Tapi bagaimana tepatnya cara kerja Pelacakan Objek? Ada banyak solusi Pembelajaran Mendalam untuk masalah ini, dan hari ini saya ingin berbicara tentang solusi umum dan matematika di baliknya.
Jadi, dalam artikel ini saya akan mencoba memberi tahu Anda dengan kata-kata dan rumus sederhana tentang:
- YOLO adalah pendeteksi objek yang bagus
- Filter Kalman
- Jarak Mahalanobis
- SORT dalam
YOLO adalah pendeteksi objek yang bagus
Anda harus segera membuat catatan yang sangat penting yang perlu Anda ingat - Deteksi Objek bukanlah Pelacakan Objek. Bagi banyak orang, ini bukan berita, tetapi seringkali orang bingung dengan konsep ini. Dengan kata sederhana:
Deteksi Objek hanyalah definisi objek dalam gambar / bingkai. Artinya, algoritme atau jaringan neural mendefinisikan objek dan mencatat posisinya serta kotak pembatas (parameter persegi panjang di sekitar objek). Sejauh ini, tidak ada pembicaraan tentang bingkai lain, dan algoritme hanya berfungsi dengan satu.
Contoh:
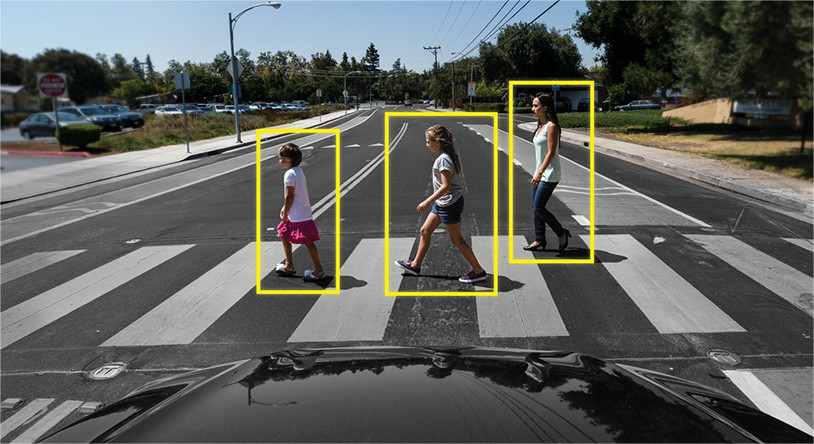
Pelacakan Objek adalah masalah lain. Di sini tugasnya tidak hanya mengidentifikasi objek dalam bingkai, tetapi juga menghubungkan informasi dari bingkai sebelumnya sedemikian rupa agar tidak kehilangan objek, atau membuatnya unik.
Contoh:

Artinya, Pelacak Objek menyertakan Deteksi Objek untuk menentukan objek, dan algoritme lain untuk memahami objek mana pada bingkai baru yang termasuk dalam bingkai sebelumnya.
Oleh karena itu, Deteksi Objek memainkan peran yang sangat penting dalam tugas pelacakan.
Mengapa YOLO? Ya, karena YOLO dianggap lebih efisien daripada banyak algoritme lain untuk mengidentifikasi objek. Berikut adalah grafik kecil untuk perbandingan dari pencipta YOLO:
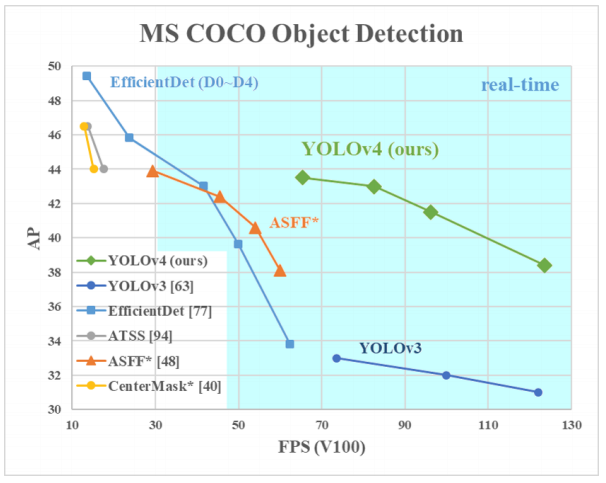
Di sini kita melihat YOLOv3-4 karena mereka adalah versi terbaru dan lebih efisien daripada yang sebelumnya.
Arsitektur dari Detektor Objek yang berbeda
Jadi, ada beberapa arsitektur jaringan neural yang dirancang untuk mendefinisikan objek. Mereka umumnya dikategorikan ke dalam "dua tingkat" seperti RCNN, RCNN cepat dan RCNN yang lebih cepat, dan "tingkat tunggal" seperti YOLO.
Jaringan neural "dua lapisan" yang tercantum di atas menggunakan apa yang disebut wilayah dalam gambar untuk menentukan apakah objek tertentu ada di wilayah itu.
Biasanya terlihat seperti ini (untuk RCNN yang lebih cepat, yang merupakan sistem dua tingkat tercepat yang terdaftar):
- Gambar / bingkai diumpankan ke input
- Bingkai dijalankan melalui CNN untuk membentuk peta fitur
- Jaringan neural terpisah menentukan wilayah dengan kemungkinan tinggi untuk menemukan objek di dalamnya
- Kemudian, menggunakan penggabungan RoI, wilayah ini dikompresi dan dimasukkan ke dalam jaringan saraf, yang menentukan kelas objek di wilayah tersebut

Tetapi jaringan saraf ini memiliki dua masalah utama: mereka tidak melihat gambaran keseluruhan, tetapi hanya pada wilayah individu, dan mereka relatif lambat.
Apa yang keren dari YOLO? Fakta bahwa arsitektur ini tidak memiliki dua masalah dari atas, dan telah berulang kali membuktikan keefektifannya.
Secara umum arsitektur YOLO pada blok pertama tidak jauh berbeda dalam hal "logika blok" dari detektor lain, yaitu gambar diumpankan ke input, kemudian dibuat peta fitur menggunakan CNN (meskipun YOLO menggunakan CNNnya sendiri yang disebut Darknet-53), kemudian peta fitur ini dianalisis dengan cara tertentu (lebih lanjut tentang ini nanti), memberikan posisi dan ukuran kotak pembatas dan kelasnya.

Tapi apa itu Neck, Dense Prediction, dan Sparse Prediction?
Kami membahas Prediksi Jarang sedikit lebih awal - ini hanya pengulangan tentang cara kerja algoritme dua tingkat: mereka mendefinisikan wilayah secara individual dan kemudian mengklasifikasikan wilayah tersebut.
Leher (atau "leher") adalah blok terpisah, yang dibuat untuk mengumpulkan informasi dari lapisan terpisah dari blok sebelumnya (seperti yang ditunjukkan pada gambar di atas) untuk meningkatkan akurasi prediksi. Jika Anda tertarik dengan ini, Anda dapat menggunakan istilah Google "Path Aggregation Network", "Spatial Attention Module" dan "Spatial Pyramid Pooling".
Dan terakhir, yang membedakan YOLO dari semua arsitektur lainnya adalah blok yang disebut (dalam gambar kami di atas) Prediksi Padat. Kami akan lebih fokus padanya, karena ini adalah solusi yang sangat menarik, yang memungkinkan YOLO untuk menjadi pemimpin dalam efisiensi deteksi objek.
YOLO (You Only Look Once) membawa filosofi melihat gambar sekali, dan untuk yang satu ini melihat (yaitu, menjalankan gambar melalui satu jaringan saraf) untuk membuat semua definisi objek yang diperlukan. Bagaimana ini bisa terjadi?
Jadi, pada keluaran dari pekerjaan YOLO, kita biasanya menginginkan ini:
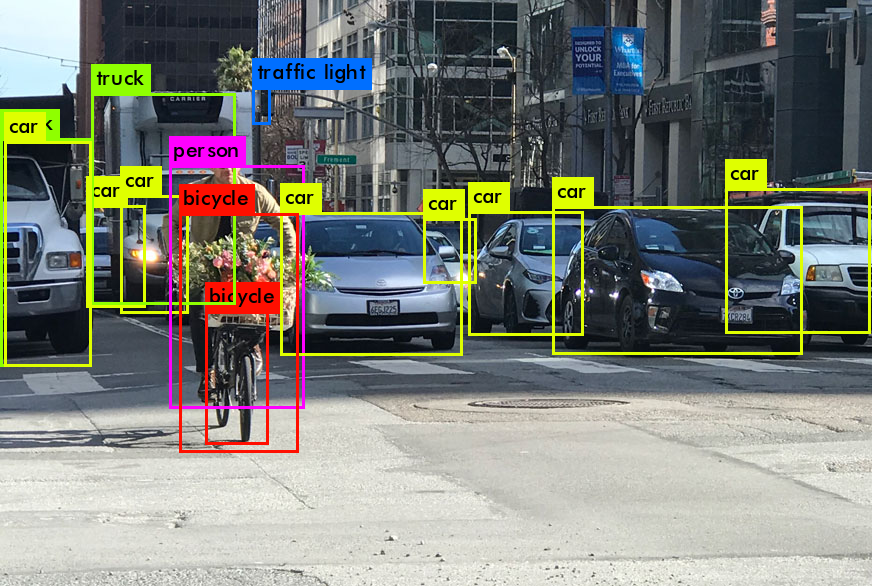
Apa yang dilakukan YOLO saat belajar dari data (dengan kata sederhana):
Langkah 1: Biasanya, gambar akan dibentuk ulang menjadi ukuran 416x416 sebelum melatih jaringan saraf, sehingga mereka dapat diberi makan secara berkelompok (untuk mempercepat pembelajaran ).
Langkah 2: Bagilah gambar (untuk saat ini secara mental) ke dalam sel berukuran a x a . Di YOLOv3-4, biasanya membelah menjadi 13x13 sel (kita akan berbicara tentang skala yang berbeda nanti untuk membuatnya lebih jelas).

Sekarang mari kita fokus pada sel-sel ini, tempat kita membagi gambar / bingkai. Sel semacam itu, yang disebut sel kisi, berada di inti gagasan YOLO. Setiap sel adalah "jangkar" yang ditempelkan pada kotak pembatas. Artinya, beberapa persegi panjang digambar di sekitar sel untuk menentukan objek (karena tidak jelas bentuk apa yang paling cocok untuk persegi panjang, mereka digambar sekaligus dalam beberapa bentuk yang berbeda), dan posisi, lebar dan tinggi dihitung relatif terhadap pusat sel ini.
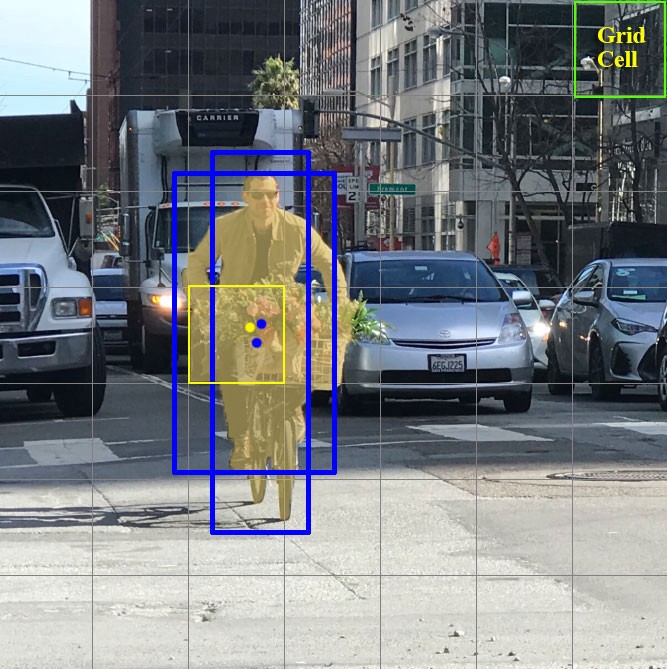
Bagaimana kotak pembatas ini digambar di sekitar kandang? Bagaimana ukuran dan posisinya ditentukan? Di sinilah teknik kotak jangkar (dalam terjemahan - kotak jangkar, atau "persegi panjang jangkar") berperan. Mereka ditetapkan di awal baik oleh pengguna sendiri, atau ukurannya ditentukan berdasarkan ukuran kotak pembatas yang ada dalam kumpulan data tempat YOLO akan melatih (pengelompokan K-means dan IoU digunakan untuk menentukan ukuran yang paling sesuai). Biasanya, ada 3 kotak jangkar berbeda yang akan digambar di sekitar (atau di dalam) satu sel:

Mengapa ini dilakukan? Ini akan menjadi jelas sekarang saat kita membahas bagaimana YOLO belajar.
Langkah 3. Gambar dari dataset dijalankan melalui jaringan saraf kita (perhatikan bahwa selain gambar dalam dataset pelatihan, kita harus memiliki posisi dan ukuran kotak pembatas nyata untuk objek di atasnya. Ini disebut "anotasi" dan sebagian besar dilakukan secara manual ).
Sekarang mari kita pikirkan tentang apa yang kita butuhkan untuk mendapatkan hasil.
Untuk setiap sel, kita perlu memahami dua hal mendasar:
- Manakah dari 3 kotak jangkar yang digambar di sekitar sangkar yang paling cocok untuk kita, dan bagaimana kita bisa sedikit mengubahnya agar pas dengan objeknya
- Benda apa yang ada di dalam kotak jangkar ini dan apakah itu ada di sana
Lalu apa yang seharusnya menjadi keluaran dari YOLO?
1. Pada keluaran untuk setiap sel, kita ingin mendapatkan:

2. Keluaran harus menyertakan parameter berikut:
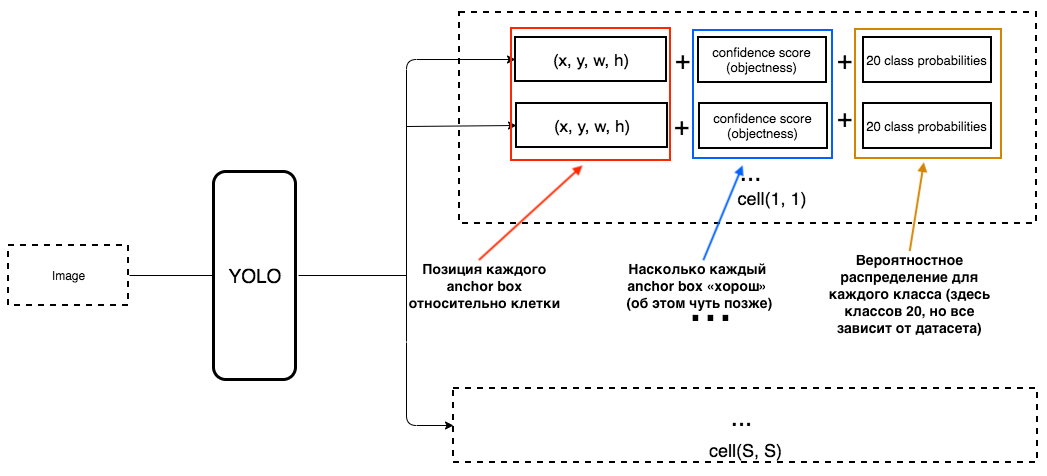
Bagaimana objek ditentukan? Faktanya, parameter ini ditentukan menggunakan metrik IoU selama pelatihan. Metrik IoU bekerja seperti ini:
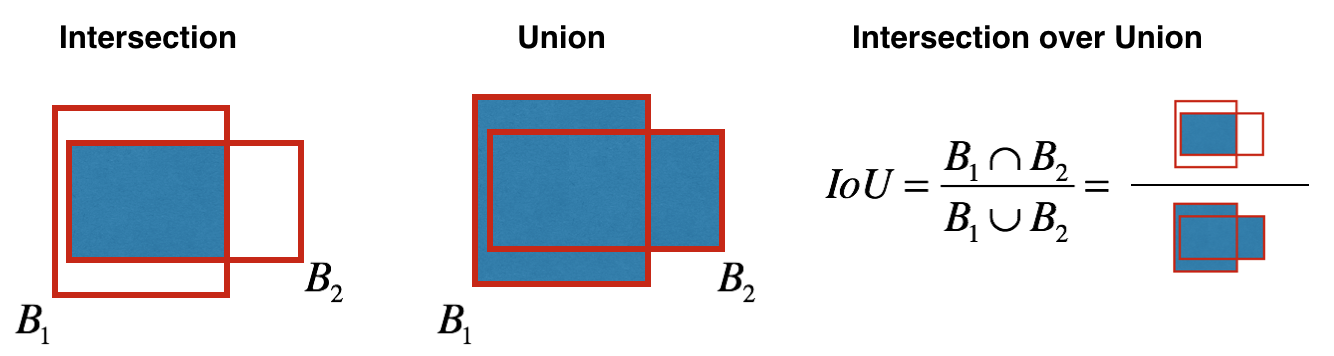
Pada awalnya, Anda dapat menetapkan ambang batas untuk metrik ini, dan jika kotak pembatas yang diprediksi berada di atas ambang batas ini, maka objeknya akan sama dengan satu, dan semua kotak pembatas lainnya dengan objek yang lebih rendah akan dikecualikan. Kita akan membutuhkan nilai objektivitas ini ketika menghitung skor keyakinan keseluruhan (sejauh mana kita yakin bahwa objek yang kita butuhkan terletak di dalam persegi panjang yang diprediksi) untuk setiap objek tertentu.
Dan sekarang kesenangan dimulai. Mari kita bayangkan bahwa kita adalah pencipta YOLO dan kita perlu melatihnya untuk mengenali orang-orang yang ada di dalam bingkai / gambar. Kami memberi makan gambar dari dataset ke YOLO, di mana ekstraksi fitur terjadi di awal, dan di akhir kami mendapatkan lapisan CNN yang memberi tahu kami tentang semua sel tempat kami "membagi" gambar kami. Dan jika lapisan ini memberi tahu kita "kebohongan" tentang sel-sel dalam gambar, maka kita harus mengalami Loss yang besar, sehingga nantinya dapat dikurangi ketika gambar-gambar berikut dimasukkan ke dalam jaringan saraf.
Untuk lebih jelasnya, ada diagram yang sangat sederhana tentang bagaimana YOLO membuat lapisan terakhir ini:
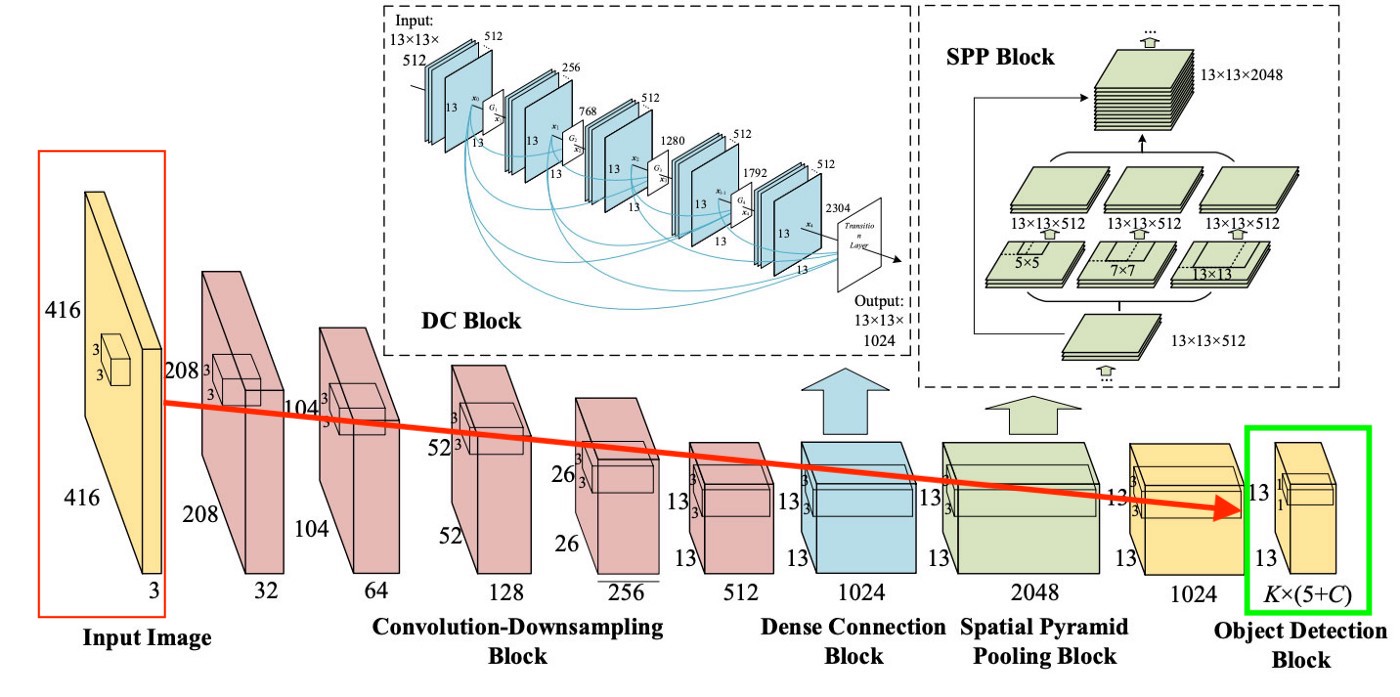
Seperti yang bisa kita lihat dari gambar, layer ini berukuran 13x13 (untuk gambar, ukuran aslinya adalah 416x416) untuk membicarakan "setiap sel" di gambar. Dari lapisan terakhir ini, informasi yang kita inginkan diperoleh.
YOLO memprediksi 5 parameter (untuk setiap kotak jangkar untuk sel tertentu):

Agar lebih mudah dipahami, ada visualisasi yang baik tentang topik ini:

Seperti yang dapat Anda pahami dari gambar ini, tugas YOLO adalah memprediksi parameter ini seakurat mungkin untuk menentukan objek dalam gambar seakurat mungkin. Dan skor keyakinan, yang ditentukan untuk setiap kotak pembatas yang diprediksi, adalah sejenis filter untuk menyaring prediksi yang sepenuhnya tidak akurat. Untuk setiap kotak pembatas yang diprediksi, kami mengalikan IoU-nya dengan probabilitas bahwa ini adalah objek tertentu (distribusi probabilitas dihitung selama pelatihan jaringan saraf), kami mengambil probabilitas terbaik dari semua kemungkinan, dan jika angka setelah perkalian melebihi ambang tertentu, maka kami dapat meninggalkan prediksi ini kotak pembatas pada gambar.
Lebih lanjut, ketika kita hanya memprediksi kotak pembatas dengan skor keyakinan tinggi, prediksi kita (jika divisualisasikan) mungkin terlihat seperti ini: Sekarang

kita dapat menggunakan teknik NMS (penekanan non-maks) untuk memfilter kotak pembatas sedemikian rupa sehingga untuk dari satu objek hanya ada satu kotak pembatas yang diprediksi.

Anda juga harus tahu bahwa YOLOv3-4 diprediksi dalam 3 skala berbeda. Artinya, gambar dibagi menjadi 64 sel grid, 256 sel dan 1024 sel agar juga dapat melihat objek kecil. Untuk setiap grup sel, algoritme mengulangi tindakan yang diperlukan selama prediksi / pembelajaran, yang dijelaskan di atas.
Banyak teknik telah digunakan di YOLOv4 untuk meningkatkan akurasi model tanpa kehilangan terlalu banyak kecepatan. Namun untuk prediksinya sendiri, Dense Prediction dibiarkan sama seperti di YOLOv3. Jika Anda tertarik dengan apa yang penulis lakukan secara ajaib untuk meningkatkan akurasi tanpa kehilangan kecepatan, ada artikel bagus yang ditulis tentang YOLOv4 .
Saya harap saya bisa menyampaikan sedikit tentang cara kerja YOLO secara umum (lebih tepatnya, dua versi terakhir, yaitu YOLOv3 dan YOLOv4), dan ini akan membangkitkan keinginan Anda untuk menggunakan model ini di masa mendatang, atau mempelajari lebih lanjut tentang cara kerjanya.
Sekarang kita telah menemukan apa yang mungkin merupakan jaringan saraf terbaik untuk Deteksi Objek (dalam hal kecepatan / kualitas), akhirnya mari beralih ke bagaimana kita dapat mengaitkan informasi tentang objek YOLO spesifik kita di antara bingkai video. Bagaimana program dapat memahami bahwa orang di bingkai sebelumnya adalah orang yang sama seperti di bingkai baru?
SORT dalam
Untuk memahami teknologi ini, Anda harus terlebih dahulu memahami beberapa aspek matematika - jarak Mahalonobis dan filter Kalman.
Jarak Mahalonobis
Mari kita lihat contoh yang sangat sederhana untuk secara intuitif memahami apa itu jarak Maholonobis dan mengapa itu diperlukan. Banyak orang mungkin tahu apa jarak Euclidean. Biasanya, ini adalah jarak dari satu titik ke titik lainnya dalam ruang Euclidean:
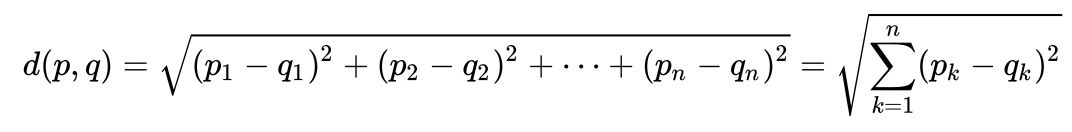

Misalkan kita memiliki dua variabel - X1 dan X2. Untuk masing-masing, kami memiliki banyak dimensi.
Sekarang, katakanlah kita memiliki 2 dimensi baru:
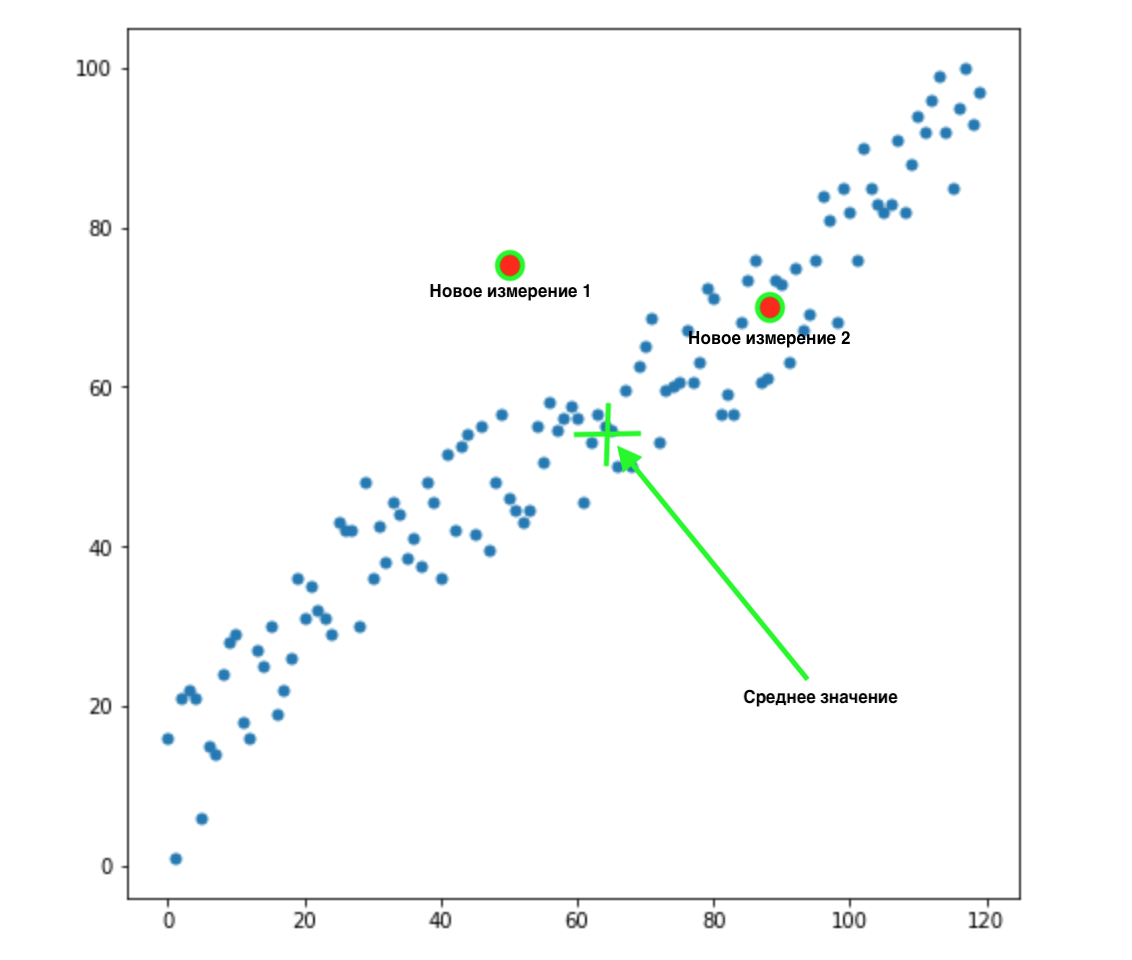
Bagaimana kita mengetahui mana dari dua nilai ini yang paling sesuai untuk distribusi kita? Semuanya jelas bagi mata - poin 2 cocok untuk kita. Tapi jarak Euclidean ke mean sama untuk kedua poin. Karenanya, jarak Euclidean sederhana ke mean tidak akan berhasil untuk kita.
Seperti yang bisa kita lihat dari gambar di atas, variabel-variabel tersebut berkorelasi satu sama lain, dan cukup kuat. Jika mereka tidak berkorelasi satu sama lain, atau berkorelasi jauh lebih sedikit, kita bisa menutup mata dan menerapkan jarak Euclidean untuk tugas-tugas tertentu, tetapi di sini kita perlu mengoreksi korelasi dan memperhitungkannya.
Jarak Mahalonobis hanya mengatasi ini. Karena biasanya ada lebih dari dua variabel dalam kumpulan data, kami akan menggunakan matriks kovariansi sebagai ganti korelasi:
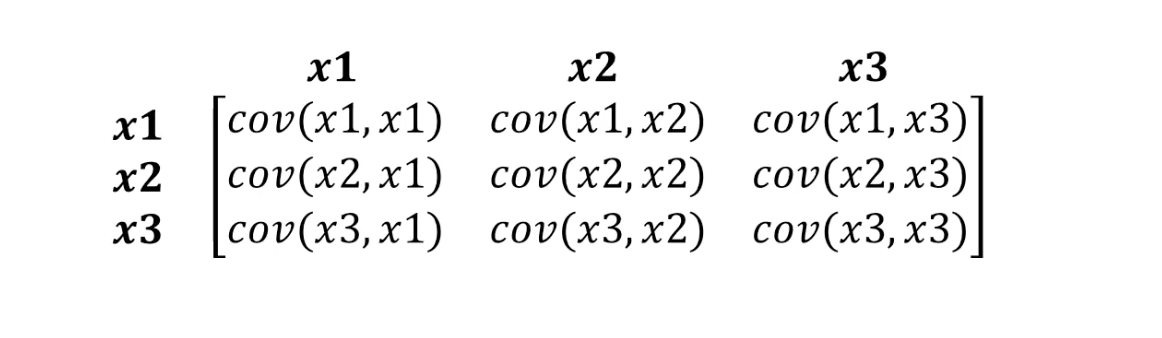
Apa sebenarnya fungsi jarak Mahalonobis:
- Singkirkan kovarian variabel
- Menjadikan varians variabel sama dengan 1
- Kemudian menggunakan jarak Euclidean biasa untuk data yang diubah.
Mari kita lihat rumus bagaimana jarak Mahalonobis dihitung:

Mari kita lihat apa arti dari komponen rumus kita:
- Perbedaan ini adalah perbedaan antara titik baru kita dan sarana untuk setiap variabel.
- S adalah matriks kovariansi yang telah kita bicarakan sebelumnya.
Hal yang sangat penting bisa dipahami dari rumusnya. Sebenarnya kita mengalikan dengan matriks kovarians terbalik. Dalam hal ini, semakin tinggi korelasi antar variabel, semakin besar kemungkinan kita akan memperpendek jaraknya, karena kita akan mengalikan dengan kebalikan dari yang lebih besar - yaitu, angka yang lebih kecil (jika dengan kata sederhana).
Kita mungkin tidak akan membahas detail aljabar linier, yang perlu kita pahami adalah bahwa kita mengukur jarak antar titik sedemikian rupa untuk memperhitungkan varians variabel kita dan kovariansi di antara keduanya.
Filter Kalman
Untuk menyadari bahwa ini adalah hal yang keren dan terbukti dapat diterapkan di banyak bidang, cukup diketahui bahwa filter Kalman digunakan pada tahun 1960-an. Ya, ya, saya mengisyaratkan ini - penerbangan ke bulan. Ini telah diterapkan di sana di beberapa tempat, termasuk bekerja dengan jalur penerbangan pulang pergi. Filter Kalman juga sering digunakan dalam analisis deret waktu di pasar keuangan, dalam analisis indikator berbagai sensor di pabrik, perusahaan, dan banyak tempat lainnya. Saya harap saya berhasil sedikit membuat Anda penasaran dan kami akan menjelaskan secara singkat filter Kalman dan cara kerjanya. Saya juga menyarankan Anda untuk membaca artikel ini di Habré jika Anda ingin mempelajarinya lebih lanjut.
Filter Kalman
, . , , .
, . 4 . , 72 .
3 :
1) (Kalman Gain):

, - ( ).
2) , ( , ), , .

3) (), :
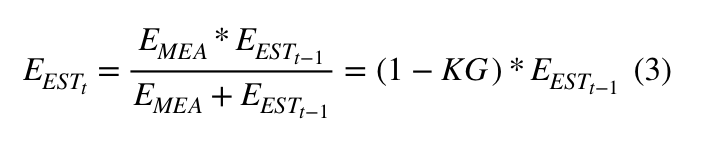
, :
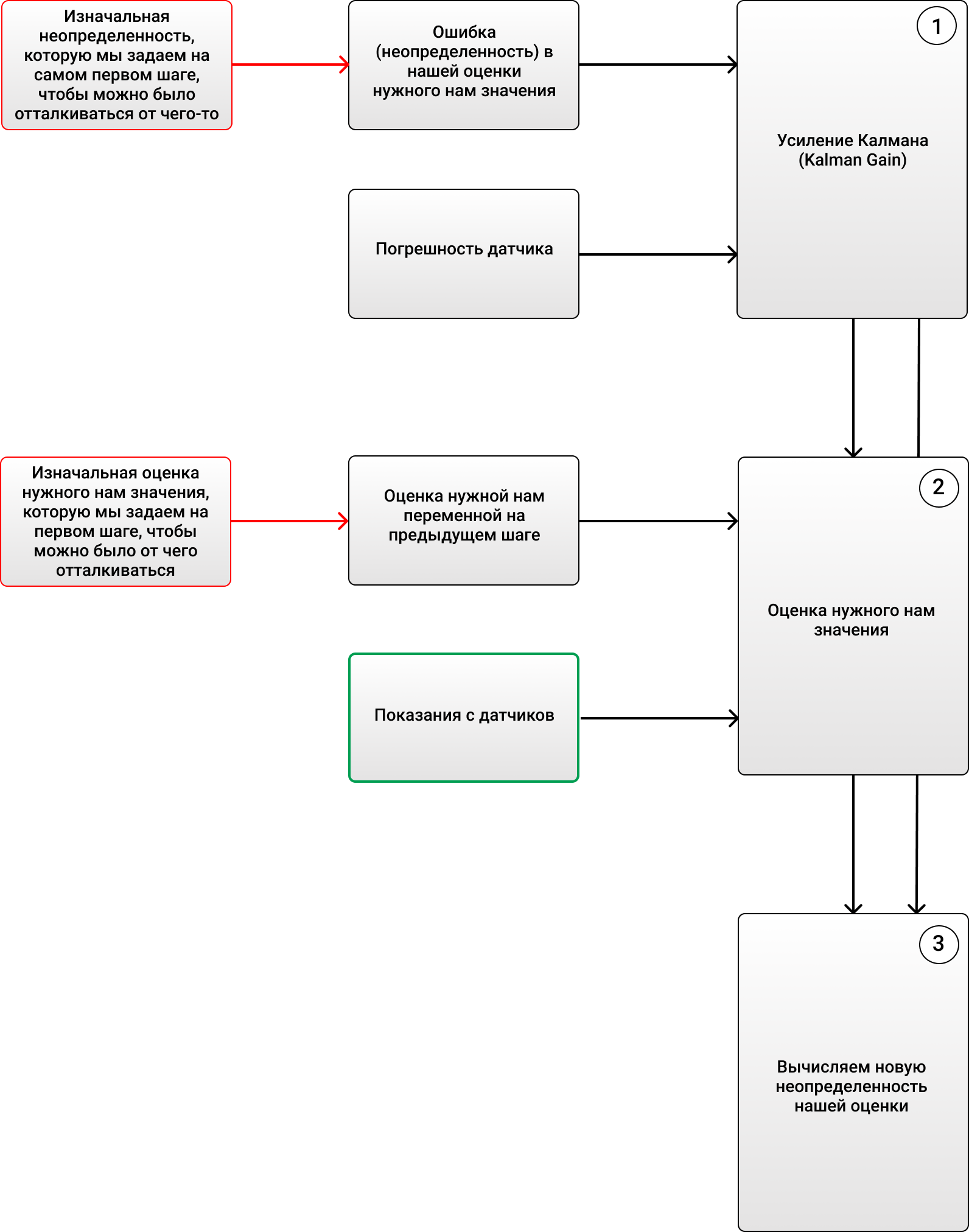
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
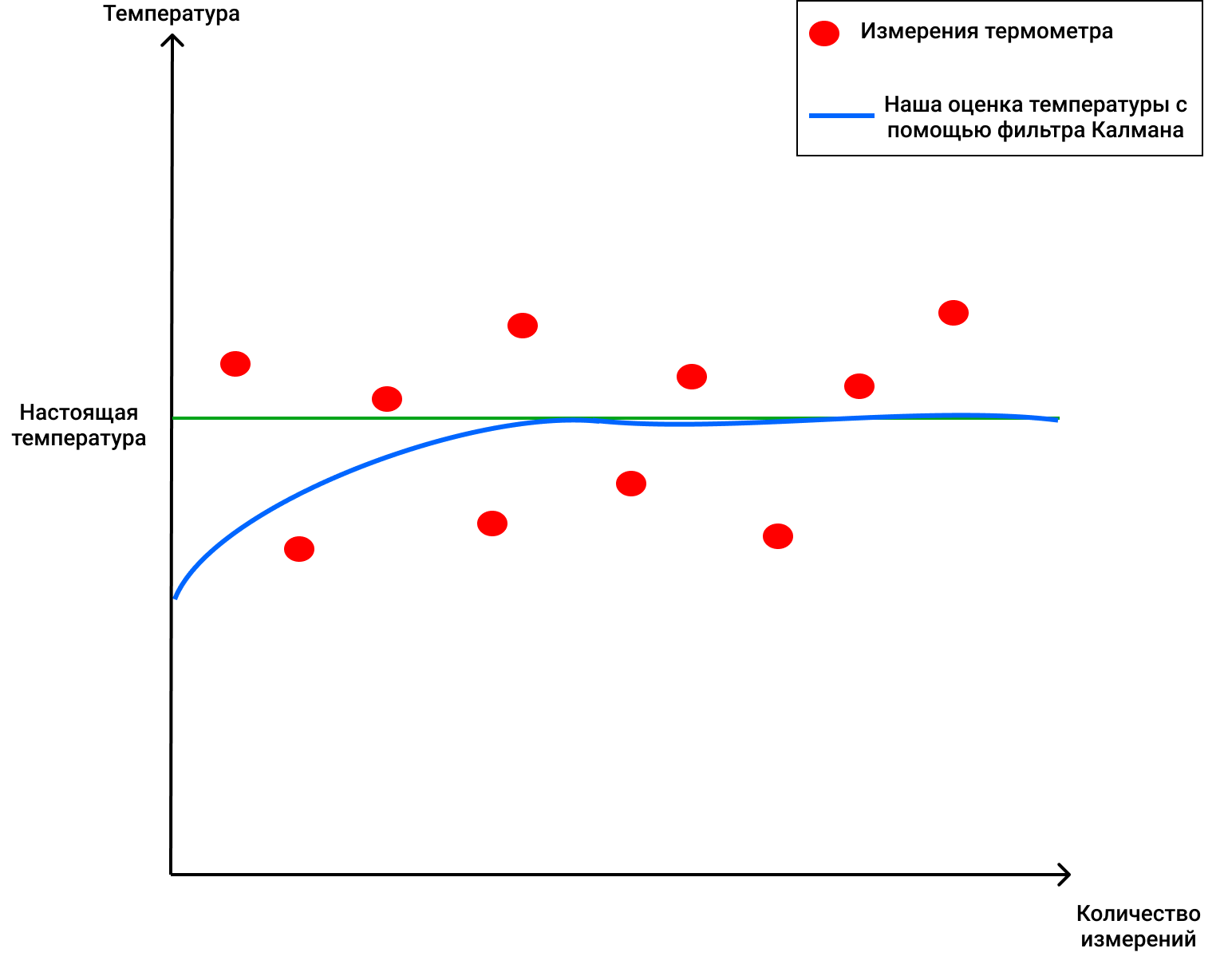
, !
, , , , , ( , ).
, . 4 . , 72 .
3 :
1) (Kalman Gain):
, - ( ).
2) , ( , ), , .
3) (), :
, :
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
, !
, , , , , ( , ).
DeepSORT - akhirnya!
Jadi, sekarang kita tahu apa itu filter Kalman dan jarak Mahalonobis. Teknologi DeepSORT hanya menghubungkan kedua konsep ini bersama-sama untuk mentransfer informasi dari satu bingkai ke bingkai lainnya, dan menambahkan metrik baru yang disebut penampilan. Pertama, dengan menggunakan deteksi objek, posisi, ukuran dan kelas dari satu kotak pembatas ditentukan. Kemudian Anda dapat, pada prinsipnya, menerapkan algoritme Hungaria untuk mengaitkan objek tertentu dengan ID objek yang sebelumnya ada di bingkai dan dilacak menggunakan filter Kalman - dan semuanya akan menjadi super, seperti di SORT asli... Tetapi teknologi DeepSORT memungkinkan untuk meningkatkan akurasi deteksi dan mengurangi jumlah peralihan antar objek, ketika, misalnya, satu orang dalam bingkai menghalangi orang lain untuk sementara, dan sekarang orang yang terhalang dianggap sebagai objek baru. Bagaimana dia melakukannya?
Dia menambahkan elemen keren ke karyanya - yang disebut "penampilan" orang-orang yang muncul dalam bingkai (penampilan). Penampilan ini dilatih oleh jaringan saraf terpisah yang dibuat oleh penulis DeepSORT. Mereka menggunakan sekitar 1.100.000 gambar dari lebih dari 1000 orang yang berbeda untuk membuat jaringan saraf memprediksi dengan benarSORT asli bermasalah - karena tampilan objek tidak digunakan di sana, pada kenyataannya, saat objek menutupi sesuatu untuk beberapa bingkai (misalnya, orang lain atau kolom di dalam gedung), algoritme kemudian menetapkan ID lain untuk orang ini - sebagai hasilnya dimana apa yang disebut "memori" dari objek dalam SORT asli berumur pendek.
Jadi, sekarang objek memiliki dua sifat - dinamika gerakan dan penampilannya. Untuk dinamika, kami memiliki indikator yang disaring dan diprediksi menggunakan filter Kalman - (u, v, a, h, u ', v', a ', h'), di mana u, v adalah posisi X dari persegi panjang yang diprediksi dan Y, a adalah rasio aspek persegi panjang yang diprediksi, h adalah tinggi persegi panjang, dan turunannya terkait dengan setiap nilai. Untuk penampilan, jaringan saraf dilatih, yang memiliki struktur:
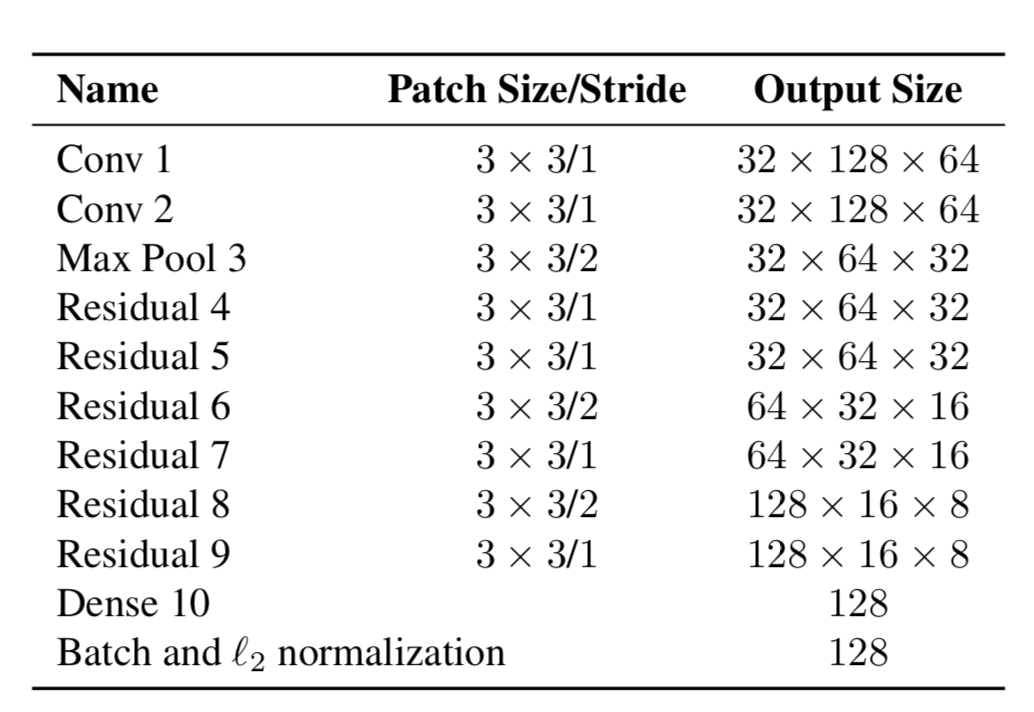
Dan pada akhirnya menghasilkan sebuah vektor fitur berukuran 128x1. Kemudian, alih-alih menghitung jarak antara objek tertentu menggunakan YOLO, dan objek yang sudah kita ikuti di frame, lalu menetapkan ID tertentu hanya dengan menggunakan jarak Mahalonobis, penulis membuat metrik baru untuk menghitung jarak, yang meliputi kedua prediksi menggunakan filter Kalman, dan "jarak kosinus", sebagaimana disebut sebaliknya, koefisien Otiai.
Hasilnya, jarak dari objek YOLO tertentu ke objek yang diprediksi oleh filter Kalman (atau objek yang sudah ada di antara objek yang diamati pada frame sebelumnya) adalah:

Dimana Da adalah jarak kemiripan eksternal dan Dk adalah jarak Mahalonobis. Lebih lanjut, jarak hybrid ini digunakan dalam algoritma Hungaria untuk mengurutkan objek tertentu dengan benar dengan ID yang ada.
Dengan demikian, metrik tambahan sederhana Da membantu membuat algoritme DeepSORT baru yang elegan yang digunakan dalam banyak masalah dan cukup populer dalam masalah Pelacakan Objek.
Artikel itu ternyata cukup berbobot, terima kasih kepada mereka yang membaca sampai akhir! Saya harap saya dapat memberi tahu Anda sesuatu yang baru dan membantu Anda memahami cara kerja Pelacakan Objek di YOLO dan DeepSORT.