Oleh karena itu, di dalam setiap proses terpisah tidak ada masalah tradisional "aneh" dengan eksekusi kode paralel, kunci, kondisi balapan , ... Dan pengembangan DBMS itu sendiri menyenangkan dan sederhana.
Tetapi kesederhanaan yang sama memberikan batasan yang signifikan. Karena hanya ada satu thread pekerja di dalam proses, maka ia tidak dapat menggunakan lebih dari satu inti CPU untuk menjalankan permintaan - yang berarti bahwa kecepatan server secara langsung bergantung pada frekuensi dan arsitektur inti terpisah.
Di zaman kita yang berakhir dengan "perlombaan megahertz" dan sistem multicore dan multiprosesor yang berjaya, perilaku seperti itu adalah kemewahan dan pemborosan yang tidak dapat diterima. Oleh karena itu, dimulai dengan PostgreSQL 9.6, saat memproses kueri, beberapa operasi dapat dilakukan oleh beberapa proses secara bersamaan.
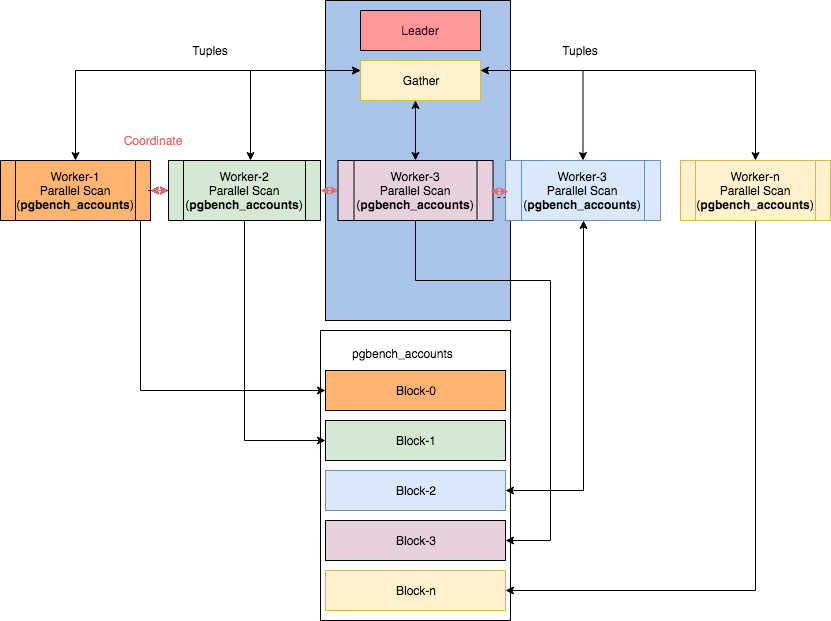
Anda dapat mengenal skema operasi beberapa node paralel di artikel "Parallelism in PostgreSQL" oleh Ibrar Ahmed, di mana gambar ini diambil.Namun, dalam kasus ini menjadi… tidak sepele untuk membaca rencana.
Secara singkat, kronologi implementasi eksekusi paralel dari operasi rencana terlihat seperti ini:
- 9.6 - fungsionalitas dasar: Seq Scan , Join, Agregat
- 10 - Pemindaian Indeks (untuk btree), Pemindaian Heap Bitmap, Gabung Hash, Gabung Gabung, Pemindaian Subquery
- 11 - operasi grup : Hash Bergabung dengan tabel hash bersama, Tambahkan (UNION)
- 12 - statistik dasar per pekerja pada node rencana
- 13 - statistik rinci per pekerja
Oleh karena itu, jika Anda menggunakan salah satu versi PostgreSQL terbaru, kemungkinan melihatnya di paket
Parallel ...sangat tinggi. Dan bersamanya mereka datang dan ...
Keanehan seiring waktu
Mari kita ambil rencana dari PostgreSQL 9.6 :
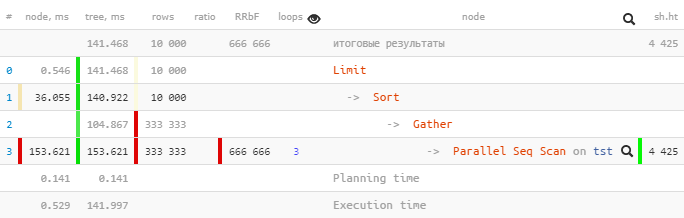
[lihat menjelaskan.tensor.ru]
Hanya satu yang
Parallel Seq Scandieksekusi 153.621 md dalam subpohon, dan Gatherbersama-sama dengan semua subnode - hanya 104.867 md.
Bagaimana? Apakah total waktu "di atas" menjadi lebih sedikit? ..
Mari kita lihat
Gather-node lebih detail:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2memberi tahu kita bahwa selain proses utama di bawah pohon, 2 proses tambahan lagi terlibat - total 3. Oleh karena itu, semua yang terjadi di dalam Gathersubpohon adalah kreativitas total dari ketiga proses sekaligus.
Sekarang mari kita lihat apa yang ada di sana
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425Aha!
loops=3Merupakan ringkasan dari semua 3 proses. Dan, rata-rata, setiap siklus tersebut memakan waktu 51.207ms. Artinya, server memerlukan 51.207 x 3 = 153.621milidetik waktu prosesor untuk menyelesaikan node ini . Artinya, jika kita ingin memahami "apa yang dilakukan server" - nomor ini akan membantu kita memahami.
Perhatikan bahwa untuk memahami waktu eksekusi "sebenarnya" , Anda perlu membagi total waktu dengan jumlah pekerja - yaitu [actual time] x [loops] / [Workers Launched].
Dalam contoh kami, setiap pekerja hanya melakukan satu siklus melalui node, oleh karena itu
153.621 / 3 = 51.207. Dan ya, sekarang tidak ada yang aneh bahwa satu-satunya Gatherproses kepala diselesaikan dalam "seolah-olah, dalam waktu yang lebih singkat."
Total: lihat menjelaskan.tensor.ru total (untuk semua proses) waktu node untuk memahami jenis beban apa yang disibukkan oleh server Anda, dan untuk mengoptimalkan bagian mana dari kueri yang layak menghabiskan waktu.
Dalam hal ini, perilaku dari menjelaskan.depesz.com yang sama , yang menunjukkan waktu "rata-rata sebenarnya" sekaligus, terlihat kurang berguna untuk tujuan debugging:
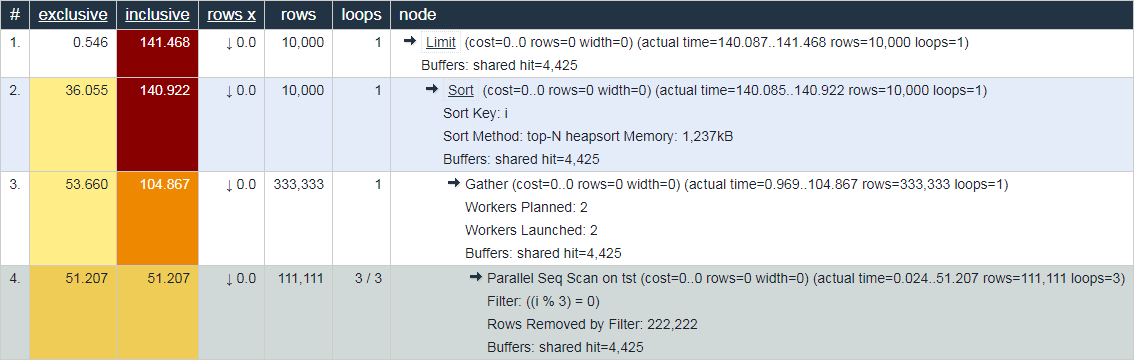
Tidak setuju? Selamat datang di komentar!
Gather Merge kehilangan segalanya
Sekarang mari kita jalankan kueri yang sama pada versi PostgreSQL 10 :
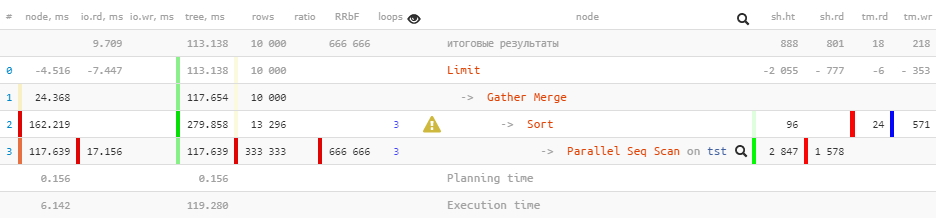
[lihat menjelaskan.tensor.ru]
Perhatikan bahwa
Gathersekarang kita memiliki node, bukan node dalam rencana Gather Merge. Inilah yang dikatakan manual tentang ini :
Ketika sebuah node berada di atas bagian paralel dari rencanaGather Merge, bukanGather, itu berarti bahwa semua proses yang mengeksekusi bagian dari rencana paralel mengeluarkan tupel dalam urutan yang diurutkan, dan bahwa proses utama melakukan penggabungan pemelihara pesanan. NodeGather, di sisi lain, menerima tupel dari proses bawahan dalam urutan arbitrer yang sesuai untuknya, melanggar urutan yang mungkin ada.
Tapi tidak semuanya baik-baik saja di kerajaan Denmark:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156Saat meneruskan atribut
Buffersdan I/O Timingske atas pohon, beberapa data hilang sebelum waktunya . Kami dapat memperkirakan ukuran kerugian ini hanya sekitar 2/3 , yang dibentuk oleh proses tambahan.
Sayangnya, dalam rencana itu sendiri, tidak ada tempat untuk mendapatkan informasi ini - oleh karena itu "minus" pada simpul di atasnya. Dan jika Anda melihat evolusi lebih lanjut dari rencana ini di PostgreSQL 12 , maka itu tidak berubah secara mendasar, kecuali bahwa beberapa statistik ditambahkan untuk setiap pekerja di
Sort-node:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 msTotal: jangan percaya pada data node di atas
Gather Merge.