
Tujuan artikel ini adalah untuk berbagi pengalaman pertama kami dengan MLflow .
Kami akan memulai tinjauan kami tentang MLflow dari server pelacakannya dan melanjutkan melalui semua iterasi studi. Kemudian kami akan berbagi pengalaman kami menghubungkan Spark ke MLflow menggunakan UDF.
Konteks
Di Alpha Health, kami menggunakan pembelajaran mesin dan kecerdasan buatan untuk memberdayakan orang-orang untuk menjaga kesehatan dan kesejahteraan mereka. Inilah alasan mengapa model pembelajaran mesin menjadi inti dari produk data yang kami kembangkan, itulah sebabnya perhatian kami tertuju pada MLflow, platform sumber terbuka yang mencakup semua aspek siklus pembelajaran mesin.
MLflow
Tujuan utama MLflow adalah menyediakan lapisan tambahan di atas pembelajaran mesin yang akan memungkinkan data scientist bekerja dengan hampir semua library machine learning ( h2o , keras , mleap , pytorch , sklearn , dan tensorflow ), membawa pekerjaannya ke level berikutnya.
MLflow menyediakan tiga komponen:
- Pelacakan - merekam dan membuat kueri eksperimen: kode, data, konfigurasi, dan hasil. Sangat penting untuk mengikuti proses pembuatan model.
- Proyek - Format kemasan untuk dijalankan di platform apa pun (mis. SageMaker )
- Model adalah format umum untuk mengirimkan model ke berbagai alat penerapan.
MLflow (alfa pada saat penulisan ini) adalah platform open source yang memungkinkan Anda mengelola siklus proses machine learning, termasuk eksperimen, penggunaan kembali, dan penerapan.
Mengonfigurasi MLflow
Untuk menggunakan MLflow, pertama-tama Anda perlu menyiapkan seluruh lingkungan Python, untuk itu kami akan menggunakan PyEnv (untuk menginstal Python di Mac, lihat di sini ). Jadi kita dapat membuat lingkungan virtual tempat kita akan menginstal semua perpustakaan yang diperlukan untuk dijalankan.
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```Instal perpustakaan yang diperlukan.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```Catatan: kami menggunakan PyArrow untuk menjalankan model seperti UDF. Versi PyArrow dan Numpy perlu diperbaiki karena versi terbaru saling bertentangan.
Luncurkan UI Pelacakan
Pelacakan MLflow memungkinkan kita untuk mencatat dan membuat permintaan ke eksperimen menggunakan Python dan REST API. Selain itu, Anda dapat menentukan tempat menyimpan artefak model (localhost, Amazon S3 , Azure Blob Storage , Google Cloud Storage, atau server SFTP ). Karena kami menggunakan AWS di Alpha Health, S3 akan digunakan sebagai penyimpanan artefak.
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3://<bucket>/mlflow/artifacts/ \
--host localhost
--port 5000MLflow merekomendasikan penggunaan penyimpanan file persisten. Penyimpanan file adalah tempat server akan menyimpan metadata yang dijalankan dan eksperimen. Saat memulai server, pastikan server mengarah ke penyimpanan file yang persisten. Di sini kami hanya akan menggunakannya untuk percobaan
/tmp.
Ingatlah bahwa jika kita ingin menggunakan server mlflow untuk menjalankan percobaan lama, mereka harus ada di penyimpanan file. Namun, bahkan tanpa ini, kami dapat menggunakannya di UDF, karena kami hanya memerlukan jalur ke model.
Catatan: Perlu diingat bahwa UI Pelacakan dan klien model harus memiliki akses ke lokasi artefak. Artinya, terlepas dari fakta bahwa UI Pelacakan terletak di instans EC2, saat MLflow diluncurkan secara lokal, mesin harus memiliki akses langsung ke S3 untuk menulis model artefak.
Tracking UI menyimpan artefak dalam bucket S3
Model lari
Setelah Server Pelacakan berjalan, Anda dapat mulai melatih model.
Sebagai contoh, kami akan menggunakan modifikasi wine dari contoh MLflow di Sklearn .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csvSeperti yang telah kami katakan, MLflow memungkinkan Anda mencatat parameter, metrik, dan artefak model sehingga Anda dapat melacak bagaimana mereka berkembang saat Anda mengulang. Fitur ini sangat berguna, karena dengan cara ini kita dapat mereproduksi model terbaik dengan menghubungi server Pelacakan atau dengan memahami kode mana yang telah melakukan iterasi yang diperlukan menggunakan log komit hash git.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")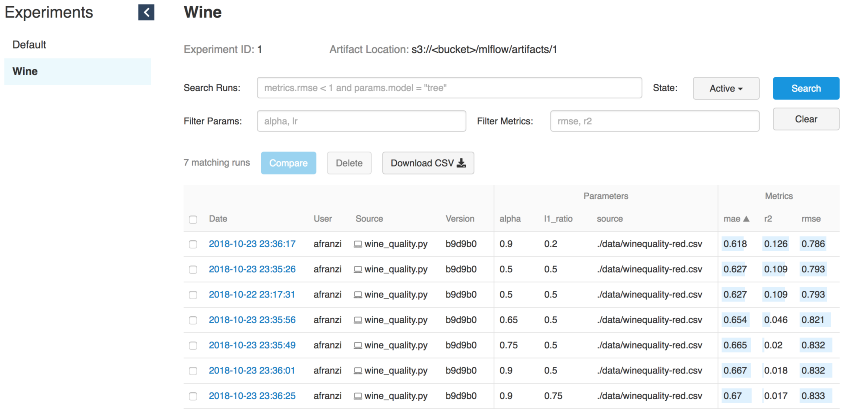
Iterasi anggur
Bagian server untuk model
Server pelacakan MLflow, diluncurkan dengan perintah "server mlflow", memiliki REST API untuk melacak peluncuran dan menulis data ke sistem file lokal. Anda dapat menentukan alamat server pelacakan menggunakan variabel lingkungan "MLFLOW_TRACKING_URI" dan API pelacakan MLflow akan secara otomatis menghubungi server pelacakan di alamat ini untuk membuat / mendapatkan informasi peluncuran, metrik log, dll.Untuk menyediakan model dengan server, kita memerlukan server pelacakan yang sedang berjalan (lihat antarmuka peluncuran) dan ID Proses model.
Sumber: Docs // Menjalankan server pelacakan

Jalankan ID
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path modelUntuk melayani model menggunakan fungsionalitas pelayanan MLflow, kita memerlukan akses ke UI Pelacakan untuk mendapatkan informasi tentang model hanya dengan menentukan
--run_id.
Setelah model berkomunikasi dengan Server Pelacakan, kita bisa mendapatkan titik akhir model baru.
# Query Tracking Server Endpoint
curl -X POST \
http://127.0.0.1:5005/invocations \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Menjalankan model dari Spark
Terlepas dari kenyataan bahwa server Pelacakan cukup kuat untuk menyajikan model secara real time, latih mereka dan gunakan fungsi penyajian (sumber: mlflow // docs // models # local ), menggunakan Spark (batch atau streaming) adalah solusi yang lebih kuat untuk akun distribusi.
Bayangkan Anda baru saja melakukan pelatihan offline lalu menerapkan model keluaran ke semua data Anda. Di sinilah Spark dan MLflow akan menunjukkan yang terbaik.
Instal PySpark + Jupyter + Spark
Sumber: Memulai PySpark - Jupyter
Untuk menunjukkan bagaimana kita menerapkan model MLflow ke dataframe Spark, kita perlu menyiapkan notebook Jupyter untuk bekerja sama dengan PySpark.
Mulailah dengan menginstal Apache Spark versi stabil terbaru :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀Instal PySpark dan Jupyter di lingkungan virtual:
pip install pyspark jupyterSiapkan variabel lingkungan:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"Setelah ditentukan
notebook-dir, kita bisa menyimpan notebook kita di folder yang diinginkan.
Meluncurkan Jupyter dari PySpark
Karena kami dapat mengatur Jupiter sebagai driver PySpark, kami sekarang dapat menjalankan notebook Jupyter dalam konteks PySpark.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
Seperti disebutkan di atas, MLflow menyediakan fungsi untuk mencatat artefak model di S3. Segera setelah kami memiliki model yang dipilih di tangan kami, kami memiliki kesempatan untuk mengimpornya sebagai UDF menggunakan modul
mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark - Menghasilkan Prediksi Kualitas Anggur
Sampai titik ini, kita telah membicarakan tentang cara menggunakan PySpark dengan MLflow dengan menjalankan prediksi kualitas anggur di seluruh kumpulan data anggur. Tetapi bagaimana jika Anda perlu menggunakan modul Python MLflow dari Scala Spark?
Kami menguji ini juga dengan membagi konteks Spark antara Scala dan Python. Artinya, kami mendaftarkan MLflow UDF dengan Python, dan menggunakannya dari Scala (ya, mungkin bukan solusi terbaik, tapi apa yang kami miliki).
Scala Spark + MLflow
Untuk contoh ini, kami akan menambahkan Toree Kernel ke Jupiter yang ada.
Instal Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```Seperti yang Anda lihat dari notebook terlampir, UDF terbagi antara Spark dan PySpark. Kami berharap bagian ini akan bermanfaat bagi mereka yang menyukai Scala dan ingin menerapkan model pembelajaran mesin ke produksi.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf.<locals>.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Langkah selanjutnya
Meskipun MLflow ada di Alpha pada saat penulisan, ini terlihat cukup menjanjikan. Hanya kemampuan untuk menjalankan beberapa kerangka kerja pembelajaran mesin dan menggunakannya dari satu titik akhir membawa sistem pemberi rekomendasi ke tingkat berikutnya.
Selain itu, MLflow mendekatkan Data Engineer dan Data Scientist dengan membuat lapisan umum di antara mereka.
Setelah melakukan penelitian tentang MLflow ini, kami yakin kami akan melanjutkan dan menggunakannya untuk pipeline Spark dan sistem pemberi rekomendasi.
Alangkah baiknya untuk menyinkronkan penyimpanan file dengan database daripada sistem file. Dengan cara ini kita perlu mendapatkan beberapa titik akhir yang dapat menggunakan penyimpanan file yang sama. Misalnya, gunakan beberapa contoh Prestodan Athena dengan Glue metastore yang sama.
Sebagai rangkuman, saya ingin berterima kasih kepada komunitas MLFlow karena telah membuat pekerjaan kami dengan data menjadi lebih menarik.
Jika Anda bermain dengan MLflow, silakan menulis kepada kami dan memberi tahu kami bagaimana Anda menggunakannya, dan terlebih lagi jika Anda menggunakannya dalam produksi.
Pelajari lebih lanjut tentang kursus:
Pembelajaran Mesin. Kursus Pembelajaran Mesin Dasar
. Kursus lanjutan
Baca lebih banyak: