Parsing
Apa itu parsing? Ini adalah pengumpulan dan sistematisasi informasi yang diposting di situs web menggunakan program khusus yang mengotomatiskan prosesnya.
Penguraian biasanya digunakan untuk analisis harga dan pengambilan konten.
Mulailah
Untuk mengumpulkan uang dari bandar taruhan, saya harus segera menerima informasi tentang peluang kejadian tertentu dari beberapa situs. Kami tidak akan masuk ke bagian matematika.
Karena saya belajar C # di sharaga saya, saya memutuskan untuk menulis semua isinya. Orang-orang di Stack Overflow menyarankan untuk menggunakan Selenium WebDriver. Ini adalah driver browser (pustaka perangkat lunak) yang memungkinkan Anda mengembangkan program yang mengontrol perilaku browser. Itulah yang kita butuhkan, pikirku.
Saya menginstal perpustakaan dan berlari untuk menonton panduan di Internet. Setelah beberapa saat, saya menulis program yang dapat membuka browser dan mengikuti beberapa tautan.
Hore! Meskipun berhenti, bagaimana cara menekan tombol, bagaimana mendapatkan informasi yang diperlukan? XPath akan membantu kami di sini.
XPath
Secara sederhana, ini adalah bahasa untuk menanyakan elemen dokumen XML dan XHTML.
Untuk artikel ini, saya akan menggunakan Google Chrome. Namun, peramban modern lainnya harus memiliki, jika tidak sama, maka antarmuka yang sangat mirip.
Untuk melihat kode halaman tempat Anda berada, tekan F12.

Untuk melihat di mana dalam kode terdapat elemen pada halaman (teks, gambar, tombol), klik panah di sudut kiri atas dan pilih elemen ini pada halaman. Sekarang mari beralih ke sintaks.
Sintaks standar untuk menulis XPath:
// tagname [@ atribut = 'value']
// : Memilih semua node dalam dokumen html mulai dari node saat ini
Tagname : Tag dari node saat ini.
@ : Memilih atribut
Atribut : Nama atribut dari node.
Nilai : Nilai atribut.
Awalnya mungkin tidak jelas, tetapi setelah contoh semuanya harus diatur.
Mari kita lihat beberapa contoh sederhana:
// input [@ type = 'text']
// label [@ id = 'l25']
// input [@ value = '4']
// a [@ href = 'www.walmart. com ']
Pertimbangkan contoh yang lebih kompleks untuk html'i yang diberikan:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class = 'contentBlock'] // div
Elemen berikut akan dipilih untuk XPath ini:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class = 'contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>Perhatikan perbedaan antara / (mengambil dari simpul akar) dan // (mengambil simpul dari simpul saat ini terlepas dari lokasinya). Jika kurang jelas, maka lihat kembali contoh di atas.
// div [@ class = 'contentBlock'] / div [@ class = 'listItem'] / a [@ class = 'link'] / span [@ class = 'name']
Permintaan ini sama dengan html ini :
// div / div / a / span
// span [@ class = 'name']
// a [@ class = 'link'] / span [@ class = 'name']
// a [@ class = ' link 'danhref= 'habr.com'] / span
// span [text () = 'habr' atau text () = 'habrhabr']
// div [@ class = 'listItem'] // span [@ class = 'name' ]
// a [berisi (href, 'habr')] / span
// span [contains (text (), 'habr')]
Hasil:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// span [text () = 'habr'] / parent :: a / parent :: div
Sama dengan
// div / div [@ class = 'listItem'] [1]
Hasil:
<div class = 'listItem'>parent :: - Mengembalikan induk satu level ke atas.
Ada juga fitur yang sangat keren seperti following-sibling :: - mengembalikan banyak elemen pada level yang sama mengikuti level saat ini, mirip dengan preceding-sibling :: - mengembalikan banyak elemen pada level yang sama sebelum level saat ini.
// span [@ class = 'name'] / following-sibiling :: text () [1]
Hasil:
"text1"
"text2"Saya pikir itu lebih jelas sekarang. Untuk mengkonsolidasikan materi, saya menyarankan Anda untuk pergi ke situs ini dan menulis beberapa permintaan untuk menemukan beberapa elemen html'i ini.
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>Sekarang kita tahu apa itu XPath, mari kita kembali menulis kodenya. Karena moderator Habr tidak menyukai bandar taruhan, mereka akan mengurai harga kopi di Walmart
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleep's ditulis sehingga halaman web punya waktu untuk memuat.
Program ini akan membuka situs web toko Walmart, menekan beberapa tombol, membuka bagian kopi dan mendapatkan nama dan harga barang.
Jika halaman web cukup besar dan oleh karena itu XPath membutuhkan waktu lama atau sulit untuk ditulis, maka Anda perlu menggunakan beberapa metode lain.
Permintaan HTTP
Pertama, mari kita lihat bagaimana konten muncul di situs.

Dengan kata sederhana, browser membuat permintaan ke server dengan permintaan untuk memberikan informasi yang diperlukan, dan server, pada gilirannya, memberikan informasi ini. Semua ini dilakukan dengan menggunakan permintaan HTTP.
Untuk melihat permintaan yang dikirimkan browser Anda di situs tertentu, cukup buka situs ini, tekan F12 dan buka tab Jaringan, lalu muat ulang halaman.

Sekarang tinggal menemukan permintaan yang kita butuhkan.
Bagaimana cara melakukannya? - pertimbangkan semua permintaan dengan jenis pengambilan (kolom ketiga pada gambar di atas) dan lihat tab Pratinjau.

Jika tidak kosong maka harus dalam format XML atau JSON, jika tidak, cari terus. Jika demikian, lihat apakah informasi yang Anda butuhkan ada di sini. Untuk memeriksa ini, saya menyarankan Anda untuk menggunakan semacam JSON Viewer atau XML Viewer (google dan buka tautan pertama, salin teks dari tab Respon dan tempelkan ke Viewer). Ketika Anda menemukan permintaan yang Anda butuhkan, maka simpan namanya (kolom kiri) atau host URL (tab Headers) di suatu tempat, agar Anda tidak mencari nanti. Misalnya, jika departemen kopi dibuka di situs web walmart, maka permintaan akan dikirim, yang hukumnya dimulai dengan walmart.com/cp/api/wpa. Akan ada semua informasi tentang kopi yang dijual.
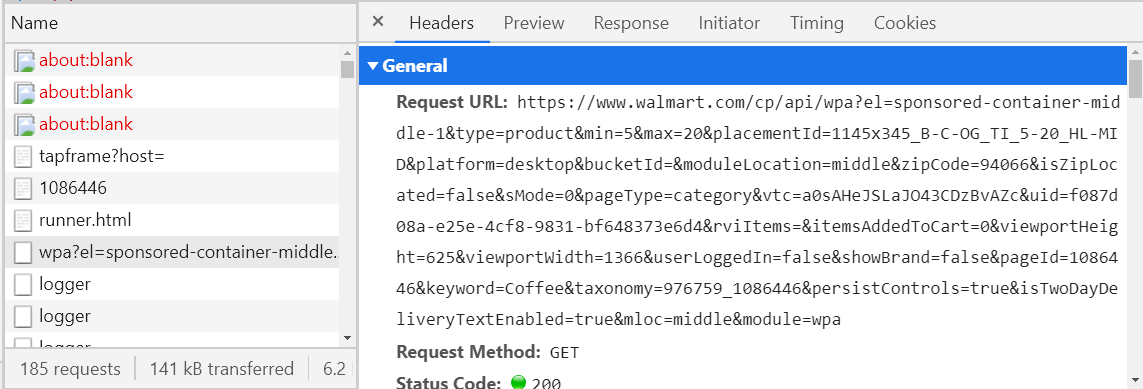
Setengah jalan berlalu, sekarang permintaan ini dapat "dipalsukan" dan segera dikirim melalui program, menerima informasi yang diperlukan dalam hitungan detik. Ini tetap mengurai JSON atau XML, dan ini jauh lebih mudah daripada menulis XPath. Tetapi seringkali pembentukan permintaan semacam itu adalah hal yang agak tidak menyenangkan (lihat URL pada gambar di atas) dan jika Anda berhasil, maka dalam beberapa kasus Anda akan menerima respons seperti itu.
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}Sekarang Anda akan belajar bagaimana Anda dapat menghindari masalah dengan meniru permintaan menggunakan alternatif - server proxy.
Server proxy
Server proxy adalah perangkat yang menjadi perantara antara komputer dan Internet.
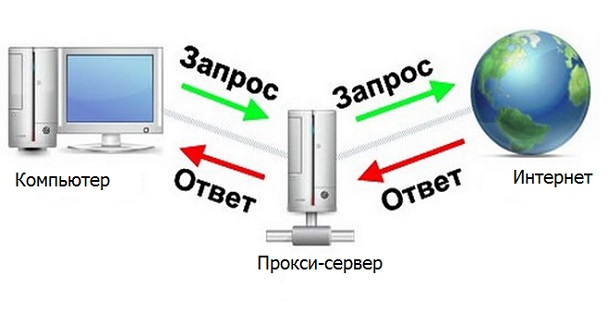
Akan sangat bagus jika program kami adalah server proxy, maka Anda dapat dengan cepat dan nyaman memproses tanggapan yang diperlukan dari server. Kemudian akan ada rantai seperti Browser - Program - Internet (server situs yang diurai).
Untungnya untuk si tajam ada pustaka yang bagus untuk kebutuhan seperti itu - Titanium Web Proxy.
Mari buat kelas PServer
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}Sekarang mari kita bahas setiap metode secara terpisah.
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone - tambahkan metode untuk memproses respons dari server. Ini akan dipanggil secara otomatis saat respons tiba.
eksplisitEndPoint - Konfigurasi server proxy,
ExplicitProxyEndPoint (IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress dan port tempat server proxy dijalankan.
decryptSsl - apakah akan mendekripsi SSL. Dengan kata lain, jika decrtyptSsl = true, maka server proxy akan memproses semua permintaan dan tanggapan.
eksplisitEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest - tambahkan metode untuk memproses permintaan sebelum mengirimnya ke server. Ini juga akan dipanggil secara otomatis sebelum permintaan dikirim.
proxyServer.Start () - "memulai" server proxy, mulai saat ini server mulai memproses permintaan dan tanggapan.
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false - permintaan dan respons saat ini tidak akan diproses.
Jika kita tidak tertarik dengan permintaan atau tanggapannya (misalnya, gambar atau semacam skrip), lalu mengapa mendekripsi? Cukup banyak sumber daya yang dihabiskan untuk ini, dan jika semua permintaan dan tanggapan diterjemahkan, program akan bekerja untuk waktu yang lama. Oleh karena itu, jika permintaan saat ini tidak berisi host dari permintaan yang kami minati, tidak ada gunanya mendekripsi.
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}await e.GetResponseBodyAsString () - mengembalikan respons sebagai string.
Agar WebDriver dapat terhubung ke server proxy, Anda perlu menulis yang berikut ini:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);Sekarang Anda dapat menangani permintaan yang Anda inginkan.
Kesimpulan
Dengan WebDriver, Anda dapat menavigasi halaman, mengklik tombol, dan meniru perilaku pengguna biasa. Dengan XPaths, Anda dapat mengekstrak informasi yang Anda butuhkan dari halaman web. Jika XPaths tidak berfungsi, maka server proxy selalu dapat membantu, yang dapat mencegat permintaan antara browser dan situs.