Proyek ini telah berkembang, perpustakaan sekarang menyelesaikan semua tugas dasar pemrosesan bahasa Rusia alami: segmentasi menjadi token dan kalimat, analisis morfologis dan sintaksis, lemmatisasi, ekstraksi entitas bernama.

Untuk artikel berita, kualitas semua tugas sebanding atau lebih unggul dari solusi yang ada... Misalnya, Natasha mengatasi tugas NER sebesar 1 poin persentase lebih buruk daripada Deeppavlov BERT NER (F1 PER 0,97, LOC 0,91, ORG 0,85), model berbobot 75 kali lebih sedikit (27MB), berjalan pada CPU 2 kali lebih cepat (25 artikel / detik ) daripada BERT NER pada GPU.
Ada 9 repositori dalam proyek ini , perpustakaan Natasha menggabungkannya dalam satu antarmuka. Dalam artikel ini, kita akan berbicara tentang alat baru, membandingkannya dengan solusi yang ada: Deeppavlov , SpaCy , UDPipe .

Longread ini didahului oleh serangkaian posting di natasha.github.io :Jika Anda terintimidasi oleh ukuran teks di bawah ini, tonton 20 menit pertama dari tube stream tentang sejarah proyek Natasha, ada penceritaan ulang singkatnya:
- Natasha - NER kompak berkualitas tinggi untuk bahasa Rusia
- Navec - embeddings ringkas untuk bahasa Rusia
- Corus - kumpulan kumpulan data NLP berbahasa Rusia
- Razdel - segmentasi teks berbahasa Rusia menjadi token dan penawaran
- Naeval - perbandingan kuantitatif sistem untuk NLP berbahasa Rusia
- Nerus adalah kumpulan data sintetis berbahasa Rusia berukuran besar dengan markup morfologi, sintaksis, dan entitas bernama
Teks menggunakan catatan dan diskusi dari obrolan t.me/natural_language_processing , tautan ke materi baru muncul di tempat yang sama:
- Mengapa Natasha tidak menggunakan Transformers. BERT dalam 100 baris
- Model BERT Slovnet
- Aliran tabung tentang sejarah proyek Natasha
- Dokumentasi Yargy yang Diperbarui
- Sumber daya tambahan di parser Yargy
Bagi mereka yang ingin mendengarkan lebih banyak, lihat pembicaraan setiap jam di Datafest 2020, hampir mencakup posting ini:
Kandungan:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

Sebelumnya, perpustakaan Natasha memecahkan masalah NER untuk bahasa Rusia, dibangun berdasarkan aturan , menunjukkan kualitas dan kinerja rata-rata. Sekarang Natasha adalah proyek besar, terdiri dari 9 repositori . Pustaka Natasha menyatukannya dalam satu antarmuka, menyelesaikan tugas-tugas dasar pemrosesan bahasa Rusia alami: segmentasi menjadi token dan kalimat, embeddings terlatih, analisis morfologi dan sintaksis, lemmatisasi, NER. Semua solusi menunjukkan hasil teratas dalam topik berita , berjalan cepat di CPU.
Natasha mirip dengan pustaka gabungan lainnya: SpaCy , UDPipe , Stanza... SpaCy menginisialisasi dan memanggil model secara implisit, pengguna meneruskan teks ke fungsi ajaib
nlp, mendapatkan dokumen yang diurai sepenuhnya.
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
Antarmuka Natasha lebih bertele-tele. Pengguna secara eksplisit menginisialisasi komponen: memuat embeddings yang telah dilatih sebelumnya, meneruskannya ke konstruktor model. Sam memanggil metode
segment, tag_morph, parse_syntaxsegmentasi ke dalam token dan permintaan, analisis morfologi dan sintaksis.
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
Ekstraktor entitas bernama tidak bergantung pada hasil morfologi dan penguraian, tetapi dapat digunakan secara terpisah.
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
Natasha memecahkan masalah lemmatisasi , menggunakan Pymorphy2 dan hasil analisis morfologi.
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
Untuk membawa frasa ke bentuk normal, tidak cukup hanya menemukan lemma kata-kata individu, untuk Kementerian Luar Negeri Rusia akan berubah menjadi Kementerian Luar Negeri Rusia, untuk Organisasi Nasionalis Ukraina - Organisasi Nasionalis Ukraina. Natasha menggunakan hasil parsing, memperhitungkan hubungan antar kata, menormalkan entitas bernama.
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
Natasha menemukan nama, nama organisasi, dan nama tempat dalam teks. Untuk nama di perpustakaan ada seperangkat aturan siap pakai untuk pengurai Yargy , modul membagi nama yang dinormalisasi menjadi beberapa bagian, dari "Viktor Fedorovich Yushchenko" diperoleh
{first: , last: , middle: }.
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
Perpustakaan berisi aturan untuk penguraian tanggal, jumlah uang dan alamat, mereka dijelaskan dalam dokumentasi dan buku referensi .
Perpustakaan Natasha sangat cocok untuk mendemonstrasikan teknologi proyek, yang digunakan dalam pendidikan. Arsip dengan bobot model dimasukkan ke dalam paket, setelah instalasi Anda tidak perlu mengunduh dan mengkonfigurasi apa pun.
Natasha menggabungkan pustaka proyek lain di bawah satu antarmuka. Untuk mengatasi masalah praktis, Anda harus menggunakannya secara langsung:
- Razdel - segmentasi teks menjadi kalimat dan token;
- Navec - embeddings kompak berkualitas tinggi;
- Slovnet - model ringkas modern untuk morfologi, sintaksis, NER;
- Yargy - aturan dan kosakata untuk mengekstraksi informasi terstruktur;
- Ipymarkup - visualisasi NER dan markup sintaksis;
- Corus - kumpulan tautan ke kumpulan data umum berbahasa Rusia;
- Nerus adalah korpus besar dengan markup otomatis entitas bernama, morfologi, dan sintaksis.
Razdel - segmentasi teks berbahasa Rusia menjadi token dan penawaran

Perpustakaan Razdel adalah bagian dari proyek Natasha, membagi teks berbahasa Rusia menjadi token dan kalimat. Petunjuk instalasi , contoh penggunaan dan pengukuran kinerja di gudang Razdel.
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
Model modern sering tidak peduli dengan segmentasi, mereka menggunakan BPE , menunjukkan hasil yang luar biasa, mengingat semua versi GPT dan kebun binatang BERT . Natasha memecahkan masalah penguraian morfologi dan sintaksis, semuanya masuk akal hanya untuk kata-kata terpisah dalam satu kalimat. Oleh karena itu, kami secara bertanggung jawab mendekati tahap segmentasi, mencoba mengulangi markup dari kumpulan data terbuka populer: SynTagRus , OpenCorpora , GICRYA .
Kecepatan dan kualitas Razdel sebanding atau lebih baik daripada solusi open source lain untuk bahasa Rusia.
| Solusi segmentasi token | Kesalahan per 1000 token | Waktu pemrosesan, detik |
| Regexp-baseline | 19 | 0,5 |
| SpaCy
|
17 | 5.4 |
| NLTK
|
130 | 3.1 |
| MyStem
|
19 | 4.5 |
| Musa
|
sebelas | 1.9 |
| SegTok
|
12 | 2.1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
Jumlah rata-rata error untuk 4 dataset : SynTagRus , OpenCorpora , GICRYA dan RNC . Detail lebih lanjut di repositori Razdel .
Mengapa Anda membutuhkan Razdel sama sekali, jika garis dasar dengan garis biasa memberikan kualitas yang sama dan ada banyak solusi siap pakai untuk bahasa Rusia? Faktanya, Razdel bukan hanya tokenizer, tetapi mesin segmentasi berbasis aturan kecil. Segmentasi adalah tugas dasar, yang sering dijumpai dalam praktik. Misalnya, ada tindakan yudisial, Anda perlu menonjolkan bagian operatif di dalamnya dan membaginya menjadi paragraf. Secara alami, solusi off-the-shelf tidak dapat melakukan itu. Baca cara menulis aturan Anda sendiri di kode sumber . Selanjutnya kami akan berbicara tentang cara mendorong diri Anda sendiri dan membuat solusi teratas untuk token dan penawaran di mesin kami.
Apa kesulitannya?
Dalam bahasa Rusia, kalimat biasanya diakhiri dengan titik, tanda tanya, atau tanda seru. Mari kita pisahkan teks dengan ekspresi reguler
[.?!]\s+. Solusi ini akan memberikan 76 kesalahan per 1000 kalimat. Jenis dan contoh kesalahan:
Singkatan
... platform apa pun dengan audiens 3.000 orang atau lebih adalah seorang blogger.
... sebuah ketukan berdiri di atas mereka dari akhir abad ke-17;
… Di Chamber Musical Theatre dinamai ▒B.A. Pokrovsky.
Inisial
setelah opera "Idomeneo" V.A.▒Motsarta - R.▒Shtrausa ...
Daftar
2. dumal akan berada di konsulat Finlandia antrian yang cukup panjang ...
g.▒ kereta api kereta api Rusia ...
Akhir kalimat smiley atau titik tipografi
Siapa pun yang menawarkan cara untuk menghilangkan minus - berkat itu :) ▒ Saya melihat, bijaksana ... ▒ Sekarang ini lebih tidak menyenangkan, karena isinya akan rusak.
Kutipan, ucapan langsung, di akhir kalimat ada tanda petik
- apakah Anda memiliki pengantin wanita di kota? ”▒“ Untuk siapa mempelai wanita? ”
“Sangat bagus bahwa saya tidak seperti itu!” ▒Sekarang, saat menerjemahkan, saya membuat kesalahan Freudian: “idologi”.
Razdel mempertimbangkan nuansa ini, mengurangi jumlah kesalahan dari 76 menjadi 43 per 1000 kalimat.
Situasinya mirip dengan token. Solusi dasar yang baik adalah regex
[--]+|[0-9]+|[^-0-9 ], yang membuat 19 kesalahan per 1000 token. Contoh:
Bilangan pecahan, tanda baca kompleks
... Pada akhir 1980-an - awal 1990-an
... BS-▒3 dapat dicatat massa yang sedikit lebih sedikit (3▒, ▒6 t)
- dan dia meninggal ▒.▒. Apakah Anda mengerti gadis itu, elang? ▒!
Razdel mengurangi jumlah kesalahan menjadi 7 per 1000 token.
Prinsip operasi
Sistem dibangun berdasarkan aturan. Prinsip segmentasi menjadi token dan penawaran adalah sama.
Koleksi kandidat
Kami menemukan dalam teks semua kandidat untuk akhir kalimat: titik, elipsis, tanda kurung, tanda kutip.
6.▒ Pilihan jawaban yang paling sering dan pada saat yang sama berperingkat tinggi "Saya senang" ▒ (13 pernyataan, 25 poin) ▒– situasi menerima persetujuan dan dorongan. ▒7.▒ Patut dicatat bahwa dalam jawaban "Saya tahu" itu diperkirakan sebagai yang paling stereotip , tapi hanya sekali ada jawaban "Aku seorang wanita" ▒; ▒ ada pernyataan “hanya satu pernikahan yang menungguku dalam hidup ini” ▒ dan “cepat atau lambat aku harus melahirkan” ▒.▒ Penyusun: V.▒P.▒Golovin , F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov.
Untuk token, kami membagi teks menjadi atom. Batas token tidak persis lewat di dalam atom.
Pada akhir 1980▒-▒▒-awal1990▒-▒▒
BS▒-▒3▒ dimungkinkan▒menandai sedikit▒ kelas kecil▒ (▒3▒, ▒6▒▒) ▒
▒— Da▒and▒umerla▒.▒.▒.▒Dapat ▒ligirl, ▒ the falcon▒? ▒!
Persatuan
Kami secara konsisten melewati kandidat untuk pemisahan, menghapus yang tidak perlu. Kami menggunakan daftar heuristik.
Daftar barang. Pemisah adalah titik atau tanda kurung, di sebelah kiri adalah angka atau huruf
6.▒ Jawaban yang paling sering dan sangat dihargai "Saya senang" (13 pernyataan, 25 poin) adalah situasi menerima persetujuan dan dorongan. 7.▒ Patut diperhatikan bahwa dalam jawaban "Saya tahu" ...
Inisial. Pemisah - titik, satu huruf kapital di kiri
... Penyusun: V.▒P.▒Golovin, F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov ...
Tidak ada spasi di sebelah kanan pemisah
... tetapi hanya sekali jawaban "Saya seorang wanita" ▒; ada pernyataan "hanya satu pernikahan yang menungguku dalam hidup ini" dan "cepat atau lambat aku harus melahirkan" ▒.
Tidak ada tanda akhir kalimat sebelum tanda kutip penutup atau tanda kurung, ini bukan kutipan atau pidato langsung
6. Jawaban yang paling sering dan sangat dihargai adalah "Saya senang" «(13 pernyataan, 25 poin) ▒ - situasi mendapatkan persetujuan dan dorongan. ... "satu pernikahan adalah semua yang menungguku dalam hidup ini" dan "cepat atau lambat aku harus melahirkan."
Akibatnya, ada dua pemisah yang tersisa, kami menganggapnya sebagai akhir kalimat.
6. Varian jawaban "Saya senang" yang paling sering dan sekaligus sangat dihargai (13 pernyataan, 25 poin) adalah situasi menerima persetujuan dan dorongan.▒7. Patut dicatat bahwa dalam jawaban "Saya tahu" ini dinilai sebagai yang paling stereotip, tetapi hanya sekali jawaban "Saya seorang wanita" ditemukan; ada pernyataan "satu pernikahan adalah semua yang menanti saya dalam hidup ini" dan "cepat atau lambat saya harus melahirkan." Disusun oleh V.P. Golovin, F.V. Zanichev, A.L. Rastorguev, R.V. Savko, I. I. Tuchkov.
Prosedurnya serupa untuk token, aturannya berbeda.
Pecahan atau bilangan rasional
... (3▒, ▒6 t) ...
Tanda baca kompleks
- ya, dan mati.▒.▒. Apakah Anda mengerti gadis itu, elang? ▒!
Tidak ada spasi di sekitar tanda hubung, ini bukan permulaan ucapan langsung.
Di akhir 1980▒-▒ - awal 1990▒-▒
BS▒-it3 dapat dicatat ...
Semua yang tersisa dianggap sebagai batasan token.
Pada akhir 1980-an-x▒-awal▒1990-x▒
BS-3▒ itu mungkin▒tonotices sedikit▒lower▒mass▒ (▒3,6▒t▒) ▒
▒ - ya dan mati. ..▒Got it▒li▒girl, ▒sokol▒?!
Batasan
Aturan Razdel dioptimalkan untuk teks yang ditulis dengan rapi dengan tanda baca yang benar. Solusi ini berfungsi baik dengan artikel berita, teks sastra. Pada posting dari jejaring sosial, transkrip percakapan telepon, kualitasnya lebih rendah. Jika tidak ada spasi di antara kalimat atau tidak ada titik di akhir, atau kalimat diawali dengan huruf kecil, Razdel akan membuat kesalahan. Baca
cara menulis aturan untuk tugas Anda dalam kode sumber , topik ini belum diungkapkan dalam dokumentasi.
Slovnet - pemodelan pembelajaran mendalam untuk pemrosesan bahasa Rusia alami

Dalam proyek tersebut Natasha Slovnet terlibat dalam pengajaran dan inferensi model modern untuk NLP berbahasa Rusia. Pustaka berisi model ringkas berkualitas tinggi untuk mengekstraksi entitas bernama, mengurai morfologi, dan sintaksis. Kualitas semua tugas sebanding atau lebih baik dari solusi terbuka lainnya untuk bahasa Rusia pada teks berita. Petunjuk instalasi , contoh penggunaan - di gudang Slovnet . Mari kita lihat lebih dekat bagaimana solusi untuk masalah NER diatur, untuk morfologi dan sintaks semuanya dengan analogi.
Di penghujung tahun 2018, setelah ada artikel dari Google tentang BERT , terjadi banyak kemajuan dalam NLP berbahasa Inggris. Pada 2019, orang-orang dari proyek DeepPavlovBERT multibahasa yang diadaptasi untuk bahasa Rusia, RuBERT muncul . Kepala CRF dilatih di atas , ternyata DeepPavlov BERT NER - SOTA untuk bahasa Rusia. Model ini memiliki kualitas yang sangat baik, kesalahan 2 kali lebih sedikit daripada pengejar terdekat DeepPavlov NER , tetapi ukuran dan kinerjanya menakutkan: 6GB - konsumsi RAM GPU, 2GB - ukuran model, 13 artikel per detik - kinerja pada GPU yang baik.
Pada tahun 2020, dalam proyek Natasha, kami berhasil mendekati kualitas DeepPavlov BERT NER, ukuran modelnya ternyata 75 kali lebih kecil (27MB), konsumsi memori 30 kali lebih sedikit (205MB), kecepatannya 2 kali lebih tinggi pada CPU (25 artikel per detik ).
| Natasha, Slovnet NER | DeepPavlov BERT NER | |
| PER / LOC / ORG F1 menurut token, rata-rata menurut Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0,97 / 0,91 / 0,85 | 0,98 / 0,92 / 0,86 |
| Ukuran model | 27MB | 2 GB |
| Konsumsi memori | 205MB | 6 GB (GPU) |
| Performa, artikel berita per detik (1 artikel ≈ 1KB) | 25 per CPU (Core i5) | 13 GPU (RTX 2080 Ti), 1 CPU |
| Waktu inisialisasi, detik | 1 | 35 |
| Perpustakaan mendukung | Python 3.5+, PyPy3 | Python 3.6+ |
| Dependensi | NumPy | TensorFlow |
Kualitas Slovnet NER lebih rendah 1 poin persentase dibandingkan dengan SOTA DeepPavlov BERT NER, ukuran model 75 kali lebih kecil, konsumsi memori 30 kali lebih kecil, kecepatan 2 kali lebih tinggi pada CPU. Perbandingan dengan SpaCy, PullEnti, dan solusi lain untuk NER berbahasa Rusia di repositori Slovnet .
Bagaimana Anda mendapatkan hasil ini? Resep singkat:
Slovnet NER = Slovnet BERT NER - analog dari distilasi DeepPavlov BERT NER + melalui markup sintetis ( Nerus ) di WordCNN-CRF dengan mesin embeddings terkuantisasi ( Navec ) + untuk inferensi pada NumPy.
Sekarang teratur. Rencananya adalah sebagai berikut: latih model berat dengan arsitektur BERT pada dataset kecil yang dianotasi secara manual. Kami menandainya dengan korpus berita, dan kami mendapatkan kumpulan data pelatihan sintetis kotor yang besar. Mari latih model primitif kompak di atasnya. Proses ini disebut distilasi: model yang berat adalah guru, model kompak adalah siswa. Kami berharap bahwa arsitektur BERT adalah redundan untuk masalah NER, model yang kompak tidak akan kehilangan banyak kualitas dibandingkan model yang berat.
Guru teladan
DeepPavlov BERT NER terdiri dari encoder RuBERT dan kepala CRF. Model guru berat kami mengulangi arsitektur ini dengan sedikit perbaikan.
Semua tolok ukur mengukur kualitas NER pada teks berita. Mari latih RuBERT dalam pemberitaan. Repositori Corus berisi tautan ke korpus berita publik berbahasa Rusia, dengan total 12 GB teks. Kami menggunakan teknik dari artikel Facebook tentang RoBERTa : kumpulan agregat besar, topeng dinamis, penolakan untuk memprediksi kalimat berikutnya (NSP). RuBERT menggunakan kamus besar yang terdiri dari 120.000 sub-token - warisan BERT multibahasa Google. Jika kita mengurangi ukuran menjadi 50.000 dari berita yang paling sering muncul, liputannya akan berkurang 5%. Dapatkan NewsRuBERT, model memprediksi sub-token terselubung di berita 5 poin persentase lebih baik daripada RuBERT (63% di 1 teratas).
Mari kita latih encoder NewsRuBERT dan kepala CRF untuk 1000 artikel dari Collection5 . Kami mendapatkan Slovnet BERT NER , kualitas 0.5 poin persentase lebih baik dari DeepPavlov BERT NER, ukuran model 4 kali lebih kecil (473MB), bekerja 3 kali lebih cepat (40 artikel per detik).
NewsRuBERT = RuBERT + 12GB berita + teknologi dari RoBERTa + kamus-50K.
Slovnet BERT NER (analog dari DeepPavlov BERT NER) = NewsRuBERT + CRF head + Collection5.
Sekarang, untuk melatih model dengan arsitektur mirip BERT, biasanya menggunakan Transformers dari Hugging Face. Transformer adalah 100.000 baris kode Python. Ketika kehilangan atau sampah meledak pada kesimpulan, sulit untuk mencari tahu apa yang salah. Oke, banyak kode yang digandakan di sana. Bahkan jika kita melatih RoBERTa, kita dapat dengan cepat melokalkan masalah ke ~ 3000 baris kode, tetapi ini juga banyak. Dengan PyTorch modern, perpustakaan Transformers hampir tidak relevan. Dengan
torch.nn.TransformerEncoderLayerkode model mirip RoBERTa dibutuhkan 100 baris:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
Ini bukan prototipe, kode disalin dari repositori Slovnet . Transformer bagus untuk dibaca, mereka melakukan banyak pekerjaan, memasukkan kode untuk artikel dengan Arxiv, seringkali sumber Python lebih jelas daripada penjelasan dalam artikel ilmiah.
Dataset sintetis
Mari tandai 700.000 artikel dari korpus Lenta.ru dengan model yang berat. Kami mendapatkan kumpulan data pelatihan sintetis yang sangat besar. Arsip tersedia di repositori Nerus proyek Natasha. Markupnya berkualitas sangat tinggi, F1 memperkirakan dengan token: PER - 99,7%, LOC - 98,6%, ORG - 97,2%. Contoh kesalahan yang jarang terjadi:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
Model pelajar
Tidak ada masalah dengan pilihan arsitektur model guru berat, hanya ada satu opsi - transformator. Model siswa kompak lebih sulit, ada banyak pilihan. Dari 2013 hingga 2018, dari munculnya word2vec hingga artikel di BERT, umat manusia menghasilkan sekumpulan arsitektur jaringan saraf untuk memecahkan masalah NER. Semuanya memiliki skema umum:
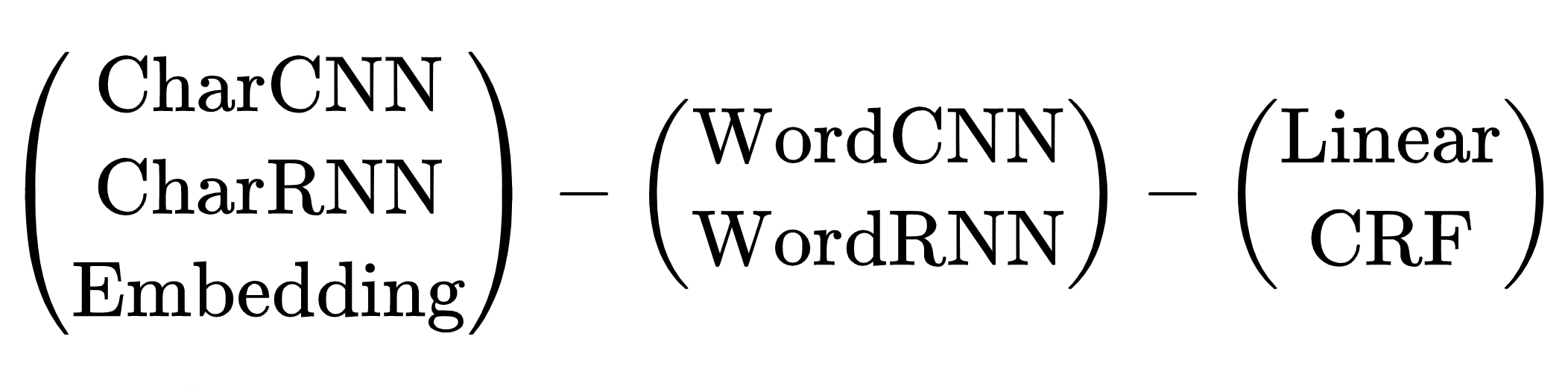
Skema arsitektur jaringan neural untuk tugas NER: pembuat enkode token, pembuat enkode konteks, dekoder tag. Penjelasan singkatan dalam artikel review oleh Yang (2018) .
Ada banyak kombinasi arsitektur. Pilih yang mana? Misalnya, (CharCNN + Embedding) -WordBiLSTM-CRF adalah diagram model dari artikel tentang DeepPavlov NER , SOTA untuk bahasa Rusia hingga 2019.
Kami melewatkan opsi dengan CharCNN, CharRNN, meluncurkan jaringan saraf kecil dengan simbol pada setiap token bukanlah cara kami, terlalu lambat. Saya juga ingin menghindari WordRNN, solusinya harus bekerja pada CPU, kalikan matriks pada setiap token secara perlahan. Untuk NER, pilihan antara Linear dan CRF bersifat kondisional. Kami menggunakan pengkodean BIO, urutan tag itu penting. Kami harus menahan rem yang buruk, gunakan CRF. Masih ada satu opsi - Embedding-WordCNN-CRF. Model ini tidak peka huruf besar / kecil, karena NER penting, “harapan” hanyalah sebuah kata, “Harapan” mungkin sebuah nama. Tambahkan ShapeEmbedding - embedding dengan garis besar token, misalnya: "NER" - EN_XX, "Vainovich" - RU_Xx, "!" - PUNCT_!, "Dan" - RU_x, "5.1" - NUM, "New York" - RU_Xx-Xx. Skema NER Slovnet - (WordEmbedding + ShapeEmbedding) -WordCNN-CRF.
Distilasi
Mari latih Slovnet NER pada kumpulan data sintetis yang sangat besar. Mari kita bandingkan hasilnya dengan guru model kelas kakap Slovnet BERT NER. Kualitas dihitung dan dirata-ratakan pada Collection5, Gareev, factRuEval-2016, BSNLP-2019 yang ditandai secara manual. Ukuran sampel pelatihan sangat penting: untuk 250 artikel berita (factRuEval-2016), rata-rata untuk PER, LOC, LOG F1 adalah 0,64, untuk 1000 (analog dengan Collection5) - 0,81, untuk seluruh dataset - 0,91, kualitas NER BERT Slovnet - 0,92.
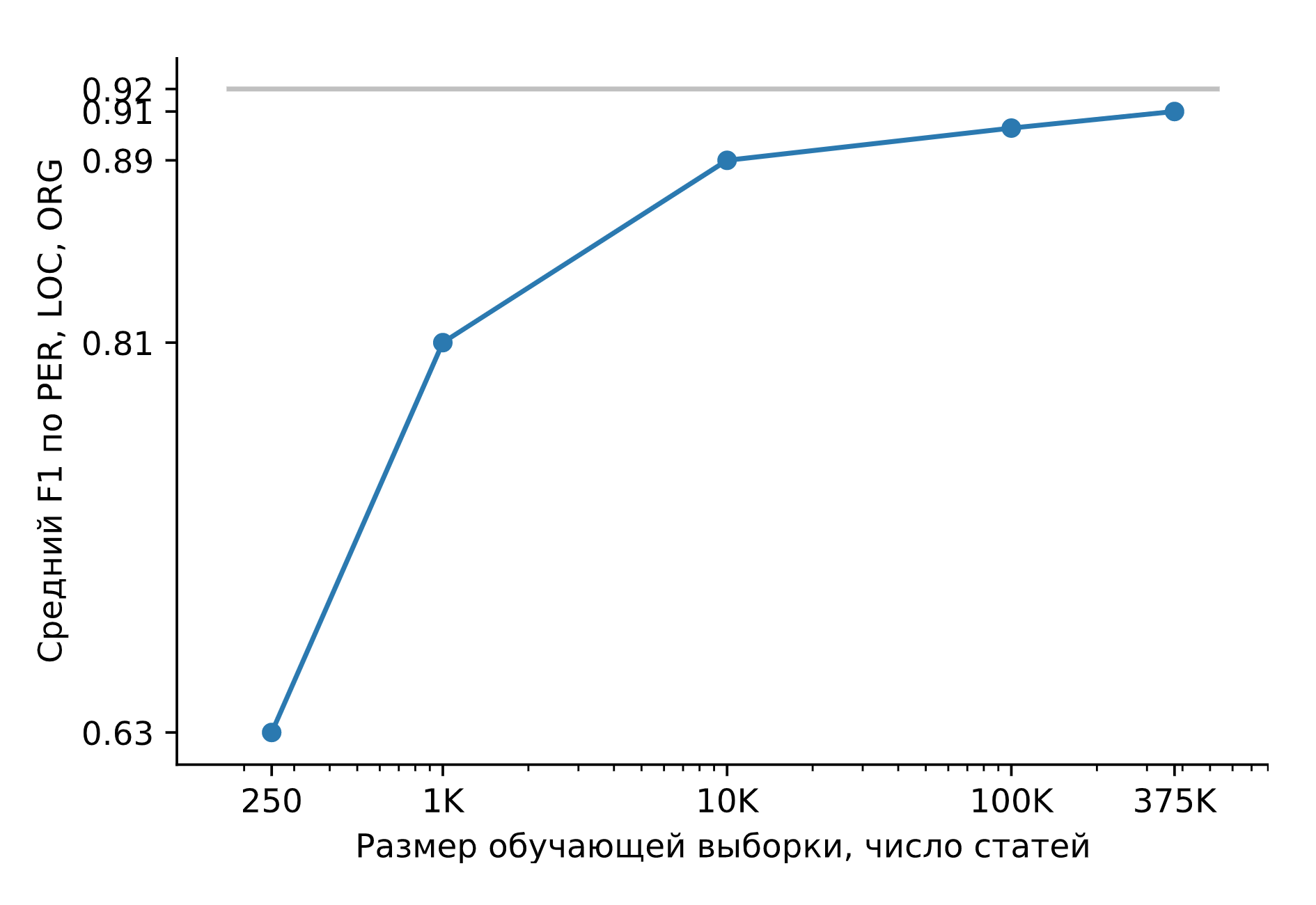
Kualitas Slovnet NER, bergantung pada jumlah contoh pelatihan sintetis. Garis abu-abu - kualitas Slovnet BERT NER. Slovnet NER tidak melihat contoh yang ditandai dengan tangan, NER hanya berlatih pada data sintetis.
Model siswa primitif 1 poin persentase lebih buruk daripada model guru keras. Ini hasil yang luar biasa. Resep universal menunjukkan dirinya sendiri:
Kami menandai beberapa data secara manual. Kami melatih trafo berat. Kami menghasilkan banyak data sintetis. Kami melatih model sederhana pada sampel yang besar. Kami mendapatkan trafo dengan kualitas, ukuran dan performa model yang sederhana.
Pustaka Slovnet memiliki dua model lagi yang dilatih sesuai dengan resep ini: Slovnet Morph - penanda morfologi, Sintaks Slovnet - pengurai sintaksis. Slovnet Morph tertinggal di belakang model guru berat sebesar 2 poin persentase , Sintaks Slovnet - 5 . Kedua model memiliki kualitas dan kinerja yang lebih baik daripada solusi Rusia yang ada untuk artikel berita.
Kuantisasi
Slovnet NER berukuran 289MB. 287MB ditempati oleh meja dengan embeddings. Model ini menggunakan kosakata besar sebanyak 250.000 baris, yang mencakup 98% kata dalam teks berita. Menggunakan kuantisasi , ganti vektor pelampung 300 dimensi dengan vektor 8-bit 100 dimensi. Ukuran model akan dikurangi 10 kali (27MB), kualitas tidak akan berubah. Library Navec adalah bagian dari proyek Natasha, kumpulan embeddings terlatih yang sudah dikuantisasi. Bobot yang dilatih pada fiksi membutuhkan 50 MB, melewati semua model RusVectores statis menurut perkiraan sintetis .
Kesimpulan
Slovnet NER menggunakan PyTorch untuk pelatihan. Paket PyTorch memiliki berat 700MB, saya tidak ingin menyeretnya ke produksi untuk inferensi. PyTorch juga tidak berfungsi dengan penerjemah PyPy . Slovnet digunakan bersama dengan pengurai Yargy, analog dari pengurai Yandex Tomita . Dengan PyPy, Yargy bekerja 2-10 kali lebih cepat, bergantung pada kompleksitas tata bahasa. Saya tidak ingin kehilangan kecepatan karena ketergantungan pada PyTorch.
Solusi standar adalah menggunakan TorchScript atau mengubah model menjadi ONNX , membuat inferensi di ONNXRuntime . Slovnet NER menggunakan blok non-standar: embeddings terkuantisasi, decoder CRF. TorchScript dan ONNXRuntime tidak mendukung PyPy.
Slovnet NER adalah model yang sederhana,mengimplementasikan secara manual semua blok di NumPy , gunakan bobot yang dihitung oleh PyTorch. Mari terapkan sedikit keajaiban NumPy, dengan hati-hati menerapkan blok CNN , decoder CRF , membongkar embedding yang terkuantisasi membutuhkan 5 baris . Kecepatan inferensi pada CPU sama dengan ONNXRuntime dan PyTorch, 25 artikel berita per detik pada Core i5.
Teknik ini bekerja pada model yang lebih kompleks: Slovnet Morph dan Syntax Slovnet juga diimplementasikan di NumPy. Slovnet NER, Morph dan Syntax berbagi tabel embedding yang sama. Mari kita ambil bobot dalam file terpisah, tabel tidak digandakan dalam memori dan disk:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
Batasan
Natasha mengekstrak entitas standar: nama, nama toponim, dan organisasi. Solusinya menunjukkan kualitas berita yang baik. Bagaimana cara bekerja dengan entitas dan jenis teks lain? Kita perlu melatih model baru. Ini tidak mudah dilakukan. Kami membayar untuk ukuran dan kecepatan kerja yang ringkas dengan kerumitan persiapan model. Laptop skrip untuk menyiapkan model guru yang berat , laptop skrip untuk model siswa , petunjuk untuk menyiapkan embeddings terkuantisasi .
Navec - embeddings ringkas untuk bahasa Rusia

Model ringkas nyaman digunakan. Mereka memulai dengan cepat, menggunakan sedikit memori, dan lebih banyak proses paralel yang sesuai pada satu contoh.
Di NLP, 80-90% bobot model ada di tabel embedding. Perpustakaan Navec adalah bagian dari proyek Natasha, kumpulan embeddings yang telah dilatih sebelumnya untuk bahasa Rusia. Dalam hal metrik kualitas intrinsik, mereka sedikit di bawah solusi teratas RusVectores , tetapi ukuran arsip dengan bobot 5-6 kali lebih kecil (51MB), kamus 2-3 kali lebih besar (500K kata).
| Kualitas * | Ukuran model, MB | Ukuran kamus, × 10 3 | |
| Navec | 0.719 | 50.6 | 500 |
| RusVectores | 0,638-0,726 | 220.6–290.7 | 189-249 |
Kita akan berbicara tentang embeddings kata demi kata lama yang merevolusi NLP pada tahun 2013. Teknologi tersebut masih relevan hingga saat ini. Dalam proyek Natasha, model untuk penguraian morfologi , sintaksis, dan ekstraksi entitas bernama bekerja pada embeddings Navec kata demi kata, dan menunjukkan kualitas di atas solusi terbuka lainnya .
RusVectores
Untuk bahasa Rusia, biasanya menggunakan embeddings terlatih dari RusVectores , mereka memiliki fitur yang tidak menyenangkan: tabel tidak berisi kata-kata, tetapi memasangkan "word_POS-tag". Idenya bagus, untuk pasangan "oven_VERB" kami mengharapkan vektor yang mirip dengan "cook_VERB", "cook_VERB", dan untuk "oven_NOUN" - "hut_NOUN", "furnace_NOUN".
Dalam praktiknya, tidak nyaman menggunakan embeddings semacam itu. Tidaklah cukup untuk membagi teks menjadi token, untuk setiap token Anda perlu mendefinisikan tag POS. Tabel embedding bengkak. Alih-alih satu kata "menjadi", kami menyimpan 6: 2 yang wajar "menjadi_VERB", "menjadi_NOUN" dan 4 aneh "menjadi_ADV", "menjadi_PROPN", "menjadi_NUM", "menjadi_ADJ". Ada 195.000 kata unik dalam tabel dengan 250.000 entri.
Kualitas
Mari kita perkirakan kualitas embeddings pada masalah kedekatan semantik. Mari kita ambil beberapa kata, untuk setiap kita akan menemukan vektor embedding, kita akan menghitung cosine similarity. Navec untuk kata yang mirip "cup" dan "jug" akan menghasilkan 0.49, untuk "fruit" dan "oven" - -0.0047. Mari kumpulkan banyak pasangan dengan tanda referensi kemiripan, hitung korelasi Spearman dengan jawaban kita.
Para penulis RusVectores menggunakan kecil, hati-hati diuji dan revisi daftar uji SimLex965 pasang . Mari tambahkan Yandex LRWC baru dan kumpulan data dari proyek RUSSE : HJ , RT , AE , AE2 :
| Kualitas rata-rata pada 6 dataset | Memuat waktu, detik | Ukuran model, MB | Ukuran kamus, × 10 3 | ||
| Navec | hudlit_12B_500K_300d_100q |
0.719 | 1.0 | 50.6 | 500 |
news_1B_250K_300d_100q |
0,653 | 0,5 | 25.4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0.692 | 3.3 | 220.6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0.691 | 5.0 | 290.0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0.726 | 5.2 | 290.7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0,638 | 8.0 | 2741.9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0,664 | 16.4 | 2752.1 | 195 |
Kualitasnya
hudlit_12B_500K_300d_100qsebanding atau lebih baik daripada solusi RusVectores, kamusnya 2-3 kali lebih besar, ukuran modelnya 5-6 kali lebih kecil. Bagaimana Anda mendapatkan kualitas dan ukuran ini?
Prinsip operasi
hudlit_12B_500K_300d_100q- Embeddings GloVe dilatih untuk fiksi 145GB . Mari ambil arsip dengan teks dari proyek RUSSE . Mari gunakan implementasi GloVe asli dalam C dan bungkus dengan antarmuka Python yang nyaman .
Mengapa tidak word2vec? Eksperimen pada kumpulan data besar lebih cepat dengan GloVe. Setelah kami menghitung matriks kolokasi, gunakan untuk menyiapkan embeddings dengan dimensi berbeda, pilih opsi terbaik.
Mengapa tidak fastText? Dalam proyek Natasha kami bekerja dengan teks berita. Ada beberapa kesalahan ketik di dalamnya, masalah token OOV diselesaikan dengan kamus besar. 250.000 baris dalam tabel
news_1B_250K_300d_100qmencakup 98% kata dalam artikel berita.
Ukuran kamus
hudlit_12B_500K_300d_100q- 500.000 entri, mencakup 98% kata dalam teks fiksi. Dimensi optimal vektor adalah 300. Tabel bilangan float 500.000 × 300 membutuhkan 578MB, ukuran arsip dengan bobot hudlit_12B_500K_300d_100q12 kali lebih kecil (48MB). Ini tentang kuantisasi.
Kuantisasi
Gantikan 32-bit float number dengan 8-bit code: [−∞, −0.86) - code 0, [−0.86, -0.79) - code 1, [-0.79, -0.74) - 2,…, [0.86, ∞) - 255. Ukuran tabel akan berkurang 4 kali lipat (143MB).
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
Data dikasar, beda nilai -0.005 dan -0.003 ganti satu kode 127, -0.030 dan -0.031 - 118
Mari kita ganti dengan kode bukan satu, tapi 3 angka. Kami mengelompokkan semua triplet angka dari tabel embedding menggunakan algoritma k-means menjadi 256 cluster, alih-alih setiap triplet kami akan menyimpan kode dari 0 hingga 255. Tabel akan berkurang 3 kali (48MB). Navec menggunakan pustaka PQk-means , ia membagi matriks menjadi 100 kolom, mengelompokkan masing-masing secara terpisah, kualitas pada pengujian sintetis akan turun sebesar 1 poin persentase. Jelas tentang kuantisasi dalam artikel Penghitung Produk untuk k-NN .
Embeddings terkuantisasi lebih lambat dari biasanya. Vektor yang dikompresi harus dibongkar sebelum digunakan. Kami dengan hati-hati menerapkan prosedur, menerapkan sihir Numpy, di PyTorch kami menggunakan torch.gather . Di Slovnet NER, akses ke tabel embedding membutuhkan 0,1% dari total waktu komputasi.
Sebuah modul
NavecEmbeddingdari perpustakaan Slovnet mengintegrasikan Navec ke dalam model PyTorch:
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus adalah kumpulan data sintetis besar dengan markup morfologi, sintaksis, dan entitas bernama

Dalam proyek Natasha, analisis morfologi, sintaksis dan ekstraksi entitas bernama dibuat oleh 3 model kompak: Slovnet NER , Slovnet Morph dan Slovnet Syntax . Kualitas solusi 1–5 persen lebih buruk daripada solusi berat dengan arsitektur BERT, ukurannya 50–75 kali lebih kecil, dan kecepatan pada CPU 2 kali lebih tinggi. Model dilatih pada kumpulan data Nerus sintetis yang sangat besar , dalam arsip 700.000 artikel berita dengan markup morfologi, sintaksis, dan entitas bernama CoNLL-U :
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER, Morf, Sintaks - model primitif. Ketika ada 1000 contoh dalam set pelatihan, Slovnet NER tertinggal dari analog BERT yang berat sebesar 11 poin persentase, ketika 10.000 contoh - dengan 3 poin, ketika 500.000 - oleh 1.
Nerus adalah hasil kerja, model berat dengan arsitektur BERT : Slovnet BERT NER , Morf BERT Slovnet , Sintaks BERT Slovnet . Memproses 700.000 artikel berita membutuhkan waktu 20 jam di Tesla V100. Kami menghemat waktu peneliti lain, kami meletakkan arsip yang sudah selesai di akses terbuka. Di SpaCy-Ru mengajar di Nerus model kualitatif untuk SpaCy berbahasa Rusia, siapkan tambalan di repositori resmi.

Markup sintetis memiliki kualitas tinggi: akurasi penentuan tag morfologis adalah 98%, tautan sintaksis - 96%. Untuk NER, F1 memperkirakan dengan token: PER - 99%, LOC - 98%, ORG - 97%. Untuk menilai kualitasnya, kami menandai SynTagRus , Collection5 dan potongan berita GramEval2020 , membandingkan markup referensi dengan milik kami, untuk detail lebih lanjut di repositori Nerus . Karena kesalahan dalam markup sintaks, ada loop dan banyak akar, tag POS terkadang tidak sesuai dengan tepi sintaksis. Berguna untuk menggunakan validator dari Dependensi Universal , lewati contoh seperti itu.
Paket Python Nerus mengatur antarmuka yang nyaman untuk memuat dan merender markup:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
Petunjuk pemasangan, contoh penggunaan , penilaian kualitas di gudang Nerus.
Corus - kumpulan tautan ke kumpulan data umum berbahasa Rusia + fungsi untuk diunduh

Pustaka Corus adalah bagian dari proyek Natasha, kumpulan tautan ke set data NLP bahasa Rusia publik + paket Python dengan fungsi pemuat. Daftar link ke sumber , petunjuk instalasi dan contoh penggunaan di repositori Corus.
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
Kumpulan data terbuka yang berguna untuk bahasa Rusia sangat tersembunyi sehingga hanya sedikit orang yang mengetahuinya.
Contoh dari
Kumpulan artikel berita
Kami ingin melatih model bahasa pada artikel berita, kami membutuhkan banyak teks. Hal pertama yang terlintas dalam pikiran adalah potongan berita dari dataset Taiga (~ 1GB). Banyak orang tahu tentang dump Lenta.ru (2GB). Sumber lain lebih sulit ditemukan. Pada tahun 2019, Dialogue menyelenggarakan kompetisi untuk menghasilkan berita utama ; penyelenggara menyiapkan dump RIA Novosti selama 4 tahun (3.7GB). Pada 2018, Yuri Baburov menerbitkan unggahan dari 40 sumber berita berbahasa Rusia (7,5 GB). Relawan dari ODS membagikan arsip (7GB) yang dikumpulkan untuk proyek analisis agenda berita .
Di registri Coruslink ke mereka dataset ditandai «berita», untuk semua sumber memiliki fungsi-loader:
load_taiga_*, load_lenta, load_ria, load_buriy_*, load_ods_*.
NER
Kami ingin mengajarkan NER untuk bahasa Rusia, kami membutuhkan teks beranotasi. Pertama-tama, kami mengingat data kompetisi factRuEval-2016 . Markup memiliki kekurangan: formatnya yang kompleks, rentang entitas tumpang tindih, ada kategori "LocOrg" yang ambigu. Tidak semua orang tahu tentang koleksi Named Entities 5, penerus Persons-1000 . Tata letak dalam format standar , bentang tidak berpotongan, cantik! Tiga sumber lainnya hanya diketahui oleh penggemar paling berdedikasi NER berbahasa Rusia. Kami akan menulis kepada Rinat Gareev melalui surat, melampirkan tautan ke artikelnya tahun 2013 , sebagai tanggapan kami akan menerima 250 artikel berita dengan nama dan organisasi yang diberi tag. BSNLP-2019 kompetisi yang diadakan tahun 2019tentang NER untuk bahasa Slavia, kami akan menulis kepada penyelenggara, kami akan mendapatkan 450 lebih teks yang ditandai. Proyek WiNER muncul dengan ide untuk membuat markup NER semi-otomatis dari dump Wikipedia , unduhan besar untuk bahasa Rusia tersedia di Github .
Link dan fungsi untuk memuat register Corus:
load_factru, load_ne5, load_gareev, load_bsnlp, load_wikiner.
Kumpulan tautan
Sebelum Anda mendapatkan bootloader dan masuk ke registri, tautan ke sumber diakumulasikan di bagian dengan Tiket . Koleksi 30 dataset: versi baru dari Taiga , teks 568GB Rusia dari Crawl Common , ulasan c Banki.ru dan Auto.ru . Kami mengundang Anda untuk membagikan temuan Anda, membuat tiket dengan tautan.
Fungsi loader
Kode untuk kumpulan data sederhana mudah untuk ditulis sendiri. Tempat pembuangan Lenta.ru terbentuk dengan baik, implementasinya sederhana . Taiga terdiri dari ~ 15 juta file zip CoNLL-U . Agar pengunduhan bekerja dengan cepat, tidak menggunakan banyak memori dan tidak merusak sistem file, Anda perlu bingung, dengan hati-hati menerapkan pekerjaan dengan file zip pada level rendah .
Untuk 35 sumber, paket Corus Python memiliki fungsi pemuat. Antarmuka untuk mengakses Taiga tidak lebih rumit dari dump Lenta.ru:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
Kami mengundang pengguna untuk membuat permintaan tarik, mengirim fungsi loader mereka, instruksi singkat di repositori Corus.
Naeval - perbandingan kuantitatif sistem untuk NLP berbahasa Rusia

Natasha bukanlah proyek ilmiah, tidak ada tujuan untuk mengalahkan SOTA, tetapi penting untuk memeriksa kualitas pada tolok ukur publik, untuk mencoba mengambil tempat tinggi tanpa kehilangan banyak kinerja. Seperti yang mereka lakukan di akademi: ukur kualitas, dapatkan nomor, ambil tablet dari artikel lain, bandingkan angka-angka ini dengan milik mereka. Skema ini memiliki dua masalah:
- Lupakan kinerja. Jangan bandingkan ukuran model, kecepatan Penekanannya hanya pada kualitas.
- Jangan publikasikan kodenya. Biasanya ada jutaan nuansa dalam menghitung metrik kualitas. Bagaimana tepatnya itu dihitung di artikel lain? Tidak diketahui.
Naeval adalah bagian dari proyek Natasha, seperangkat skrip untuk menilai kualitas dan kecepatan alat sumber terbuka untuk memproses bahasa asli Rusia:
| Tugas | Set data | Solusi |
| Tokenisasi | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER , DeepPavlov BERT NER , DeepPavlov Slavia BERT NER , PullEnti , SpaCy , Stanza , Texterra , Tomita , MITIE , Slovnet NER , Slovnet BERT NER
|
Mari kita lihat lebih dekat masalah NER di bawah ini.
Set data
Ada 5 tolok ukur publik untuk NER berbahasa Rusia: factRuEval-2016 , Collection5 , Gareev , BSNLP-2019 , WiNER . Tautan sumber dikumpulkan di registri Corus . Semua dataset terdiri dari artikel berita, substring dengan nama, nama organisasi dan toponim yang ditandai di teks. Apa bisa lebih mudah?
Semua sumber memiliki format markup yang berbeda. Collection5 menggunakan format Standoff dari utilitas Brat , Gareev dan WiNER - dialek berbeda dari markup BIO , BSNLP-2019 memiliki formatnya sendiri , factRuEval-2016 juga memiliki spesifikasi non-sepele sendiri... Naeval mengonversi semua sumber ke format umum. Markup terdiri dari span. Rentang - tiga: tipe entitas, awal dan akhir substring.
Jenis entitas. factRuEval-2016 dan Collection5 secara terpisah menandai semi-nama-semi-organisasi: "Kremlin", "EU", "USSR". BSNLP-2019 dan WiNER menyoroti nama-nama acara tersebut: "Championship of Russia", "Brexit". Naeval mengadaptasi dan menghapus beberapa tag, meninggalkan tag referensi PER, LOC, ORG: nama orang, nama toponim dan organisasi.
Rentang bersarang. FaktanyaRuEval-2016, bentangnya tumpang tindih. Naeval menyederhanakan markup:
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
Model
Naeval membandingkan 12 solusi terbuka untuk masalah NER Rusia. Semua alat dibungkus dalam wadah Docker dengan antarmuka web:
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
Beberapa solusi sangat sulit untuk diluncurkan dan dikonfigurasi sehingga hanya sedikit orang yang menggunakannya. PullEnti , sistem berbasis aturan yang canggih, menempati posisi pertama dalam kompetisi factRuEval pada tahun 2016. Alat ini didistribusikan sebagai SDK untuk C #. Bekerja di Naeval berubah menjadi proyek terpisah dengan satu set pembungkus untuk PullEnti: PullentiServer - server web di C #, klien-pullenti - klien Python untuk PullentiServer:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
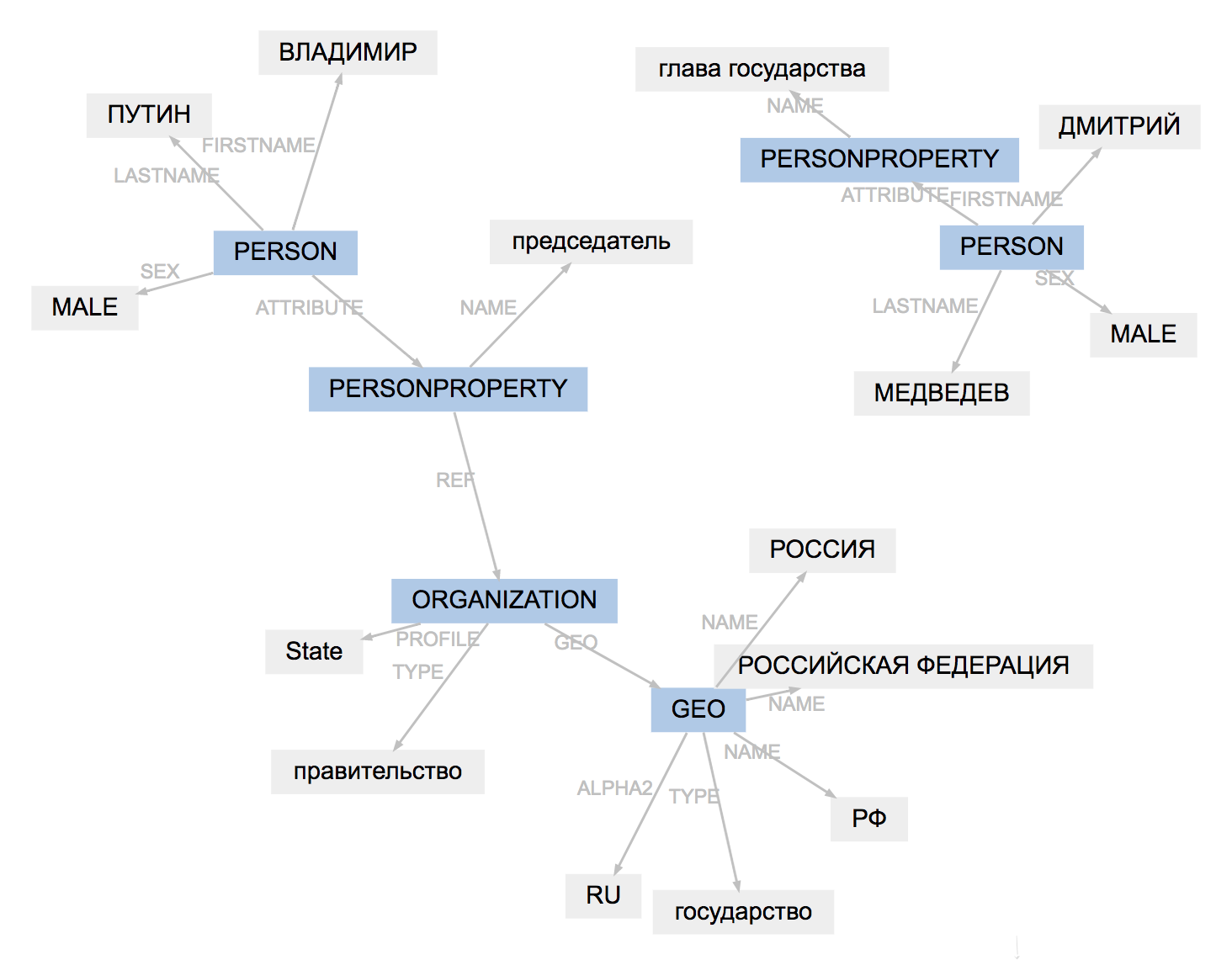
Format markup untuk semua alat sedikit berbeda. Naeval memuat hasil, menyesuaikan jenis entitas, menyederhanakan struktur span:
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
Hasil pekerjaan PullEnti lebih sulit diadaptasi daripada markup factRuEval-2016. Algoritme menghapus tag PERSONPROPERTY, memisahkan PERSON, ORGANIZATION, dan GEO yang bertingkat menjadi PER, LOC, ORG yang tidak tumpang tindih.
Perbandingan
Untuk setiap pasangan "model, set data", Naeval menghitung ukuran F1 berdasarkan token , menerbitkan tabel dengan skor kualitas .
Natasha bukanlah proyek ilmiah, kepraktisan solusinya penting bagi kami. Naeval mengukur waktu mulai, kecepatan lari, ukuran model, dan konsumsi RAM. Tabel dengan hasil di repositori .
Kami menyiapkan kumpulan data, menggabungkan 20 sistem dalam wadah Docker dan metrik terhitung untuk 5 tugas lain NLP bahasa Rusia, menghasilkan repositori Naeval: tokenisasi , segmentasi ke dalam kalimat , embeddings , morfologi , dan analisis sintaksis .
Yargy- —

Parser Yargy adalah analog dari parser Yandex Tomita untuk Python. Petunjuk penginstalan , contoh penggunaan , dokumentasi di repositori Yargy. Aturan untuk mengekstraksi entitas dijelaskan menggunakan tata bahasa dan kamus bebas konteks . Dua tahun lalu saya menulis artikel tentang Habr tentang Yargy dan perpustakaan Natasha , berbicara tentang memecahkan masalah NER untuk bahasa Rusia. Proyek itu diterima dengan baik. Yargy-parser menggantikan Tomita dalam proyek-proyek besar di dalam Sberbank, Interfax dan RIA Novosti. Banyak materi pendidikan bermunculan. Video besar dari lokakarya di Yandex, satu setengah jam tentang proses pengembangan tata bahasa dengan contoh:
Dokumentasi diperbarui, saya menyisir bagian pengantar dan buku referensi . Yang terpenting, Cookbook telah muncul - bagian dengan praktik yang berguna. Ini berisi jawaban atas pertanyaan yang paling sering diajukan dari t.me/natural_language_processing :
- bagaimana melewatkan sebagian teks ;
- cara mengirimkan token, bukan teks ;
- apa yang harus dilakukan jika pengurai melambat .
Yargy parser adalah alat yang kompleks. Cookbook menjelaskan poin-poin yang tidak jelas yang muncul saat bekerja dengan seperangkat aturan yang besar:
Kami memiliki beberapa layanan besar yang berjalan di lab Yargy. Saya membaca kembali kode, pola yang dikumpulkan di Cookbook yang tidak dijelaskan di depan umum:
- pembuatan aturan ;
- fakta warisan (sangat berguna, tidak ada solusi dalam praktik yang dapat dilakukan tanpa teknik ini).
Setelah membaca dokumentasi, ada gunanya melihat repositori dengan contoh :
Proyek Natasha juga memiliki repositori penggunaan natasha . Di sinilah kode pengguna parser Yargy yang diterbitkan di Github pergi. 80% tautannya adalah proyek pendidikan, tetapi ada juga contoh informatif:
- analisis feed pada pekerjaan metro di St. Petersburg ;
- mengurai iklan untuk menyewa rumah di jejaring sosial ;
- ekstraksi atribut dari nama ban mobil ;
- mengurai lowongan dari saluran pekerjaan obrolan ODS ;
Kasus paling menarik dari penggunaan pengurai Yargy, tentu saja, tidak dipublikasikan secara publik di Github. Kirimkan ke PM jika perusahaan menggunakan Yargy dan, jika Anda tidak keberatan, tambahkan logo Anda ke natasha.github.io .
Ipymarkup - visualisasi markup entitas bernama dan hubungan sintaksis

Ipymarkup adalah perpustakaan primitif yang dibutuhkan untuk menyorot substring dalam teks, visualisasi NER. Petunjuk instalasi , contoh penggunaan di repositori Ipymarkup. Pustaka ini mirip dengan displaCy dan displaCy ENT , sangat berharga untuk men-debug tata bahasa untuk parser Yargy.
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

Proyek Natasha memiliki solusi untuk masalah penguraian . Tidak hanya perlu menyoroti kata-kata dalam teks, tetapi juga menggambar panah di antara kata-kata itu. Ada banyak solusi yang sudah jadi, bahkan ada artikel ilmiah tentang topik tersebut .
Tentu saja, tidak ada yang muncul, dan suatu hari saya benar-benar bingung, menerapkan semua keajaiban CSS dan HTML yang terkenal, menambahkan visualisasi baru ke Ipymarkup. Instruksi penggunaan di dok.
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
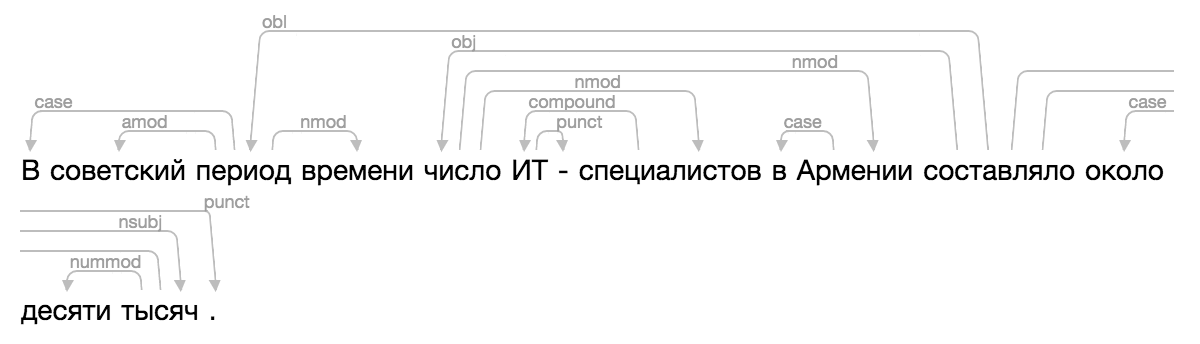
Sekarang di Natasha dan Nerus lebih mudah untuk melihat hasil penguraian.
