Machine Learning. Jaringan saraf (bagian 1): Proses pelatihan perceptron
Pada artikel ini, kita akan menggunakan jaringan saraf untuk memodelkan pelaksanaan operasi OR logis; XOR, yang merupakan jenis aplikasi "Hello World" untuk jaringan saraf.
Artikel ini akan menjelaskan langkah demi langkah proses pemodelan seperti itu menggunakan TensorFlow.js.
Jadi, mari kita membangun jaringan saraf untuk operasi OR logis. Pada bagian input, kita akan selalu mengirimkan dua sinyal X 1 dan X 2 , dan pada bagian keluaran kita akan menerima satu sinyal keluaran Y. Untuk melatih jaringan syaraf tiruan, kita juga membutuhkan training dataset (Gambar 1).

Gambar 1 - Dataset pelatihan dan model untuk memodelkan operasi OR logis
Untuk memahami struktur jaringan neural apa yang akan disetel, mari kita bayangkan set data pelatihan pada bidang koordinat dengan sumbu X 1 dan X 2 (Gambar 2, kiri).
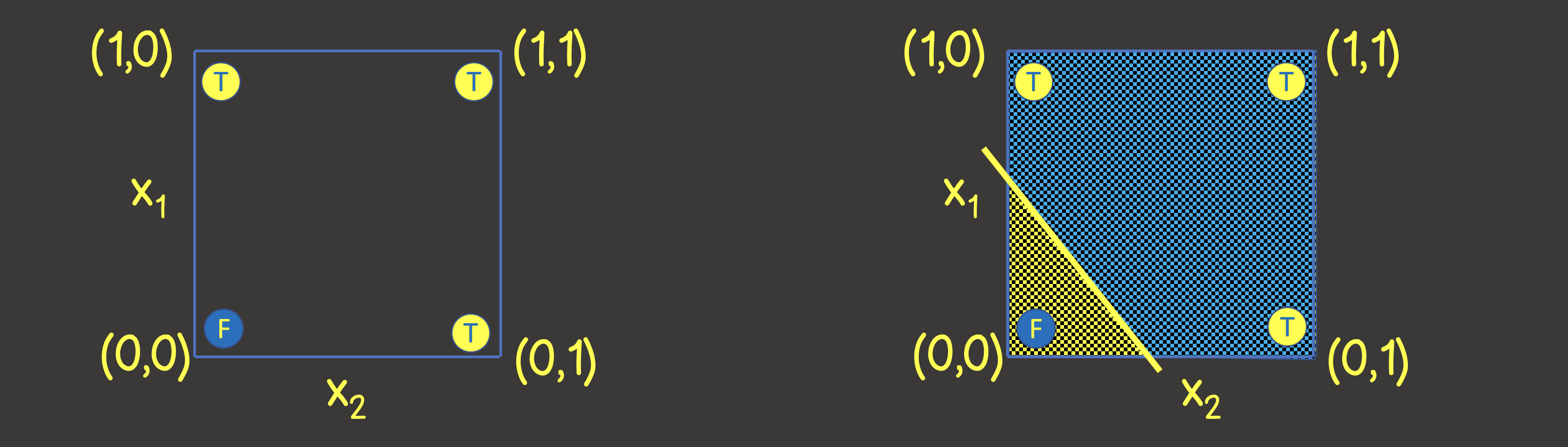
Gambar 2 - Pelatihan diatur pada bidang koordinat untuk operasi OR logis
Harap dicatat bahwa untuk menyelesaikan masalah ini, kita hanya perlu menggambar garis yang akan membagi bidang sedemikian rupa sehingga di satu sisi garis terdapat semua nilai TRUE , dan di sisi lain - semua nilai FALSE (Gambar 2, kanan). Kita juga tahu bahwa satu neuron dalam jaringan saraf (perceptron) dapat dengan sempurna mengatasi tujuan ini, nilai keluarannya dihitung dari sinyal masukan sebagai:
yang merupakan representasi matematis dari persamaan garis.
Mengingat nilai kita berada pada range 0 sampai 1, maka kita juga menerapkan fungsi aktivasi sigmoid. Jadi, jaringan saraf kita terlihat seperti pada Gambar 3.

Gambar 3 - Jaringan saraf untuk melatih operasi OR logis.
Jadi mari kita selesaikan masalah ini menggunakan TensorFlow.js.
Pertama, kita perlu mengubah set data pelatihan menjadi tensor. Tensor adalah wadah data yang bisa dimiliki sumbu dan jumlah sembarang elemen di sepanjang masing-masing sumbu. Kebanyakan tensor akrab dengan matematika - vektor (tensor dengan satu sumbu), matriks (tensor dengan dua sumbu - baris, kolom).
Untuk menentukan set data pelatihan, sumbu pertama (sumbu 0) selalu merupakan sumbu di mana semua contoh data yang tersedia berada (Gambar 4).
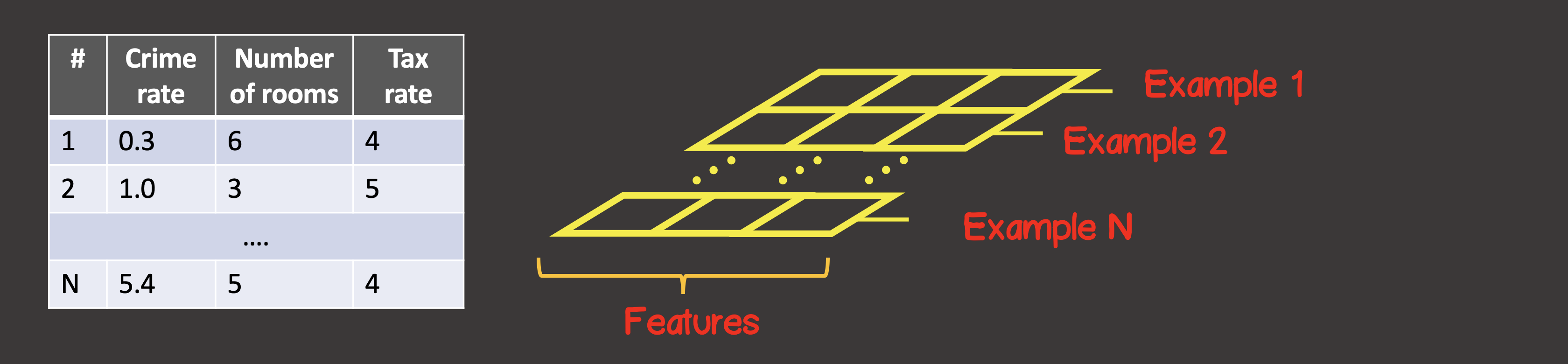
Gambar 4 - Struktur Tensor
Dalam kasus khusus kami, kami memiliki 4 contoh data sampel (Gambar 1), yang berarti bahwa tensor input sepanjang sumbu pertama akan memiliki 4 elemen. Setiap elemen sampel pelatihan adalah vektor yang terdiri dari dua elemen X1, X2... Jadi, tensor masukan memiliki 2 sumbu (matriks), sepanjang sumbu pertama ada 4 elemen, sepanjang sumbu kedua - 2 elemen.
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
Demikian juga, ubah keluaran menjadi tensor. Adapun sinyal input, sepanjang sumbu pertama kami memiliki 4 elemen, dan setiap elemen berisi vektor yang berisi satu nilai:
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
Mari buat model menggunakan TensorFlow API:
const model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 1, activation: 'sigmoid' })
);
Pembuatan model akan selalu dimulai dengan panggilan ke tf.sequential () . Blok bangunan utama model adalah lapisan. Kita dapat menghubungkan ke model sebanyak lapisan di jaringan saraf yang kita butuhkan. Di sini kita menggunakan lapisan padat , yang berarti setiap neuron di lapisan berikutnya memiliki koneksi dengan setiap neuron di lapisan sebelumnya. Misalnya, jika kita memiliki dua lapisan padat, di lapisan pertama neuron, dan yang kedua - , maka jumlah koneksi antar lapisan akan .
Dalam kasus kami, seperti yang dapat kita lihat, jaringan saraf terdiri dari satu lapisan, di mana terdapat satu neuron, oleh karena itu unit ditetapkan ke satu.
Juga, untuk lapisan pertama jaringan saraf, kita harus mengatur inputShape , karena setiap instance input diwakili oleh vektor dua nilai X1dan X2, oleh karena itu inputShape = [2] . Perhatikan bahwa inputShape tidak perludiseteluntuk lapisan perantara - TensorFlow dapat menentukan nilai ini dari nilai unit lapisan sebelumnya.
Juga, jika perlu, setiap lapisan dapat diberi fungsi aktivasi, kami menentukan di atas bahwa ini akan menjadi fungsi sigmoid. Fungsi aktivasi yang saat ini tersedia di TensorFlow dapat ditemukan di sini .
Selanjutnya, kita perlu mengkompilasi model (lihat API di sini ), sementara kita perlu mengatur dua parameter yang diperlukan - ini adalah fungsi kesalahan dan jenis pengoptimal yang akan mencari nilai minimumnya:
model.compile({
optimizer: tf.train.sgd(0.1),
loss: 'meanSquaredError'
});
Kami telah menetapkan penurunan gradien stokastik sebagai pengoptimal dengan langkah pelatihan 0,1.
Daftar pengoptimal yang diterapkan di pustaka: tf.train.sgd , tf.train.momentum , tf.train.adagrad , tf.train.adadelta , tf.train.adam , tf.train.adamax , tf.train.rmsprop .
Dalam praktiknya, secara default, Anda dapat langsung memilih pengoptimal adam , yang memiliki tingkat konvergensi model terbaik, berbeda dengan sgd - kecepatan pembelajaran di setiap tahap pelatihan disetel bergantung pada riwayat langkah sebelumnya dan tidak konstan selama seluruh proses pembelajaran.
Sebagai fungsi kesalahan, ini diberikan oleh fungsi root mean square error:
Model sudah ditetapkan, dan langkah selanjutnya adalah proses pelatihan model, untuk ini metode fit harus dipanggil pada model :
async function initModel() {
// skip for brevity
await model.fit(trainingInputTensor, trainingOutputTensor, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
// any actions on during any epoch of training
await tf.nextFrame();
}
}
})
}
Kami telah menetapkan bahwa proses pembelajaran harus terdiri dari 100 langkah pembelajaran (jumlah epochs pembelajaran); juga di setiap epoch yang berurutan - data input harus diacak dalam urutan acak ( shuffle = true ) - yang akan mempercepat proses konvergensi model, karena hanya ada beberapa contoh dalam dataset pelatihan kami (4).
Setelah proses pelatihan selesai, kita dapat menggunakan metode prediksi , yang berdasarkan sinyal masukan baru, akan menghitung nilai keluaran.
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
const output = model.predict(testInputTensor).arraySync();
Metode generateInputs hanya menghasilkan kumpulan data sampel 10x10 yang membagi bidang koordinat menjadi 100 kotak:
Kode lengkap diberikan di sini
import React, { useEffect, useState } from 'react';
import LossPlot from './components/LossPlot';
import Canvas from './components/Canvas';
import * as tf from "@tensorflow/tfjs";
let model;
export default () => {
const [data, changeData] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
async function initModel() {
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape:[2], units:1, activation: 'sigmoid'})
);
model.compile({
optimizer: tf.train.adam(0.1),
loss: 'meanSquaredError'
});
await model.fit(inputTensor, outputTensor, {
epochs: 100,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
changeLossHistory((prevHistory) => [...prevHistory, {
epoch,
loss
}]);
const output = model.predict(testInputTensor)
.arraySync();
changeData(() => output.map(([out], i) => ({
out,
x1: testInput[i][0],
x2: testInput[i][1]
})));
await tf.nextFrame();
}
}
})
}
initModel();
}, []);
return (
<div>
<Canvas data={data} squareAmount={10}/>
<LossPlot loss={lossHistory}/>
</div>
);
}
function generateInputs(squareAmount) {
const step = 1 / squareAmount;
const input = [];
for (let i = 0; i < 1; i += step) {
for (let j = 0; j < 1; j += step) {
input.push([i, j]);
}
}
return input;
}
Pada gambar berikut, Anda akan melihat bagian dari proses pembelajaran:

Implementasi Planker:
Simulasi operasi logis XOR
Kumpulan pelatihan untuk fungsi ini ditunjukkan pada Gambar 6, dan kami juga akan menempatkan titik-titik ini seperti yang kami lakukan untuk operasi logis ATAU pada bidang koordinat
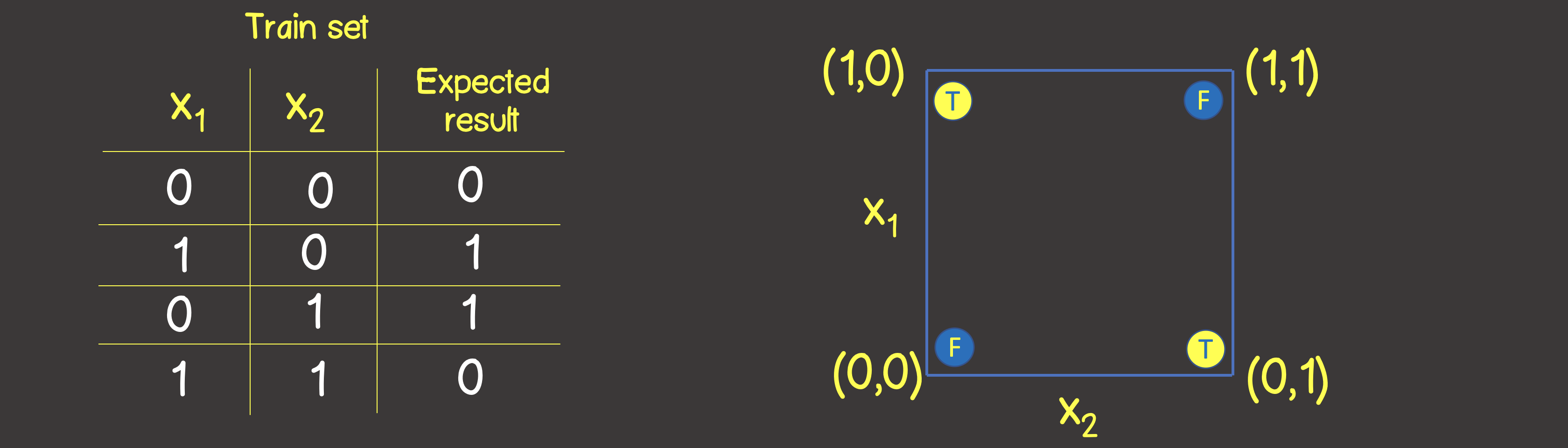
Gambar 6 - Dataset pelatihan dan model untuk pemodelan operasi logis EKSKLUSIF OR (XOR)
Harap dicatat bahwa tidak seperti operasi OR logis - Anda tidak dapat membagi bidang dengan satu garis lurus, sehingga di satu sisi terdapat semua nilai TRUE , dan di sisi lain - semua SALAH . Namun, kita dapat melakukan ini dengan menggunakan dua kurva (Gambar 7).
Jelas, dalam kasus ini, satu neuron dalam satu lapisan tidak cukup - setidaknya diperlukan satu lapisan lagi dengan dua neuron, yang masing-masing akan menentukan salah satu dari dua garis di bidang.
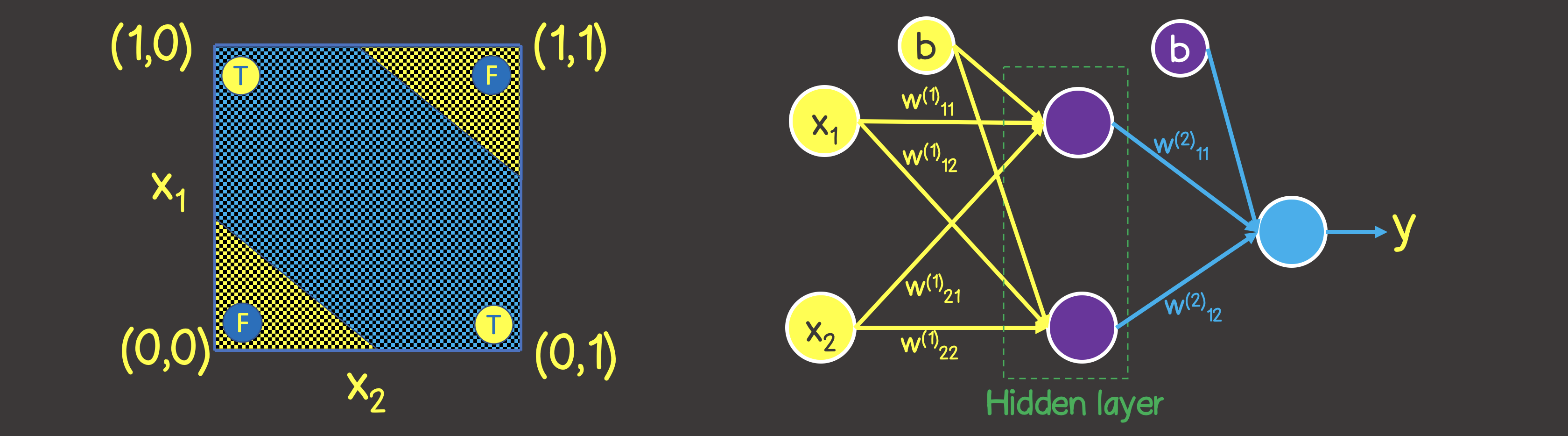
Gambar 7 - Model jaringan syaraf tiruan untuk operasi logis EXCLUSIVE OR (XOR)
Pada kode sebelumnya, kita perlu melakukan perubahan di beberapa tempat, salah satunya adalah training dataset itu sendiri:
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [0]]
const outputTensor = tf.tensor(output, [output.length, 1]);
Tempat kedua adalah struktur model yang diubah, menurut Gambar 7:
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 2, activation: 'sigmoid' })
);
model.add(
tf.layers.dense({ units: 1, activation: 'sigmoid' })
);
Proses pembelajaran dalam hal ini terlihat seperti ini:

Implementasi Planker:
Topik artikel selanjutnya
Pada artikel selanjutnya kami akan menjelaskan bagaimana menyelesaikan masalah yang berkaitan dengan klasifikasi objek ke dalam kategori, berdasarkan daftar beberapa fitur.