Tetapi semua solusi ini tidak memiliki apa yang saya butuhkan:
- Instalasi terpusat
- Hasil pencarian memperhitungkan hak akses
- Cari berdasarkan konten dokumen
- Morfologi
Dan saya memutuskan untuk membuatnya sendiri.
Saya akan mengungkapkan poin demi poin apa yang saya miliki dalam bentuk untuk menghindari perbedaan interpretasi dan kesalahpahaman.
Instalasi terpusat - eksekusi klien-server. Semua solusi di atas memiliki satu masalah mendasar - setiap pengguna membuat indeks pencarian lokalnya sendiri, yang, dalam kasus volume penyimpanan yang besar, penundaan pengindeksan, profil pengguna di mesin bertambah, dan umumnya tidak nyaman jika ada karyawan baru yang datang atau pindah ke mesin baru.
Hasil pencarian memperhitungkan hak - semuanya sederhana di sini - hasil harus sesuai dengan hak karyawan atas resource file. Jika tidak, ternyata meskipun karyawan tersebut tidak memiliki hak atas sumber daya, dia dapat membaca semuanya dari cache pencarian. Ini akan menjadi canggung, setuju? Cari berdasarkan konten dokumen - cari berdasarkan teks dokumen, semuanya jelas, menurut saya, dan tidak ada perbedaan.
Morfologi bahkan lebih sederhana. Ditentukan dalam kueri "pisau" dan menerima "pisau" dan "pisau", "pisau" dan "pisau". Diharapkan ini bekerja untuk Rusia dan Inggris.
Kami telah memutuskan perumusan masalah, kami dapat melanjutkan ke implementasi.
Sebagai mesin pencari, saya memilih sistem Sphinx, dan bahasa pengembangan antarmukanya adalah C # dan .net, dan sebagai hasilnya, proyek tersebut dinamai Vidocq (Vidocq) sesuai nama detektif Prancis. Yah, seperti, ia menemukan segalanya dan hanya itu.
Secara arsitektural, aplikasinya terlihat seperti ini:
Robot pencarian secara rekursif merayapi sumber daya file dan memproses file sesuai dengan daftar ekstensi yang diberikan. Pemrosesan terdiri dari mengambil konten file, mengompresi teks - tanda kutip, koma, spasi ekstra, dll. Dihapus dari teks, kemudian konten ditempatkan di database (MS SQL), tanggal penempatan ditandai dan robot bergerak.
Pengindeks Sphins bekerja secara langsung dengan basis yang diterima, membentuk indeksnya sendiri dan mengembalikan penunjuk ke file yang ditemukan dan cuplikan dari fragmen teks yang ditemukan sebagai respons.
Formulir dikembangkan dalam C # yang dikomunikasikan dengan Sphinx melalui konektor MySQL. Sphinx memberikan array file sesuai dengan permintaan, kemudian array tersebut difilter untuk hak akses pengguna yang melakukan pencarian, keluarannya diformat dan ditampilkan kepada pengguna.
Kami perlu menyimpan informasi berikut tentang file:
- ID file
- Nama file
- Jalur ke file
- Isi file
- Ekspansi
- Tanggal ditambahkan ke pangkalan
Ini semua dilakukan dalam satu tabel dan robot pencari akan menambahkan semuanya ke dalamnya. Penambahan tanggal diperlukan agar pada saat robot pada putaran berikutnya membandingkan tanggal modifikasi file dengan tanggal masuknya ke database, dan jika tanggal berbeda maka update informasi tentang file tersebut.
Kemudian siapkan mesin pencari itu sendiri. Saya tidak akan menjelaskan keseluruhan konfigurasi, itu akan tersedia di arsip proyek, tetapi saya hanya akan membahas poin-poin utama.
Permintaan utama yang membentuk basis
dokumen sumber: documents_base
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}Menyiapkan morfologi melalui lemmatizer.
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}Setelah itu, Anda dapat mengatur pengindeks di pangkalan dan memeriksa pekerjaan.
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateDi sini jalur ke pengindeks diikuti dengan nama indeks untuk menempatkan yang diproses, jalur ke konfigurasi dan tanda –rotate berarti bahwa pengindeksan akan dilakukan berdasarkan keuntungan, yaitu dengan layanan pencarian berjalan. Setelah pengindeksan selesai, indeks akan diganti dengan yang diperbarui.
Kami memeriksa pekerjaan di konsol. Sebagai antarmuka, Anda dapat menggunakan klien MySQL, yang diambil, misalnya, dari kit server web.
mysql -h 127.0.0.1 -P 9306setelah itu request pilih id dari documets; harus mengembalikan daftar dokumen yang diindeks, jika, tentu saja, Anda memulai layanan Sphinx itu sendiri dan melakukan semuanya dengan benar.
Oke, konsolnya bagus, tapi kami tidak akan memaksa pengguna untuk mengetikkan perintah, bukan?
Saya membuat sketsa formulir seperti ini
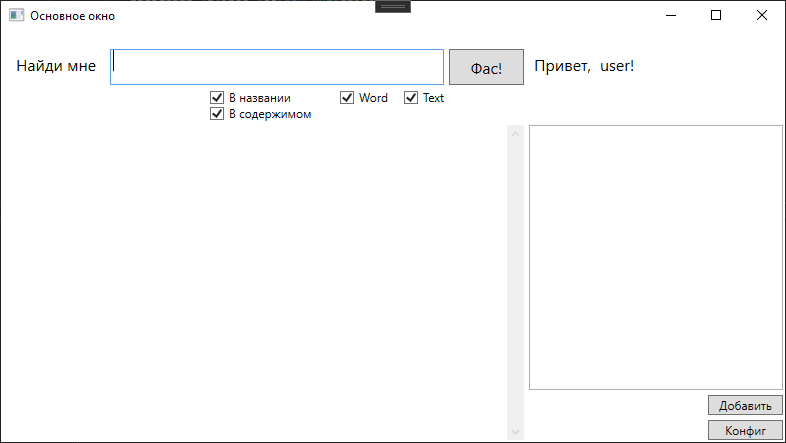
Dan di sini dengan hasil pencarian

Ketika Anda mengklik hasil tertentu, dokumen terbuka.
Bagaimana diimplementasikan.
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}Ya, ada kode bydloc, tapi ini adalah MVP.
Sebenarnya, permintaan ke Sphinx terbentuk di sini, bergantung pada kotak centang yang disetel. Kotak centang menunjukkan jenis file yang akan dicari dan area pencarian.
Kemudian permintaan tersebut masuk ke Sphinx, dan kemudian hasilnya diurai.
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}Pada tahap yang sama, masalah muncul. Setiap elemen masalah adalah kotak teks kaya dengan acara untuk membuka dokumen saat diklik. Item ditempatkan di StackPanel dan sebelum file tersebut diperiksa untuk pengguna. Dengan demikian, file yang tidak dapat diakses oleh pengguna tidak akan disertakan dalam output.
Keuntungan dari solusi ini:
- Pengindeksan dilakukan secara terpusat
- Tampilan akurat berdasarkan hak akses
- Pencarian yang dapat disesuaikan menurut jenis dokumen
Tentu saja, untuk pengoperasian penuh solusi seperti itu, arsip file harus diatur dengan benar di perusahaan. Idealnya, profil pengguna roaming dan sebagainya harus dikonfigurasi. Dan ya, saya tahu tentang SharePoint, Pencarian Windows, dan kemungkinan besar beberapa solusi lainnya. Kemudian Anda bisa tanpa henti mendiskusikan pilihan platform pengembangan, mesin pencari Sphinx, Manticore atau Elastic, dan seterusnya. Tetapi saya tertarik untuk memecahkan masalah dengan alat yang saya sedikit mengerti. Saat ini berjalan dalam mode MVP, tetapi saya sedang mengembangkannya.
Tetapi bagaimanapun, saya siap mendengarkan saran Anda tentang poin apa yang dapat ditingkatkan atau diulang sejak awal.