Ilmuwan Data mencari tahu apa yang diminati orang dan untuk apa mereka membelanjakan uang mereka
Dalam rangka meneliti berbagai khalayak, Ilmuwan Data mengamati fakta alam dan mengejutkan yang dengan jelas menjadi ciri masyarakat di sekitar kita. Dalam artikel ini saya akan berbicara tentang keingintahuan dan kasus tidak biasa yang saya perhatikan ketika melakukan tugas yang berkaitan dengan analisis audit, meneliti minat pengguna Internet, dan perilaku pembelian berbagai kelompok sosial.
Fitur sosiologis apa yang telah diidentifikasi melalui penggunaan model pembelajaran mesin? Apa yang kita ketahui tentang pelanggan?

Profil pelanggan dari ceknya? Mudah!
Saya bekerja sebagai analis data di CleverDATA dan biasanya menghadapi tugas-tugas berikut: klasifikasi data mentah, analisis audit, dan pembuatan model yang mirip (LaL), ketika pelanggan memiliki audiensnya sendiri dan dia ingin menemukan yang serupa. Ini sangat diminati untuk berbagai kampanye iklan online.
Kami memiliki 1DMC DATA Exchange , di mana anggota dapat memperkaya dan memonetisasi data mereka. Ini berisi dua jenis data yang tidak dipersonalisasi, yang digabungkan ke dalam atribut taksonomi kami - pembelian online dan aliran klik, yaitu urutan kunjungan laman yang dapat kami lacak. Format data memenuhi standar GDPR Eropa untuk perlindungan data pribadi.
Atribut taksonomi kita adalah fakta kepemilikan sesuatu atau adanya kepentingan tertentu pada seseorang. Ini adalah informasi biner - ada atau tidak.
Berikut beberapa contoh atribut taksonomi kami:

Salah satu tugas yang paling penting adalah mengumpulkan data pemasok mentah ke dalam atribut taksonomi, yaitu tugas klasifikasi.
Saya perlu menarik kesimpulan tentang pembelian orang tentang gaya hidup mereka dan apakah mereka memiliki barang-barang tertentu (secara kondisional, cek untuk model batang jalan bermerek mungkin menunjukkan bahwa pembeli adalah pemilik sepeda motor Harley-Davidson) atau mengidentifikasi minat potensial untuk membeli dari melalui halaman Internet yang mereka kunjungi. Informasi ini kemudian akan digunakan untuk iklan bertarget.

Dalam pekerjaan saya, rantai berikut muncul:
- periksa - model AI saya - profil pembeli;
- click stream - model AI saya - profil pengunjung situs.
Alat yang kami gunakan di CleverDATA akan secara otomatis membuat pengklasifikasi biner untuk atribut apa pun di taksonomi kami. Dari nama atribut taksonomi (pemilik atribut sepeda motor chopper), kami berakhir dengan pengklasifikasi biner yang dievaluasi secara otomatis (apakah modelnya bagus atau analitik perlu ditingkatkan), yang dapat menentukan ada atau tidaknya barang semacam itu pada seseorang dengan cek. Anda dapat membaca lebih lanjut tentang ini di artikel kami di Habré .

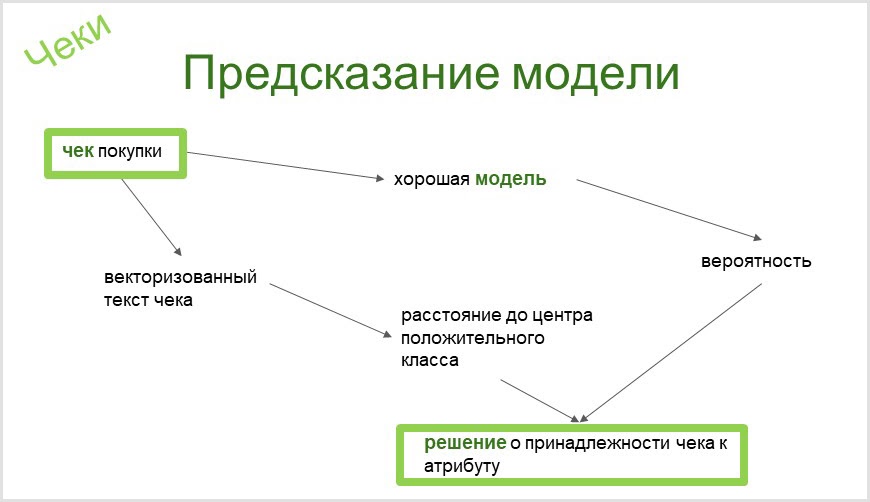
Saat mengklasifikasikan cek, Anda memerlukan alat yang memungkinkan Anda memisahkan cek yang mirip dalam kata-kata dari kesamaan artinya. Jadi, entah bagaimana saya membuat model untuk menangkap minat dalam kursus pelatihan ulang profesional. Dan dia mengidentifikasi cek untuk pembelian buku anak-anak Paolo Cossi "A Course in Magic Lessons for an Ordinary Cat" sebagai minat dalam topik tersebut. Ini tentu saja merupakan kesalahan yang lucu. Ngomong-ngomong, saya belajar tentang keberadaan buku dari cek ini.

Untuk menghindari keingintahuan seperti itu, kami menggunakan model bahasa untuk mengevaluasi pengklasifikasi biner yang dihasilkan dan memotong contoh yang serupa dalam kata-kata, tetapi tidak dalam arti.
Dari waktu ke waktu saya harus melihat-lihat tanda terima dengan mata saya untuk menemukan beberapa kecocokan palsu dan kemudian mengotomatiskan pencarian untuk koneksi yang salah dibangun. Akan sangat membantu untuk memahaminya, karena mungkin satu kasus yang tidak dapat dipahami akan memungkinkan saya untuk meningkatkan keseluruhan proses.
Selama seluruh praktik saya, saya telah mengumpulkan serangkaian cek teka-teki yang tidak hanya dapat saya klasifikasikan, tetapi bahkan menguraikan apa yang sebenarnya dibeli pembeli. Saya secara teratur membagikan kasus lucu ini dengan rekan kerja dan bahkan memulai kolom "lelucon AI".
Petunjuk paling umum adalah indikasi di cek judul buku tanpa nama produk. Inilah yang kita lihat dalam kasus "sihir untuk kucing biasa". Dan pembelian apa yang dicatat di cek "Pagar Novosibirsk 1029 rubel." dan "Kotak kontrak 5000 rubel." Saya masih tidak mengerti. Saya menerima versi Anda di komentar untuk artikel ini.
Selanjutnya, mari beralih ke klasifikasi aliran klik.
Profil klien berdasarkan pergerakannya di situs web
Sistem klasifikasi clickstream diperkenalkan oleh kami pada tahun 2019, yang kaya akan terobosan di bidang NLP (Natural Language Processing). Salah satu penemuan paling terkenal dan sukses di bidang ini adalah jaringan BERT ( Representasi Encoder Bidirectional dari Transformers ). Jadi akan ada sedikit Bertology di depan.

Dari nama atribut, menggunakan model bahasa probabilistik, kami mendapatkan daftar kueri yang ditambah (diperpanjang dengan sinonim) yang kami rayapi (kirim ke mesin telusur dan kumpulkan hasil penelusuran), dari sini kami mendapatkan sampel pelatihan kami. Mari lakukan vektorisasi menggunakan model bahasa BERT yang telah dilatih sebelumnya. Menggunakan embeddings yang diperoleh (vektor), kami melatih pengklasifikasi (dengan fungsi kerugian triplet).
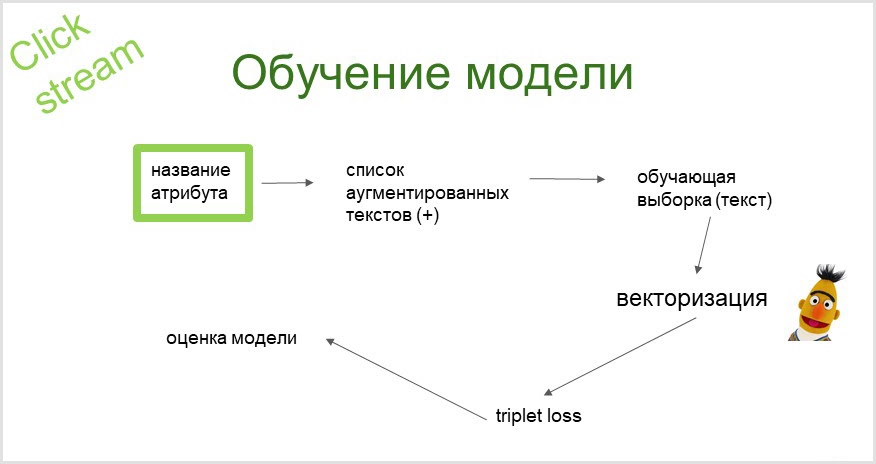
Bagaimana cara kerja prediksi tersebut?
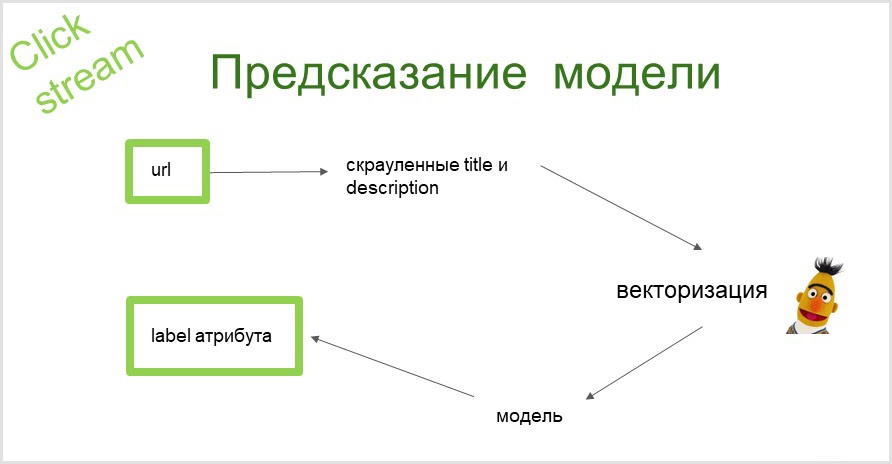
Kami mengambil url halaman, mengumpulkan informasi teks (judul dan deskripsi halaman). Dengan bantuan BERT, kami mendapatkan representasi vektor dari teks-teks ini. Kemudian vektor ini dimasukkan ke dalam model dan pada keluarannya kita mendapatkan atribut yang dapat kita referensikan ke halaman.
Secara umum, sistem ini sangat berhasil, semua kasus lucu yang saya temui lebih merupakan pengecualian daripada aturan. Tetapi saya mencoba memberi perhatian besar pada mereka, karena kesalahan kecil dapat menyebabkan konsekuensi besar yang tidak menyenangkan, karena sejumlah besar data melewati sistem.
Data online yang saya teliti menunjukkan bahwa orang membaca lebih banyak di Internet. Ternyata ini adalah salah satu topik yang sangat populer - astrologi, meramal, dll.

Halaman spesifik ini (url, bukan domain) dikunjungi oleh lebih dari 5000 ribu orang (pengenal unik) per hari. Saya sangat terkejut dengan situs yang didedikasikan untuk astrologi kucing dan mengungkapkan hubungan antara karakter hewan dan tanda zodiaknya.

Semua orang tahu tentang kata-kata berhenti dan biasanya mereka menghubungkan kamus atau memfilter berdasarkan frekuensi tanpa membahas lebih dalam secara spesifik teks. Awalnya, saya juga menghubungkan kamus saya. Hasilnya tidak menyenangkan: situs resep tanpa menggunakan makanan yang dipanggang diklasifikasikan sebagai atribut minat dalam memanggang (memanggang rumahan). Dan ini karena fakta bahwa semua partikel negatif ada di kamus stop word saya.

Menggunakan contoh saya, saya mendorong kolega saya untuk membaca kamus yang Anda gunakan untuk memfilter data Anda dengan cermat.
Masalah umum lainnya adalah orang sering menggunakan bahasa sarkastik, yang, selama tahap merangkak, mengarah ke frasa lucu dalam judul dan deskripsi halaman yang terkait dengan kueri tertentu di Internet. Misalnya, model dapat mengaitkan pasties dan minat pada diet vegetarian. Menurut saya hal ini dapat dijelaskan dengan banyaknya komentar pada artikel dengan topik vegetarianisme dengan semangat "Bagaimana Anda hidup tanpa pasties?"

Dan sekarang satu menit humor hitam dalam judul kami "lelucon AI": model menghubungkan diskusi tentang legalisasi eutanasia dengan minat untuk membeli rumah, dan rapper Timati - dengan sirkus. Saya harus merayapi data dan menandai ulang kelas secara manual.
Ada pengaturan yang tidak bisa kita kendalikan, tergantung pada masyarakat tempat kita tinggal. Dan kemudian kejahatan itu bercampur dengan komedi dan hubungan keluarga.

Dan ada juga kasus kontroversial ketika Anda bahkan tidak tahu apakah perlu memarahi model dan mendesain ulang sesuatu, berjuang dengan kesalahan, atau membiarkan semuanya apa adanya.
Ada kemungkinan bahwa penerimaan parsel memang mengandung risiko bisnis.
Apa pun bisa ditemukan di papan buletin.

Telusuri audiens serupa
Blok tugas berikutnya yang saya, sebagai seorang analis, harus selesaikan adalah Audiens Research / pemodelan yang mirip. Pelanggan, pada umumnya, menginginkan beberapa pengetahuan baru tentang audiens, yang akan membantunya menjalin komunikasi dengannya. Tetapi meskipun permintaannya tidak dirumuskan dengan jelas, kami selalu berusaha membantunya, dan dalam banyak kasus kami berhasil.
Di sini Anda memiliki pilihan apakah akan fokus pada Riset Audiens, yaitu, pada wawasan internal (analisis kecerdasan audiens), atau pada model yang mirip, yang kemudian akan memungkinkan Anda untuk mempercepat audiens pertukaran kami dan menemukan pelanggan potensial berdasarkan data internal pelanggan tentang audiens target. Audiens dipahami sebagai seperangkat pengenal yang dikodekan (nomor telepon, alamat email, atau id online). Saya mengingatkan Anda bahwa kami tidak bekerja dengan data dalam bentuk yang jelas, kami mematuhi semua aturan hukum.
Jadi, kami dapat menyilangkan banyak pengenal yang disandikan dengan bursa dan melihat perilaku pembelian atau aliran klik mereka. Kami melakukan pengelompokan untuk audiens target dan tugas apa pun. Setelah model mengelompokkan orang-orang menurut perilaku pembelian mereka, entah bagaimana saya melihat sekelompok orang hanya terdiri dari orang-orang yang bertaruh pada olahraga dan tidak lagi membeli apa pun secara online. Meskipun, ada kemungkinan mereka memiliki akun terpisah untuk tujuan taruhan.
Berikut tangkapan layar dari cluster ini.

Kasus "Happy motherhood"
Untuk kampanye iklan untuk merek popok terkenal, perlu dilakukan penelitian khalayak dan menemukan wanita pada trimester ketiga kehamilan - pelanggan menyarankan bahwa dari trimester ketiga produk harus diiklankan sehingga sebagian besar khalayak akan membelinya.
Pada awal analisis, gambaran keadaan kehidupan ibu hamil menyerupai gambaran yang sangat indah: keluarga muda dengan hewan peliharaan, pada malam kelahiran seorang anak, melengkapi tempat tinggal.

Wanita dari kelompok yang berbeda memiliki gadget dengan merek berbeda, lebih suka merek produk kebersihan yang berbeda, dan secara umum semuanya baik-baik saja. Lihat diri mu sendiri.
25,5% ID
Pembeli Huggies Elite Soft tiga kali lebih kecil kemungkinannya untuk membeli Pampers dan 7 kali lebih kecil kemungkinannya untuk membeli produk Lovular. Mereka menggunakan produk merek Peligrin. Dengan probabilitas tinggi (0,6) adalah orang tua dari anak perempuan. Mereka cenderung membayar utilitas melalui Internet.
25,5% dari pengenal
cenderung membayar untuk layanan komunikasi dan asuransi melalui Internet. Dengan probabilitas tinggi (0,6) adalah pemilik anjing. Beli produk Helen Harper. Di antara elektronik konsumen, merek Xiaomi diekspresikan.
17,5% pengenal
Pengguna Ozon Premium. Mereka membeli perlengkapan perawatan bayi Philips Avent dan tertarik dengan perlengkapan dan pemasangan setrika.
Perhatian, saran untuk masa depan: hati-hati terhadap promosi / merek yang menimbulkan keributan dalam total volume data.
Status Ozon Premium di banyak cluster kami ternyata menjadi salah satu atribut yang menentukan. Namun menargetkan audiens pembeli popok potensial hanya untuk Ozon Premium berada di luar akal sehat. Jadi saya harus menghapus status dari semua data. Ya, saya kemudian menurunkan metrik, tetapi pada saat yang sama meningkatkan kecukupan model. Tempat pertama diambil oleh barang-barang untuk bayi yang baru lahir, dan bukan oleh status populer yang dipromosikan. Itu adalah pengalaman yang mengajari saya untuk memotong barang yang terlalu signifikan untuk model tersebut.
Untuk pemodelan serupa, gagasan untuk membangun beberapa pengklasifikasi sederhana dari audiens target (kelas 1) dan digeneralisasikan (kelas 0) terletak di permukaan untuk menyoroti audiens target.
Sebagai contoh, mari kita membeli target audiens dan sepuluh kali volume profil acak. Kami membawa informasi ini secara berurutan, pembelian. Kemudian kami bekerja dengan teks yang dihasilkan (preprocessing): kami menghapus semua kata-kata frekuensi tinggi yang tidak informatif, dan membawa sisanya ke bentuk awal. Selanjutnya, kami membangun pengklasifikasi sederhana dari beberapa keluarga yang berbeda - linier (SVC Linear, Regresi Logistik), "kayu" (RandomForest), dll. - dan mengukur kepentingan fitur, yaitu, pentingnya kata apa pun dalam opini model. Saya menemukan nilai ambang batas, yang di atasnya nilai pentingnya tanda-tanda ini tidak memadai, yaitu tanda terlalu berisik. Sebelum membangun sesuatu yang otomatis, Anda harus menerapkan akal sehat dan metode pandangan sekilas berkali-kali untuk mengumpulkan statistik internal dan memahami metode mana yang berhasil dan mana yang tidak.
Kami memeriksa kelompok-kelompok dengan gambar yang sangat indah pada malam kelahiran seorang anak, tetapi kisah kehidupan lain juga dilacak. Misalnya, di salah satu cluster, calon pembeli popok bayi baru lahir kemungkinan besar (0,65) memiliki akun di situs kencan. Ini bukan pernyataan yang tidak berdasar, mereka membayar layanan di situs tersebut.
Agar wawasan dapat "bekerja", Anda harus selalu menafsirkan pengetahuan baru, tetapi kali ini saya sama sekali tidak ingin mencari cerita di dalamnya - semua orang tahu tentang penyakit sosial dan kekacauan sehari-hari di negara kita.

Izinkan saya mengingatkan Anda bahwa sebagai bagian dari kasus ini, kami meneliti seluruh audiens yang tertarik membeli popok untuk bayi baru lahir. Dan ternyata tidak hanya wanita yang hamil trimester ketiga.
Saya menyebut cluster terpisah "Sunday Dads" - perwakilannya adalah penggemar sepak bola, penggemar mobil yang rajin, membeli komponen untuk mobil Sparco dan dari waktu ke waktu membeli produk Chupa Chups.
Dan sekarang perhatiannya, pertanyaannya: apakah perlu menghapus "Sunday dads" jika mereka tidak berhubungan dengan target audiens yang awalnya ditentukan? Saya sering menanyakan pertanyaan ini kepada manajer proyek saya, dan tugas tersebut telah dipikirkan ulang. Mungkin kita tidak terlalu membutuhkan target audiens yang spesifik, tetapi setiap orang yang bisa menjadi pembeli produk. Dalam kasus kami, ini adalah ayah, dan kakek-nenek, saudara laki-laki, dan pacar dari seorang wanita yang sedang melahirkan, siap untuk merawat bayi. Jawaban audiens mana yang harus dipertimbangkan sebagai target adalah untuk perwakilan bisnis.
Kasus "Pengusaha Perorangan"

Kasus berikutnya, yang akan saya ceritakan kepada Anda, adalah Riset Audiens untuk audiens target “Pengusaha perorangan” yang telah membuka rekening koran di bank terkenal.
Perbedaan utama antara orang-orang ini dan penonton bursa dapat dilihat dengan jelas dalam pembelian mereka. Yang paling jelas adalah pembayaran royalti (10-15% dari profil), layanan keamanan dan tagihan utilitas untuk bangunan non-hunian. Di antara tanda tidak langsung yang menunjuk kepada pengusaha adalah pembelian satu bagasi tambahan selama penerbangan (dalam 15-20% kasus). Di seluruh volume pemeriksaan, bagian penting terdiri dari buku-buku tentang psikologi, pengetahuan diri dan pengembangan diri, lokakarya untuk berkomunikasi dengan bawahan dan literatur pembinaan.
Dengan bantuan pentingnya fitur LaL, kami mendapatkan tanda-tanda tidak langsung dari target audiens: transportasi udara, pembelian robot penyedot debu, mesin kopi, smartphone Honor, pengiriman bunga, pembayaran premi asuransi. Kasus ini adalah salah satu kasus luar biasa di mana mesin memberi kita hasil yang mudah ditafsirkan.
Orang sibuk membeli robot rumahan. Tidak ada kantor yang dapat melakukannya tanpa mesin kopi. Pengiriman bunga dan penerbangan yang sering juga dapat dihubungkan =).
Kasus "Pemilik mobil"
Sebuah merek mobil terkenal di segmen harga "di atas rata-rata" sangat yakin bahwa pelanggannya adalah orang-orang yang benar-benar luar biasa dan ingin mengetahui kebiasaan dan preferensi mereka.
Target audiens ini secara signifikan tumpang tindih dengan kasus sebelumnya ("Pengusaha perorangan"). Tetapi tidak semua pengusaha perorangan membeli mobil merek ini.

Ternyata ide pelanggan tentang keunikan pelanggan sangat dibesar-besarkan. Ya, penontonnya tidak sesuai dengan rata-rata, tetapi hanya dalam beberapa detail, misalnya, pengendara lebih suka membeli teh elit (300 rubel lebih mahal) dan umumnya menghabiskan lebih banyak untuk keindahan dan estetika daripada fungsional dan praktis.
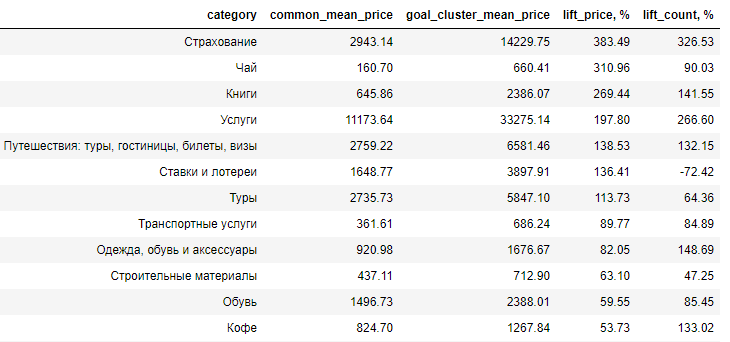
Di sini, perbedaan antara audiens target dan audiens rata-rata pembeli dalam hal peningkatan disajikan, yaitu, berdasarkan persentase berapa harga rata-rata suatu produk di audiens yang dipelajari melebihi nilai yang sama di audiens rata-rata (lift_price). Seperti yang Anda lihat, pengeluaran utama adalah untuk kesenangan.
Kami selalu menguji hipotesis dengan adil dan tidak memihak. Diharapkan terkadang hipotesis pelanggan tentang eksklusivitas audiensnya tidak didukung oleh data yang diperoleh. Tidak ada yang perlu dikhawatirkan, hanya perlu hipotesis dan penelitian baru.

Sebagai kesimpulan, saya akan mengatakan bahwa dalam pekerjaan saya, saya dipandu oleh prinsip "Rutin menenangkan". Dan saya menyarankan Anda.
Dengan data yang begitu beragam, sangat penting untuk berhati-hati dan memperhatikan hal-hal kecil, karena pengecualian apa pun pada pandangan pertama mungkin nanti berubah menjadi aturan dan kita bisa mendapatkan banyak hasil yang salah.
Jadi, jika saya tidak melihat apa yang dirujuk oleh model "tanpa memanggang" saya sebagai "memanggang", sistem "bocor" akan masuk ke produksi. Jadi jangan abaikan rutinitas: jika Anda menghabiskan setengah jam memeriksa mata, Anda bisa tidur nyenyak - model tidak akan membuat kesalahan.
