
Ada sebuah lelucon di lingkungan TI bahwa pembelajaran mesin (ML) seperti seks di kalangan remaja: semua orang membicarakannya, semua orang berpura-pura melakukannya, tetapi, pada kenyataannya, sangat sedikit orang yang berhasil. FunCorp telah berhasil memperkenalkan ML ke dalam mekanisme utama produknya dan mencapai peningkatan radikal (hampir 40%!) Dalam metrik utama. Menarik? Selamat datang di cat.
Sedikit latar belakang
Bagi mereka yang membaca blog FunCorp secara tidak teratur, izinkan saya mengingatkan Anda bahwa produk kami yang paling sukses adalah aplikasi iFunny UGC dengan elemen jejaring sosial untuk pecinta meme. Pengguna (dan ini adalah perwakilan keempat generasi muda di AS) mengunggah atau membuat gambar atau video baru langsung di aplikasi, dan algoritme cerdas memilih (atau, seperti yang kami katakan, "fitur", dari kata "unggulan") yang terbaik dari mereka dan bentuk masing-masing hari dari 7 terbitan 30-60 unit konten dalam umpan terpisah, yang mana 99% pemirsanya berinteraksi. Alhasil, saat masuk ke aplikasi, setiap pengguna melihat meme, video, dan gambar lucu teratas. Jika Anda sering berkunjung, umpan akan dengan cepat bergulir dan pengguna menunggu masalah berikutnya dalam beberapa jam. Namun, jika Anda lebih jarang berkunjung, konten unggulan terakumulasi, dan feed dapat bertambah menjadi 1000 item dalam beberapa hari.
Karenanya, tugas muncul: untuk menunjukkan kepada setiap pengguna konten yang paling relevan untuknya, mengelompokkan meme yang menarik baginya secara pribadi di awal umpan.
Selama lebih dari 9 tahun keberadaan iFunny, ada beberapa pendekatan untuk tugas ini.
Pertama, kami mencoba cara yang jelas untuk mengurutkan umpan berdasarkan jumlah senyuman (analogi "suka" kami) - Tingkat senyum . Itu lebih baik daripada mengurutkan dalam urutan kronologis, tetapi pada saat yang sama menyebabkan efek "suhu rata-rata di rumah sakit": ada sedikit humor yang disukai semua orang, dan akan selalu ada orang yang tidak tertarik (dan bahkan terus terang kesal) topik populer saat ini ... Tetapi Anda juga ingin melihat semua lelucon lucu baru dari kartun favorit Anda.
Dalam percobaan berikutnya, kami mencoba mempertimbangkan minat masing-masing komunitas mikro: penggemar anime, olahraga, meme dengan kucing dan anjing, dll. Untuk melakukan ini, mereka mulai membentuk beberapa fitur-feed tematik dan menawarkan pengguna untuk memilih topik yang mereka minati, menggunakan tag dan teks yang dikenali dalam gambar. Ini telah meningkat dalam beberapa hal, tetapi efek dari jejaring sosial telah hilang: ada lebih sedikit komentar pada konten unggulan, yang memainkan peran besar dalam keterlibatan pengguna. Selain itu, dalam perjalanan ke umpan tersegmentasi, kami kehilangan banyak meme populer yang sangat top. Mereka menonton "Kartun Favorit", tetapi tidak melihat lelucon tentang "Avengers terakhir".
Karena kami sudah mulai menerapkan algoritme pembelajaran mesin ke dalam produk kami, yang kami sajikan pada pertemuan kami sendiri, mereka ingin melakukan pendekatan lain dengan menggunakan teknologi ini.
Diputuskan untuk mencoba membangun sistem rekomendasi berdasarkan prinsip penyaringan kolaboratif. Prinsip ini baik dalam kasus di mana aplikasi memiliki sangat sedikit data tentang pengguna: sedikit yang menunjukkan usia atau jenis kelamin mereka saat mendaftar, dan hanya dengan alamat IP seseorang dapat mengasumsikan lokasi geografis mereka (walaupun tanpa peramal diketahui bahwa sebagian besar pengguna iFunny adalah penduduk. Amerika Serikat), dan menurut model telepon - tingkat pendapatan. Dalam hal ini, secara umum, semuanya. Pemfilteran kolaboratif bekerja seperti ini: riwayat peringkat positif dari konten pengguna diambil, ada pengguna lain dengan peringkat serupa, kemudian dia merekomendasikan apa yang telah disukai pengguna yang sama (dengan peringkat serupa).
Fitur tugas
Meme adalah konten yang cukup spesifik. Pertama, sangat rentan terhadap tren yang berubah dengan cepat. Konten dan bentuk yang mencapai puncak dan membuat 80% penonton tersenyum seminggu yang lalu, hari ini dapat menyebabkan gangguan dengan sifat sekunder dan ketidaktepatan mereka.
Kedua, interpretasi yang sangat non-linear dan situasional dari makna meme. Dalam pemilihan berita, Anda dapat menemukan nama-nama terkenal, topik yang cukup konsisten digunakan oleh pengguna tertentu. Dalam pilihan film, Anda dapat mengetahui pemeran, genre, dan banyak lagi. Ya, Anda dapat memahami semua ini dalam pilihan meme pribadi. Tapi betapa mengecewakannya jika melewatkan mahakarya humor yang sebenarnya, yang menggunakan gambar atau kosa kata yang sama sekali tidak cocok dengan konten semantik!

Terakhir, sejumlah besar konten yang dibuat secara dinamis. Di iFunny, pengguna membuat puluhan ribu kiriman setiap hari. Semua konten ini harus "digali" secepat mungkin, dan dalam kasus sistem rekomendasi yang dipersonalisasi, tidak hanya untuk menemukan "berlian", tetapi juga untuk dapat memprediksi penilaian konten oleh berbagai perwakilan masyarakat.
Apa arti fitur-fitur ini untuk pengembangan model pembelajaran mesin? Pertama-tama, model harus terus dilatih pada data terbaru. Pada permulaan pendalaman dalam pengembangan sistem rekomendasi, masih belum sepenuhnya jelas apakah kita berbicara tentang puluhan menit atau beberapa jam. Namun keduanya berarti perlunya pelatihan ulang model yang konstan, atau bahkan lebih baik - pelatihan online tentang aliran data yang berkelanjutan. Semua ini bukanlah tugas termudah dari sudut pandang menemukan arsitektur model yang sesuai dan memilih hyperparameternya: sedemikian rupa sehingga akan menjamin bahwa dalam beberapa minggu metrik tidak akan mulai menurun dengan percaya diri.
Kesulitan terpisah adalah kebutuhan untuk mengikuti protokol pengujian a / b yang kami adopsi. Kami tidak pernah menerapkan apa pun tanpa terlebih dahulu memeriksa beberapa pengguna, membandingkan hasil dengan grup kontrol.
Setelah perhitungan yang lama, diputuskan untuk memulai MVP dengan karakteristik berikut: kami hanya menggunakan informasi tentang interaksi pengguna dengan konten, kami melatih model secara real time, tepat di server yang dilengkapi dengan memori dalam jumlah besar, yang memungkinkan penyimpanan seluruh riwayat interaksi grup pengguna pengujian untuk jangka waktu yang cukup lama. Kami memutuskan untuk membatasi waktu pelatihan menjadi 15-20 menit untuk mempertahankan efek kebaruan, serta memiliki waktu untuk menggunakan data terbaru dari pengguna yang secara besar-besaran datang ke aplikasi selama rilis.
Model
Pertama, kami mulai mengubah pemfilteran kolaboratif paling klasik dengan dekomposisi matriks dan pelatihan di ALS (bolak-balik kuadrat terkecil) atau SGD (penurunan gradien stokastik). Tetapi mereka dengan cepat menemukan: mengapa tidak langsung memulai dengan jaringan saraf paling sederhana? Dengan jaring satu lapis sederhana, di mana hanya ada satu lapisan embedding linier, dan tidak ada pembungkusan lapisan tersembunyi, agar tidak mengubur diri Anda dalam beberapa minggu saat memilih hyperparameternya. Sedikit melampaui MVP? Mungkin. Tetapi untuk melatih mesh semacam itu hampir tidak lebih sulit daripada arsitektur yang lebih klasik, jika Anda memiliki perangkat keras yang dilengkapi dengan GPU yang baik (Anda harus membayarnya).
Awalnya, jelas bahwa hanya ada dua opsi untuk pengembangan acara: pengembangan akan memberikan hasil yang signifikan dalam metrik produk, kemudian perlu menggali lebih jauh ke dalam parameter pengguna dan konten, ke dalam pelatihan tambahan tentang konten baru dan pengguna baru, ke dalam jaringan saraf yang dalam, atau peringkat konten yang dipersonalisasi tidak akan membawa peningkatan nyata dan "toko" dapat ditutup. Jika opsi pertama terjadi, maka semua hal di atas harus disekrup ke lapisan Embedding awal.
Kami memutuskan untuk memilih Mesin Faktorisasi Saraf . Prinsip operasinya adalah sebagai berikut: setiap pengguna dan setiap konten dikodekan oleh vektor dengan panjang yang sama tetap - embeddings, yang selanjutnya dilatih pada serangkaian interaksi yang diketahui antara pengguna dan konten.
Set pelatihan mencakup semua fakta pengguna yang melihat konten. Selain senyuman, diputuskan untuk mempertimbangkan mengklik tombol "bagikan" atau "simpan", serta menulis komentar, untuk mendapatkan masukan positif tentang konten. Jika ada, interaksi ditandai dengan 1 (satu). Jika, setelah melihat, pengguna tidak meninggalkan umpan balik positif, interaksi ditandai dengan 0 (nol). Jadi, meski tidak ada skala peringkat eksplisit, model eksplisit digunakan (model dengan peringkat eksplisit dari pengguna), dan bukan model implisit, yang hanya akan memperhitungkan tindakan positif.
Kami juga mencoba model implisit, tetapi tidak langsung berfungsi, jadi kami fokus pada model eksplisit. Mungkin, untuk model implisit, Anda perlu menggunakan fungsi kerugian peringkat lintas entropi biner yang lebih licik daripada fungsi kerugian peringkat lintas entropi biner sederhana.
Perbedaan antara Neural Matrix Factorization dan Neural Collaborative Filtering standar terletak pada apa yang disebut dengan lapisan Bi-Interaction Pooling, bukan lapisan yang terhubung sepenuhnya seperti biasa yang hanya akan menghubungkan pengguna dan vektor penyematan konten. Layer Bi-Interaction mengubah satu set vektor embedding (hanya ada 2 vektor di iFunny: user dan konten) menjadi satu vektor dengan mengalikannya elemen demi elemen.
Dengan tidak adanya lapisan tersembunyi tambahan di atas Interaksi-Bi, kita mendapatkan perkalian titik dari vektor-vektor ini dan, menambahkan bias pengguna dan bias konten, membungkusnya dalam sebuah sigmoid. Ini adalah perkiraan kemungkinan umpan balik positif dari pengguna setelah melihat konten ini. Berdasarkan penilaian inilah kami memberi peringkat pada konten yang tersedia sebelum mendemonstrasikannya pada perangkat tertentu.
Dengan demikian, tugas pelatihan adalah memastikan bahwa embeddings pengguna dan konten yang memiliki interaksi positif saling berdekatan (memiliki produk titik maksimum), dan embeddings pengguna dan konten yang terdapat interaksi negatif berada jauh dari satu sama lain. (produk titik minimum).
Sebagai hasil dari pelatihan ini, embedding pengguna yang tersenyum hal yang sama menjadi dekat satu sama lain dengan sendirinya. Dan ini adalah deskripsi matematis yang nyaman dari pengguna yang dapat digunakan dalam banyak tugas lainnya. Tapi itu cerita lain.
Jadi, pengguna memasuki umpan dan mulai menonton konten. Setiap kali Anda melihat, tersenyum, berbagi, dll. klien mengirimkan statistik ke penyimpanan analitik kami (yang, jika tertarik, kami tulis sebelumnya di artikel Pindah dari Redshift ke Clickhouse ). Dalam perjalanan, kami memilih acara yang menarik bagi kami dan mengirimkannya ke server ML, di mana mereka disimpan dalam memori.
Setiap 15 menit, model dilatih ulang di server, setelah itu statistik pengguna baru diperhitungkan dalam rekomendasi.
Klien meminta halaman berikutnya dari feed, ini dibentuk dengan cara standar, tetapi dalam cara daftar konten dikirim ke layanan ML, yang mengurutkannya sesuai dengan bobot yang diberikan oleh model terlatih untuk pengguna tertentu ini.

Hasilnya, pengguna pertama-tama melihat gambar dan video yang menurut modelnya paling disukai olehnya.
Arsitektur layanan internal
Layanan ini bekerja melalui HTTP. Flask digunakan sebagai server HTTP bersama dengan Gunicorn. Ini menangani dua permintaan: add_event dan get_rates.
permintaan add_event menambahkan interaksi baru antara pengguna dan konten. Itu ditambahkan ke antrian internal dan kemudian diproses dalam proses terpisah (memuncak hingga 1600 rps).
Permintaan get_rates menghitung bobot untuk daftar user_id dan content_id sesuai dengan model (di puncak sekitar seratus rps).
Proses internal utama adalah Dispatcher. Itu ditulis dalam asyncio dan mengimplementasikan logika dasar:
- memproses antrian permintaan add_event dan menyimpannya dalam hashmap yang sangat besar (200 juta kejadian per minggu);
- menghitung ulang model dalam lingkaran;
- menyimpan acara baru ke disk setiap setengah jam, sekaligus menghapus acara yang lebih lama dari seminggu dari peta hash.

Model terlatih ditempatkan dalam memori bersama, tempat model tersebut dibaca oleh pekerja HTTP.
hasil
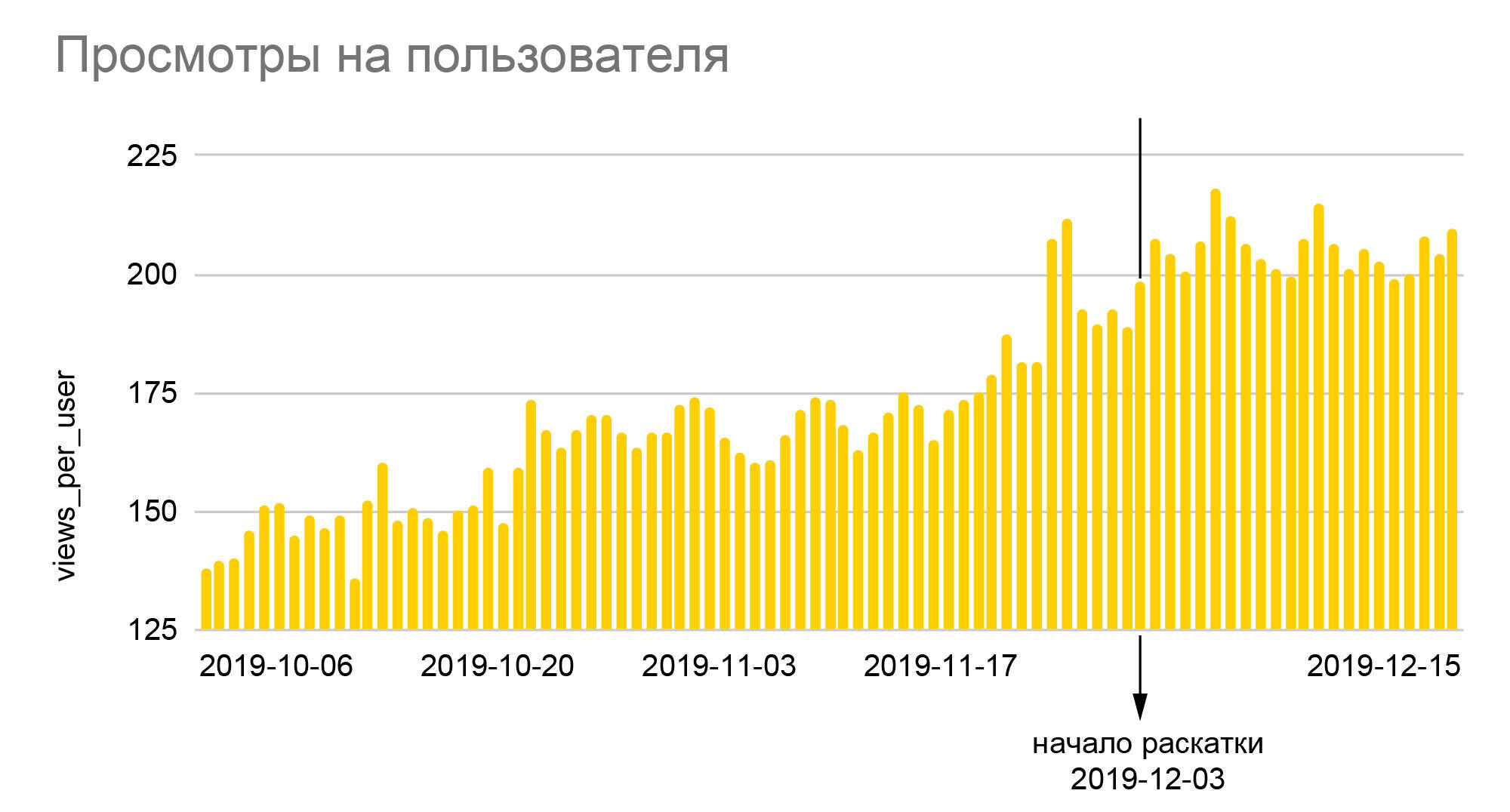

Grafik berbicara sendiri. Pertumbuhan 25% dalam jumlah relatif smilies dan hampir 40% kedalaman penayangan yang kami lihat pada mereka adalah hasil dari peluncuran algoritme baru ke seluruh audiens pada akhir pengujian A / B 50/50, yaitu peningkatan nyata relatif terhadap nilai dasar hampir dua kali lebih besar. Karena iFunny menghasilkan uang dari iklan, peningkatan kedalaman berarti peningkatan pendapatan yang proporsional, yang, pada gilirannya, memungkinkan kami melewati bulan-bulan krisis tahun 2020 dengan cukup tenang. Peningkatan jumlah smilies diterjemahkan ke dalam loyalitas yang lebih besar, yang berarti kemungkinan lebih rendah untuk meninggalkan aplikasi di masa mendatang; pengguna setia mulai pergi ke bagian lain aplikasi, meninggalkan komentar, berkomunikasi satu sama lain. Dan yang terpenting, kami tidak hanya menciptakan dasar yang dapat diandalkan untuk meningkatkan kualitas rekomendasi,tetapi juga meletakkan dasar untuk membuat fitur baru berdasarkan data perilaku anonim dalam jumlah besar yang telah kami kumpulkan selama bertahun-tahun penerapannya.
Kesimpulan
Layanan ML Content Rate adalah hasil dari sejumlah besar penyempurnaan dan peningkatan kecil.
Pertama, pengguna yang tidak terdaftar juga diperhitungkan dalam pelatihan. Awalnya, ada pertanyaan tentang mereka, karena mereka secara apriori tidak dapat meninggalkan emotikon - tanggapan paling sering setelah melihat konten. Tetapi segera menjadi jelas bahwa ketakutan ini sia-sia dan menutup titik pertumbuhan yang sangat besar. Banyak eksperimen dilakukan dengan konfigurasi sampel pelatihan: untuk menempatkan sebagian besar audiens di dalamnya atau untuk memperluas interval waktu interaksi yang diperhitungkan. Selama eksperimen ini, ternyata tidak hanya jumlah data yang memainkan peran penting untuk metrik produk, tetapi juga waktu untuk memperbarui model. Seringkali, peningkatan kualitas peringkat tenggelam dalam 10-20 menit ekstra untuk menghitung ulang model, yang membuatnya perlu untuk meninggalkan inovasi.
Banyak, bahkan yang terkecil, peningkatan telah membuahkan hasil: peningkatan kualitas pembelajaran, percepatan proses pembelajaran, atau penyimpanan memori. Misalnya, ada masalah dengan fakta bahwa interaksi tidak sesuai dengan memori - interaksi harus dioptimalkan. Selain itu, kode telah dimodifikasi dan menjadi mungkin untuk didorong ke dalamnya, misalnya, lebih banyak interaksi untuk penghitungan ulang. Ini juga menyebabkan peningkatan stabilitas layanan.
Sekarang pekerjaan sedang dilakukan untuk secara efektif menggunakan parameter pengguna dan konten yang diketahui, untuk membuat model tambahan dan pelatihan ulang dengan cepat, dan hipotesis baru untuk perbaikan di masa mendatang muncul.
Jika Anda tertarik untuk mempelajari bagaimana kami mengembangkan layanan ini dan perbaikan lain apa yang berhasil kami terapkan - tulis di komentar, setelah beberapa saat kami akan siap untuk menulis bagian kedua.
Tentang Penulis
Sayangnya, Habr tidak mengizinkan untuk menunjuk beberapa penulis untuk artikel tersebut. Meskipun artikel tersebut diterbitkan dari akun saya, sebagian besar ditulis oleh pengembang utama layanan FunCorp ML - Grisha Kuzovnikov (PhoenixMSTU), serta seorang analis dan ilmuwan data - Dima Zemtsov. Pelayan bandel Anda terutama bertanggung jawab atas lelucon seks remaja, bagian pengantar dan hasil, ditambah pekerjaan editorial. Dan, tentu saja, semua pencapaian ini tidak akan mungkin terjadi tanpa bantuan tim pengembangan backend, QA, analis, dan tim produk, yang menemukan semua ini dan menghabiskan beberapa bulan untuk melakukan dan menyesuaikan eksperimen A / B.