Mudah untuk memproses teks dalam bahasa natural menggunakan Python, karena ini adalah alat pemrograman tingkat tinggi, memiliki infrastruktur yang berkembang dengan baik, dan telah membuktikan dirinya di bidang analisis data dan pembelajaran mesin. Beberapa perpustakaan dan kerangka kerja telah dikembangkan oleh komunitas untuk memecahkan masalah NLP dengan Python. Dalam pekerjaan kami, kami akan menggunakan alat web interaktif untuk mengembangkan skrip python Jupyter Notebook, pustaka NLTK untuk analisis teks dan pustaka wordcloud untuk membangun cloud kata.
Jaringan tersebut berisi cukup banyak materi tentang topik analisis teks, tetapi di banyak artikel (termasuk yang berbahasa Rusia) diusulkan untuk menganalisis teks dalam bahasa Inggris. Analisis teks Rusia memiliki beberapa hal spesifik dalam menggunakan perangkat NLP. Sebagai contoh, perhatikan analisis frekuensi teks cerita "Blizzard" oleh A. Pushkin.
Analisis frekuensi secara kasar dapat dibagi menjadi beberapa tahap:
- Memuat dan menjelajahi data
- Pembersihan teks dan praproses
- Hapus kata-kata berhenti
- Menerjemahkan kata ke dalam bentuk dasar
- Menghitung statistik kemunculan kata-kata dalam teks
- Visualisasi awan dari popularitas kata
Skrip tersedia di github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb , sumber - github.com/Metafiz/nlp-course-20/blob/master/pushkin -metel.txt
Memuat data
Kami membuka file menggunakan fungsi built-in terbuka, menentukan mode membaca dan pengkodean. Kami membaca seluruh konten file, sebagai hasilnya kami mendapatkan teks string:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
Panjang teks - jumlah karakter - dapat diperoleh dengan fungsi len standar:
len(text)
Sebuah string dalam python dapat direpresentasikan sebagai daftar karakter, sehingga akses indeks dan operasi pemotongan juga dimungkinkan untuk bekerja dengan string. Misalnya, untuk melihat 300 karakter pertama teks, cukup jalankan perintah:
text[:300]
Pra-pemrosesan (preprocessing) teks
Untuk melakukan analisis frekuensi dan menentukan pokok bahasan teks, disarankan untuk menghapus teks dari tanda baca, karakter spasi tambahan, dan angka. Anda dapat melakukan ini dengan berbagai cara - menggunakan fungsi string bawaan, menggunakan ekspresi reguler, menggunakan pemrosesan daftar, atau dengan cara lain.
Pertama, mari kita ubah karakter menjadi satu kasus, misalnya, lebih rendah:
text = text.lower()
Kami menggunakan set karakter tanda baca standar dari modul string:
import string
print(string.punctuation)
string.punctuation adalah string. Kumpulan karakter khusus yang akan dihapus dari teks dapat diperluas. Perlu untuk menganalisis teks sumber dan mengidentifikasi karakter yang harus dihapus. Mari tambahkan jeda baris, tab, dan simbol lain yang ditemukan di teks sumber kita ke tanda baca (misalnya, karakter dengan kode \ xa0):
spec_chars = string.punctuation + '\n\xa0«»\t—…'
Untuk menghapus karakter, kami menggunakan pemrosesan elemen-bijaksana dari string - membagi string teks asli menjadi karakter, hanya menyisakan karakter yang tidak ada dalam set spec_chars, dan sekali lagi menggabungkan daftar karakter menjadi string:
text = "".join([ch for ch in text if ch not in spec_chars])
Anda dapat mendeklarasikan fungsi sederhana yang menghapus kumpulan karakter yang ditentukan dari teks sumber:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
Ini dapat digunakan baik untuk menghapus karakter khusus dan untuk menghapus angka dari teks asli:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
Teks tokenizing
Untuk pemrosesan lebih lanjut, teks yang telah dihapus harus dipecah menjadi beberapa bagian - token. Analisis teks bahasa natural menggunakan pemecahan simbol, kata, dan kalimat. Proses partisi disebut tokenisasi. Untuk tugas kita dalam analisis frekuensi, kita perlu memecah teks menjadi kata-kata. Untuk melakukan ini, Anda dapat menggunakan metode siap pakai dari pustaka NLTK:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
Variabel text_tokens adalah daftar kata (token). Untuk menghitung jumlah kata dalam teks yang diproses sebelumnya, Anda bisa mendapatkan panjang daftar token:
len(text_tokens)
Untuk menampilkan 10 kata pertama, mari gunakan operasi slice:
text_tokens[:10]
Untuk menggunakan alat analisis frekuensi pustaka NLTK, Anda perlu mengonversi daftar token ke kelas Teks, yang disertakan dalam pustaka ini:
import nltk
text = nltk.Text(text_tokens)
Mari kita simpulkan tipe teks variabel:
print(type(text))
Operasi slice juga berlaku untuk variabel jenis ini. Misalnya, tindakan ini akan mengeluarkan 10 token pertama dari teks:
text[:10]
Menghitung statistik kemunculan kata-kata dalam teks
Kelas FreqDist (distribusi frekuensi) digunakan untuk menghitung statistik distribusi frekuensi kata dalam teks:
from nltk.probability import FreqDist
fdist = FreqDist(text)
Mencoba menampilkan variabel fdist akan menampilkan kamus yang berisi token dan frekuensinya - berapa kali kata-kata ini muncul dalam teks:
FreqDist({'': 146, '': 101, '': 69, '': 54, '': 44, '': 42, '': 39, '': 39, '': 31, '': 27, ...})
Anda juga dapat menggunakan metode most_common untuk mendapatkan daftar tupel dengan token paling umum:
fdist.most_common(5)
[('', 146), ('', 101), ('', 69), ('', 54), ('', 44)]
Frekuensi penyebaran kata dalam sebuah teks dapat divisualisasikan dengan menggunakan grafik. Kelas FreqDist berisi metode plot built-in untuk membuat plot seperti itu. Diperlukan untuk menunjukkan jumlah token, yang frekuensinya akan ditampilkan pada grafik. Dengan parameter cumulative = False, grafik tersebut menggambarkan hukum Zipf : jika semua kata dari teks yang cukup panjang diurutkan dalam urutan frekuensi penggunaannya, maka frekuensi kata ke-n dalam daftar tersebut akan mendekati berbanding terbalik dengan nomor urutnya n.
fdist.plot(30,cumulative=False)
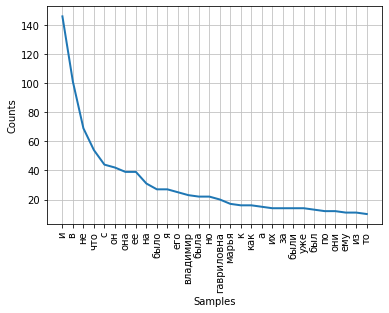
Dapat dicatat bahwa pada saat ini frekuensi tertinggi memiliki konjungsi, preposisi dan bagian layanan lain dari ucapan yang tidak membawa beban semantik, tetapi hanya mengekspresikan hubungan sintaksis-semantik antar kata. Agar hasil analisis frekuensi mencerminkan subjek teks, maka kata-kata tersebut perlu dihapus dari teks.
Hapus kata-kata berhenti
Kata-kata henti (atau kata-kata derau), sebagai suatu peraturan, mencakup preposisi, konjungsi, interjeksi, partikel, dan bagian ucapan lain yang sering ditemukan dalam teks, bersifat resmi dan tidak membawa beban semantik - kata-kata itu berlebihan.
Pustaka NLTK berisi daftar stop-word siap pakai untuk berbagai bahasa. Mari kita dapatkan daftar seratus kata untuk bahasa Rusia:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
Perlu dicatat bahwa kata henti peka konteks - untuk teks dengan topik yang berbeda, kata henti mungkin berbeda. Seperti dalam kasus dengan karakter khusus, perlu untuk menganalisis teks sumber dan mengidentifikasi kata-kata berhenti yang tidak termasuk dalam set standar.
Daftar stopword dapat diperpanjang menggunakan metode perpanjangan standar:
russian_stopwords.extend(['', ''])
Setelah menghapus kata-kata berhenti, frekuensi distribusi token dalam teks adalah sebagai berikut:
fdist_sw.most_common(10)
[('', 23),
('', 20),
('', 17),
('', 9),
('', 9),
('', 8),
('', 7),
('', 6),
('', 6),
('', 6)]
Seperti yang Anda lihat, hasil analisis frekuensi menjadi lebih informatif dan lebih akurat mencerminkan topik utama teks. Namun, kami melihat dalam hasil, token seperti "vladimir" dan "vladimira", yang sebenarnya adalah satu kata, tetapi dalam bentuk yang berbeda. Untuk memperbaiki situasi ini, kata-kata dari teks sumber perlu dibawa ke basis atau bentuk aslinya - untuk melakukan stemming atau lemmatisasi.
Visualisasi awan dari popularitas kata
Di akhir pekerjaan kami, kami memvisualisasikan hasil analisis frekuensi teks dalam bentuk "awan kata".
Untuk ini kita membutuhkan pustaka wordcloud dan matplotlib:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
Untuk membangun cloud kata, string harus diteruskan ke metode sebagai input. Untuk mengonversi daftar token setelah preprocessing dan menghapus kata-kata berhenti, kita akan menggunakan metode join, menentukan spasi sebagai pemisah:
text_raw = " ".join(text)
Mari panggil metode untuk membangun cloud:
wordcloud = WordCloud().generate(text_raw)
Hasilnya, kami mendapatkan "awan kata" untuk teks kami:

Dengan melihatnya, Anda bisa mendapatkan gambaran umum tentang pokok bahasan dan karakter utama dari karya tersebut.