int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}Ini adalah aplikasi sederhana khusus untuk eksperimen, mencari bilangan prima menggunakan saringan Eratosthenes . Mari jalankan solusi 20 kali dan hitung waktu pengguna untuk setiap eksekusi.
Deskripsi bangku tes
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
Sebar waktu eksekusi sebelum pengoptimalan:
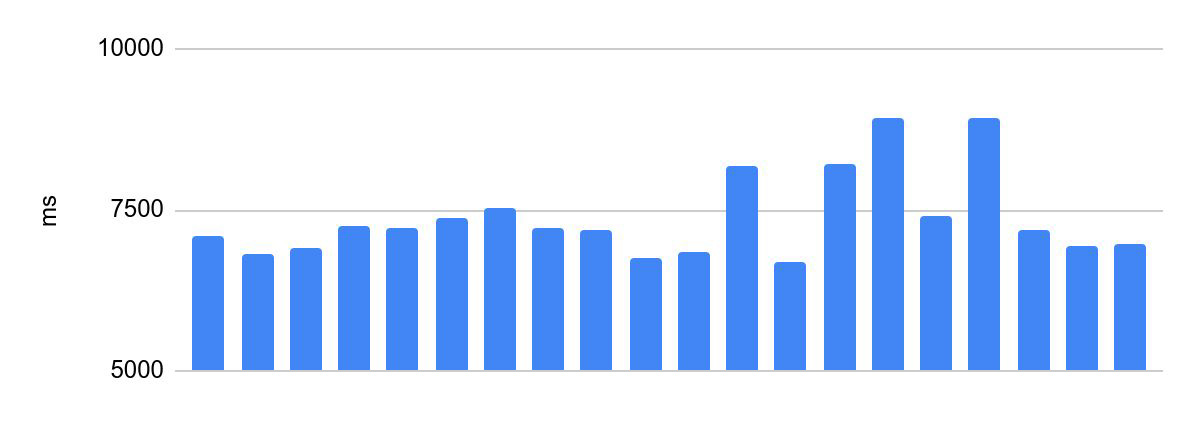
Perbedaan antara eksekusi tercepat dan paling lambat adalah 2230 ms.
Ini tidak dapat diterima untuk pemrograman Olimpiade. Waktu pelaksanaan kode peserta merupakan salah satu kriteria keberhasilan solusinya dan salah satu syarat kompetisi, pembagian hadiah bergantung pada hal ini. Oleh karena itu, ada persyaratan penting untuk sistem tersebut - waktu verifikasi yang sama untuk kode yang sama. Berikut ini, kami akan menyebutnya sebagai konsistensi eksekusi kode.
Mari kita coba menyelaraskan waktu eksekusi.
Isolasi inti
Mari kita mulai dengan yang sudah jelas. Proses bersaing untuk mendapatkan inti, dan Anda harus mengisolasi inti tersebut untuk pelaksanaan solusi. Selain itu, dengan Hyper Threading diaktifkan, sistem operasi menetapkan satu inti prosesor fisik sebagai dua inti logis terpisah. Untuk mengisolasi inti secara jujur, kita perlu menonaktifkan Hyper Threading. Ini dapat dilakukan di pengaturan BIOS.
Kernel Linux yang out-of-the-box mendukung tanda startup untuk mengisolasi isolcpus kernel Tambahkan tanda ini ke GRUB_CMDLINE_LINUX_DEFAULT di pengaturan grub: / etc / default / grub. Misalnya:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
Jalankan update-grub dan mulai ulang sistem.
Semuanya terlihat seperti yang diharapkan - dua kernel pertama tidak digunakan oleh sistem:

Mari kita mulai dengan kernel yang terisolasi. Konfigurasi CPU Affinity memungkinkan Anda mengikat proses ke inti tertentu. Ada beberapa cara untuk melakukannya. Misalnya, mari kita jalankan solusi dalam wadah porto (kernel dipilih menggunakan argumen cpu_set):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop: kami menggunakan QEMU-KVM untuk menjalankan solusi dalam produksi. Wadah porto digunakan di seluruh artikel agar lebih mudah ditampilkan.
Meluncurkan dengan kernel yang didedikasikan untuk solusi, tanpa memuat kernel tetangga:

Perbedaannya adalah 375 ms. Sudah lebih baik, tapi masih terlalu banyak.
Penampilan Tyunim
Mari kita coba uji stres kita. Yang mana? Tugas kita adalah memuat semua inti dengan banyak utas. Hal ini dapat dilakukan dengan beberapa cara:
- Tulis aplikasi sederhana yang akan membuat banyak utas dan mulai menghitung sesuatu di masing-masing utas.
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
Peluncuran dengan inti yang didedikasikan untuk solusi, dengan beban pada inti yang berdekatan:

Perbedaannya adalah 1354 md: satu detik lebih banyak daripada tanpa beban. Jelasnya, beban mempengaruhi waktu eksekusi, meskipun faktanya kami menjalankan kernel yang terisolasi. Terlihat bahwa pada saat tertentu waktu eksekusi mengalami penurunan. Sekilas, ini berlawanan dengan intuisi: dengan meningkatnya beban, kinerja juga meningkat.
Dalam produksi, perilaku ini (saat waktu eksekusi mulai mengambang di bawah beban) bisa sangat menyakitkan untuk diaktifkan. Berapa beban dalam kasus ini? Aliran keputusan dari peserta, paling sering di kompetisi dan olimpiade besar.
Alasannya adalah Intel Turbo Boost diaktifkan saat beban - sebuah teknologi untuk meningkatkan frekuensi. Nonaktifkan. Untuk stand saya, saya juga mematikan SpeedStep... Untuk prosesor AMD, Turbo Core Cool'n'Quiet harus dimatikan. Semua hal di atas dilakukan di BIOS, ide utamanya adalah menonaktifkan apa yang secara otomatis mengontrol frekuensi prosesor.
Berjalan pada inti yang terisolasi dengan Turbo Boost dinonaktifkan dan memuat pada inti tetangga:

Kelihatannya bagus, tetapi perbedaannya masih 252ms. Dan itu masih terlalu banyak.
Offtop: perhatikan bagaimana waktu eksekusi rata-rata turun sekitar 25%. Dalam kehidupan sehari-hari, teknologi yang dinonaktifkan itu bagus.
Kami menyingkirkan persaingan untuk inti, menstabilkan frekuensi inti - sekarang tidak ada yang memengaruhi mereka. Jadi, dari mana asal perbedaannya?
NUMA
Non-Uniform Memory Access, atau Non-Uniform Memory Architecture, "arsitektur dengan memori yang tidak rata." Dalam sistem NUMA (yaitu, secara konvensional, pada komputer multiprosesor modern), setiap prosesor memiliki memori lokal, yang dianggap sebagai bagian dari total. Setiap prosesor dapat mengakses memori lokalnya dan memori lokal prosesor lain (memori jarak jauh). Ketidakrataannya adalah akses ke memori lokal terasa lebih cepat.
Waktu eksekusi "berjalan" justru karena ketidakseimbangan tersebut. Mari perbaiki dengan mengikat eksekusi kita ke node numa tertentu. Untuk melakukan ini, tambahkan node numa ke konfigurasi kontainer porto:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Berjalan pada inti yang terisolasi dengan Turbo Boost dinonaktifkan, konfigurasi NUMA dan pemuatan pada inti tetangga:
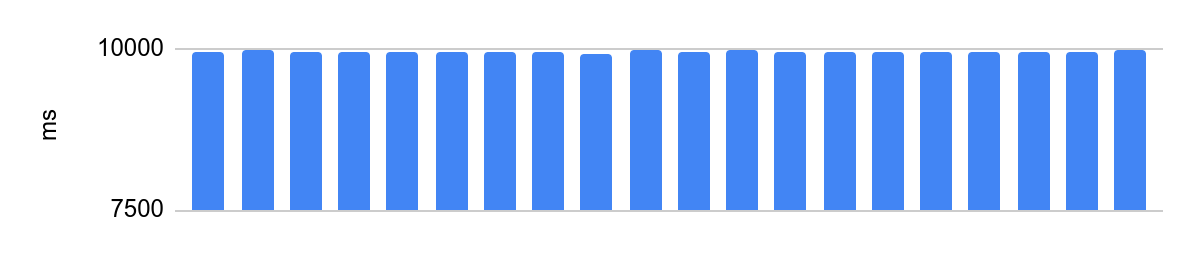
Perbedaannya adalah 48 ms, dan waktu eksekusi rata-rata setelah kami menonaktifkan pengoptimalan prosesor adalah 10 detik. 48ms pada 10s setara dengan kesalahan 0,5%, sangat bagus.
Spoiler penting
Sedikit lebih banyak tentang isolcpus
Bendera isolcpus bermasalah: beberapa utas sistem masih dapat menjadwalkan ke kernel yang terisolasi.
Oleh karena itu, dalam produksi kami menggunakan kernel yang ditambal dengan fungsionalitas tambahan dari tanda ini. Jadi, kami memilih kernel, dengan mempertimbangkan bendera, ketika utas menjadwalkan.
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
Rencana untuk masa depan
Pools
Jika satu mesin yang menentukan lebih kuat dari yang lain, maka tidak ada jumlah tweak isolasi inti yang akan membantu - sebagai hasilnya, kami masih akan mendapatkan perbedaan besar dalam waktu eksekusi. Oleh karena itu, Anda perlu memikirkan lingkungan yang heterogen. Hingga saat ini, kami sama sekali tidak mendukung heterogenitas - seluruh armada mesin penentu dilengkapi dengan perangkat keras yang sama. Namun dalam waktu dekat, kami akan mulai membagi perangkat keras yang berbeda menjadi kumpulan yang homogen, dan setiap kompetisi akan diadakan dalam kumpulan yang sama dengan perangkat keras yang sama.
Pindah ke cloud
Tantangan baru untuk sistem adalah perlunya diluncurkan di Yandex.Cloud. Dengan standar saat ini, server besi tidak dapat diandalkan, perlu dipindahkan, tetapi penting untuk menjaga konsistensi dalam pelaksanaan paket. Di sini kemungkinan teknis masih diselidiki. Ada gagasan bahwa, dalam kasus ekstrem, mesin cloud dapat menjalankan solusi yang tidak memerlukan waktu eksekusi yang ketat. Jadi, kami akan mengurangi beban pada mesin besi dan mereka hanya akan menangani solusi yang hanya membutuhkan konsistensi. Ada pilihan lain: pertama periksa parsel di cloud dan, jika tidak memenuhi batas waktu, periksa ulang di perangkat keras sebenarnya.
Mengumpulkan statistik
Bahkan setelah semua penyesuaian, prosesor pasti akan terhambat. Untuk mengurangi efek negatif, kami akan menjalankan solusi secara paralel, membandingkan hasilnya dan, jika berbeda, meluncurkan pemeriksaan ulang. Selain itu, jika salah satu mesin yang menentukan terus merosot, ini adalah alasan untuk menghentikan layanan dan mengatasi alasannya.
kesimpulan
Kontes memiliki kekhasan - tampaknya semuanya bermuara pada menjalankan kode dan mendapatkan hasilnya. Dalam artikel ini, saya hanya mengungkapkan satu aspek kecil dari proses ini. Ada sesuatu seperti ini di setiap lapisan layanan.