Prinsip-prinsip sistem kami
Saat mendengar istilah seperti "otomatis" dan "penipuan", Anda kemungkinan besar akan memikirkan pembelajaran mesin, Apache Spark, Hadoop, Python, Airflow, dan teknologi lain dari ekosistem Apache Foundation dan ilmu data. Saya rasa ada satu aspek dalam menggunakan alat ini yang biasanya tidak disebutkan: alat tersebut memerlukan prasyarat tertentu dalam sistem perusahaan Anda sebelum Anda dapat mulai menggunakannya. Singkatnya, Anda memerlukan platform data perusahaan yang mencakup data lake dan penyimpanan. Tetapi bagaimana jika Anda tidak memiliki platform seperti itu dan masih perlu mengembangkan praktik ini? Asas-asas berikut, yang saya bahas di bawah, telah membantu kami mencapai titik di mana kami dapat berfokus pada peningkatan ide-ide kami, daripada menemukan ide yang berhasil. Namun, ini bukanlah "dataran" proyek.Masih banyak hal dalam rencana dari sudut pandang teknologi dan produk.
Prinsip 1: Nilai Bisnis Menjadi Yang Utama
Kami telah menempatkan nilai bisnis di pusat dari semua upaya kami. Secara umum, setiap sistem analisis otomatis termasuk dalam kelompok sistem kompleks dengan otomatisasi tingkat tinggi dan kompleksitas teknis. Butuh waktu lama untuk membuat solusi lengkap jika Anda membuatnya dari awal. Kami memutuskan untuk memprioritaskan nilai bisnis dan kelengkapan teknologi. Dalam kehidupan nyata, ini berarti kita tidak menerima teknologi maju sebagai dogma. Kami memilih teknologi yang paling sesuai untuk kami saat ini. Seiring waktu, tampaknya kita harus mengimplementasikan ulang beberapa modul. Kompromi inilah yang telah kami terima.
Prinsip 2: kecerdasan yang ditingkatkan
Saya yakin kebanyakan orang yang tidak terlalu terlibat dalam pengembangan solusi pembelajaran mesin mungkin berpikir bahwa mengganti orang adalah tujuannya. Faktanya, solusi pembelajaran mesin masih jauh dari sempurna dan hanya dapat diganti di area tertentu. Kami membuang ide ini dari awal karena beberapa alasan: data yang tidak seimbang pada aktivitas penipuan dan ketidakmampuan untuk memberikan daftar lengkap fitur untuk model pembelajaran mesin. Sebaliknya, kami memilih opsi kecerdasan yang ditingkatkan. Ini adalah konsep alternatif kecerdasan buatan yang berfokus pada peran pendukung AI, menyoroti fakta bahwa teknologi kognitif dirancang untuk meningkatkan kecerdasan manusia, bukan menggantikannya. [1]
Dengan pemikiran ini, mengembangkan solusi pembelajaran mesin yang lengkap sejak awal akan membutuhkan banyak upaya yang akan menunda penciptaan nilai untuk bisnis kita. Kami memutuskan untuk membangun sistem dengan aspek pembelajaran mesin yang terus berkembang di bawah bimbingan pakar domain kami. Bagian rumit dari pengembangan sistem semacam itu adalah sistem tersebut harus memberikan analis kami kasus-kasus tidak hanya dalam hal apakah itu merupakan aktivitas penipuan atau bukan. Secara umum, setiap anomali dalam perilaku pelanggan adalah kasus mencurigakan yang perlu diselidiki dan ditanggapi oleh spesialis. Hanya sebagian kecil dari kasus yang dilaporkan ini yang benar-benar dapat diklasifikasikan sebagai penipuan.
Prinsip 3: platform intelijen yang kaya
Bagian tersulit dari sistem kami adalah pemeriksaan menyeluruh dari alur kerja sistem. Analis dan pengembang harus dapat dengan mudah mengambil kumpulan data historis dengan semua metrik yang digunakan untuk analisis mereka. Selain itu, platform data harus menyediakan cara mudah untuk melengkapi kumpulan metrik yang ada dengan yang baru. Proses yang kita buat, dan ini bukan hanya proses perangkat lunak, harus memudahkan penghitungan ulang periode sebelumnya, menambahkan metrik baru, dan mengubah perkiraan data. Kami dapat mencapai ini dengan mengumpulkan semua data yang dihasilkan oleh sistem produksi kami. Dalam hal ini, data secara bertahap akan menjadi penghalang. Kami perlu menyimpan dan melindungi semakin banyak data yang tidak kami gunakan. Dalam skenario seperti itu, seiring waktu, data akan menjadi semakin tidak relevan,namun tetap membutuhkan upaya kita untuk mengelolanya. Bagi kami, penimbunan data tidak masuk akal, dan kami memutuskan untuk mengambil pendekatan yang berbeda. Kami memutuskan untuk mengatur penyimpanan data waktu nyata di sekitar entitas target yang ingin kami klasifikasikan, dan hanya menyimpan data yang memungkinkan kami untuk memeriksa periode terbaru dan terbaru. Tantangan dari upaya ini adalah bahwa sistem kami heterogen dengan beberapa penyimpanan data dan modul perangkat lunak yang memerlukan perencanaan yang cermat agar dapat bekerja secara konsisten.yang memungkinkan Anda untuk memeriksa periode terbaru dan saat ini. Tantangan dari upaya ini adalah bahwa sistem kami heterogen dengan beberapa penyimpanan data dan modul perangkat lunak yang memerlukan perencanaan yang cermat agar dapat bekerja secara konsisten.yang memungkinkan Anda untuk memeriksa periode terbaru dan saat ini. Tantangan dari upaya ini adalah bahwa sistem kami heterogen dengan beberapa penyimpanan data dan modul perangkat lunak yang memerlukan perencanaan yang cermat agar dapat bekerja secara konsisten.
Konsep konstruktif dari sistem kami
Kami memiliki empat komponen utama dalam sistem kami: sistem penyerapan, komputasi, analisis BI, dan sistem pelacakan. Mereka melayani tujuan tertentu yang terisolasi, dan kami mengisolasi mereka dengan mengikuti pendekatan desain khusus.
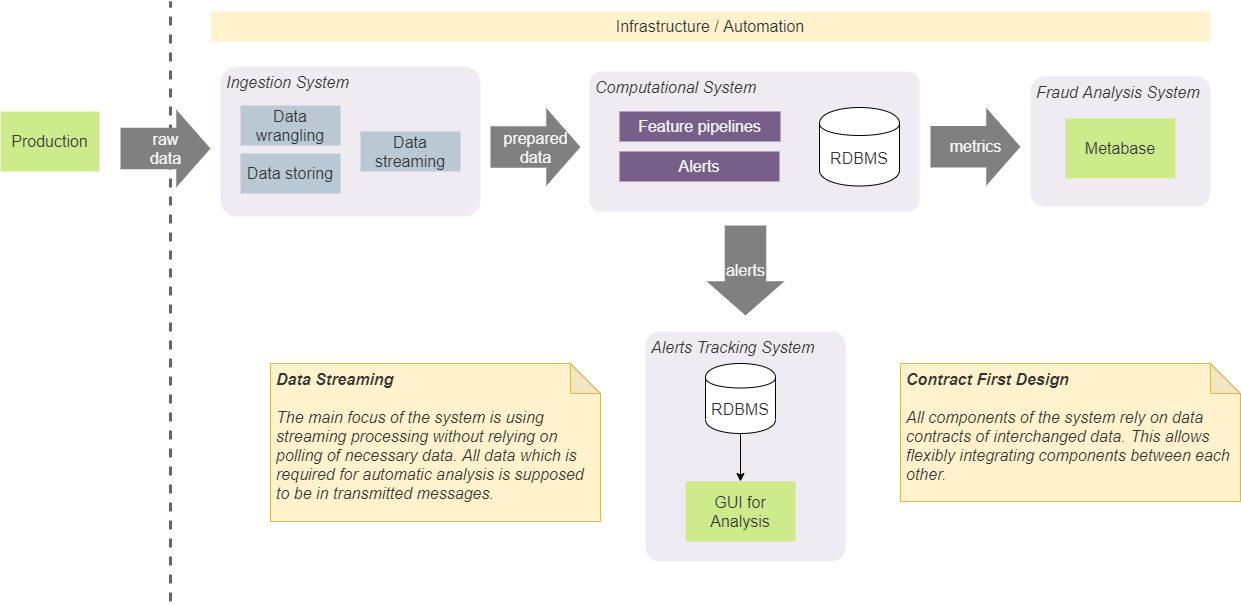
Desain berbasis kontrak
Pertama-tama, kami sepakat bahwa komponen hanya boleh bergantung pada struktur data (kontrak) tertentu yang diteruskan di antara mereka. Ini membuatnya mudah untuk mengintegrasikan di antara mereka dan tidak memaksakan komposisi (dan urutan) komponen tertentu. Misalnya, dalam beberapa kasus, ini memungkinkan kami untuk langsung mengintegrasikan sistem penerima dengan sistem pelacakan peringatan. Jika demikian, ini akan dilakukan sesuai dengan kontrak pemberitahuan yang disepakati. Artinya, kedua komponen tersebut akan diintegrasikan menggunakan kontrak yang dapat digunakan oleh komponen lain. Kami tidak akan menambahkan kontrak tambahan untuk menambahkan peringatan ke sistem pelacakan dari sistem masukan. Pendekatan ini membutuhkan penggunaan jumlah kontrak minimum yang telah ditentukan dan menyederhanakan sistem dan komunikasi. Faktanya,kami menggunakan pendekatan yang disebut "Desain Kontrak Pertama" dan menerapkannya pada kontrak streaming. [2]
Mempertahankan dan mengelola state dalam sistem pasti akan menimbulkan komplikasi dalam implementasinya. Secara umum, status harus dapat diakses dari setiap komponen, harus konsisten dan memberikan nilai yang paling relevan untuk semua komponen, dan harus dapat diandalkan dengan nilai yang benar. Selain itu, melakukan panggilan ke penyimpanan persisten untuk mendapatkan status terbaru akan meningkatkan jumlah I / O dan kompleksitas algoritme yang digunakan dalam pipeline real-time kami. Karena itu, kami memutuskan untuk menghapus penyimpanan status selengkap mungkin dari sistem kami. Pendekatan ini membutuhkan penyertaan semua data yang diperlukan dalam blok data yang ditransmisikan (pesan). Misalnya, jika kita perlu menghitung jumlah total beberapa pengamatan (jumlah operasi atau kasus dengan karakteristik tertentu),kami menghitungnya dalam memori dan menghasilkan aliran nilai seperti itu. Modul dependen akan menggunakan partisi dan batch untuk membagi aliran menjadi entitas dan beroperasi pada nilai terbaru. Pendekatan ini menghilangkan kebutuhan untuk memiliki penyimpanan persistent disk untuk data tersebut. Sistem kami menggunakan Kafka sebagai perantara pesan dan dapat digunakan sebagai database dengan KSQL. [3] Tetapi menggunakannya akan sangat mengikat solusi kami ke Kafka, dan kami memutuskan untuk tidak menggunakannya. Pendekatan yang kami ambil memungkinkan kami untuk mengganti Kafka dengan broker pesan lain tanpa perubahan sistem internal yang besar.Pendekatan ini menghilangkan kebutuhan untuk memiliki penyimpanan persistent disk untuk data tersebut. Sistem kami menggunakan Kafka sebagai perantara pesan dan dapat digunakan sebagai database dengan KSQL. [3] Tetapi menggunakannya akan sangat mengikat solusi kami ke Kafka, dan kami memutuskan untuk tidak menggunakannya. Pendekatan yang kami ambil memungkinkan kami untuk mengganti Kafka dengan broker pesan lain tanpa perubahan sistem internal yang besar.Pendekatan ini menghilangkan kebutuhan untuk memiliki penyimpanan persistent disk untuk data tersebut. Sistem kami menggunakan Kafka sebagai perantara pesan dan dapat digunakan sebagai database dengan KSQL. [3] Tetapi menggunakannya akan sangat mengikat solusi kami ke Kafka, dan kami memutuskan untuk tidak menggunakannya. Pendekatan yang kami ambil memungkinkan kami untuk mengganti Kafka dengan broker pesan lain tanpa perubahan sistem internal yang besar.
Konsep ini tidak berarti bahwa kami tidak menggunakan penyimpanan disk dan basis data. Untuk memeriksa dan menganalisis kinerja sistem, kami perlu menyimpan sebagian besar data pada disk, yang mewakili berbagai indikator dan status. Poin penting di sini adalah bahwa algoritme waktu nyata tidak bergantung pada data semacam itu. Dalam kebanyakan kasus, kami menggunakan data yang disimpan untuk analisis offline, debugging, dan pelacakan kasus dan hasil tertentu yang dihasilkan sistem.
Masalah sistem kami
Ada masalah tertentu yang telah kami selesaikan hingga tingkat tertentu, tetapi mereka membutuhkan solusi yang lebih bijaksana. Untuk saat ini, saya hanya ingin menyebutkannya di sini, karena setiap poin bernilai artikel tersendiri.
- , , .
- . , .
- IF-ELSE ML. - : «ML — ». , ML, , . , , .
- .
- (true positive) . — , . , , — . , , .
- , .
- : , () .
- Terakhir tapi bukan yang akhir. Kami perlu membuat platform validasi kinerja yang luas di mana kami dapat menganalisis model kami. [4]