Batas dan pembatasan CPU
Seperti banyak pengguna Kubernetes lainnya, Google sangat merekomendasikan untuk menyesuaikan batas CPU . Tanpa konfigurasi ini, container di node dapat menggunakan semua daya prosesor, yang pada gilirannya akan menyebabkan proses Kubernetes yang penting (misalnya
kubelet) berhenti merespons permintaan. Jadi, menyetel batas CPU adalah cara yang baik untuk melindungi node Anda.
Batas prosesor menyetel penampung waktu prosesor maksimum yang dapat digunakan untuk periode tertentu (100 md secara default), dan penampung tidak akan pernah melebihi batas ini. Kubernetes menggunakan alat khusus CFS Kuota untuk throttle wadah dan mencegah dari melebihi batas., namun, pada akhirnya, prosesor buatan tersebut membatasi kinerja yang lebih rendah dan meningkatkan waktu respons container Anda.
Apa yang dapat terjadi jika kami tidak menetapkan batas CPU?
Sayangnya, kami sendiri yang harus mengatasi masalah ini. Setiap node memiliki proses yang bertanggung jawab untuk mengelola container
kubelet, dan berhenti merespons permintaan. Node, ketika ini terjadi, akan masuk ke status NotReady, dan kontainer darinya akan dialihkan ke tempat lain dan akan menciptakan masalah yang sama pada node baru. Bukan skenario yang ideal, secara halus.
Mewujudkan masalah pelambatan dan daya tanggap
Metrik utama untuk melacak penampung adalah
trottlingberapa kali penampung Anda dibatasi. Kami memperhatikan dengan penuh minat adanya throttling di beberapa container, terlepas dari apakah beban prosesor maksimal atau tidak. Sebagai contoh, mari kita lihat salah satu API utama kami:
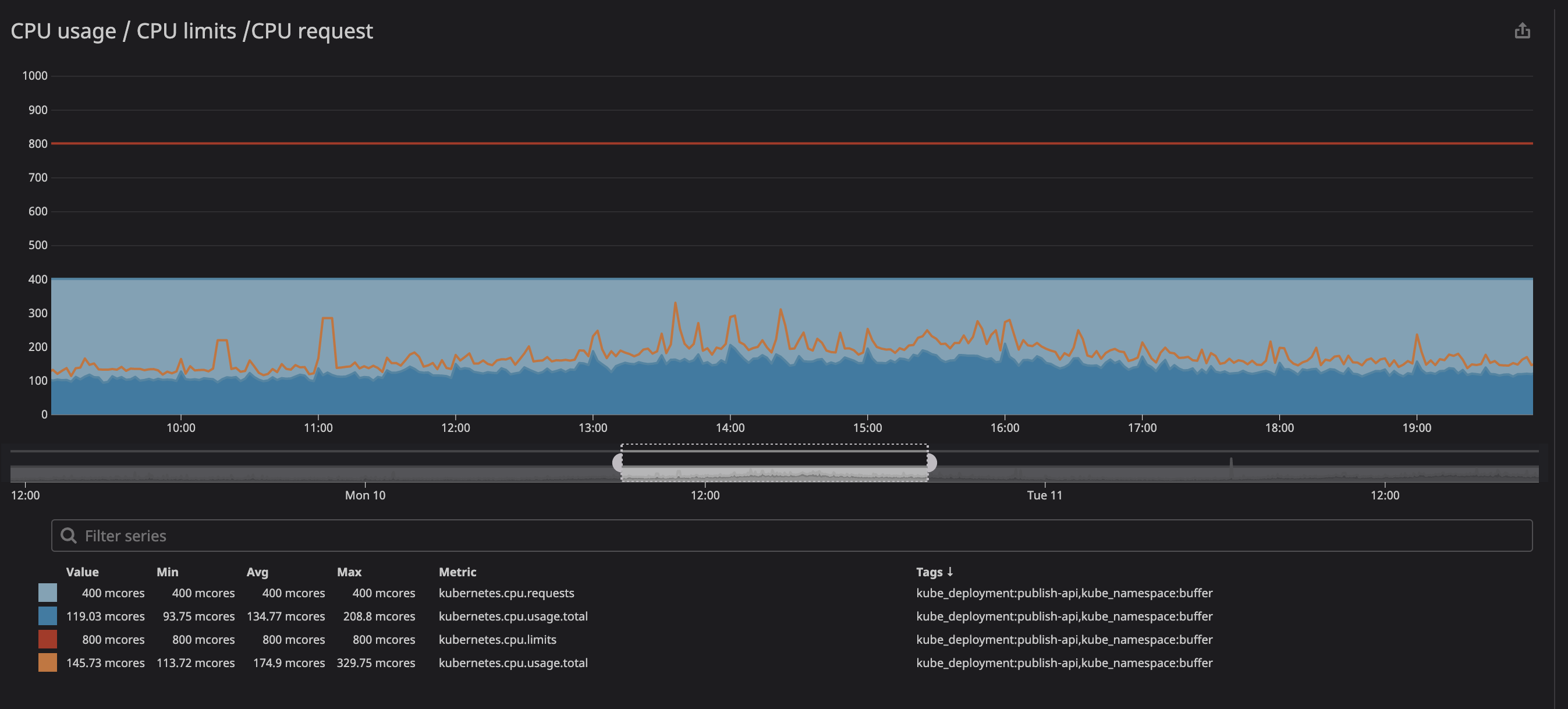
Seperti yang Anda lihat di bawah, kami menetapkan batas pada
800m(0,8 atau 80% dari inti), dan nilai puncak paling baik 200m(20% dari inti). Tampaknya kami masih memiliki banyak daya prosesor sebelum menghentikan layanan, namun ...
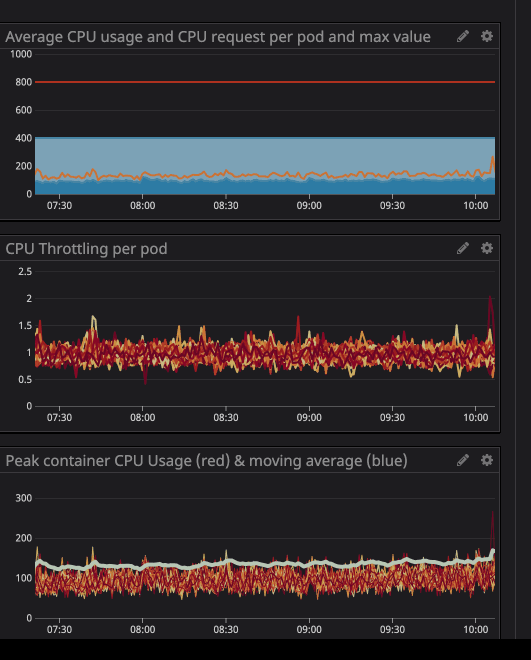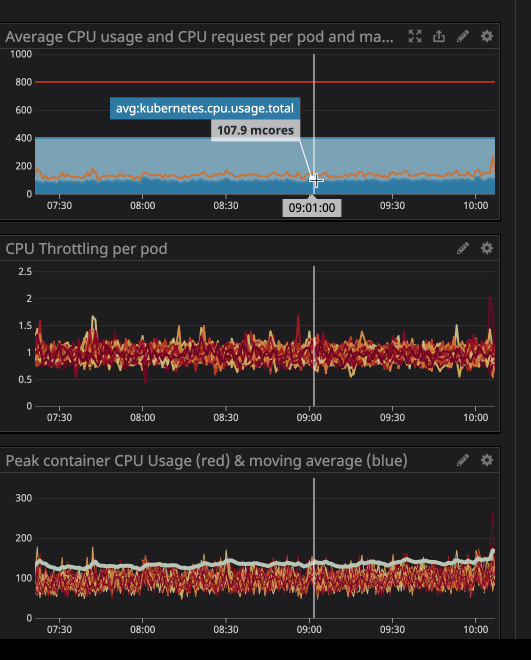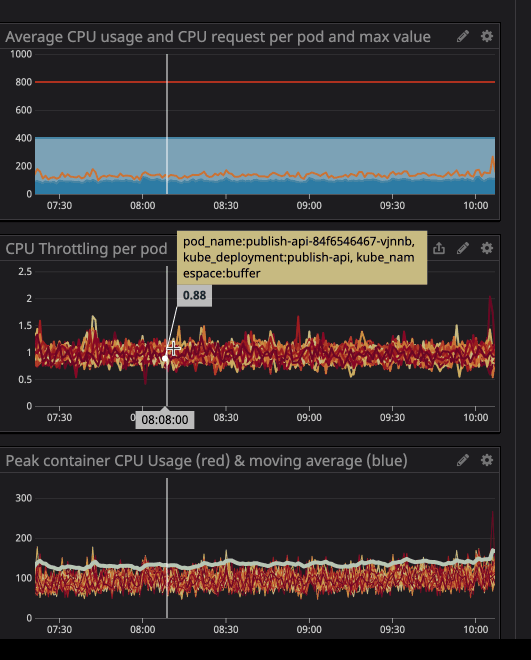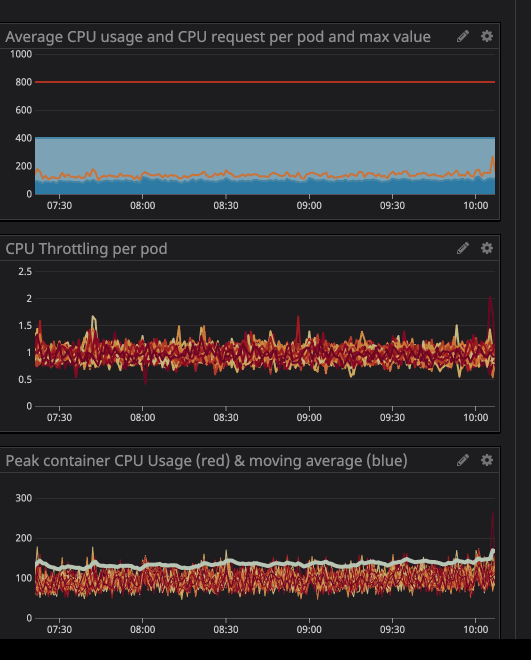
Anda mungkin telah memperhatikan bahwa bahkan ketika beban pada prosesor berada di bawah batas yang ditentukan - pelambatan yang jauh lebih rendah masih berfungsi.
Menghadapi hal ini, kami segera menemukan beberapa sumber ( masalah di github , presentasi di zadano , postingan di omio ) tentang penurunan performa dan waktu respons layanan karena pembatasan.
Mengapa kita melihat pembatasan saat penggunaan CPU rendah? Versi singkatnya berbunyi seperti ini: "Ada bug di kernel Linux yang memicu pelambatan kontainer yang tidak perlu dengan batas prosesor yang ditentukan." Jika Anda tertarik dengan sifat masalahnya, Anda dapat membaca presentasi ( video dan teks varian) oleh Dave Chiluk.
Menghapus batas prosesor (dengan sangat hati-hati)
Setelah berdiskusi panjang lebar, kami memutuskan untuk menghapus batasan prosesor dari semua layanan yang secara langsung atau tidak langsung memengaruhi fungsionalitas penting bagi pengguna kami.
Keputusan tersebut ternyata sulit, karena kami sangat menghargai stabilitas cluster kami. Di masa lalu, kami telah bereksperimen dengan ketidakstabilan cluster kami, dan kemudian layanan menghabiskan terlalu banyak sumber daya dan memperlambat kerja seluruh node kami. Sekarang semuanya sedikit berbeda: kami memiliki pemahaman yang jelas tentang apa yang kami harapkan dari cluster kami, serta strategi yang baik untuk menerapkan perubahan yang direncanakan.

Korespondensi bisnis tentang masalah mendesak.
Bagaimana cara melindungi node Anda saat menghapus batasan?
Mengisolasi layanan "tidak terbatas":
Di masa lalu, kami telah melihat beberapa node menjadi status
notReady, terutama karena layanan yang menghabiskan terlalu banyak sumber daya.
Kami memutuskan untuk menempatkan layanan tersebut di node ("tagged") yang terpisah sehingga mereka tidak akan mengganggu layanan "tertaut". Akibatnya, dengan menandai beberapa node dan menambahkan parameter toleransi ke layanan "tidak terkait", kami memperoleh lebih banyak kontrol atas cluster, dan menjadi lebih mudah bagi kami untuk mengidentifikasi masalah dengan node. Untuk melakukan proses serupa sendiri, Anda dapat membiasakan diri dengan dokumentasi .
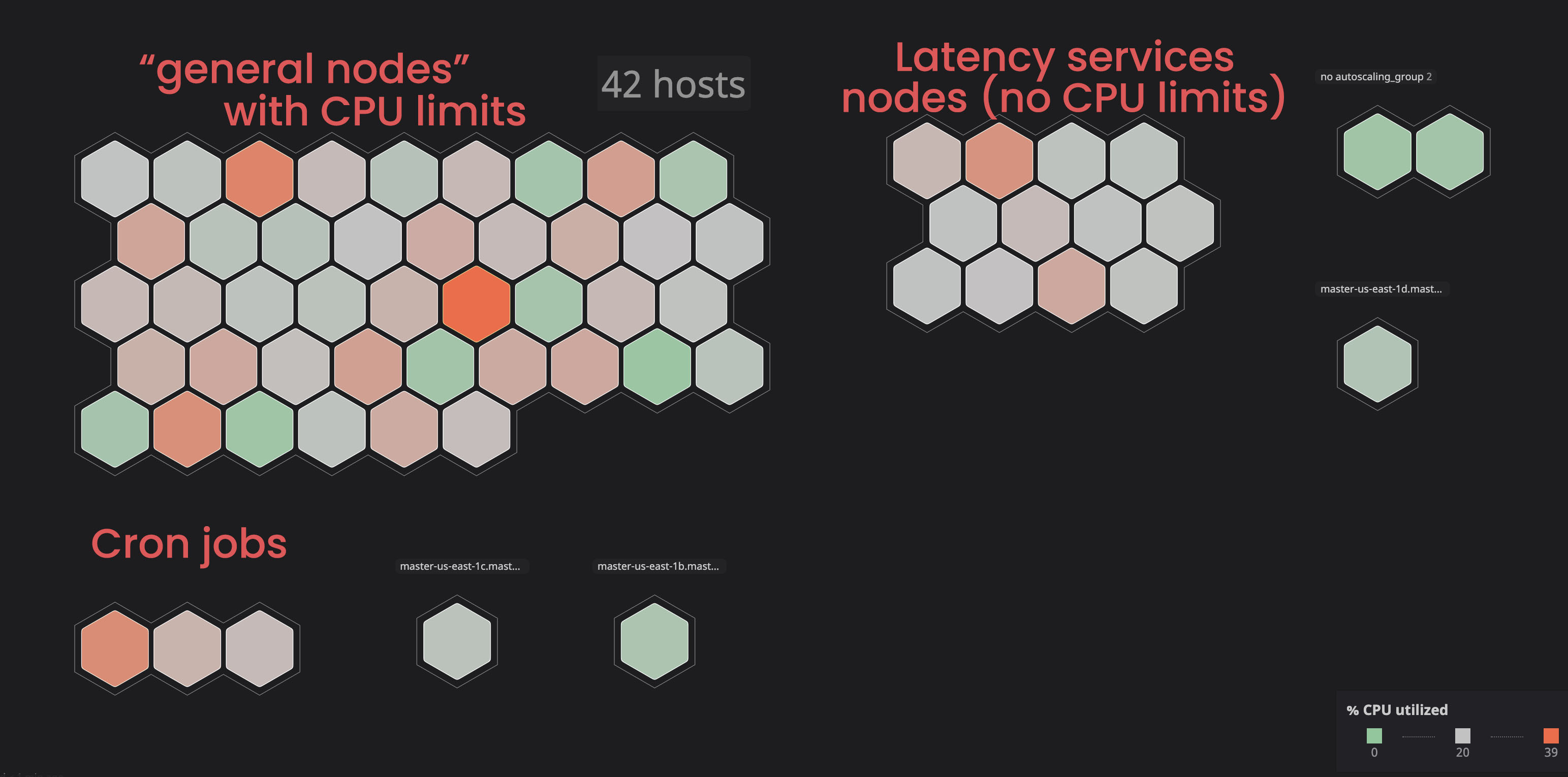
Menetapkan prosesor dan permintaan memori yang benar:
Yang terpenting, kami khawatir proses tersebut akan menghabiskan terlalu banyak sumber daya dan node akan berhenti merespons permintaan. Sejak sekarang (berkat Datadog) kami dapat dengan jelas mengamati semua layanan di cluster kami, saya menganalisis beberapa bulan pengoperasian yang kami rencanakan untuk ditetapkan sebagai "tidak terkait". Saya cukup mengatur pemanfaatan CPU maksimum dengan margin 20%, dan dengan demikian mengalokasikan ruang di node jika k8s mencoba untuk menetapkan layanan lain ke node.
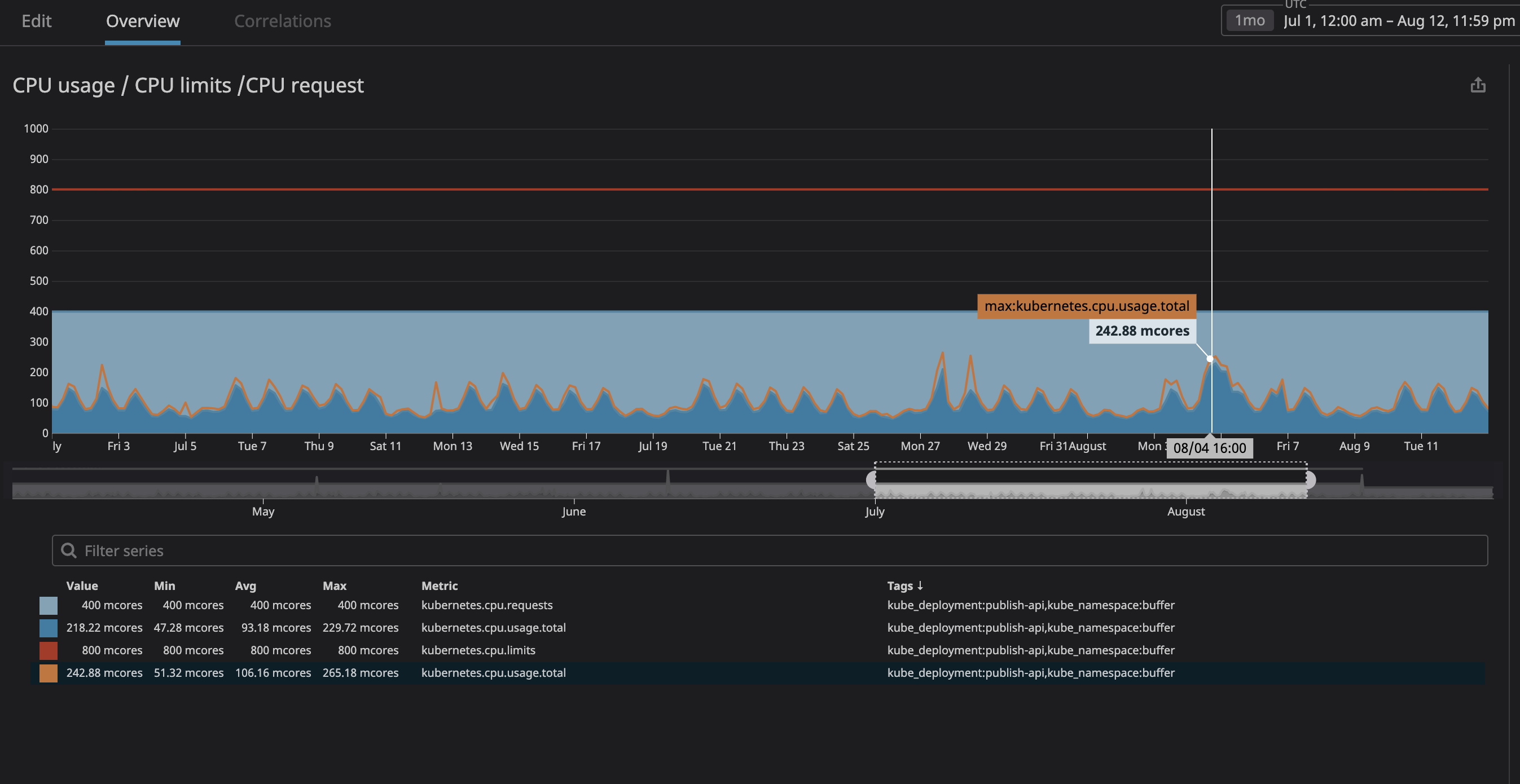
Seperti yang Anda lihat di grafik, beban prosesor maksimum telah mencapai
242minti CPU (0,242 inti prosesor). Untuk permintaan prosesor, cukup mengambil angka yang sedikit lebih besar dari nilai ini. Perhatikan bahwa karena layanan berpusat pada pengguna, puncak beban bertepatan dengan lalu lintas.
Lakukan hal yang sama dengan penggunaan memori dan kueri, dan voila - Anda sudah siap! Agar lebih aman, Anda dapat menambahkan penskalaan otomatis horizontal pada pod. Jadi, setiap kali beban pada resource tinggi, autoscaling akan membuat pod baru, dan kubernetes akan mendistribusikannya ke node dengan ruang kosong. Jika tidak ada ruang tersisa di cluster itu sendiri, Anda dapat menyetel sendiri peringatan atau mengonfigurasi penambahan node baru melalui penskalaan otomatisnya.
Dari minus tersebut, perlu dicatat bahwa kami telah kehilangan " kepadatan kontainer ", yaitu jumlah kontainer yang bekerja dalam satu node. Kami mungkin juga memiliki banyak "indulgensi" pada kepadatan lalu lintas rendah, dan ada juga kemungkinan bahwa Anda akan mencapai beban prosesor yang tinggi, tetapi penskalaan otomatis node akan membantu dengan yang terakhir.
hasil
Saya senang dapat mempublikasikan hasil eksperimen yang luar biasa ini selama beberapa minggu terakhir, kami telah memperhatikan peningkatan yang signifikan sebagai tanggapan di antara semua layanan yang dimodifikasi:
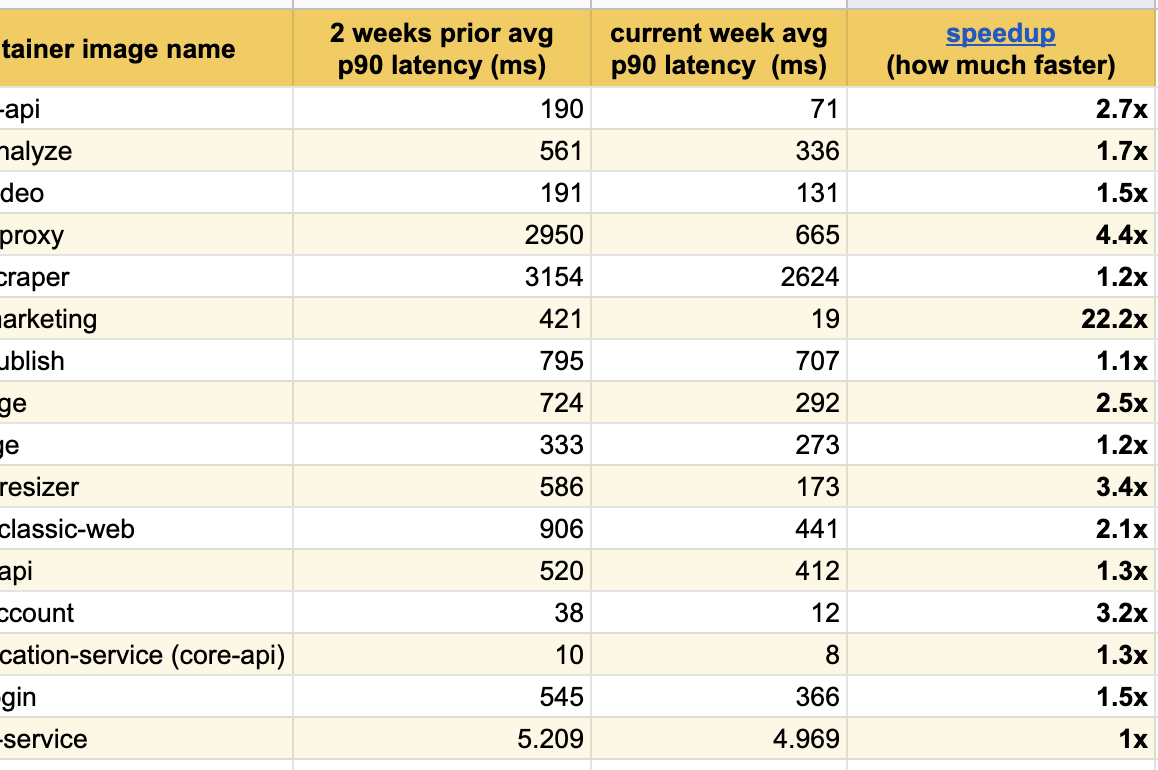
Kami mencapai hasil terbaik di halaman utama kami ( buffer.com ), di sana layanan dua puluh dua kali lebih cepat !
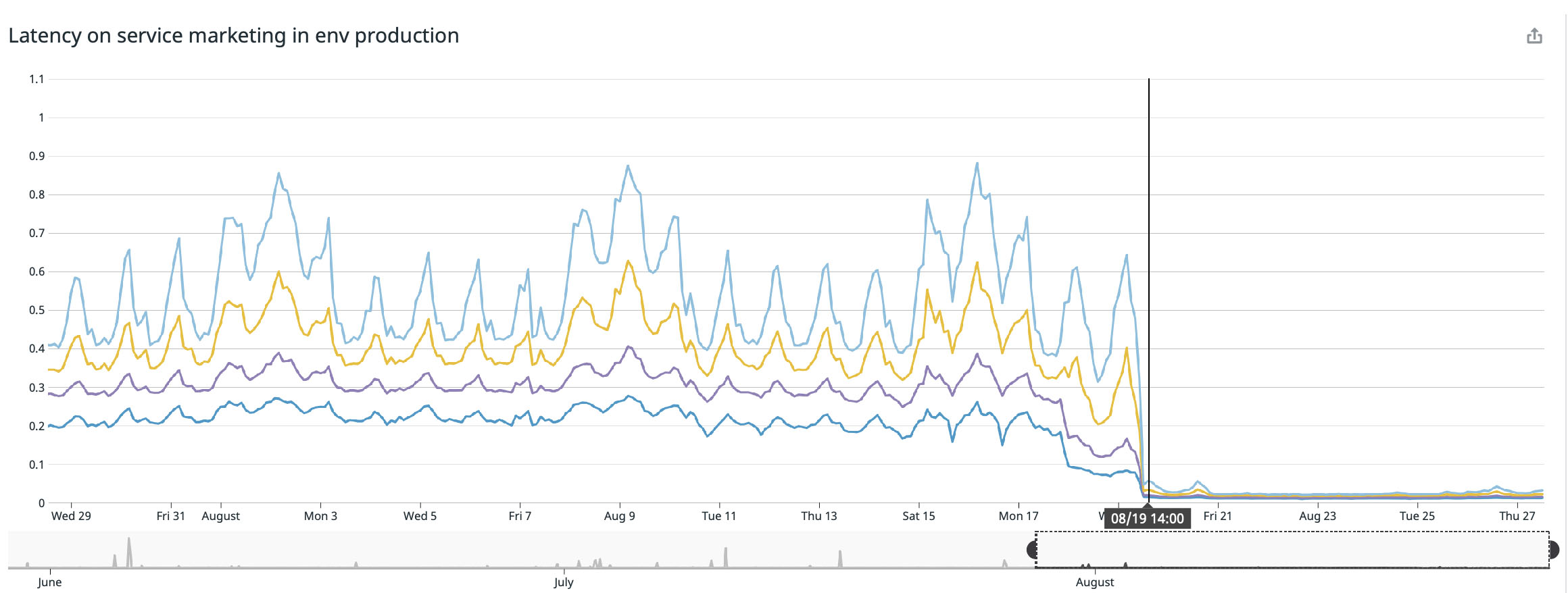
Apakah bug kernel Linux diperbaiki?
Ya, bug telah diperbaiki, dan perbaikan telah ditambahkan ke kernel distribusi versi 4.19 dan yang lebih tinggi.
Namun, saat membaca masalah kubernetes di github untuk 2 September 2020, kami masih menemukan beberapa proyek Linux dengan bug serupa. Saya yakin bahwa beberapa distribusi Linux masih memiliki bug ini dan saat ini sedang memperbaikinya.
Jika versi distribusi Anda lebih rendah dari 4.19, saya akan merekomendasikan untuk memperbarui ke yang terbaru, tetapi Anda harus mencoba menghapus batas prosesor dan melihat apakah pelambatan tetap ada. Di bawah ini Anda dapat menemukan daftar lengkap dari pengelolaan layanan Kubernetes dan distribusi Linux:
- Debian: , buster, ( 2020 ). .
- Ubuntu: Ubuntu Focal Fossa 20.04
- EKS 2019 . , AMI.
- kops: 2020
kops 1.18+Ubuntu 20.04. kops , , , . . - GKE (Google Cloud): 2020 , .
Bagaimana jika perbaikan memperbaiki masalah pelambatan?
Saya tidak yakin apakah masalah telah teratasi sepenuhnya. Ketika kita mendapatkan versi kernel yang diperbaiki, saya akan menguji cluster dan memperbarui posting. Jika seseorang telah memperbarui, saya akan tertarik untuk meninjau hasil Anda.
Kesimpulan
- Jika Anda bekerja dengan kontainer Docker di Linux (tidak peduli Kubernetes, Mesos, Swarm, atau apapun), kontainer Anda bisa kehilangan kinerja karena pelambatan;
- Coba perbarui ke versi terbaru dari distribusi Anda dengan harapan bug telah diperbaiki;
- Menghapus batas prosesor akan menyelesaikan masalah, tetapi ini adalah teknik berbahaya yang harus digunakan dengan sangat hati-hati (lebih baik memperbarui kernel terlebih dahulu dan membandingkan hasilnya);
- Jika Anda menghapus batas prosesor, pantau prosesor dan penggunaan memori Anda dengan hati-hati, dan pastikan bahwa sumber daya prosesor Anda melebihi konsumsi;
- Opsi yang aman adalah melakukan autoscale pod untuk membuat pod baru jika beban tinggi pada perangkat keras, sehingga kubernetes menugaskannya ke node bebas.
Saya harap postingan ini membantu Anda meningkatkan kinerja sistem penampung Anda.
PS Di sini penulis dalam korespondensi dengan pembaca dan komentator (dalam bahasa Inggris).