Jalur penelitian
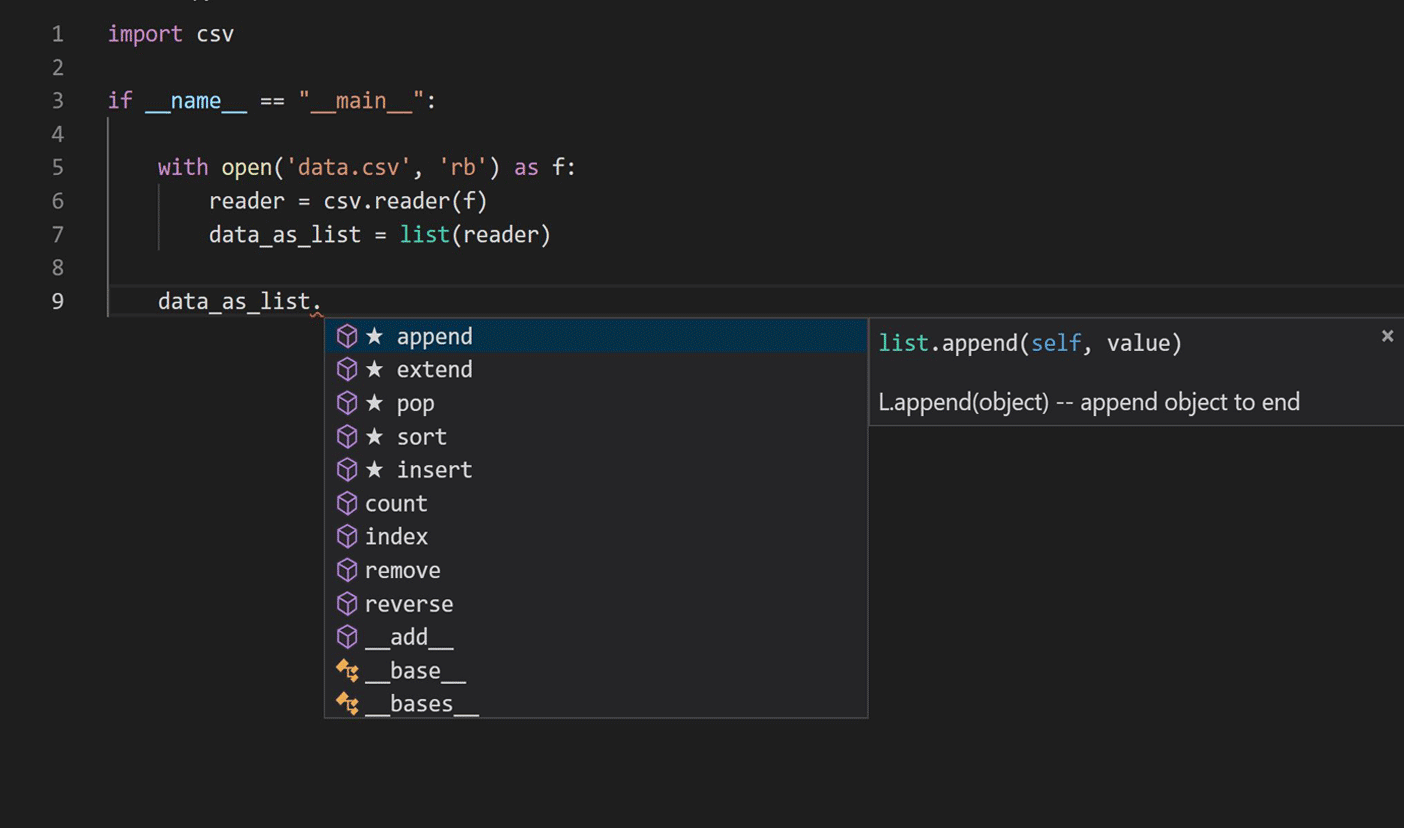
Perjalanan dimulai dengan meneliti penerapan teknik pemodelan bahasa dalam pemrosesan bahasa alami untuk mempelajari kode Python. Kami fokus pada skrip penyelesaian IntelliCode saat ini, seperti yang ditunjukkan pada gambar di bawah ini.

Tugas utamanya adalah menemukan fragmen (anggota) yang paling mungkin dari jenis tersebut, dengan mempertimbangkan fragmen kode yang mendahului panggilan fragmen (anggota). Dengan kata lain, mengingat cuplikan kode C asli, kosakata V, dan himpunan semua metode yang memungkinkan M ⊂ V, kami ingin mendefinisikan:
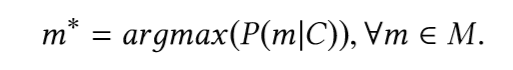
Untuk menemukan fragmen ini, kita perlu membuat model yang dapat memprediksi probabilitas fragmen yang tersedia.
Pendekatan modern sebelumnya berdasarkan jaringan saraf berulang ( RNN ) hanya menggunakan sifat sekuensial dari kode sumber, mencoba menyampaikan teknik bahasa alami tanpa memanfaatkan karakteristik unik dari sintaks bahasa pemrograman dan semantik kode. Sifat dari masalah penyelesaian kode telah membuatnya menjadi kandidat yang menjanjikan untuk memori jangka pendek jangka pendek ( LSTM). Saat menyiapkan data untuk melatih model, kami menggunakan pohon sintaksis abstrak parsial (AST) yang sesuai dengan cuplikan kode yang berisi ekspresi akses anggota (anggota) dan panggilan fungsi modul untuk menangkap semantik yang dibawa oleh kode jarak jauh.
Melatih jaringan neural dalam adalah tugas intensif sumber daya yang membutuhkan cluster komputasi berkinerja tinggi. Kami menggunakan framework pelatihan paralel terdistribusi Horovod dengan pengoptimal Adam , menyimpan salinan seluruh model neural pada setiap pekerja, memproses kumpulan mini yang berbeda dari set data pelatihan secara paralel. Kami menggunakan Pembelajaran Mesin Azureuntuk pelatihan model dan penyetelan hyperparameter, karena layanan cluster sesuai permintaan GPU-nya memudahkan penskalaan pelatihan kami sesuai kebutuhan, dan juga membantu menyediakan dan mengelola cluster VM, menjadwalkan pekerjaan, mengumpulkan hasil, dan menangani kegagalan. Tabel tersebut menunjukkan model arsitektur yang kami uji, serta akurasi dan ukuran modelnya masing-masing.

Kami memilih manufaktur Implementasi Prediktif karena ukuran model yang lebih kecil dan peningkatan 20% dalam akurasi model dibandingkan model produksi sebelumnya selama evaluasi model offline; ukuran model sangat penting untuk penerapan produksi.
Arsitektur model ditunjukkan pada gambar di bawah ini:

Untuk menerapkan LSTM dalam produksi, kami harus meningkatkan kecepatan inferensi model dan jejak memori untuk memenuhi persyaratan penyelesaian kode selama pengeditan. Anggaran memori kami sekitar 50MB dan kami harus menjaga kecepatan keluaran rata-rata di bawah 50 milidetik. IntelliCode LSTM dilatih dengan TensorFlow dan kami memilih ONNX Runtime sebagai inferensi untuk mendapatkan performa terbaik. ONNX Runtime bekerja dengan kerangka kerja pembelajaran mendalam yang populer dan membuatnya mudah untuk diintegrasikan ke dalam berbagai lingkungan penyajian dengan menyediakan API yang mencakup banyak bahasa termasuk Python, C, C ++, C #, Java, dan JavaScript - kami menggunakan C # API yang kompatibel dengan .NET Core untuk diintegrasikan ke dalam Server Bahasa Microsoft Python .
Kuantisasi adalah pendekatan yang efektif untuk mengurangi ukuran model dan meningkatkan kinerja saat penurunan presisi yang disebabkan oleh perkiraan angka digit rendah dapat diterima. Dengan kuantisasi INT8 pasca pelatihan yang disediakan oleh ONNX Runtime, peningkatan yang dihasilkan sangat signifikan: jejak memori dan waktu inferensi berkurang menjadi sekitar seperempat nilai prekuantisasi dibandingkan dengan model asli, dengan pengurangan akurasi model sebesar 3%. Anda dapat menemukan informasi terperinci tentang desain arsitektur model, penyetelan hyperparameter, akurasi, dan kinerja dalam makalah penelitian yang kami terbitkan di konferensi KDD 2019.
Tahap terakhir dari rilis ke produksi adalah melakukan eksperimen A / B online yang membandingkan model LSTM baru dengan model kerja sebelumnya. Hasil eksperimen A / B online pada tabel di bawah menunjukkan peningkatan sekitar 25% dalam keakuratan rekomendasi tingkat pertama (akurasi item penyelesaian pertama yang direkomendasikan dalam daftar penyelesaian) dan peningkatan 17% dalam mean inverse rank (MRR), yang meyakinkan kami bahwa model LSTM baru secara signifikan lebih baik. model sebelumnya.

Pengembang Python: Coba add-on IntelliCode dan kirimkan masukan Anda!
Berkat banyak upaya tim, kami telah menyelesaikan peluncuran bertahap model pembelajaran mendalam pertama untuk semua pengguna IntelliCode Python dalam Visual Studio Code . Dalam versi terbaru ekstensi IntelliCode untuk Visual Studio Code, kami juga mengintegrasikan runtime ONNX dan LSTM untuk bekerja dengan ekstensi Pylance baru , yang seluruhnya ditulis dalam TypeScript. Jika Anda seorang pengembang Python, instal ekstensi IntelliCode dan bagikan pendapat Anda dengan kami.