
Ketika saya memulai karir saya sebagai pengembang, pekerjaan pertama saya adalah DBA (administrator database, DBA). Pada tahun-tahun tersebut, bahkan sebelum AWS RDS, Azure, Google Cloud, dan layanan cloud lainnya, ada dua jenis DBA:
- , . « », , .
- : , , SQL. ETL- . , .
DBA aplikasi biasanya menjadi bagian dari tim pengembangan. Mereka memiliki pengetahuan yang mendalam tentang topik tertentu, sehingga mereka biasanya hanya mengerjakan satu atau dua proyek. Infrastruktur DBA biasanya merupakan bagian dari tim TI dan dapat mengerjakan banyak proyek secara bersamaan.
Saya adalah admin database aplikasi
Saya tidak pernah memiliki keinginan untuk bermain-main dengan cadangan atau penyimpanan tweak (saya yakin itu menyenangkan!). Sampai hari ini, saya suka mengatakan bahwa saya adalah admin DB yang tahu cara mengembangkan aplikasi, bukan pengembang yang mengerti database.
Pada artikel ini, saya akan membagikan beberapa tip pengembangan database yang telah saya pelajari selama karir saya.
Kandungan:
- Perbarui hanya yang perlu diperbarui
- Nonaktifkan kendala dan indeks untuk beban berat
- Gunakan tabel UNLOGGED untuk data perantara
- Menerapkan Seluruh Proses dengan WITH dan RETURNING
- Hindari indeks di kolom dengan selektivitas rendah
- Gunakan indeks parsial
- Selalu muat data yang diurutkan
- Indeks kolom berkorelasi tinggi dengan BRIN
- Jadikan indeks "tidak terlihat"
- Jangan jadwalkan proses yang panjang untuk dimulai pada awal jam berapa pun
- Kesimpulan
Perbarui hanya yang perlu diperbarui
Operasi ini
UPDATEmenghabiskan banyak sumber daya. Cara terbaik untuk mempercepatnya adalah dengan memperbarui hanya yang perlu diperbarui.
Berikut adalah contoh permintaan untuk menormalkan kolom email:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
Tampak tidak bersalah, bukan? Permintaan tersebut memperbarui alamat email untuk 1.010.000 pengguna. Tetapi apakah semua baris perlu diperbarui?
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
Hanya 10.000 baris yang perlu diperbarui. Dengan mengurangi jumlah data yang diproses, kami telah mengurangi waktu eksekusi dari 1,5 detik menjadi kurang dari 300 ms. Ini juga akan menghemat upaya kami lebih lanjut dalam memelihara database.
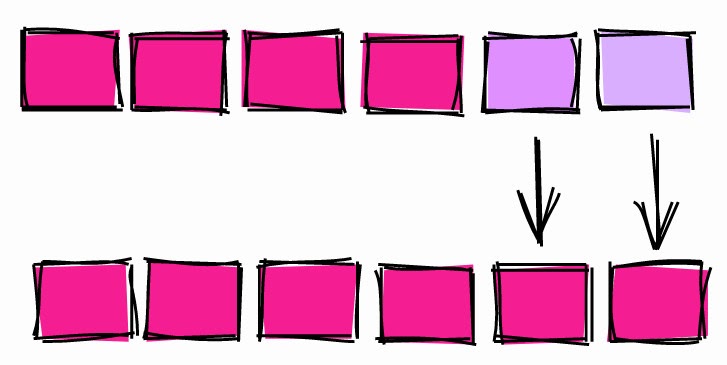
Perbarui hanya yang perlu diperbarui.
Jenis pembaruan besar ini sangat umum dalam skrip migrasi data. Lain kali Anda menulis skrip seperti ini, pastikan untuk memperbarui hanya yang diperlukan.
Nonaktifkan kendala dan indeks untuk beban berat
Batasan adalah bagian penting dari database relasional: mereka menjaga konsistensi dan keandalan data. Tetapi semuanya memiliki harganya sendiri, dan lebih sering daripada tidak, Anda harus membayar saat memuat atau memperbarui sejumlah besar baris.
Mari tentukan skema penyimpanan kecil:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
Ini mendefinisikan berbagai jenis batasan seperti "bukan null" serta batasan unik ...
Untuk menyetel titik awal, mari mulai menambahkan
salekunci asing ke tabel
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
Setelah menentukan batasan dan indeks, memuat satu juta baris ke dalam tabel membutuhkan waktu sekitar 15,4 detik.
Sekarang, pertama, mari muat data ke dalam tabel, dan baru kemudian tambahkan batasan dan indeks:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
Memuat lebih cepat, 2,27 detik. bukan 15.4. Indeks dan batasan dibuat lebih lama setelah memuat data, tetapi keseluruhan proses jauh lebih cepat: 3,1 dtk. bukannya 15,4.
Sayangnya, di PostgreSQL Anda tidak dapat melakukan hal yang sama dengan indeks, Anda hanya dapat membuangnya dan membuatnya kembali. Di database lain, seperti Oracle, Anda dapat menonaktifkan dan mengaktifkan indeks tanpa membangun kembali.
UNLOGGED-
Saat Anda mengubah data di PostgreSQL, perubahan tersebut ditulis ke log depan tulis (WAL ). Ini digunakan untuk menjaga konsistensi, mengindeks ulang dengan cepat selama pemulihan, dan mempertahankan replikasi.
Menulis ke WAL sering kali diperlukan, tetapi ada beberapa situasi di mana Anda dapat memilih keluar dari WAL untuk mempercepat. Misalnya, dalam kasus tabel perantara.
Tabel perantara disebut tabel satu kali, yang menyimpan data sementara yang digunakan untuk mengimplementasikan beberapa proses. Misalnya, dalam proses ETL, sangat umum untuk memuat data dari file CSV ke dalam tabel pementasan, menghapus informasi, dan kemudian memuatnya ke dalam tabel target. Dalam skenario ini, tabel pementasan adalah sekali pakai dan tidak digunakan di cadangan atau replika.
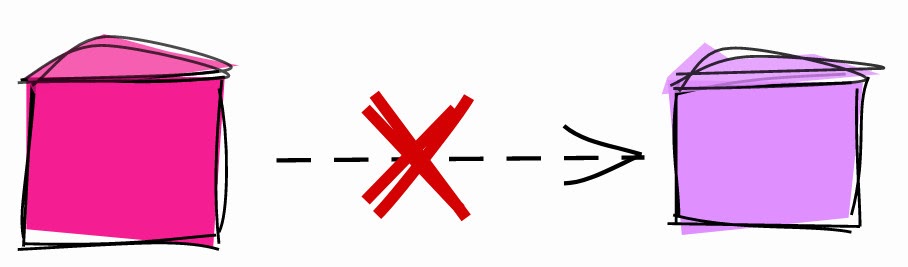
Tabel UNLOGGED.
Tabel pementasan yang tidak perlu dipulihkan jika terjadi kegagalan dan tidak diperlukan dalam replika dapat disetel sebagai UNLOGGED :
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
Perhatian : Sebelum menggunakan
UNLOGGED, pastikan Anda memahami semua implikasinya.
Menerapkan Seluruh Proses dengan WITH dan RETURNING
Misalkan Anda memiliki tabel users dan Anda menemukan tabel itu berisi data duplikat:
Table setup
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
Pengguna haki benita mendaftar dua kali, dengan surat
ME@hakibenita.comdan me@hakibenita.com. Karena kami tidak menormalkan alamat email saat memasukkannya ke dalam tabel, sekarang kami harus menangani duplikat.
Kita butuh:
- Identifikasi alamat duplikat dalam huruf kecil dan tautkan pengguna duplikat satu sama lain.
- Perbarui pesanan sehingga hanya merujuk ke salah satu duplikat.
- Hapus duplikat dari tabel.
Anda dapat menautkan pengguna duplikat menggunakan tabel pementasan:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
Tabel perantara berisi tautan di antara pengambilan. Jika pengguna dengan alamat email yang dinormalisasi muncul lebih dari sekali, kami memberinya ID pengguna minimum, tempat kami menciutkan semua duplikat. Pengguna lainnya disimpan dalam kolom array dan semua tautan ke mereka akan diperbarui.
Dengan menggunakan tabel perantara, kami memperbarui tautan menjadi duplikat di tabel
orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
Sekarang Anda dapat dengan aman menghapus duplikat dari
users:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
Perhatikan bahwa kami menggunakan fungsi tak terestimasi untuk "mengubah" larik , yang mengubah setiap elemen menjadi string.
Hasil:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
Bagus, semua instance pengguna
3( ME@hakibenita.com) dikonversi ke pengguna 2( me@hakibenita.com).
Kami juga dapat memeriksa bahwa duplikat dihapus dari tabel
users:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
Sekarang kita bisa menyingkirkan tabel pementasan:
db=# DROP TABLE duplicate_users;
DROP TABLE
Tidak apa-apa, tapi butuh waktu lama dan perlu dibersihkan! Apakah ada cara yang lebih baik?
Ekspresi Tabel Umum (CTE)
Dengan ekspresi tabel umum , juga dikenal sebagai ekspresi
WITH, kita dapat menjalankan seluruh prosedur dengan ekspresi SQL tunggal:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
Alih-alih tabel pementasan, kami membuat ekspresi tabel umum dan menggunakannya kembali.
Menampilkan hasil dari CTE
Salah satu keuntungan dari menjalankan DML dalam ekspresi
WITHadalah Anda dapat mengembalikan data darinya menggunakan kata kunci RETURNING . Katakanlah kita membutuhkan laporan tentang jumlah baris yang diperbarui dan dihapus:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
Hasil:
orders_updated | users_deleted
----------------+---------------
2 | 1
Keunggulan dari pendekatan ini adalah bahwa seluruh proses dijalankan dalam satu perintah, jadi tidak perlu mengelola transaksi atau khawatir tentang membersihkan tabel pementasan jika terjadi kegagalan proses.
Peringatan : Seorang pembaca Reddit menunjukkan kepada saya kemungkinan perilaku eksekusi DML yang tidak dapat diprediksi dalam ekspresi tabel umum :
Sub-ekspresi dalamWITHdieksekusi secara bersamaan satu sama lain dan dengan kueri utama. Oleh karena itu, ketika digunakan dalamWITHekspresi pengubah data, urutan pembaruan sebenarnya tidak dapat diprediksi.
Ini berarti Anda tidak dapat mengandalkan urutan eksekusi subekspresi independen. Ternyata jika ada ketergantungan di antara keduanya, seperti pada contoh di atas, Anda bisa mengandalkan eksekusi subekspresi dependen sebelum menggunakannya.
Hindari indeks di kolom dengan selektivitas rendah
Misalkan Anda memiliki proses pendaftaran di mana pengguna login di alamat email. Untuk mengaktifkan akun Anda, Anda perlu memverifikasi email Anda. Tabelnya mungkin terlihat seperti ini:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
Sebagian besar pengguna Anda sadar akan warga negara, mereka mendaftar dengan alamat surat yang benar dan segera mengaktifkan akun. Mari isi tabel dengan data pengguna, dan asumsikan bahwa 90% pengguna diaktifkan:
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
Untuk menanyakan jumlah pengguna yang diaktifkan dan tidak diaktifkan, Anda dapat membuat indeks menurut kolom
activated:
db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
Dan jika Anda menanyakan jumlah pengguna yang tidak diaktifkan , basis akan menggunakan indeks:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
Pangkalan memutuskan bahwa filter akan mengembalikan 102.567 item, kira-kira 10% dari tabel. Ini konsisten dengan data yang kami muat, jadi tabel berfungsi dengan baik.
Namun, jika kami menanyakan jumlah pengguna yang diaktifkan , kami menemukan bahwa database telah memutuskan untuk tidak menggunakan indeks :
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
Banyak developer yang bingung ketika database tidak menggunakan index. Untuk menjelaskan mengapa melakukan ini, berikut ini: jika Anda perlu membaca seluruh tabel, apakah Anda akan menggunakan indeks ?
Mungkin tidak, mengapa ini perlu? Membaca dari disk itu mahal, jadi sebaiknya Anda membaca sesedikit mungkin. Misalnya, jika tabel berukuran 10 MB dan indeksnya 1 MB, maka untuk membaca seluruh tabel, Anda harus membaca 10 MB dari disk. Dan jika Anda menambahkan indeks, Anda mendapatkan 11 MB. Itu boros.
Sekarang mari kita lihat statistik yang dikumpulkan PostgreSQL di tabel kita:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
Ketika PostgreSQL mengurai tabel, ditemukan bahwa
activatedada dua nilai berbeda di kolom tersebut . Nilai tdi kolom most_common_valssesuai dengan frekuensi 0.89743334di kolom most_common_freqs, dan nilai fsesuai dengan frekuensi 0.10256667. Setelah menganalisis tabel, database menentukan bahwa 89,74% dari catatan adalah pengguna aktif dan 10,26% sisanya tidak diaktifkan.
Berdasarkan statistik ini, PostgreSQL memutuskan bahwa lebih baik memindai seluruh tabel daripada berasumsi bahwa 90% baris memenuhi ketentuan. Ambang batas di mana basis dapat memutuskan apakah akan menggunakan indeks bergantung pada banyak faktor, dan tidak ada aturan praktis.
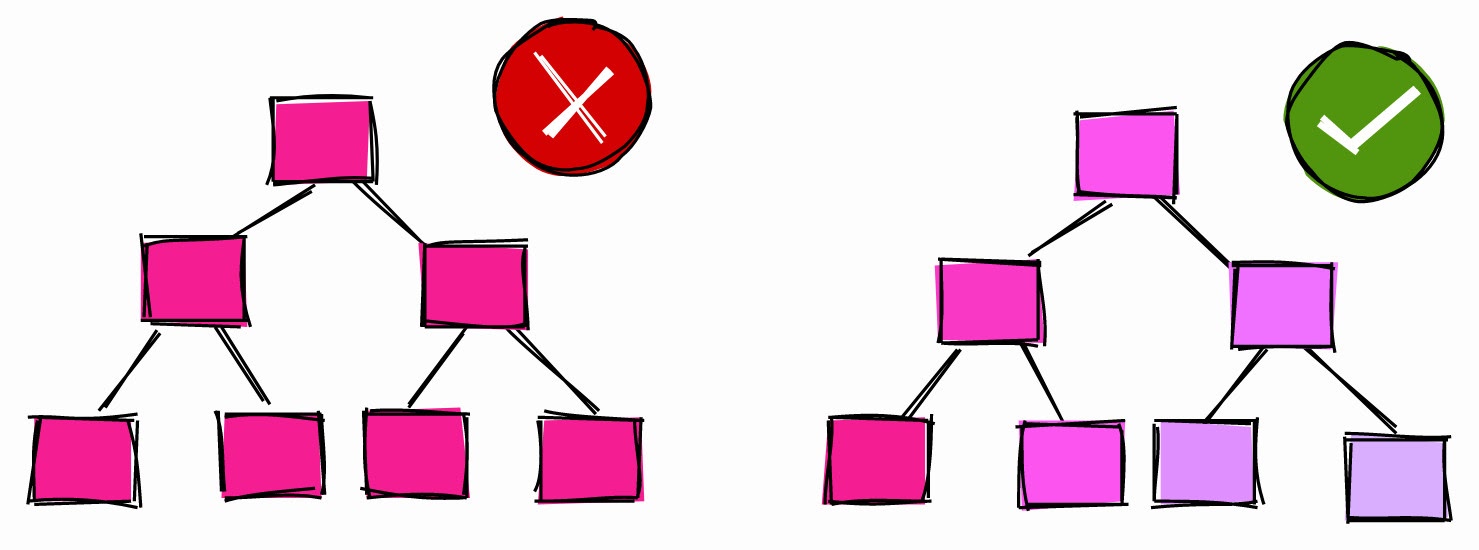
Indeks untuk kolom dengan selektivitas rendah dan tinggi.
Gunakan indeks parsial
Pada bab sebelumnya, kami membuat indeks pada kolom boolean di mana sekitar 90% record adalah
true(pengguna yang diaktifkan).
Saat kami menanyakan jumlah pengguna aktif, database tidak menggunakan indeks. Dan ketika ditanya jumlah non-aktif, database menggunakan indeks.
Timbul pertanyaan: jika database tidak akan menggunakan indeks untuk menyaring pengguna aktif, mengapa kita mengindeks mereka di tempat pertama?
Sebelum menjawab pertanyaan ini, mari kita lihat bobot indeks lengkap per kolom
activated:
db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
Indeks tersebut berbobot 21 MB. Hanya untuk referensi: tabel dengan pengguna adalah 65 MB. Artinya, bobot indeks ~ 32% dari bobot dasar. Karena itu, kami tahu bahwa ~ 90% konten indeks kemungkinan tidak akan digunakan.
Di PostgreSQL, Anda dapat membuat indeks hanya pada sebagian tabel - yang disebut indeks parsial :
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
Kami menggunakan ekspresi
WHEREuntuk membatasi string yang dicakup oleh indeks. Mari kita periksa apakah itu berhasil:
db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
Hebat, database ternyata cukup pintar untuk menyadari bahwa ekspresi Boolean yang kami gunakan dalam kueri mungkin berfungsi untuk indeks parsial.
Pendekatan ini memiliki keuntungan lain:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
Indeks kolom penuh berbobot 21 MB, dan indeks parsial hanya 2,2 MB. Itu adalah 10%, yang sesuai dengan proporsi pengguna yang tidak diaktifkan di tabel.
Selalu muat data yang diurutkan
Ini adalah salah satu komentar saya yang paling sering ketika mengurai kode. Nasihatnya tidak seintuitif yang lain dan dapat berdampak besar pada produktivitas.
Misalkan Anda memiliki meja besar dengan penjualan khusus:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
Setiap malam selama proses ETL, Anda memuat data ke dalam tabel:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Untuk mensimulasikan unduhan, kami menggunakan data acak. Kami memasukkan 100 ribu baris dengan nama acak, dan tanggal penjualan untuk periode dari 1 Januari 2020 dan dua tahun ke depan.
Untuk sebagian besar, tabel digunakan untuk ringkasan laporan penjualan. Paling sering, mereka memfilter berdasarkan tanggal untuk melihat penjualan untuk periode tertentu. Untuk mempercepat pemindaian rentang, mari buat indeks dengan
sold_at:
db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
Mari kita lihat rencana eksekusi untuk permintaan mengambil semua penjualan pada Juni 2020:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
Setelah menjalankan permintaan beberapa kali untuk memanaskan cache, waktu eksekusi menjadi stabil pada level 6 ms.
Pemindaian Bitmap
Dalam hal eksekusi, kami melihat bahwa basis menggunakan pemindaian bitmap. Itu terjadi dalam dua tahap:
(Bitmap Index Scan): basis menelusuri seluruh indekssale_fact_sold_at_ixdan menemukan semua halaman dalam tabel yang berisi baris yang relevan.(Bitmap Heap Scan): basis membaca halaman yang berisi string relevan dan menemukan halaman yang memenuhi ketentuan.
Halaman bisa berisi banyak baris. Pada langkah pertama, indeks digunakan untuk mencari halaman . Tahap kedua mencari baris di halaman, maka operasi
Recheck Conddalam rencana eksekusi mengikuti .
Pada titik ini, banyak DBA dan pengembang akan membulatkan dan melanjutkan ke kueri berikutnya. Namun ada cara untuk meningkatkan kueri ini.
Indeks Scan
Mari buat sedikit perubahan pada pemuatan data.
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
Kali ini kami memuat data yang diurutkan berdasarkan
sold_at.
Sekarang rencana eksekusi untuk kueri yang sama terlihat seperti ini:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
Setelah beberapa kali berjalan, waktu eksekusi menjadi stabil di 2,3ms. Kami telah mencapai penghematan berkelanjutan sekitar 60%.
Kami juga melihat bahwa kali ini database tidak menggunakan pemindaian bitmap, tetapi menerapkan pemindaian indeks "normal". Mengapa?
Korelasi
Saat database menganalisis tabel, ia mengumpulkan semua statistik yang didapatnya. Salah satu parameternya adalah korelasi :
Korelasi statistik antara urutan fisik baris dan urutan nilai logis dalam kolom. Jika nilainya sekitar -1 atau +1, pemindaian indeks pada kolom dianggap lebih menguntungkan daripada jika nilai korelasinya sekitar 0, karena jumlah akses disk acak berkurang.
Sebagaimana dijelaskan dalam dokumentasi resmi, korelasi adalah ukuran bagaimana nilai-nilai dalam kolom tertentu pada disk diurutkan.
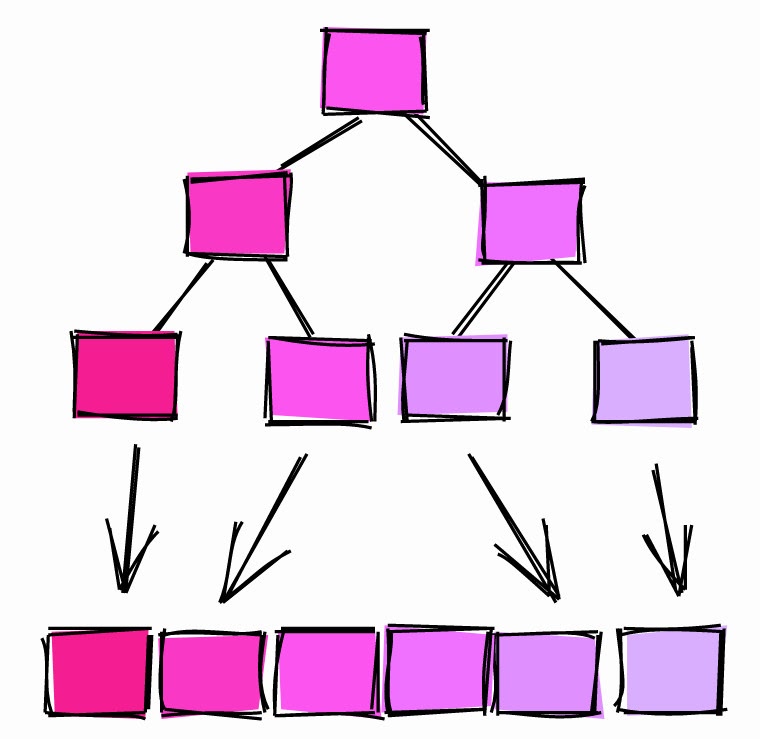
Korelasi = 1.
Jika korelasinya 1 atau lebih, itu berarti halaman disimpan pada disk dengan urutan yang kurang lebih sama seperti baris pada tabel. Ini sangat umum. Misalnya, ID auto-incrementing cenderung memiliki korelasi dekat dengan 1. Kolom tanggal dan timestamp yang menunjukkan kapan baris dibuat juga memiliki korelasi yang mendekati 1.
Jika korelasinya -1, halaman diurutkan dalam urutan kolom yang terbalik.
Korelasi ~ 0.
Jika korelasi mendekati 0, itu berarti nilai-nilai pada kolom tidak berkorelasi atau hampir tidak berkorelasi dengan urutan halaman pada tabel.
Ayo kembali ke
sale_fact. Saat kami memuat data ke dalam tabel tanpa pra-pengurutan, korelasinya seperti ini:
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
ID kolom yang dibuat secara otomatis memiliki korelasi 1. Kolom memiliki
sold_atkorelasi yang sangat rendah: nilai berurutan tersebar di seluruh tabel.
Saat kami memuat data yang diurutkan ke dalam tabel, dia menghitung korelasi:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
Korelasinya sekarang
sold_atsama 1.
Jadi mengapa basis menggunakan pemindaian bitmap ketika korelasinya rendah, tetapi pemindaian indeks ketika korelasinya tinggi?
- Ketika korelasinya adalah 1, basis menentukan bahwa baris dari rentang yang diminta kemungkinan besar berada di halaman yang berurutan. Kemudian pemindaian indeks lebih baik untuk membaca banyak halaman.
- Ketika korelasinya mendekati 0, basis menentukan bahwa baris dari rentang yang diminta kemungkinan besar tersebar di seluruh tabel. Kemudian disarankan untuk menggunakan pemindaian bitmap dari halaman-halaman yang berisi baris-baris yang diperlukan, dan baru kemudian mengekstraknya menggunakan kondisi tersebut.
Lain kali Anda memuat data ke dalam tabel, pikirkan tentang berapa banyak informasi yang akan diminta dan urutkan sehingga indeks dapat memindai rentang dengan cepat.
Perintah CLUSTER
Cara lain untuk "mengurutkan tabel pada disk" menurut indeks tertentu adalah dengan menggunakan perintah CLUSTER .
Misalnya:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
Kami memuat data ke dalam tabel dalam urutan acak, sehingga korelasinya
sold_atmendekati nol.
Untuk "menyusun ulang" tabel
sold_at, kami menggunakan perintah CLUSTERuntuk mengurutkan tabel pada disk sesuai dengan indeks sale_fact_sold_at_ix:
db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
Setelah mengelompokkan tabel, korelasinya
sold_atmenjadi 1.
Perintah CLUSTER.
Poin yang perlu diperhatikan:
- Mengelompokkan tabel pada kolom tertentu dapat mempengaruhi korelasi kolom lain. Misalnya, lihat korelasi ID setelah pengelompokan menurut
sold_at. CLUSTERMerupakan operasi yang berat dan memblokir, jadi jangan menerapkannya ke tabel langsung.
Untuk alasan ini, yang terbaik adalah memasukkan data yang sudah diurutkan dan tidak bergantung
CLUSTER.
Indeks kolom berkorelasi tinggi dengan BRIN
Dalam hal indeks, banyak developer memikirkan B-tree. Tetapi PostgreSQL menawarkan jenis indeks lain, seperti BRIN :
BRIN dirancang untuk bekerja dengan tabel yang sangat besar di mana beberapa kolom secara alami berkorelasi dengan lokasi fisiknya di dalam tabel
BRIN adalah singkatan dari Block Range Index. Menurut dokumentasi, BRIN bekerja paling baik dengan kolom yang sangat berkorelasi. Seperti yang telah kita lihat di bab-bab sebelumnya, ID dan cap waktu yang bertambah otomatis secara alami berkorelasi dengan struktur fisik tabel, jadi BRIN lebih bermanfaat bagi mereka.
Dalam kondisi tertentu BRIN dapat memberikan "nilai untuk uang" yang lebih baik dalam hal ukuran dan kinerja dibandingkan dengan indeks B-tree yang sebanding.
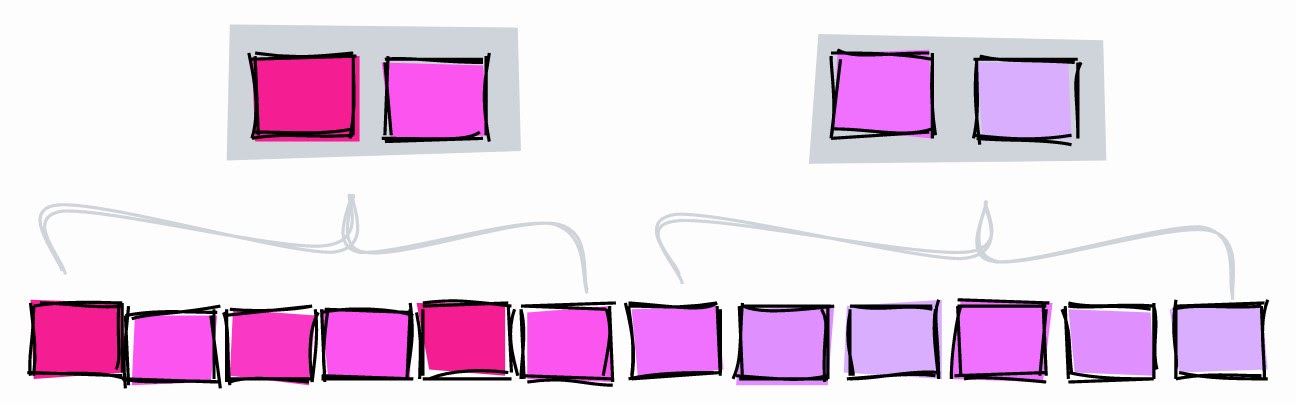
BRIN.
BRIN adalah rentang nilai dalam beberapa halaman yang berdekatan dalam sebuah tabel. Misalkan kita memiliki nilai berikut dalam kolom, masing-masing pada halaman terpisah:
1, 2, 3, 4, 5, 6, 7, 8, 9
BRIN bekerja dengan rentang halaman yang berdekatan. Jika Anda menentukan tiga halaman yang berdekatan, indeks akan memisahkan tabel menjadi beberapa rentang:
[1,2,3], [4,5,6], [7,8,9]
Untuk setiap rentang, BRIN menyimpan nilai minimum dan maksimum :
[1–3], [4–6], [7–9]
Mari gunakan indeks ini untuk mencari nilai 5:
- [1-3] - dia jelas tidak ada di sini.
- [4–6] - mungkin ada di sini.
- [7–9] - dia jelas tidak ada di sini.
Dengan BRIN kami telah membatasi area pencarian untuk memblokir 4-6.
Mari kita ambil contoh lain. Biarkan nilai dalam kolom memiliki korelasi yang mendekati nol, yaitu tidak diurutkan:
[2,9,5], [1,4,7], [3,8,6]
Mengindeks tiga blok yang berdekatan akan memberi kita rentang berikut:
[2–9], [1–7], [3–8]
Mari kita cari nilainya 5:
- [2-9] - mungkin ada di sini.
- [1-7] - mungkin ada di sini.
- [3–8] - mungkin ada di sini.
Dalam hal ini, indeks sama sekali tidak mempersempit pencarian, jadi tidak berguna.
Memahami pages_per_range
Jumlah halaman yang berdekatan ditentukan oleh parameter
pages_per_range. Jumlah halaman dalam suatu rentang memengaruhi ukuran dan presisi BRIN:
pages_per_rangeIndeks yang lebih kecil dan kurang akurat akan memberikan nilai yang besar .- Nilai yang kecil
pages_per_rangeakan memberikan indeks yang lebih besar dan lebih akurat.
Standarnya
pages_per_rangeadalah 128.
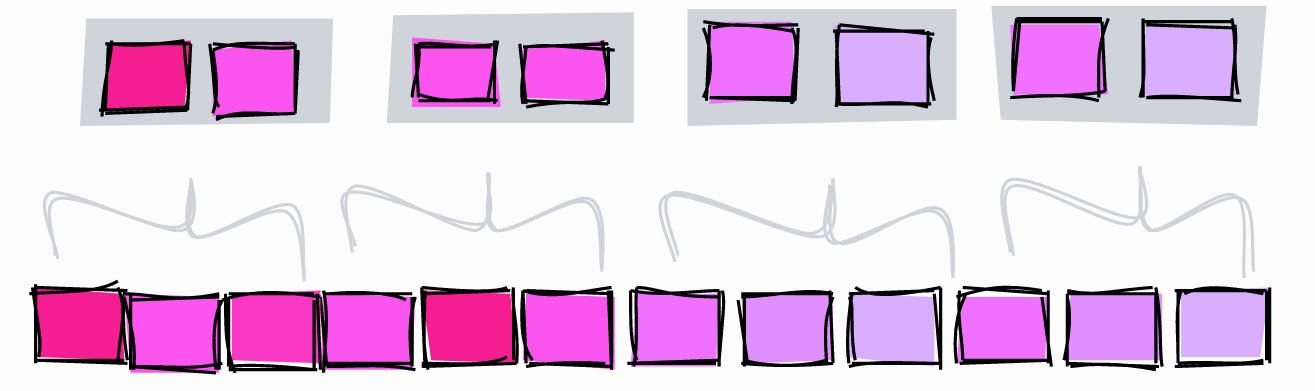
BRIN dengan pages_per_range yang lebih rendah.
Sebagai ilustrasi, mari buat BRIN dengan rentang dua halaman dan cari nilai 5:
- [1–2] - dia jelas tidak ada di sini.
- [3–4] - dia jelas tidak ada di sini.
- [5-6] - mungkin ada di sini.
- [7–8] - dia jelas tidak ada di sini.
- [9] - ini jelas tidak.
Dengan rentang dua halaman, kita dapat membatasi pencarian ke blok 5 dan 6. Jika kisarannya tiga halaman, indeks akan membatasi pencarian ke blok 4, 5, dan 6.
Perbedaan lain antara kedua indeks tersebut adalah ketika kisarannya tiga halaman, kita perlu menyimpan tiga rentang , dan dengan dua halaman dalam satu rentang, kami sudah mendapatkan lima rentang dan indeks meningkat.
Buat BRIN
Mari kita ambil tabel
sales_factdan buat BRIN menurut kolom sold_at:
db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
Standarnya adalah
pages_per_range = 128.
Sekarang mari kita tanyakan periode tanggal penjualan:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
Basis mendapatkan periode tanggal menggunakan BRIN, tetapi ini tidak menarik ...
Mengoptimalkan pages_per_range
Menurut rencana eksekusi, database menghapus 23.130 baris dari halaman, yang ditemukan menggunakan indeks. Ini mungkin menunjukkan bahwa kisaran yang kami tentukan untuk indeks terlalu besar untuk kueri ini. Mari buat indeks dengan setengah jumlah halaman dalam kisaran tersebut:
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
Dengan 64 halaman dalam rentang tersebut, database menghapus lebih sedikit baris yang ditemukan menggunakan indeks - 9 434. Ini berarti database harus melakukan lebih sedikit operasi I / O, dan kueri dijalankan sedikit lebih cepat, dalam ~ 5,5 md daripada ~ 8,9.
Mari kita uji indeks dengan nilai yang berbeda
pages_per_range:
| pages_per_range | Baris dihapus saat memeriksa ulang indeks |
| 128 | 23130 |
| 64 | 9 434 |
| 8 | 874 |
| 4 | 446 |
| 2 | 446 |
Mengurangi
pages_per_rangeindeks menjadi lebih tepat, dan menghapus lebih sedikit baris dari halaman yang ditemukannya.
Harap perhatikan bahwa kami telah mengoptimalkan kueri yang sangat spesifik. Ini bagus untuk ilustrasi, tetapi dalam kehidupan nyata lebih baik menggunakan nilai yang memenuhi kebutuhan sebagian besar kueri.
Memperkirakan ukuran indeks
Keuntungan utama lain dari BRIN adalah ukurannya. Pada bab sebelumnya, kami
sold_atmembuat indeks B-tree untuk bidang tersebut . Ukurannya 2.224 KB. Dan ukuran BRIN dengan parameter pages_per_range=128hanya 48 KB: 46 kali lebih kecil.
Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
Ukuran BRIN juga terpengaruh
pages_per_range. Misalnya, BRIN pages_per_range=2memiliki berat 56 Kb, sedikit lebih dari 48 Kb.
Jadikan indeks "tidak terlihat"
PostgreSQL memiliki fitur DDL transaksional yang keren . Selama bertahun-tahun dengan Oracle, saya sudah terbiasa menggunakan perintah DDL seperti
CREATE, DROPdan ALTER. Tetapi di PostgreSQL, Anda dapat menjalankan perintah DDL di dalam transaksi, dan perubahan hanya akan diterapkan setelah transaksi dilakukan.
Saya baru-baru ini menemukan bahwa menggunakan DDL transaksional dapat membuat indeks tidak terlihat! Ini berguna ketika Anda ingin melihat rencana eksekusi tanpa indeks.
Misalnya, dalam tabel
sale_factkami telah membuat indeks pada kolom sold_at. Rencana pelaksanaan untuk permintaan ambil penjualan bulan Juli terlihat seperti ini:
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
Untuk melihat seperti apa rencananya jika tidak ada indeks
sale_fact_sold_at_ix, Anda dapat meletakkan indeks di dalam transaksi dan segera memutar kembali:
db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
Pertama, mari kita mulai transaksi dengan
BEGIN. Kemudian kami menjatuhkan indeks dan membuat rencana eksekusi. Perhatikan bahwa rencana tersebut sekarang menggunakan pemindaian tabel lengkap seolah-olah indeks tersebut tidak ada. Saat ini transaksi masih dalam proses sehingga indeks belum turun. Untuk menyelesaikan transaksi tanpa menjatuhkan indeks, putar kembali menggunakan perintah ROLLBACK.
Mari kita periksa apakah indeksnya masih ada:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
Database lain yang tidak mendukung DDL transaksional dapat mencapai tujuan secara berbeda. Misalnya, Oracle mengizinkan Anda menandai indeks sebagai tidak terlihat dan pengoptimal akan mengabaikannya.
Peringatan : jika Anda menjatuhkan indeks dalam sebuah transaksi, hal itu akan menyebabkan pemblokiran operasi kompetitif
SELECT, INSERT, UPDATEdan DELETEdi meja sampai transaksi aktif. Gunakan dengan hati-hati di lingkungan pengujian dan hindari penggunaan di fasilitas produksi.
Jangan jadwalkan proses yang panjang untuk dimulai pada awal jam berapa pun
Investor tahu bahwa hal-hal aneh bisa terjadi ketika harga saham mencapai nilai bulat yang indah, misalnya $ 10, $ 100, $ 1000. Inilah yang mereka tulis tentang itu :
[...] harga aset dapat berubah tak terduga, melewati nilai bulat seperti $ 50 atau $ 100 per saham. Banyak pedagang yang tidak berpengalaman suka membeli atau menjual aset ketika harga mencapai angka bulat karena menurut mereka itu adalah harga yang wajar.
Dari sudut pandang ini, pengembang tidak jauh berbeda dengan investor. Ketika mereka perlu menjadwalkan proses yang panjang, mereka biasanya memilih satu jam.
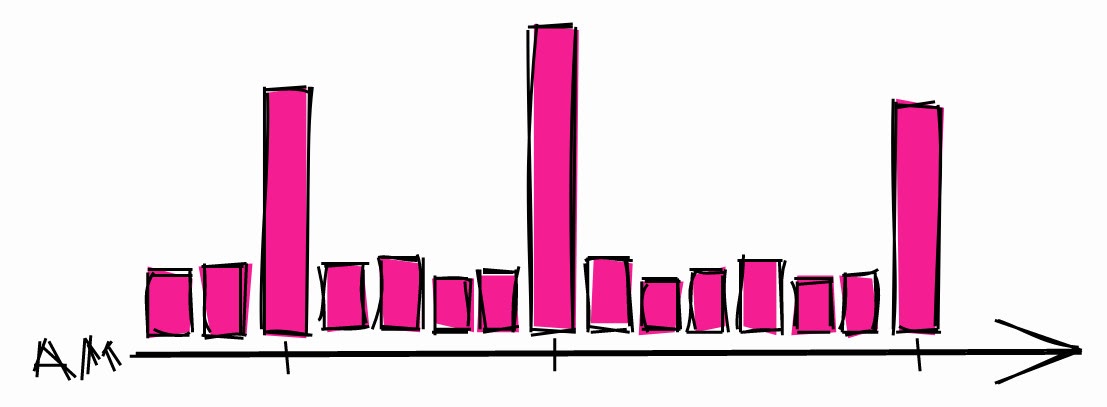
Beban sistem semalaman yang khas.
Hal ini dapat menyebabkan lonjakan beban selama jam-jam tersebut. Jadi jika Anda perlu menjadwalkan proses yang lama, ada kemungkinan lebih besar bahwa sistem akan menganggur di lain waktu.
Juga disarankan untuk menggunakan penundaan acak dalam jadwal Anda sehingga Anda tidak memulai pada waktu yang sama setiap saat. Kemudian bahkan jika tugas lain dijadwalkan untuk jam ini, itu tidak akan menjadi masalah besar. Jika Anda menggunakan timer systemd, Anda dapat menggunakan opsi RandomizedDelaySec .
Kesimpulan
Artikel ini memberikan tip dari berbagai tingkat bukti berdasarkan pengalaman saya. Beberapa mudah diimplementasikan, beberapa memerlukan pemahaman yang mendalam tentang cara kerja database. Basis data adalah tulang punggung sebagian besar sistem modern, jadi waktu yang dihabiskan untuk mempelajari cara bekerja adalah investasi yang baik untuk pengembang mana pun!