Halo, Habr! Pada artikel ini saya akan menunjukkan kepada Anda bagaimana membuat analisis frekuensi dari bahasa Internet Rusia modern dan menggunakannya untuk menguraikan teks. Siapa peduli, selamat datang di bawah luka!

Analisis frekuensi bahasa Internet Rusia
Jejaring sosial Vkontakte diambil sebagai sumber dari mana Anda bisa mendapatkan banyak teks dengan bahasa Internet modern, atau lebih tepatnya, ini adalah komentar pada publikasi di berbagai komunitas jaringan ini. Saya memilih sepakbola nyata sebagai komunitas . Untuk mengurai komentar, saya menggunakan API Vkontakte :
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passHasilnya sekitar 200MB teks. Sekarang kita menghitung karakter mana yang muncul berapa kali:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequencyHasil yang diperoleh dapat dibandingkan dengan hasil dari Wikipedia dan ditampilkan sebagai:
1) grafik perbandingan
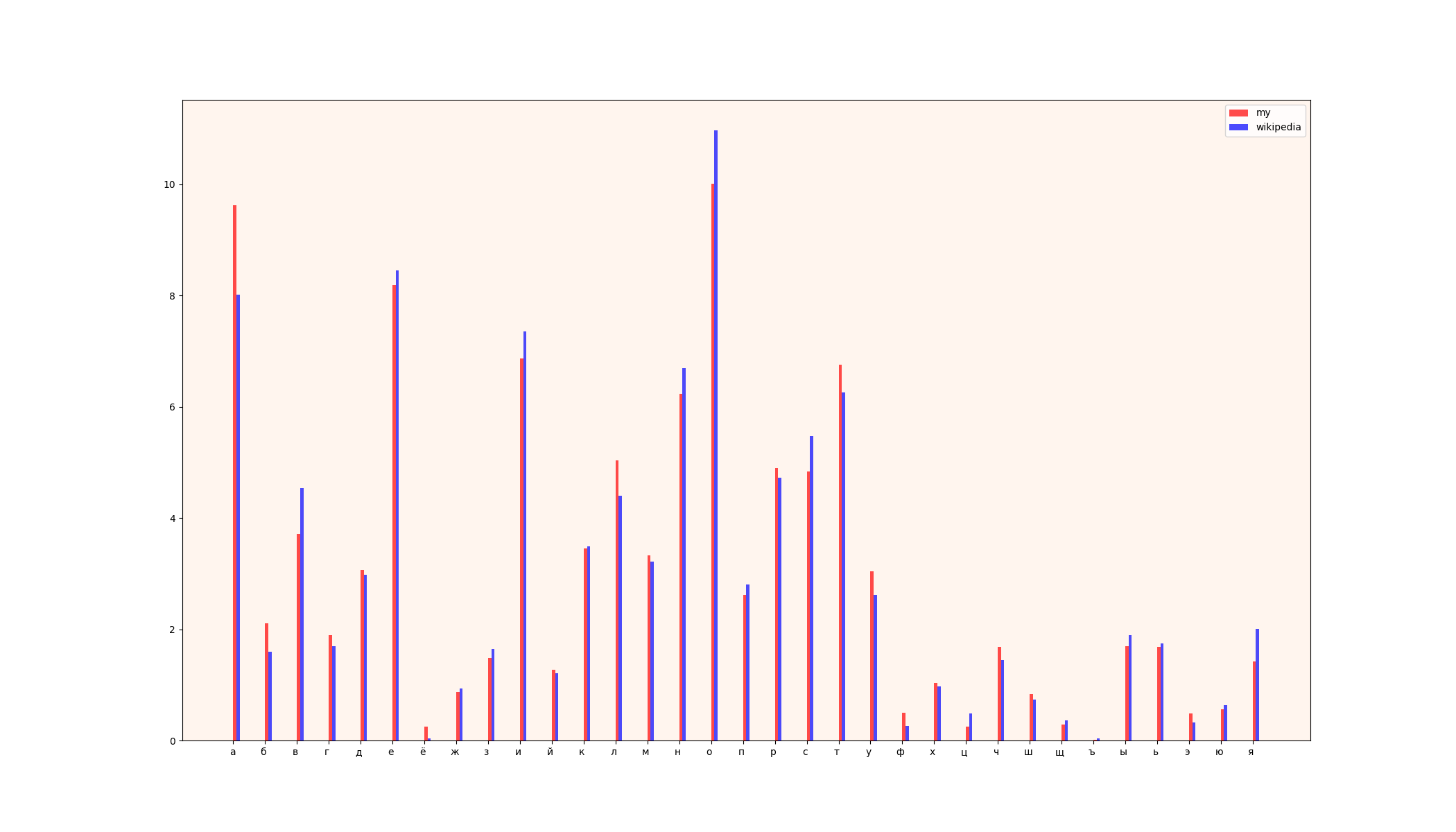
2) tabel (kiri - data Wikipedia, kanan - data saya)
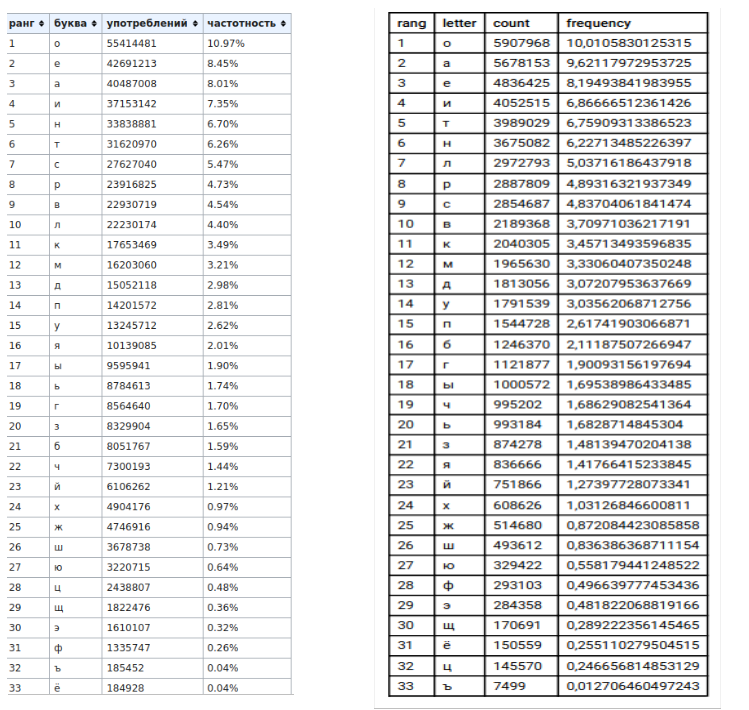
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
Jika Anda melihat teks yang didekripsi, Anda dapat menebak di mana kesalahan algoritme kami: perkelahian → lakukan, vadio → radio, toho → penambahan, kewalahan → orang. Jadi, adalah mungkin untuk menguraikan seluruh teks, setidaknya untuk memahami makna teks tersebut. Saya juga ingin mencatat bahwa metode ini hanya akan efektif dalam mendekripsi teks panjang yang telah dienkripsi dengan metode enkripsi simetris. Kode lengkapnya tersedia di Github .