
Hari ini saya akan memberi tahu Anda sedikit tentang pemikiran saya tentang tarantool / cartridge failover. Pertama, beberapa kata tentang apa itu cartridge: ini adalah bagian dari kode lua yang bekerja di dalam tarantool dan menggabungkan tarantula satu sama lain menjadi satu "cluster" bersyarat. Ini karena dua hal:
- setiap tarantula mengetahui alamat jaringan dari semua tarantula lainnya;
- tarantula secara teratur melakukan "ping" satu sama lain melalui UDP untuk memahami siapa yang masih hidup dan siapa yang tidak. Disini saya sengaja sedikit menyederhanakan, algoritma ping lebih rumit dari sekedar request-response, tapi ini tidak terlalu penting untuk parsing. Jika tertarik - google algoritma SWIM.
Dalam sebuah cluster, semuanya biasanya dibagi menjadi tarantula stateful (master / replika) dan stateless (router). Tarantula stateless bertanggung jawab untuk menyimpan data, dan tarantula stateless bertanggung jawab untuk permintaan perutean.
Ini adalah tampilannya pada gambar:
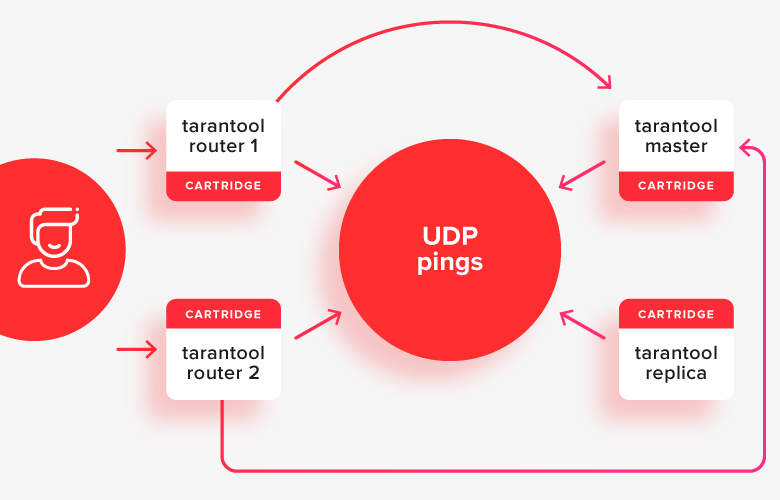
Klien membuat permintaan ke salah satu router aktif, dan mereka mengarahkan permintaan ke salah satu penyimpanan, yang sekarang menjadi master aktif. Pada gambar, jalur ini ditunjukkan dengan panah.
Sekarang saya tidak ingin memperumit masalah dan memperkenalkan sharding ke dalam percakapan tentang memilih seorang pemimpin, tetapi situasinya akan sedikit berbeda. Satu-satunya perbedaan adalah bahwa router masih perlu membuat keputusan tentang replika mana yang akan dikirim dari toko.
Pertama, mari kita bicara tentang bagaimana node mempelajari alamat satu sama lain. Untuk melakukan ini, masing-masing memiliki file yaml pada disk dengan topologi cluster, yaitu, dengan informasi tentang alamat jaringan semua anggota, dan siapa di antara mereka adalah siapa (dengan atau tanpa status). Ditambah kemungkinan kustomisasi tambahan, tetapi untuk saat ini, mari kita kesampingkan itu. File konfigurasi berisi pengaturan untuk seluruh cluster secara keseluruhan, dan sama untuk setiap tarantula. Jika ada perubahan pada mereka, maka mereka dibuat serempak untuk semua tarantula.
Sekarang perubahan konfigurasi dapat dilakukan melalui API dari salah satu tarantula dalam cluster: itu akan terhubung ke orang lain, mengirimi mereka versi baru dari konfigurasi, semua orang akan menerapkannya, dan di mana pun akan ada versi baru, sama lagi.
Skenario - kegagalan node, peralihan
Dalam situasi ketika router gagal, semuanya lebih atau kurang sederhana: klien hanya perlu pergi ke router aktif lainnya, dan dia akan mengirimkan permintaan ke toko yang diinginkan. Tetapi bagaimana jika, misalnya, tuan dari salah satu Storaja jatuh?
Saat ini kami telah menerapkan algoritme "naif" untuk kasus seperti itu, yang mengandalkan ping UDP. Jika replika tidak "melihat" tanggapan dari master untuk melakukan ping dalam waktu singkat, replika tersebut menganggap bahwa master telah jatuh, dan menjadi master itu sendiri, beralih ke mode baca-tulis dari hanya baca. Router bertindak dengan cara yang sama: jika mereka tidak melihat waktu respons ping dari master, mereka mengalihkan lalu lintas ke replika.
Ini bekerja relatif baik dalam kasus sederhana, kecuali untuk situasi otak terbelah, ketika setengah dari node dipisahkan dari yang lain oleh beberapa jenis masalah jaringan:
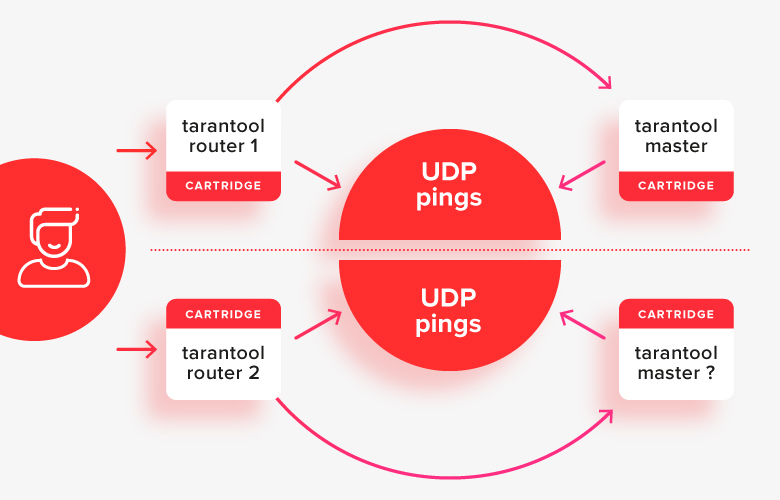
Dalam situasi ini, router akan melihat bahwa "separuh lainnya" dari cluster tidak tersedia, dan akan menganggap separuh mereka sebagai yang utama, dan ternyata ada dua master dalam sistem pada saat yang bersamaan. Ini adalah kasus penting pertama yang harus diselesaikan.
Skenario - Edit Konfigurasi pada Kegagalan
Skenario penting lainnya adalah mengganti tarantula yang gagal dalam sebuah cluster dengan yang baru, atau menambahkan node ke cluster ketika salah satu replika atau router tidak tersedia.
Selama operasi normal, ketika semua yang ada di cluster tersedia, kita dapat terhubung melalui API ke node mana pun, memintanya untuk mengedit konfigurasi, dan, seperti yang saya katakan di atas, node akan "meluncurkan" konfigurasi baru ke seluruh cluster.
Tetapi ketika seseorang tidak tersedia, Anda tidak dapat menerapkan konfigurasi baru, karena ketika node ini tersedia lagi, akan menjadi tidak jelas mana di antara mereka di cluster yang memiliki konfigurasi yang benar dan mana yang tidak. Masih tidak dapat diaksesnya node satu sama lain dapat berarti bahwa ada otak yang terbelah di antara mereka. Dan mengedit konfigurasi tidak aman, karena Anda dapat salah mengeditnya dengan cara berbeda di bagian yang berbeda.
Karena alasan ini, kami sekarang melarang pengeditan konfigurasi melalui API saat seseorang tidak tersedia. Ini dapat diperbaiki hanya pada disk, melalui file teks (secara manual). Di sini Anda harus memahami dengan baik apa yang Anda lakukan dan berhati-hatilah: otomatisasi tidak akan membantu Anda dengan cara apa pun.
Hal ini membuat pengoperasian menjadi tidak nyaman, dan ini adalah kasus kedua yang harus diselesaikan.
Skenario - failover stabil
Masalah lain dengan model failover naif adalah bahwa peralihan dari master ke replika jika terjadi kegagalan master tidak direkam di mana pun. Semua node membuat keputusan untuk beralih sendiri, dan ketika master aktif, lalu lintas akan beralih lagi.
Ini mungkin atau mungkin tidak menjadi masalah. Sebelum menyalakan master, master akan "mengejar" log transaksional dari replika, jadi kemungkinan besar tidak akan ada jeda data yang besar. Masalahnya hanya akan terjadi jika ada masalah jaringan, dan ada paket yang hilang: maka kemungkinan besar akan ada "flashing" berkala dari master (mengepakkan).
Solusinya adalah koordinator "kuat" (etcd / consul / tarantool)
Untuk menghindari masalah dengan otak yang terbelah, dan untuk memungkinkan pengeditan konfigurasi ketika cluster tidak tersedia sebagian, kami memerlukan koordinator yang kuat yang tahan terhadap segmentasi jaringan. Koordinator harus didistribusikan ke 3 pusat data sehingga jika ada yang gagal, tetap beroperasi.
Sekarang ada 2 koordinator berbasis RAFT yang menggunakan etcd dan konsul untuk ini. Ketika replikasi sinkronis muncul di tarantool, itu juga dapat digunakan untuk ini.
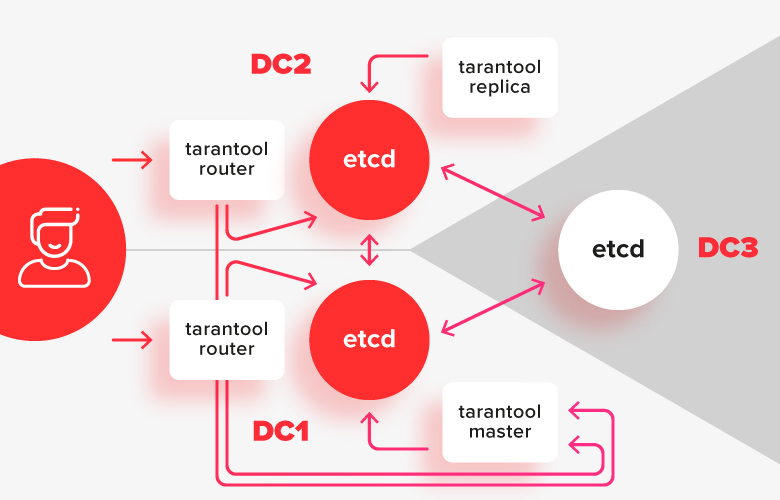
Dalam skema ini, instalasi tarantula dibagi menjadi dua pusat data, dan terhubung ke instalasi etcd lokalnya. Sebuah contoh dari etcd di pusat data ketiga berfungsi sebagai penengah sehingga jika terjadi kegagalan salah satu pusat data, untuk mengatakan dengan tepat yang mana yang tetap menjadi mayoritas.
Manajemen konfigurasi dengan koordinator yang kuat
Seperti yang saya katakan di atas, dengan tidak adanya koordinator dan kegagalan salah satu tarantula, kami tidak dapat mengedit konfigurasi secara terpusat, karena tidak mungkin untuk mengatakan konfigurasi mana di mana dari node yang benar.
Dalam kasus koordinator yang kuat, semuanya lebih sederhana: kita dapat menyimpan konfigurasi di koordinator, dan setiap instance tarantula akan berisi cache dari konfigurasi ini di sistem filenya. Setelah sambungan berhasil ke koordinator, itu akan memperbarui salinan konfigurasi ke yang ada di koordinator.
Mengedit konfigurasi juga menjadi lebih mudah: dapat dilakukan melalui API tarantula mana pun. Ini akan mengambil kunci di koordinator, mengganti nilai yang diinginkan dalam konfigurasi, menunggu semua node menerapkannya, dan melepaskan kunci. Nah, atau sebagai upaya terakhir, Anda dapat mengedit konfigurasi secara manual di etcd, dan ini akan diterapkan ke seluruh cluster.
Dimungkinkan untuk mengedit konfigurasi bahkan jika beberapa tarantula tidak tersedia. Hal utama adalah sebagian besar node koordinator tersedia.
Failover dengan koordinator yang kuat
Peralihan node yang andal dengan koordinator diselesaikan karena fakta bahwa selain konfigurasi, kami akan menyimpan informasi koordinator tentang siapa master saat ini di replika dan di mana sakelar dibuat.
Algoritme failover berubah sebagai berikut:
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
Dengan koordinator, perlindungan mengepak juga dimungkinkan. Di koordinator, Anda dapat merekam seluruh riwayat pengalihan, dan jika selama X menit terakhir master beralih ke replika, maka pengalihan sebaliknya hanya dilakukan secara eksplisit oleh administrator.
Poin penting lainnya adalah yang disebut "Anggar". Tarantula yang terputus dari pusat data lain (atau terhubung ke koordinator yang telah kehilangan mayoritasnya) harus berasumsi bahwa kemungkinan besar cluster lainnya, yang aksesnya hilang, memiliki mayoritas. Dan itu berarti, dalam waktu tertentu, semua node yang terputus dari mayoritas harus masuk ke read-only.
Masalah ketidaktersediaan koordinator
Saat kami mendiskusikan pendekatan untuk bekerja dengan koordinator, kami menerima permintaan untuk memastikan bahwa jika koordinator jatuh, tetapi semua tarantula utuh, jangan terjemahkan seluruh cluster menjadi hanya baca.
Pada awalnya tampaknya tidak terlalu realistis untuk melakukan ini, tetapi kemudian kami ingat bahwa cluster itu sendiri memantau ketersediaan node lain melalui ping UDP. Ini berarti kita dapat menargetkan mereka dan tidak memicu pemilihan ulang master di dalam set replika, jika jelas melalui ping UDP bahwa seluruh set replika hidup.
Pendekatan ini akan membantu Anda mengurangi kekhawatiran tentang ketersediaan koordinator, terutama jika Anda perlu mem-boot ulang misalnya untuk memperbarui.
Rencana implementasi
Sekarang kami mengumpulkan umpan balik dan memulai penerapan. Jika Anda memiliki sesuatu untuk dikatakan - tulis di komentar atau secara pribadi.
Rencananya seperti ini:
- Buat dukungan etcd di tarantool [selesai]
- Failover menggunakan etcd sebagai koordinator, stateful [selesai]
- Failover menggunakan tarantula sebagai koordinator, latching [selesai]
- Menyimpan konfigurasi di etcd [dalam proses]
- Menulis alat CLI untuk perbaikan cluster [dalam proses]
- Menyimpan konfigurasi di tarantula
- Manajemen cluster ketika bagian dari cluster tidak tersedia
- Pagar
- Perlindungan mengepak
- Failover menggunakan konsul sebagai koordinator
- Menyimpan konfigurasi di konsul
Di masa mendatang, kami hampir pasti akan membuang seluruh cluster tanpa koordinator yang kuat. Ini kemungkinan besar akan bertepatan dengan implementasi replikasi sinkronis berbasis RAFT di tarantula.
Ucapan Terima Kasih
Terima kasih kepada pengembang dan admin Mail.ru atas umpan balik, kritik, dan pengujian yang diberikan.