Kami akan memberi tahu Anda mengapa alat ini muncul dan apa fungsinya.

Kurangnya algoritme
Salah satu tantangan utama dalam pembelajaran mesin adalah pengurangan dimensi data. Ilmuwan Data mengurangi jumlah variabel dengan mengisolasi di antara mereka nilai-nilai yang memiliki dampak terbesar pada hasil. Setelah operasi ini, model pembelajaran mesin membutuhkan lebih sedikit memori, bekerja lebih cepat, dan lebih baik. Contoh di bawah ini menunjukkan bahwa menghilangkan fitur duplikat meningkatkan akurasi klasifikasi dari 0,903 menjadi 0,943.
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334Ada dua pendekatan untuk pengurangan dimensi - desain fitur dan pemilihan fitur. Dalam bidang seperti bioinformatika dan kedokteran, yang terakhir lebih sering digunakan, karena memungkinkan Anda menyoroti fitur-fitur penting sambil mempertahankan semantik, yaitu, tidak mengubah arti asli fitur. Namun, pustaka pembelajaran mesin Python yang paling umum - scikit-learn, pytorch, keras, tensorflow - kekurangan satu set lengkap metode pemilihan fitur.
Untuk mengatasi masalah ini, mahasiswa dan pascasarjana ITMO University telah mengembangkan perpustakaan terbuka - ITMO_FS. Sebuah tim sedang mengerjakannya di bawah kepemimpinan Ivan Smetannikov, Associate Professor dari Fakultas Teknologi Informasi dan Pemrograman, Wakil Kepala Laboratorium Machine Learning. Pengembang utama - Nikita Pilnenskiy, lulus dari gelar Master dalam Pembelajaran Mesin dan Analisis Data . Sekarang dia masuk sekolah pascasarjana.
« , . , , , (-) .
, , , . , , , ».
—
ITMO_FS diimplementasikan dengan Python dan kompatibel dengan scikit-learn, yang secara de facto dianggap sebagai alat analisis data utama. Para pemilih fiturnya mengambil parameter yang sama:
data: array-like (2-D list, pandas.Dataframe, numpy.array);
targets: array-like (1-D list, pandas.Series, numpy.array).Pustaka mendukung semua pendekatan klasik untuk pemilihan fitur - filter, pembungkus, dan metode sebaris. Diantaranya adalah algoritma seperti filter berdasarkan korelasi Spearman dan Pearson, Fit Criterion, QPFS, hill climbing filter dan lain - lain .

Pustaka juga mendukung ansambel pelatihan dengan menggabungkan algoritme pemilihan fitur berdasarkan ukuran signifikansi yang digunakan di dalamnya. Pendekatan ini memungkinkan Anda memperoleh hasil prediksi yang lebih tinggi dengan investasi waktu yang rendah.
Apa analognya
Tidak banyak perpustakaan algoritma pemilihan fitur, terutama dengan Python. Salah satu yang terbesar dianggap sebagai pengembangan insinyur dari Arizona State University (ASU). Ini mendukung sejumlah besar algoritme, tetapi hampir tidak diperbarui baru-baru ini.
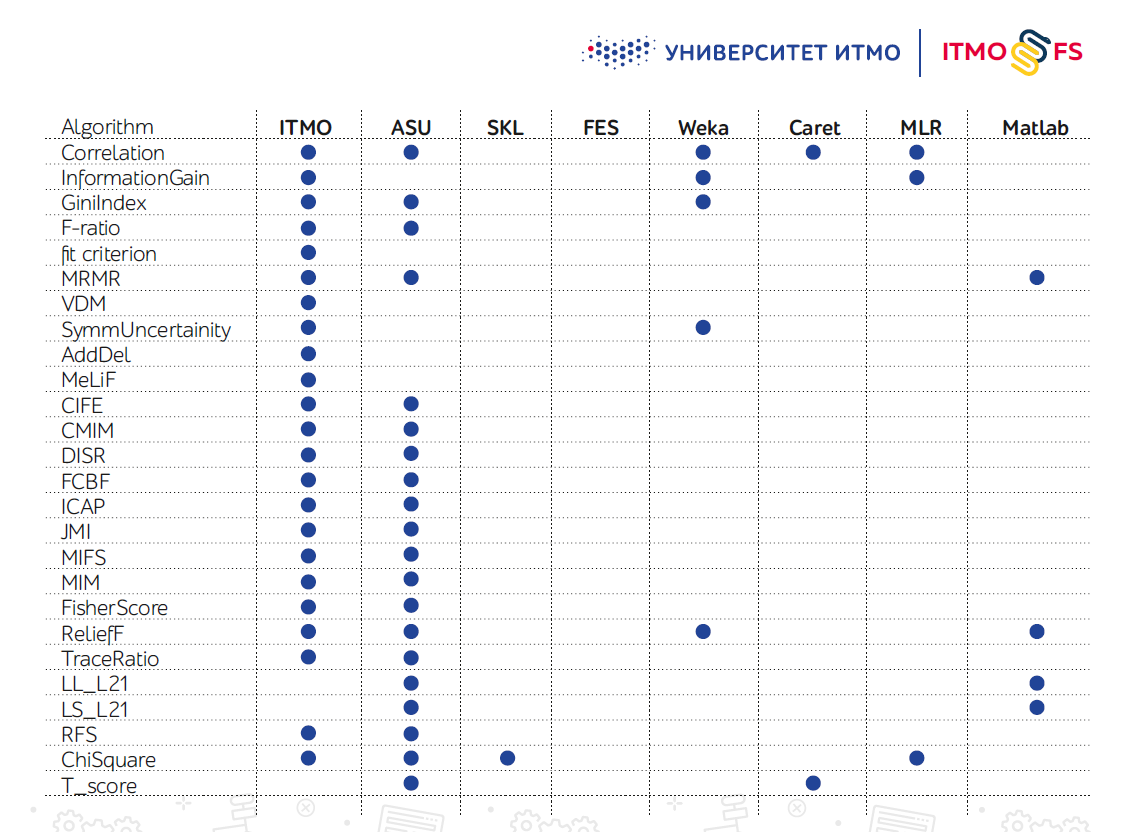
Scikit-learn sendiri juga memiliki beberapa mekanisme pemilihan fitur, tetapi dalam praktiknya, mekanisme tersebut tidak cukup.
"Secara umum, selama lima hingga tujuh tahun terakhir, fokus telah bergeser ke algoritme ensembel untuk pemilihan fitur, tetapi mereka tidak terwakili secara khusus dalam pustaka semacam itu, yang juga ingin kami perbaiki."
- Ivan Smetannikov
Prospek proyek
Penulis ITMO_FS berencana untuk mengintegrasikan produk mereka dengan scikit-learn dengan menambahkannya ke daftar pustaka resmi yang kompatibel. Saat ini, pustaka tersebut sudah berisi algoritme pemilihan fitur dalam jumlah terbesar di antara semua pustaka, tetapi penambahannya terus berlanjut. Lebih lanjut di peta jalan adalah penambahan algoritme baru, termasuk perkembangan kami sendiri.
Dalam rencana yang lebih jauh, ada tugas untuk memperkenalkan perpustakaan ke dalam sistem pembelajaran meta, menambahkan algoritme untuk pekerjaan langsung dengan data matriks (mengisi celah, menghasilkan data ruang atribut-meta, dll.), Serta antarmuka grafis. Sejalan dengan ini, hackathon akan diadakan menggunakan perpustakaan untuk menarik lebih banyak pengembang pada produk dan mendapatkan umpan balik.
Diharapkan ITMO_FS akan menemukan aplikasi di bidang kedokteran dan bioinformatika - dalam masalah seperti diagnosis berbagai kanker, konstruksi model prediktif karakteristik fenotipik (misalnya, usia seseorang) dan sintesis obat.
Dimana saya bisa mendownload
Jika Anda tertarik dengan proyek ITMO_FS, Anda dapat mengunduh pustaka dan mencobanya dalam praktik - berikut adalah repositori di GitHub . Versi awal dokumentasi tersedia di readthedocs . Di sana Anda juga dapat melihat petunjuk instalasi (didukung oleh pip). Kami menerima umpan balik apapun.
Materi tambahan dari blog kami di Habré: