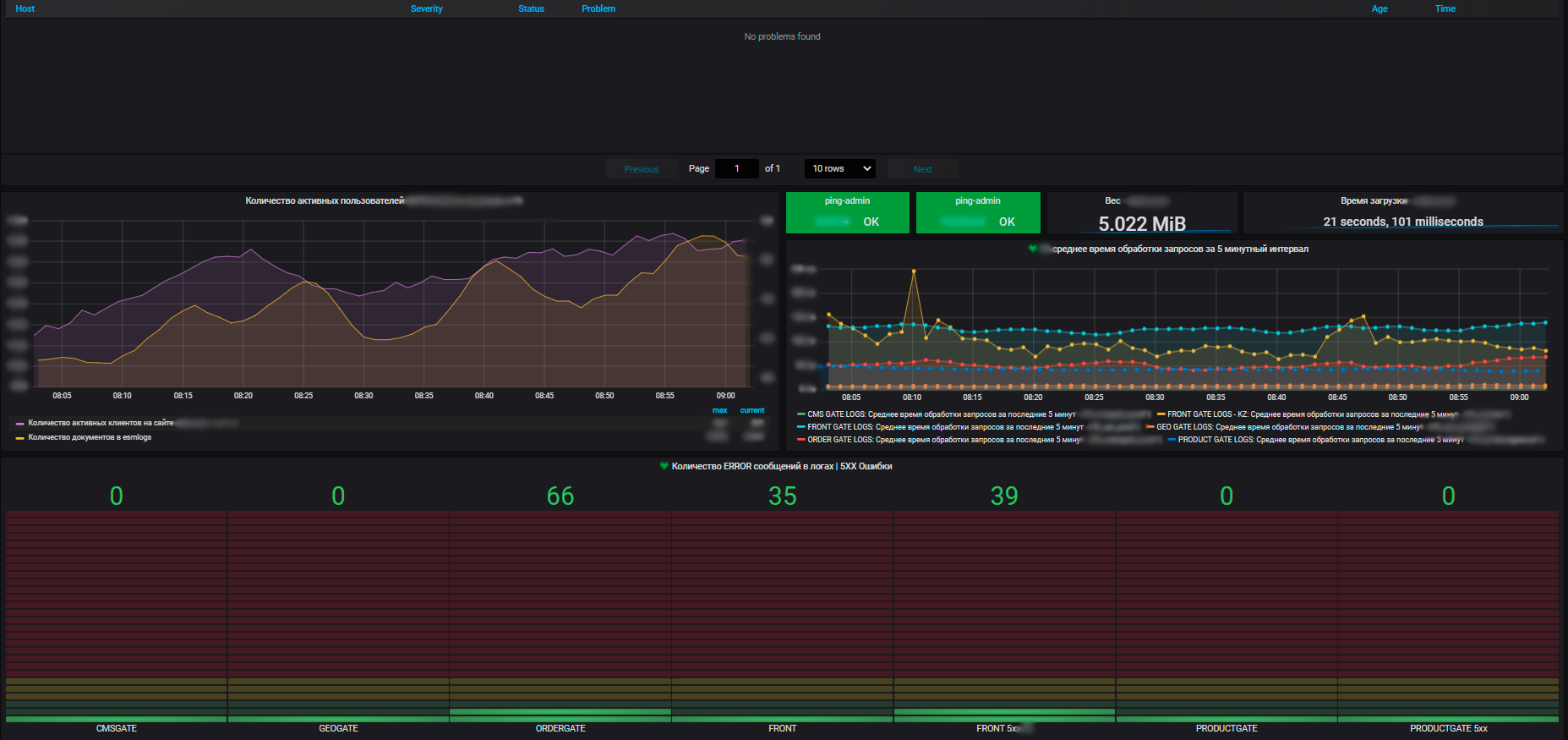
Atribut pemantauan tak tergantikan lainnya adalah visualisasi. Kami membangunnya atas dasar Grafana. Di antara sistem visualisasi lainnya, itu menonjol karena dimungkinkan untuk memvisualisasikan metrik dari berbagai sumber data di dasbor. Kami dapat mengumpulkan metrik tingkat atas dari toko online, misalnya, jumlah pesanan yang dilakukan dalam satu jam terakhir dari DBMS, metrik kinerja OS yang menjalankan toko online ini dari Zabbix, dan metrik contoh aplikasi ini dari Prometheus. Dan semua ini akan ada di satu dasbor. Visual dan dapat diakses.
Izinkan saya mencatat tentang keamanan - kami sekarang sedang menyelesaikan sistem, yang selanjutnya akan kami integrasikan dengan sistem pemantauan global. Menurut saya, masalah utama yang dihadapi e-commerce di bidang keamanan informasi terkait dengan bot, parser dan brute-force. Ini harus dipantau karena semuanya dapat sangat memengaruhi kinerja aplikasi kita dan reputasi dari sudut pandang bisnis. Dan dengan tumpukan yang dipilih, kami berhasil menangani tugas-tugas ini.
Poin penting lainnya adalah bahwa lapisan aplikasi dikumpulkan oleh Prometheus. Ia sendiri juga terintegrasi dengan Zabbix. Dan kami juga memiliki kecepatan situs, layanan yang memungkinkan kami untuk melihat parameter seperti kecepatan memuat halaman, kemacetan, rendering halaman, memuat skrip, dll., Itu juga terintegrasi melalui API. Jadi metrik dikumpulkan di Zabbix, masing-masing, kami juga waspada dari sana. Semua peringatan sejauh ini masuk ke metode pengiriman utama (untuk saat ini, ini adalah email dan telegram, mereka baru-baru ini menghubungkan MS Teams). Rencananya adalah untuk memompa peringatan ke keadaan sedemikian rupa sehingga bot pintar berfungsi sebagai layanan dan memberikan informasi pemantauan kepada semua tim produk yang tertarik.
Bagi kami, tidak hanya metrik dari sistem informasi individual yang penting, tetapi juga metrik umum untuk seluruh infrastruktur yang digunakan aplikasi: cluster server fisik yang menjalankan mesin virtual, penyeimbang lalu lintas, Network Load Balancers, jaringan itu sendiri, pemanfaatan saluran komunikasi. Plus metrik untuk pusat data kami sendiri (kami memiliki beberapa di antaranya dan infrastrukturnya cukup signifikan).
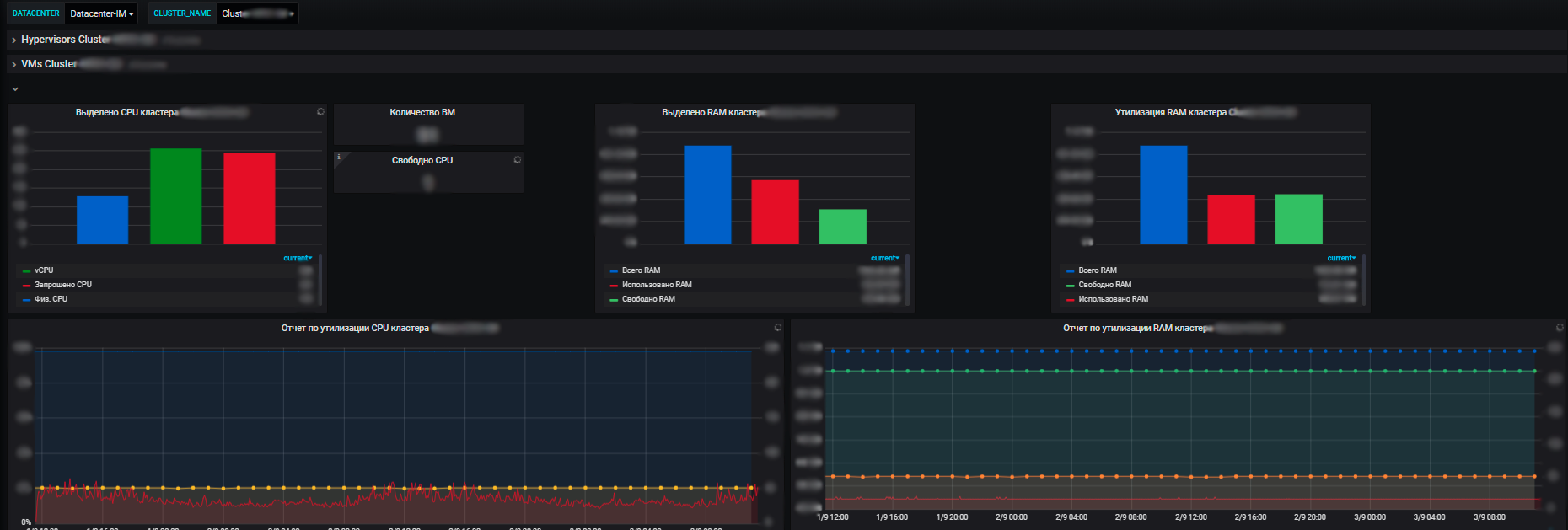
Keuntungan dari sistem pemantauan kami adalah dengan bantuannya kami melihat keadaan kesehatan semua sistem, kami dapat menilai dampaknya satu sama lain dan pada sumber daya bersama. Dan pada akhirnya, memungkinkan perencanaan sumber daya, yang juga merupakan tanggung jawab kami. Kami mengelola sumber daya server - kumpulan dalam kerangka perdagangan elektronik, memperkenalkan dan menonaktifkan peralatan baru, membeli peralatan baru, melakukan audit penggunaan sumber daya, dan sebagainya. Setiap tahun tim merencanakan proyek baru, mengembangkan sistem mereka, dan penting bagi kami untuk menyediakan sumber daya bagi mereka.
Dan dengan bantuan metrik, kami melihat tren konsumsi sumber daya oleh sistem informasi kami. Dan atas dasar mereka kita dapat merencanakan sesuatu. Di tingkat virtualisasi, kami mengumpulkan data dan melihat informasi tentang jumlah sumber daya yang tersedia dalam konteks pusat data. Dan sudah di dalam pusat data, Anda dapat melihat pemanfaatan, dan distribusi aktual, konsumsi sumber daya. Selain itu, keduanya dengan server mandiri, dan mesin virtual serta kelompok server fisik, tempat semua mesin virtual ini berputar dengan penuh semangat.
Perspektif
Sekarang kita memiliki inti dari sistem secara keseluruhan yang siap, tetapi masih ada cukup poin yang tersisa untuk dikerjakan. Setidaknya ini adalah lapisan keamanan informasi, tetapi juga penting untuk mengakses jaringan, mengembangkan peringatan, dan menyelesaikan masalah dengan korelasi. Kami memiliki banyak lapisan dan sistem, ada lebih banyak metrik di setiap lapisan. Ternyata matryoshka setingkat dengan matryoshka.
Tugas kita pada akhirnya adalah membuat peringatan yang tepat. Misalnya, jika ada masalah dengan perangkat keras, sekali lagi, dengan mesin virtual, dan ada aplikasi penting, dan layanan tidak dicadangkan dengan cara apa pun. Kami menemukan bahwa mesin virtual telah mati. Kemudian mereka akan memberi tahu metrik bisnis: pengguna telah menghilang di suatu tempat, tidak ada konversi, antarmuka antarmuka tidak tersedia, perangkat lunak dan layanan juga mati.
Dalam situasi ini, kami akan menerima spam dari lansiran, dan ini tidak lagi sesuai dengan format sistem pemantauan yang benar. Pertanyaan tentang korelasi muncul. Oleh karena itu, idealnya, sistem pemantauan kami harus mengatakan: "Teman-teman, mesin fisik Anda telah mati, dan bersamaan dengan itu aplikasi ini dan metrik semacam itu", dengan bantuan satu peringatan alih-alih membombardir kami dengan ratusan peringatan. Dia harus melaporkan hal utama - alasannya, yang berkontribusi pada ketepatan eliminasi masalah karena lokalisasi.
Sistem penanganan pemberitahuan dan peringatan kami dibangun dengan layanan hotline 24/7. Semua peringatan yang dianggap harus dimiliki oleh kami dan termasuk dalam daftar periksa dikirim ke sana. Setiap peringatan harus memiliki deskripsi: apa yang terjadi, apa artinya sebenarnya, apa pengaruhnya. Dan juga tautan ke dasbor dan instruksi tentang apa yang harus dilakukan dalam kasus ini.
Itu saja untuk kebutuhan pembangunan alert. Selanjutnya, situasi dapat berkembang ke dua arah - apakah ada masalah dan perlu diselesaikan, atau ada kegagalan dalam sistem pemantauan. Tetapi bagaimanapun juga, Anda harus pergi dan mencari tahu.
Rata-rata, sekitar seratus lansiran jatuh kepada kami setiap hari sekarang, hal ini memperhitungkan fakta bahwa korelasi lansiran belum dikonfigurasi dengan benar. Dan jika kami perlu melakukan pekerjaan teknis, dan kami secara paksa mematikan sesuatu, jumlahnya bertambah secara signifikan.
Selain memantau sistem yang kami operasikan dan mengumpulkan metrik yang dianggap penting di pihak kami, sistem pemantauan memungkinkan kami mengumpulkan data untuk tim produk. Mereka dapat memengaruhi komposisi metrik dalam sistem informasi yang dipantau di perusahaan kami.
Rekan kami dapat datang dan meminta untuk menambahkan beberapa metrik yang akan berguna bagi kami dan tim. Atau, misalnya, tim mungkin tidak memiliki cukup metrik dasar yang kami miliki, mereka perlu melacak beberapa metrik tertentu. Di Grafana, kami membuat ruang untuk setiap tim dan mengeluarkan hak admin. Juga, jika sebuah tim membutuhkan dasbor, tetapi mereka sendiri tidak dapat / tidak tahu bagaimana melakukannya, kami membantu mereka.
Karena kami berada di luar aliran penciptaan nilai tim, rilis dan perencanaan mereka, kami secara bertahap sampai pada kesimpulan bahwa rilis semua sistem berjalan mulus dan dapat diluncurkan setiap hari, tanpa berkoordinasi dengan kami. Dan penting bagi kami untuk melacak rilis ini, karena rilis tersebut berpotensi memengaruhi pengoperasian aplikasi dan merusak sesuatu, dan ini sangat penting. Untuk mengelola rilis, kami menggunakan Bamboo, dari mana kami mendapatkan data melalui API dan dapat melihat rilis mana yang keluar dari sistem informasi dan statusnya. Dan yang terpenting adalah jam berapa. Kami menempatkan penanda rilis pada metrik kritis utama, yang secara visual sangat indikatif jika terjadi masalah.
Dengan cara ini kita dapat melihat korelasi antara rilis baru dan masalah yang muncul. Ide utamanya adalah memahami cara kerja sistem pada semua lapisan, dengan cepat melokalkan masalah dan memperbaikinya dengan cepat. Memang sering terjadi bahwa sebagian besar waktu dihabiskan bukan untuk menyelesaikan masalah, tetapi mencari penyebabnya.
Dan ke arah ini di masa depan kami ingin fokus pada proaktif. Idealnya, saya ingin tahu sebelumnya tentang masalah yang akan datang, dan bukan setelah fakta, untuk menangani pencegahannya, bukan solusi. Terkadang ada kesalahan positif dari sistem pemantauan, baik karena kesalahan manusia maupun karena perubahan dalam aplikasi. Dan kami sedang mengerjakan ini, men-debug, dan mencoba memperingatkan pengguna tentang hal ini sebelum ada manipulasi pada sistem pemantauan, yang menggunakannya bersama kami. , atau lakukan acara ini di jendela teknis.
Jadi, sistem telah diluncurkan dan telah bekerja dengan sukses sejak awal musim semi ... dan menunjukkan keuntungan yang sangat nyata. Tentu saja, ini bukan versi finalnya, kami akan memperkenalkan lebih banyak fitur yang berguna. Namun saat ini, dengan begitu banyak integrasi dan aplikasi, otomatisasi pemantauan sangat diperlukan.
Jika Anda juga memantau proyek-proyek besar dengan sejumlah integrasi yang serius - tulis di komentar peluru perak apa yang Anda temukan untuk ini.