Di perusahaan kami, kami secara aktif mengerjakan abstraksi otomatis dokumen, artikel ini tidak menyertakan semua detail dan kode, tetapi menjelaskan pendekatan dan hasil utama menggunakan contoh kumpulan data netral: 30.000 artikel berita olahraga sepak bola dikumpulkan dari portal informasi Sport-Express.
Jadi, peringkasan dapat didefinisikan sebagai pembuatan ringkasan otomatis (judul, ringkasan, anotasi) dari teks asli. Ada 2 pendekatan yang sangat berbeda untuk masalah ini: ekstraktif dan abstraktif.
Peringkasan ekstraktif
Pendekatan ekstraktif terdiri dari penggalian blok informasi yang paling "signifikan" dari teks sumber. Satu blok bisa berupa paragraf tunggal, kalimat, atau kata kunci.

Metode pendekatan ini ditandai dengan adanya fungsi evaluasi pentingnya blok informasi. Dengan memeringkat blok-blok ini dalam urutan kepentingan dan memilih jumlah yang ditentukan sebelumnya, kami membentuk ringkasan akhir teks.
Mari beralih ke uraian tentang beberapa pendekatan ekstraktif.
Penjumlahan ekstraktif berdasarkan kemunculan kata-kata umum
Algoritma ini sangat sederhana untuk dipahami dan diterapkan lebih lanjut. Di sini kami hanya bekerja dengan kode sumber, dan pada umumnya kami tidak perlu melatih model ekstraksi apa pun. Dalam kasus saya, blok informasi yang diambil akan mewakili kalimat teks tertentu.
Jadi, pada langkah pertama, kami memecah teks masukan menjadi kalimat dan memecah setiap kalimat menjadi token (kata terpisah), melakukan lemmatisasi untuknya (membawa kata ke bentuk "kanonik"). Langkah ini diperlukan agar algoritme dapat menggabungkan kata-kata yang artinya identik, tetapi berbeda dalam bentuk kata.
Kemudian kami mengatur fungsi kesamaan untuk setiap pasangan kalimat. Ini akan dihitung sebagai rasio jumlah kata umum yang ditemukan di kedua kalimat dengan total panjangnya... Hasilnya, kami mendapatkan koefisien kesamaan untuk setiap pasangan kalimat.
Setelah sebelumnya menghilangkan kalimat yang tidak memiliki kata-kata yang sama dengan orang lain, kami membuat grafik di mana simpul adalah kalimat itu sendiri, ujung-ujungnya menunjukkan adanya kata-kata umum di dalamnya.
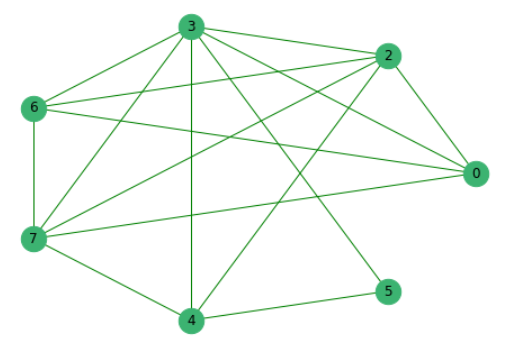
Selanjutnya, kami memberi peringkat semua proposal menurut kepentingannya.

Memilih beberapa kalimat dengan koefisien tertinggi dan kemudian mengurutkannya berdasarkan jumlah kemunculannya dalam teks, kita mendapatkan ringkasan akhir.
Penjumlahan ekstraktif berdasarkan representasi vektor terlatih
Data berita teks lengkap yang dikumpulkan sebelumnya digunakan untuk membangun algoritme berikutnya.
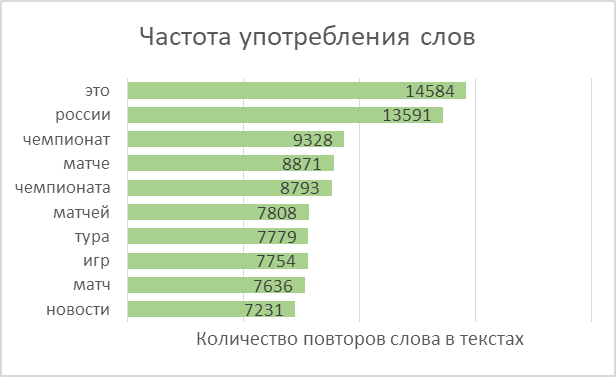
Kami membagi kata-kata di semua teks menjadi token dan menggabungkannya menjadi sebuah daftar. Secara total, teks berisi 2.270.778 kata, 114.247 di antaranya di antaranya adalah unik.
Dengan menggunakan model Word2Vec yang populer, kita akan menemukan representasi vektornya untuk setiap kata unik. Model memberikan vektor acak untuk setiap kata dan selanjutnya, pada setiap langkah pembelajaran, "mempelajari konteks", mengoreksi nilai-nilainya. Dimensi vektor, yang mampu "mengingat" fitur kata, Anda dapat mengaturnya. Berdasarkan volume dataset yang tersedia, akan diambil vektor yang terdiri dari 100 angka. Saya juga mencatat bahwa Word2Vec adalah model yang dapat dilatih ulang, yang memungkinkan Anda mengirimkan data baru ke masukan dan, atas dasar mereka, memperbaiki representasi vektor kata yang ada.
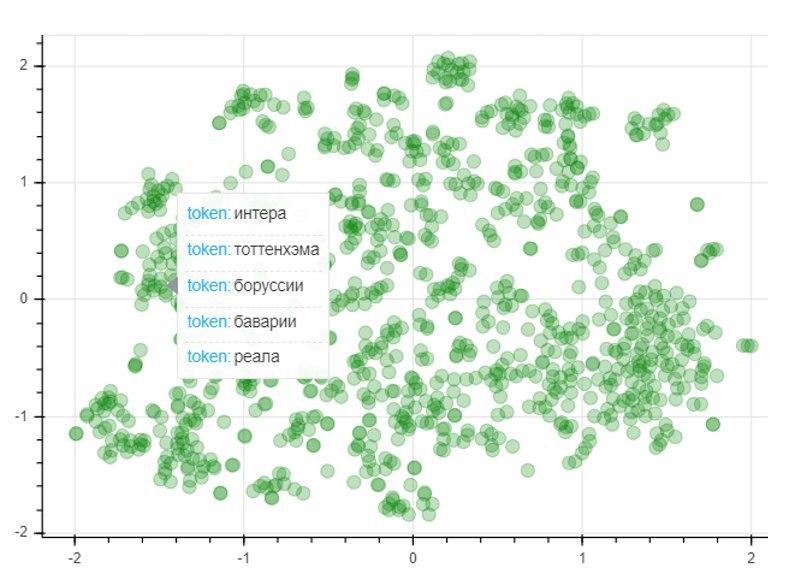
Untuk menilai kualitas model, kami akan menerapkan metode reduksi dimensi T-SNE, yang secara iteratif membuat pemetaan vektor untuk 1000 kata yang paling banyak digunakan ke dalam ruang dua dimensi. Grafik yang dihasilkan merepresentasikan lokasi titik-titik, yang masing-masing berhubungan dengan kata tertentu sedemikian rupa sehingga kata-kata yang memiliki makna yang mirip terletak berdekatan satu sama lain, dan sebaliknya. Jadi di sisi kiri grafik adalah nama klub sepak bola, dan titik di sudut kiri bawah mewakili nama dan nama keluarga pemain dan pelatih sepak bola:
Setelah mendapatkan representasi vektor kata yang terlatih, Anda dapat melanjutkan ke algoritme itu sendiri. Seperti pada kasus sebelumnya, pada input kita memiliki teks yang kita bagi menjadi kalimat. Dengan memberi token pada setiap kalimat, kami membuat representasi vektor untuk mereka. Untuk melakukan ini, kami mengambil rasio jumlah vektor untuk setiap kata dalam kalimat dengan panjang kalimat itu sendiri. Vektor kata yang dilatih sebelumnya membantu kita di sini. Jika tidak ada kata dalam kamus, vektor nol ditambahkan ke vektor kalimat saat ini. Dengan demikian, kami menetralkan pengaruh kemunculan kata baru yang tidak ada dalam kamus pada vektor umum kalimat.
Selanjutnya, kami membuat matriks kesamaan kalimat yang menggunakan rumus kesamaan kosinus untuk setiap pasangan kalimat.
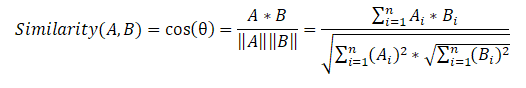
Pada tahap terakhir, berdasarkan matriks kemiripan, kami juga membuat grafik dan melakukan pemeringkatan kalimat berdasarkan kepentingan. Seperti pada algoritma sebelumnya, kita mendapatkan daftar kalimat yang diurutkan sesuai dengan kepentingannya dalam teks.

Pada akhirnya, saya akan menggambarkan secara skematis dan sekali lagi menjelaskan tahapan utama dari implementasi algoritma (untuk algoritma ekstraktif pertama, urutan tindakannya persis sama, kecuali bahwa kita tidak perlu menemukan representasi vektor dari kata-kata, dan fungsi kesamaan untuk setiap pasangan kalimat dihitung berdasarkan kemunculan kesamaan kata):

- Memisahkan teks masukan menjadi kalimat terpisah dan memprosesnya.
- Cari representasi vektor untuk setiap kalimat.
- Menghitung dan menyimpan kesamaan antara vektor kalimat dalam matriks.
- Transformasi matriks yang dihasilkan menjadi grafik dengan kalimat berupa simpul dan perkiraan kemiripan dalam bentuk edge untuk menghitung peringkat kalimat.
- Pemilihan proposal dengan skor tertinggi untuk resume akhir.
Perbandingan algoritma ekstraktif
Menggunakan mikroframework Flask ( alat untuk membuat aplikasi web minimalis ), layanan web pengujian dikembangkan untuk membandingkan keluaran model ekstraktif secara visual menggunakan contoh berbagai teks berita sumber. Saya menganalisis sinopsis yang dihasilkan oleh kedua model (mengekstrak 2 kalimat paling signifikan) untuk 100 artikel berita olahraga yang berbeda.

Berdasarkan hasil perbandingan hasil penentuan penawaran yang paling relevan oleh kedua model, saya dapat menawarkan rekomendasi penggunaan algoritma berikut ini:
- . , . , .
- . , , , . , , , .
Peringkasan abstraktif
Pendekatan abstraktif sangat berbeda dari pendahulunya dan terdiri dari pembuatan ringkasan dengan pembuatan teks baru, yang berarti meringkas dokumen utama.
Ide utama dari pendekatan ini adalah bahwa model tersebut mampu menghasilkan ringkasan yang benar-benar unik, yang mungkin berisi kata-kata yang tidak ada dalam teks aslinya. Model inferensi adalah beberapa menceritakan kembali teks, yang lebih mirip dengan kompilasi manual dari ringkasan teks oleh orang-orang.
Fase belajar
Saya tidak akan membahas pembuktian matematis dari algoritme, semua model yang saya tahu didasarkan pada arsitektur "encoder-decoder", yang pada gilirannya dibangun menggunakan lapisan LSTM berulang (Anda dapat membaca tentang prinsip kerja mereka di sini ). Saya akan menjelaskan secara singkat langkah-langkah untuk memecahkan kode urutan tes.
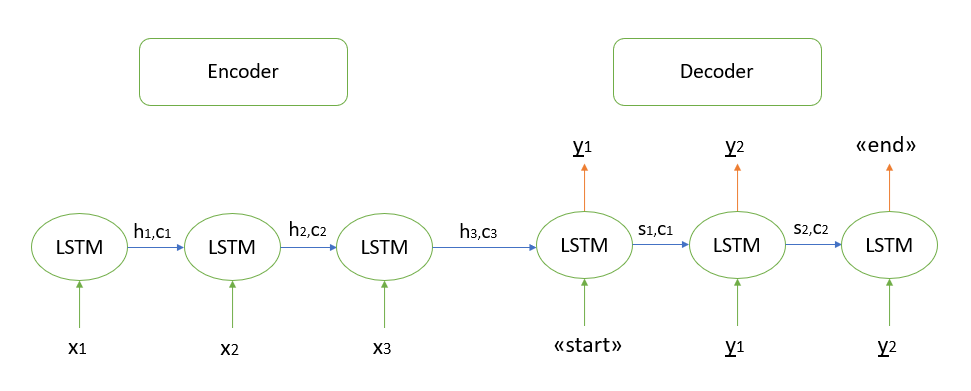
- Kami mengenkode seluruh urutan input dan menginisialisasi decoder dengan status internal encoder
- Teruskan token "mulai" sebagai masukan ke decoder
- Kami memulai decoder dengan status internal encoder untuk satu langkah waktu, sebagai hasilnya kami mendapatkan probabilitas dari kata berikutnya (kata dengan probabilitas maksimum)
- Teruskan kata yang dipilih sebagai input ke decoder pada langkah waktu berikutnya dan perbarui status internal
- Ulangi langkah 3 dan 4 hingga kami membuat token "akhir"
Detail lebih lanjut tentang arsitektur "encoder-decoder" dapat ditemukan di sini .
Menerapkan peringkasan abstraktif
Untuk membangun model abstraktif yang lebih kompleks untuk mengekstraksi konten ringkasan, teks berita lengkap dan judulnya diperlukan. Judul berita akan berfungsi sebagai ringkasan, karena model urutan teks yang panjang “tidak ingat dengan baik”.
Saat membersihkan data, kami menggunakan terjemahan huruf kecil dan membuang karakter non-bahasa Rusia. Lemmatisasi kata, penghapusan preposisi, partikel, dan bagian kata yang tidak informatif lainnya akan berdampak negatif pada hasil akhir model, karena hubungan antar kata dalam kalimat akan hilang.
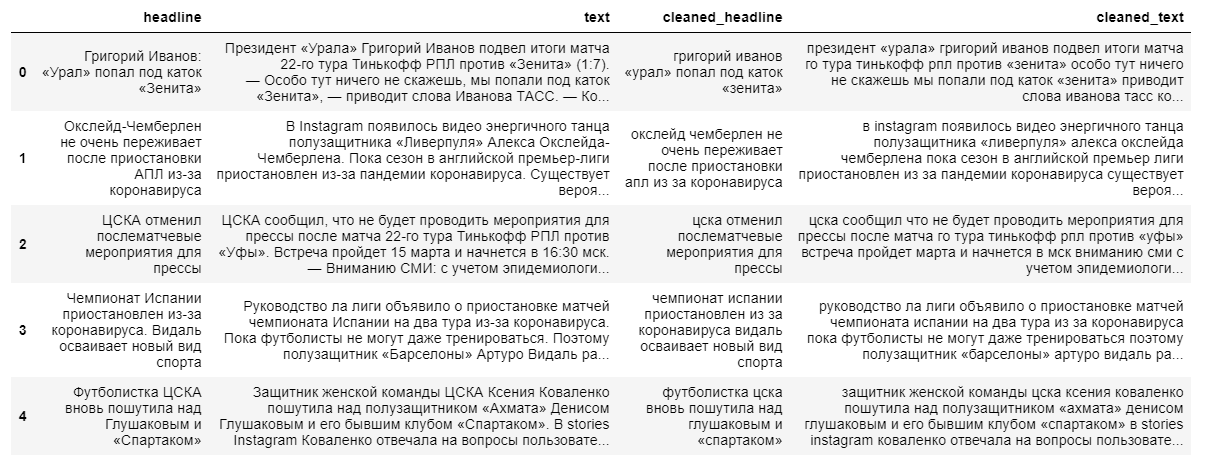
Selanjutnya, kami membagi teks dan judulnya menjadi sampel pelatihan dan pengujian dalam rasio 9 banding 1, setelah itu kami mengubahnya menjadi vektor (secara acak).
Pada langkah berikutnya, kami membuat model itu sendiri, yang akan membaca vektor kata yang ditransmisikan dan menjalankan pemrosesannya menggunakan 3 lapisan berulang encoder LSTM dan 1 lapisan dekoder.
Setelah menginisialisasi model, kami melatihnya menggunakan fungsi kerugian lintas-entropi yang menunjukkan perbedaan antara judul target yang sebenarnya dan yang diprediksi oleh model kami.

Terakhir, kami mengeluarkan hasil model untuk set pelatihan. Seperti yang Anda lihat dalam contoh, teks sumber dan ringkasan berisi ketidakakuratan karena membuang kata-kata langka sebelum membangun model (kami membuangnya untuk "menyederhanakan pembelajaran").

Keluaran model pada tahap ini meninggalkan banyak hal yang diinginkan. Model itu “berhasil mengingat” beberapa nama klub dan nama pemain sepak bola, namun praktis tidak menangkap konteksnya sendiri.
Meskipun pendekatan yang lebih modern untuk melanjutkan ekstraksi, algoritma ini masih sangat kalah dengan model ekstraktif yang dibuat sebelumnya. Namun demikian, untuk meningkatkan kualitas model, Anda dapat melatih model pada kumpulan data yang lebih besar, tetapi, menurut saya, untuk mendapatkan keluaran model yang benar-benar bagus, perlu untuk mengubah atau, mungkin, sepenuhnya mengubah arsitektur jaringan saraf yang digunakan.
Jadi pendekatan mana yang lebih baik?
Meringkas artikel ini, saya akan membuat daftar pro dan kontra utama dari pendekatan yang ditinjau untuk mengekstraksi ringkasan:
1. Pendekatan ekstraktif:
Keuntungan:
- Inti dari algoritme ini intuitif
- Kemudahan implementasi yang relatif
Kekurangan:
- Kualitas konten dalam banyak kasus bisa lebih buruk daripada konten tulisan tangan manusia
2. Pendekatan
abstraktif: Keuntungan:
- Algoritma yang diterapkan dengan baik mampu menghasilkan hasil yang paling mendekati penulisan resume manual
Kekurangan:
- Kesulitan dalam memahami ide teoritis utama dari algoritma
- Biaya tenaga kerja yang besar dalam implementasi algoritma
Tidak ada jawaban tegas untuk pertanyaan tentang pendekatan mana yang paling baik membentuk resume akhir. Itu semua tergantung pada tugas dan tujuan spesifik pengguna. Misalnya, algoritme ekstraktif kemungkinan besar lebih cocok untuk menghasilkan konten dokumen multi-halaman, di mana ekstraksi kalimat yang relevan benar-benar dapat menyampaikan gagasan teks besar dengan benar.
Menurut pendapat saya, masa depan adalah milik algoritma abstraktif. Terlepas dari kenyataan bahwa saat ini mereka kurang berkembang dan pada tingkat kualitas keluaran tertentu mereka hanya dapat digunakan untuk menghasilkan ringkasan kecil (1-2 kalimat), ada baiknya menunggu terobosan dari metode jaringan saraf. Di masa depan, mereka dapat membuat konten untuk semua ukuran teks dan, yang terpenting, konten itu sendiri akan sedekat mungkin dengan pembuatan manual resume oleh seorang ahli di bidang tertentu.
Veklenko Vlad, Analis Sistem,
Codex Consortium