1.1 Apa itu Pohon Keputusan?
1.1.1 Contoh Pohon Keputusan
Misalnya, kami memiliki kumpulan data berikut (kumpulan tanggal): cuaca, suhu, kelembaban, angin, golf. Tergantung pada cuaca dan yang lainnya, kami pergi (〇) atau tidak (×) bermain golf. Mari kita asumsikan bahwa kita memiliki 14 opsi yang terbentuk sebelumnya.

Dari data ini, kami dapat membuat struktur data yang menunjukkan kasus-kasus apa kami pergi ke golf. Struktur ini disebut Pohon Keputusan karena bentuknya yang bercabang.
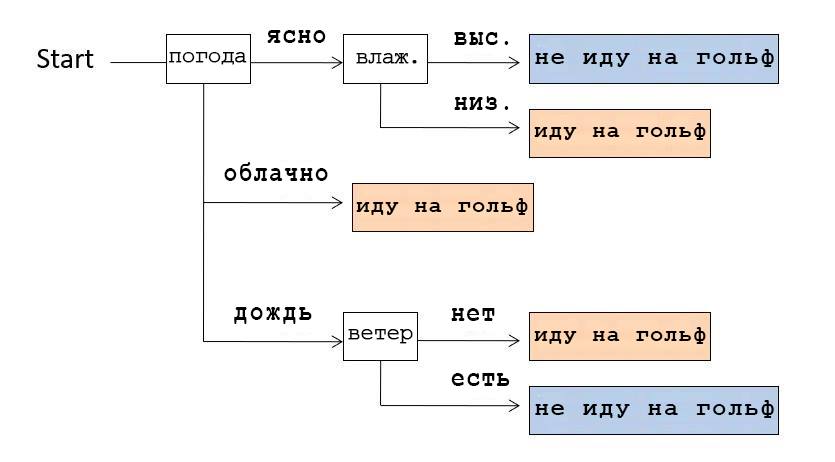
Misalnya, jika kita melihat Pohon Keputusan yang ditunjukkan pada gambar di atas, kita menyadari bahwa kita memeriksa cuaca terlebih dahulu. Jika cerah, kami periksa kelembapannya: jika tinggi, maka kami tidak pergi bermain golf, jika rendah, kami pergi. Dan jika cuaca mendung, maka mereka pergi bermain golf, apapun kondisi lainnya.
1.1.2 Tentang artikel ini
Ada algoritma yang membuat Pohon Keputusan seperti itu secara otomatis berdasarkan data yang tersedia. Pada artikel ini, kami akan menggunakan algoritma ID3 dengan Python.
Artikel ini adalah yang pertama dalam satu seri. Artikel berikut:
(Catatan penerjemah: "jika Anda tertarik dengan sekuelnya, beri tahu kami di komentar.")
- Dasar-dasar Pemrograman Python
- Dasar-dasar pustaka penting untuk analisis data Pandas
- Dasar-dasar struktur data (dalam kasus Pohon Keputusan)
- Dasar-dasar entropi informasi
- Mempelajari algoritme untuk menghasilkan Pohon Keputusan
1.1.3 Sedikit tentang Pohon Keputusan
Pembuatan Pohon Keputusan terkait dengan pembelajaran mesin dan klasifikasi yang diawasi. Klasifikasi dalam pembelajaran mesin adalah cara untuk membuat model yang mengarah ke jawaban yang benar berdasarkan pelatihan pada tanggal yang ditetapkan dengan jawaban dan data yang benar mengarah ke jawaban tersebut. Deep Learning yang sangat populer akhir-akhir ini khususnya di bidang image recognition juga merupakan bagian dari machine learning berdasarkan metode klasifikasi. Perbedaan antara Deep Learning dan Decision Tree adalah apakah hasil akhir direduksi menjadi bentuk di mana seseorang memahami prinsip-prinsip menghasilkan struktur data akhir. Keunikan dari Deep Learning adalah kita mendapatkan hasil akhir, tetapi tidak memahami prinsip pembuatannya. Tidak seperti Pembelajaran Mendalam, Pohon Keputusan mudah dipahami oleh manusia, yang juga merupakan fitur penting.
Fitur Decision Tree ini bagus tidak hanya untuk pembelajaran mesin, tetapi juga untuk penambangan tanggal, di mana pemahaman data oleh pengguna juga penting.
1.2 Tentang algoritma ID3
ID3 adalah algoritma generasi Decision Tree yang dikembangkan pada tahun 1986 oleh Ross Quinlan. Ini memiliki dua fitur penting:
- Kategori data. Data ini mirip dengan contoh kami di atas (pergi golf atau tidak), data dengan label kategori tertentu. ID3 tidak dapat menggunakan data numerik.
- Entropi informasi adalah indikator yang menunjukkan urutan data dengan varians paling sedikit dari properti suatu kelas nilai.
1.2.1 Tentang penggunaan data numerik
Algoritma C4.5, yang merupakan versi ID3 yang lebih maju, dapat menggunakan data numerik, tetapi karena ide dasarnya sama dalam seri ini, kita akan menggunakan ID3 terlebih dahulu.
1.3 Lingkungan pengembangan
Program yang saya jelaskan di bawah ini, saya uji dan jalankan di bawah kondisi berikut:
- Notebook Jupyter (menggunakan Azure Notebooks)
- Python 3.6
- Perpustakaan: math, pandas, functools (tidak menggunakan scikit-learn, tensorflow, dll.)
1.4 Program sampel
1.4.1 Sebenarnya, programnya
Pertama, salin program ke Notebook Jupyter dan jalankan.
import math
import pandas as pd
from functools import reduce
#
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
# - , ,
# .
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
}
df0 = pd.DataFrame(d)
# - , - pandas.Series,
# -
# s value_counts() ,
# , , items().
# , sorted,
#
# , , : (k) (v).
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
# Decision Tree
tree = {
# name: ()
"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),
# df: , ()
"df":df0,
# edges: (), ,
# , .
"edges":[],
}
# , , open
open = [tree]
# - .
# - pandas.Series、 -
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
# , open
while(len(open)!=0):
# open ,
# ,
n = open.pop(0)
df_n = n["df"]
# , 0,
#
if 0==entropy(df_n.iloc[:,-1]):
continue
# ,
attrs = {}
# ,
for attr in df_n.columns[:-1]:
# , ,
# , .
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
# .
# , sorted ,
# , .
for value in sorted(set(df_n[attr])):
#
df_m = df_n.query(attr+"=='"+value+"'")
# ,
attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0]
attrs[attr]["dfs"] += [df_m]
attrs[attr]["values"] += [value]
pass
pass
# , ,
# .
if len(attrs)==0:
continue
#
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
#
# , , open.
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
m = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)}
n["edges"].append(m)
open.append(m)
pass
#
print(df0,"\n-------------")
# , - tree: ,
# indent: indent,
# - .
# .
def tstr(tree,indent=""):
# .
# ( 0),
# df, , .
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
# .
for e in tree["edges"]:
# .
# indent .
s += tstr(e,indent+" ")
pass
return s
# .
print(tstr(tree))1.4.2 Hasil
Jika Anda menjalankan program di atas, Pohon Keputusan kami akan ditampilkan sebagai tabel simbol seperti yang ditunjukkan di bawah ini.
decision tree ['×:5', '○:9']
=
=['○:2']
=['×:3']
=['○:4']
=
=['×:2']
=['○:3']
1.4.3 Ubah atribut (data array) yang ingin kita eksplorasi
Larik terakhir pada set tanggal d adalah atribut kelas (larik data yang ingin kita klasifikasikan).
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],}
# - , , .
"":["","","","","","","","","","","","","",""],
}Misalnya, jika Anda menukar array "Golf" dan "Wind", seperti yang ditunjukkan pada contoh di atas, Anda mendapatkan hasil sebagai berikut:
decision tree [':6', ':8']
=×
=
=
=[':1', ':1']
=[':1']
=[':2']
=○
=
=[':1']
=[':1']
=
=[':2']
=[':1']
=[':1']
=[':3']Intinya, kami membuat aturan di mana kami memberi tahu program untuk bercabang terlebih dahulu dengan ada dan tidak adanya angin dan apakah kami akan bermain golf atau tidak.
Terima kasih sudah membaca!
Kami akan sangat senang jika Anda memberi tahu kami jika Anda menyukai artikel ini, apakah terjemahannya jelas, apakah bermanfaat bagi Anda?