
Dapatkah kueri yang berjalan secara paralel menggunakan lebih sedikit CPU dan berjalan lebih cepat daripada kueri yang berjalan secara berurutan?
Iya! Untuk demonstrasi, saya akan menggunakan dua tabel dengan satu tipe kolom
integer.

Catatan - Skrip TSQL berupa teks ada di akhir artikel.
Menghasilkan data demo
Kami
#BuildIntmemasukkan 5.000 bilangan bulat acak ke dalam tabel (sehingga Anda memiliki nilai yang sama dengan milik saya, saya menggunakan RAND dengan seed dan loop WHILE). Masukkan 5.000.000 catatan ke dalam

tabel
#Probe.

Rencana berurutan
Sekarang mari kita tulis kueri untuk menghitung jumlah kecocokan nilai dalam tabel ini. Kami menggunakan petunjuk MAXDOP 1 untuk memastikan bahwa kueri tidak akan dijalankan secara paralel.
Berikut adalah rencana eksekusi dan statistiknya:

Kueri ini berjalan dalam 891ms dan menggunakan CPU 890ms .
Rencana paralel
Sekarang mari kita jalankan kueri yang sama dengan MAXDOP 2.

Kueri tersebut membutuhkan waktu 221 ms dan menggunakan CPU 436 ms . Waktu eksekusi telah berkurang empat kali lipat, dan penggunaan CPU berkurang setengahnya!
Bitmap Ajaib
Alasan mengapa eksekusi query paralel jauh lebih efisien adalah karena operator Bitmap.
Mari kita lihat lebih dekat rencana eksekusi sebenarnya untuk kueri paralel:

Dan bandingkan dengan rencana sekuensial:

Prinsip operator Bitmap didokumentasikan dengan baik, jadi di sini saya hanya akan memberikan deskripsi singkat dengan tautan ke dokumentasi di akhir artikel.
Hash Bergabung
Gabungan hash dilakukan dalam dua langkah:
- Tahap "membangun" (bahasa Inggris - build). Semua baris dari salah satu tabel dibaca dan tabel hash dibuat untuk kunci penghubung.
- Tahap "verifikasi" (bahasa Inggris - probe). Semua baris dari tabel kedua dibaca, hash dihitung dengan fungsi hash yang sama menggunakan kunci koneksi yang sama, dan keranjang yang cocok ditemukan di tabel hash.
Biasanya, karena kemungkinan benturan hash, masih perlu membandingkan nilai kunci yang sebenarnya.
Catatan penerjemah: untuk detail lebih lanjut tentang cara kerja hash join, lihat artikel Memvisualisasikan dan Berurusan dengan Hash Match Join
Bitmap dalam rencana berurutan
Banyak orang tidak tahu bahwa Hash Match, bahkan dalam permintaan berurutan, selalu menggunakan bitmap. Tetapi dalam rencana seperti itu, Anda tidak akan melihatnya secara eksplisit, karena ini adalah bagian dari implementasi internal operator Hash Match.
HASH JOIN pada tahap membangun dan membuat tabel hash menetapkan satu (atau lebih) bit dalam bitmap. Anda kemudian dapat menggunakan bitmap untuk secara efisien mencocokkan nilai hash tanpa biaya tambahan untuk mengakses tabel hash.
Dengan rencana sekuensial, hash dihitung untuk setiap baris dari tabel kedua dan diperiksa dengan bitmap. Jika bit yang sesuai dalam bitmap disetel, maka mungkin ada kecocokan dalam tabel hash, sehingga tabel hash diperiksa berikutnya. Sebaliknya, jika tidak ada bit yang sesuai dengan nilai hash yang ditetapkan, maka kita dapat memastikan bahwa tidak ada kecocokan dalam tabel hash, dan kita dapat segera membuang string yang dicentang.
Biaya yang relatif rendah untuk membuat bitmap diimbangi dengan penghematan waktu karena tidak memeriksa string yang tidak memiliki kecocokan persis dalam tabel hash. Pengoptimalan ini sering kali efektif karena memeriksa bitmap jauh lebih cepat daripada memeriksa tabel hash.
Bitmap dalam paket paralel
Dalam rencana paralel, bitmap ditampilkan sebagai pernyataan Bitmap terpisah.
Saat berpindah dari tahap konstruksi ke tahap verifikasi, bitmap diteruskan ke operator HASH MATCH dari sisi tabel kedua (probe). Minimal, bitmap diteruskan ke sisi probe sebelum JOIN dan operator pertukaran (Paralelisme).
Di sini, bitmap dapat mengecualikan string yang tidak memenuhi kondisi penggabungan sebelum diteruskan ke pernyataan pertukaran.
Tentu saja, tidak ada pernyataan pertukaran dalam rencana berurutan, jadi memindahkan bitmap ke luar HASH JOIN tidak memberikan manfaat tambahan apa pun atas bitmap "tertanam" di dalam pernyataan HASH MATCH.
Dalam beberapa situasi (meskipun hanya dalam rencana paralel), pengoptimal dapat memindahkan Bitmap lebih jauh ke bawah bidang di sisi probe koneksi.
Idenya di sini adalah bahwa semakin cepat baris difilter, semakin sedikit overhead yang diperlukan untuk memindahkan data antar pernyataan, dan bahkan mungkin untuk menghilangkan beberapa operasi.
Selain itu, pengoptimal biasanya mencoba menempatkan filter sederhana sedekat mungkin dengan daun: paling efisien untuk memfilter baris sedini mungkin. Namun, saya harus menyebutkan bahwa bitmap yang kita bicarakan ditambahkan setelah pengoptimalan selesai.
Keputusan untuk menambahkan jenis bitmap (statis) ini ke rencana setelah pengoptimalan dibuat berdasarkan selektivitas filter yang diharapkan (jadi statistik yang akurat itu penting).
Memindahkan filter bitmap
Mari kembali ke konsep memindahkan filter bitmap ke sisi probe koneksi.
Dalam banyak kasus, filter bitmap dapat dipindahkan ke pernyataan Pindai atau Cari. Ketika ini terjadi, predikat rencana terlihat seperti ini:

Ini berlaku untuk semua baris yang cocok dengan predikat pencarian (untuk Pencarian Indeks), atau semua baris untuk Indeks Scan atau Tabel Scan. Misalnya, tangkapan layar di atas menunjukkan filter bitmap yang diterapkan pada Pemindaian Tabel untuk tabel heap.
Lebih dalam ...
Jika filter bitmap dibuat pada satu kolom atau ekspresi tipe integer atau bigint, dan diterapkan ke satu kolom tipe integer atau bigint, maka operator Bitmap dapat dipindahkan lebih jauh lagi, bahkan lebih jauh daripada operator Seek atau Scan.
Predikat akan tetap muncul dalam pernyataan Pindai atau Cari seperti pada contoh di atas, tetapi sekarang akan ditandai dengan atribut INROW, yang berarti filter dipindahkan ke Mesin Penyimpanan dan diterapkan ke baris saat dibaca.
Dengan pengoptimalan ini, baris difilter sebelum Pemroses Kueri melihat baris tersebut. Hanya string yang cocok dengan HASH MATCH JOIN yang dikirim dari Storage Engine.
Kondisi di mana pengoptimalan ini diterapkan bergantung pada versi SQL Server. Misalnya, di SQL Server 2005, selain kondisi yang disebutkan sebelumnya, kolom probe harus ditetapkan sebagai NOT NULL. Batasan ini telah dilonggarkan di SQL Server 2008.
Anda mungkin bertanya-tanya bagaimana pengoptimalan INROW memengaruhi kinerja. Akankah memindahkan operator sedekat mungkin dengan Cari atau Pindai seefisien pemfilteran di Mesin Penyimpanan? Saya akan menjawab pertanyaan menarik ini di artikel lain. Dan di sini kita juga akan melihat MERGE JOIN dan NESTED LOOP JOIN.
Opsi GABUNG lainnya
Menggunakan loop bersarang tanpa indeks adalah ide yang buruk. Kami harus memindai sepenuhnya salah satu tabel untuk setiap baris dari tabel lain - total 5 miliar perbandingan. Permintaan ini mungkin membutuhkan waktu yang sangat lama.
Gabung Gabung
Jenis gabungan fisik ini memerlukan masukan yang diurutkan, jadi gabungan gabungan paksa menyebabkan pengurutan ada sebelumnya. Rencana sekuensial terlihat seperti ini:
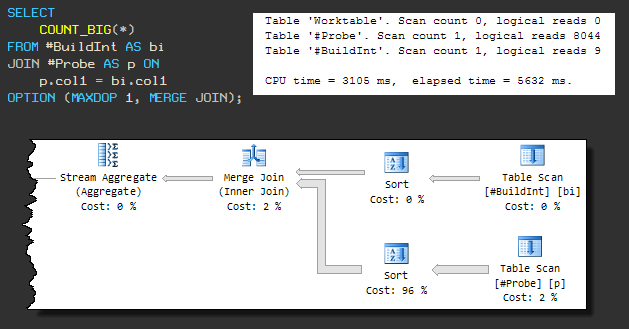
Kueri sekarang menggunakan CPU 3105ms , dan waktu eksekusi total 5632ms .
Peningkatan waktu eksekusi secara keseluruhan disebabkan oleh fakta bahwa salah satu operasi pengurutan menggunakan tempdb (meskipun SQL Server memiliki memori yang cukup untuk pengurutan).
Kebocoran ke tempdb terjadi karena algoritme pemberian memori default tidak mencadangkan cukup memori. Sampai kami memperhatikan hal ini, jelas bahwa permintaan tidak akan selesai dalam waktu kurang dari 3105 md.
Mari kita terus memaksa GABUNGAN GABUNG, tetapi memungkinkan paralelisme (MAXDOP 2):

Seperti dalam HASH JOIN paralel yang kita lihat sebelumnya, filter bitmap terletak di sisi lain dari GABUNGKAN GABUNG lebih dekat ke Pindai Tabel dan diterapkan menggunakan pengoptimalan INROW.
Dengan 468 ms CPU dan 240 ms waktu berlalu, MERGE JOIN dengan jenis tambahan hampir secepat HASH JOIN paralel ( 436 ms / 221 ms ).
Tetapi paralel MERGE JOIN memiliki satu kelemahan: ia mencadangkan 330KB memori berdasarkan jumlah baris yang diharapkan untuk disortir. Karena jenis bitmap ini digunakan setelah pengoptimalan biaya, tidak ada penyesuaian pada perkiraan, meskipun hanya 2.488 baris yang melewati urutan terbawah.
Pernyataan Bitmap hanya dapat muncul dalam rencana dengan GABUNGAN GABUNG dengan pernyataan pemblokiran berikutnya (misalnya, Urutkan). Operator pemblokiran harus menerima semua nilai yang diperlukan sebagai masukan sebelum menghasilkan baris pertama ke keluaran. Ini memastikan bahwa bitmap benar-benar penuh sebelum baris dari tabel JOIN dibaca dan diperiksa.
Tidak perlu pernyataan pemblokiran berada di sisi lain dari MERGE JOIN, tetapi penting di sisi mana bitmap digunakan.
Dengan indeks
Jika indeks yang sesuai tersedia, situasinya berbeda. Distribusi data "acak" kami sedemikian rupa sehingga
#BuildIntindeks unik dapat dibuat di atas tabel . Dan tabel #Probeberisi duplikat, jadi Anda harus bertahan dengan indeks non-unik:

Perubahan ini tidak akan mempengaruhi HASH JOIN (baik dalam serial dan paralel). HASH JOIN tidak dapat menggunakan indeks, jadi rencana dan kinerja tetap sama.
Gabung Gabung
MERGE JOIN tidak lagi perlu melakukan operasi gabungan banyak-ke-banyak dan tidak lagi memerlukan operator Sortir pada input.
Tidak adanya operator sortir pemblokiran berarti Bitmap tidak dapat digunakan.
Akibatnya, kami melihat rencana berurutan, terlepas dari parameter MAXDOP, dan kinerjanya lebih buruk daripada rencana paralel sebelum menambahkan indeks: 702 md CPU dan waktu berlalu 704 md :

Namun, ada peningkatan nyata atas rencana asli MERGE JOIN sekuensial ( 3105 md) / 5632 md ). Ini karena penghapusan penyortiran dan kinerja gabungan satu-ke-banyak yang lebih baik.
Loop Bersarang Bergabung
Seperti yang Anda duga, NESTED LOOP bekerja secara signifikan lebih baik. Mirip dengan MERGE JOIN, pengoptimal memutuskan untuk tidak menggunakan konkurensi:

Ini adalah paket yang paling efisien sejauh ini - hanya 16ms CPU dan 16ms menghabiskan waktu.
Tentu saja, ini mengasumsikan bahwa data yang diperlukan untuk menyelesaikan permintaan sudah ada di memori. Jika tidak, setiap pencarian di tabel probe akan menghasilkan I / O acak.
Pada kinerja laptop saya dari cache dingin NESTED LOOP membutuhkan 78 ms CPU dan 2152 ms, waktu yang telah berlalu. Dalam situasi yang sama, MERGE JOIN menggunakan 686 ms CPU dan 1471 ms . HASH JOIN - 391 ms CPU dan905 md .
MERGE JOIN dan HASH JOIN mendapatkan keuntungan dari I / O yang besar dan mungkin berurutan menggunakan read-ahead.
Sumber daya tambahan
Parallel Hash Join (Craig Freedman)
Query Execution Bitmap Filters (SQL Server Query Processing Team)
Bitmap di Microsoft SQL Server 2000 (artikel MSDN)
Menafsirkan Rencana Eksekusi yang Mengandung Filter Bitmap (Dokumentasi SQL Server)
Memahami Hash Joins (Dokumentasi SQL Server)
Uji skrip
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
Baca lebih banyak: