
Sumber: Vecteezy
Ya, regresi linier bukan satu-satunya. Sebutkan
lima algoritme pembelajaran mesin dengan cepat.
Tidak mungkin Anda akan menyebutkan banyak algoritme regresi. Bagaimanapun, satu-satunya algoritma regresi yang banyak digunakan adalah regresi linier, terutama karena kesederhanaannya. Namun, regresi linier seringkali tidak dapat diterapkan pada data nyata karena pilihan yang terlalu terbatas dan kebebasan bermanuver yang terbatas. Ini sering digunakan hanya sebagai model dasar untuk evaluasi dan perbandingan dengan pendekatan penelitian baru.
Tim Solusi Cloud Mail.rumenerjemahkan artikel, yang penulisnya menjelaskan 5 algoritma regresi. Mereka layak dimiliki di kotak alat Anda bersama dengan algoritme klasifikasi populer seperti SVM, pohon keputusan, dan jaringan saraf.
1. Regresi jaringan saraf
Teori
Jaringan saraf sangat kuat, tetapi biasanya digunakan untuk klasifikasi. Sinyal berjalan melalui lapisan neuron dan digeneralisasikan menjadi salah satu dari beberapa kelas. Namun, mereka dapat dengan cepat diadaptasi ke dalam model regresi dengan mengubah fungsi aktivasi terakhir.
Setiap neuron mentransmisikan nilai dari koneksi sebelumnya melalui fungsi aktivasi yang melayani tujuan generalisasi dan non-linearitas. Biasanya fungsi aktivasi adalah sesuatu seperti sigmoid atau fungsi ULT (unit linier tersearah).
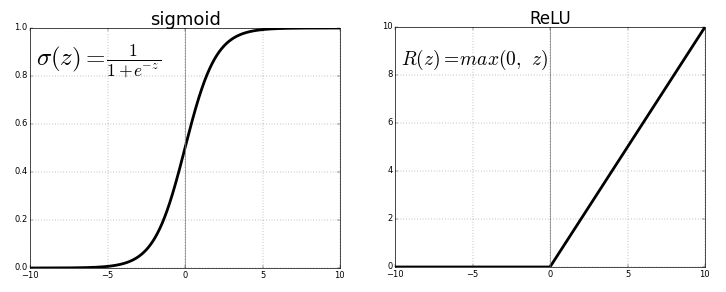
Sumber . Gambar bebas
Tapi, mengganti fungsi aktivasi terakhir (neuron keluaran) dengan yang linierfungsi aktivasi, sinyal keluaran dapat dipetakan ke banyak nilai di luar kelas tetap. Dengan demikian, output bukanlah probabilitas untuk menetapkan sinyal input ke salah satu kelas, tetapi nilai kontinu di mana jaringan saraf memperbaiki pengamatannya. Dalam pengertian ini, kita dapat mengatakan bahwa jaringan saraf melengkapi regresi linier.
Regresi jaringan saraf memiliki keunggulan non-linearitas (selain kompleksitas) yang dapat diperkenalkan dengan sigmoid dan fungsi aktivasi non-linier lainnya sebelumnya di jaringan saraf. Namun, penggunaan ULT yang berlebihan sebagai fungsi aktivasi dapat berarti bahwa model cenderung menghindari keluaran nilai negatif, karena ULT mengabaikan perbedaan relatif antara nilai negatif.
Ini dapat diatasi baik dengan membatasi penggunaan ULT dan menambahkan lebih banyak nilai negatif dari fungsi aktivasi yang sesuai, atau dengan menormalkan data ke kisaran yang benar-benar positif sebelum pelatihan.
Penerapan
Menggunakan Keras, mari kita membangun struktur jaringan saraf tiruan, meskipun hal yang sama dapat dilakukan dengan jaringan saraf konvolusional atau jaringan lain jika lapisan terakhir adalah lapisan padat dengan aktivasi linier atau hanya lapisan dengan aktivasi linier. ( Perhatikan bahwa impor Keras tidak terdaftar untuk menghemat ruang ).
model = Sequential()
model.add(Dense(100, input_dim=3, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(50, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(25, activation='softmax'))
#IMPORTANT PART
model.add(Dense(1, activation='linear'))
Masalah dengan jaringan saraf selalu varians tinggi dan kecenderungan untuk overfit. Ada banyak sumber non-linearitas pada contoh kode di atas seperti SoftMax atau sigmoid.
Jika jaringan neural Anda berfungsi dengan baik dengan data pelatihan dengan struktur linier murni, mungkin lebih baik menggunakan regresi pohon keputusan terpotong, yang mengemulasi jaringan saraf linier dan sangat tersebar, tetapi memungkinkan data scientist memiliki kontrol yang lebih baik atas kedalaman, lebar, dan atribut lain untuk mengontrol overfitting.
2. Regresi pohon keputusan
Teori
Pohon keputusan dalam klasifikasi dan regresi sangat mirip karena mereka bekerja dengan membangun pohon dengan node ya / tidak. Namun, sementara simpul daun klasifikasi menghasilkan nilai kelas tunggal (misalnya, 1 atau 0 untuk masalah klasifikasi biner), pohon regresi berakhir dengan nilai dalam mode kontinu (misalnya, 4593,49 atau 10,98).
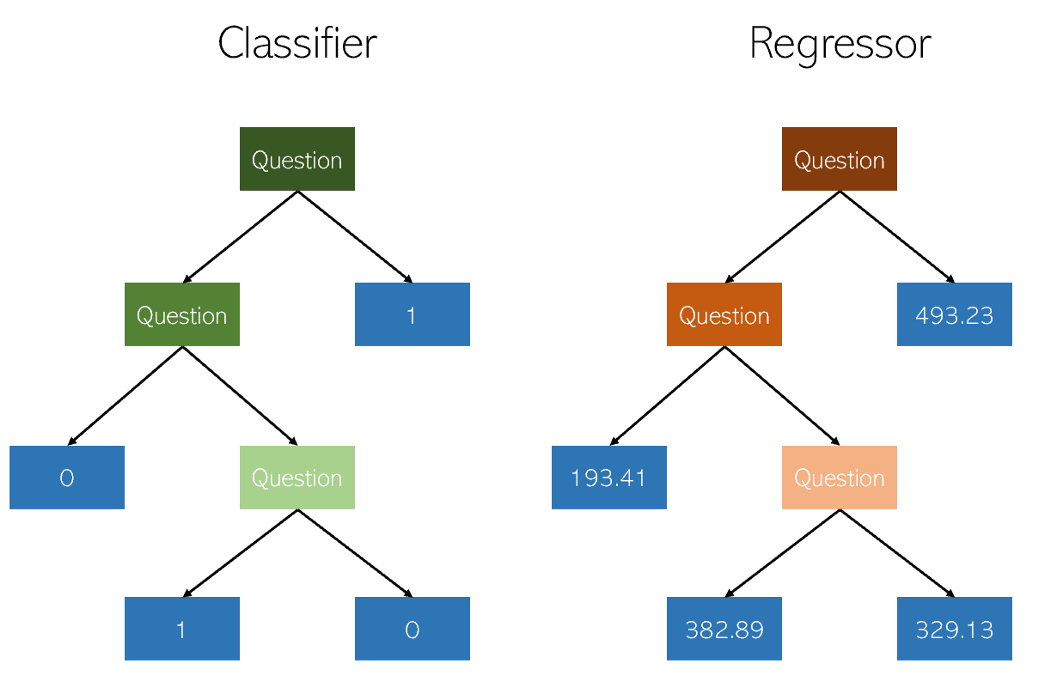
Ilustrasi penulis
Karena sifat regresi yang spesifik dan sangat tersebar sebagai masalah pembelajaran mesin belaka, regresi pohon keputusan harus dipangkas dengan hati-hati. Namun, pendekatan regresi tidak teratur - alih-alih menghitung nilai dalam skala kontinu, ia tiba di node akhir tertentu. Jika regressor dipotong terlalu banyak, ia memiliki terlalu sedikit simpul daun untuk memenuhi tujuannya dengan benar.
Akibatnya, pohon keputusan harus dipangkas sehingga memiliki kebebasan paling banyak (nilai keluaran yang mungkin dari regresi adalah jumlah simpul daun), tetapi tidak cukup untuk menjadi terlalu dalam. Jika Anda tidak memangkasnya, algoritme yang sudah sangat tersebar akan menjadi terlalu rumit karena sifat dari regresi.
Penerapan
Regresi pohon keputusan dapat dengan mudah dibuat di
sklearn:
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
Karena parameter regresi pohon keputusan sangat penting, disarankan untuk menggunakan parameter alat pengoptimalan mesin telusur
GridCVdari sklearn, untuk menemukan rekomendasi yang tepat untuk model ini.
Saat mengevaluasi kinerja secara formal, gunakan pengujian
K-folddaripada pengujian standar train-test-splituntuk menghindari keacakan yang terakhir yang dapat melanggar hasil sensitif model varian tinggi.
Bonus: Kerabat dekat dari pohon keputusan, algoritma hutan acak, juga dapat diimplementasikan sebagai regressor. Regresor hutan acak mungkin atau mungkin tidak berkinerja lebih baik daripada pohon keputusan dalam regresi (sementara biasanya kinerjanya lebih baik dalam klasifikasi) karena keseimbangan yang rumit antara redundansi dan kekurangan dalam sifat algoritma pembangunan pohon.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
3. Regresi LASSO
Metode regresi laso (LASSO, Least Absolute Shrinkage and Selection Operator) adalah variasi dari regresi linier yang secara khusus diadaptasi untuk data yang menunjukkan multikolinearitas yang kuat (yaitu, korelasi fitur yang kuat satu sama lain).
Ini mengotomatiskan bagian dari pemilihan model, seperti pemilihan variabel atau pengecualian parameter. LASSO menggunakan penyusutan, yaitu proses di mana nilai data mendekati titik pusat (seperti rata-rata).

Ilustrasi penulis. Visualisasi yang disederhanakan dari
proses kompresi Proses kompresi menambahkan beberapa keuntungan pada model regresi:
- Estimasi parameter sebenarnya yang lebih akurat dan stabil.
- Mengurangi kesalahan pengambilan sampel dan out-of-sampling.
- Menghaluskan fluktuasi spasial.
Daripada menyesuaikan kompleksitas model untuk mengimbangi kompleksitas data, seperti jaringan saraf varians tinggi dan metode regresi pohon keputusan, laso mencoba untuk mengurangi kompleksitas data sehingga dapat ditangani dengan metode regresi sederhana dengan melengkungkan ruang tempatnya berada. Dalam proses ini, laso secara otomatis membantu menghilangkan atau mendistorsi fitur yang sangat berkorelasi dan berlebihan dalam metode varians rendah.
Regresi Lasso menggunakan regularisasi L1, yaitu memberi bobot pada kesalahan dengan nilai absolutnya. Daripada, misalnya, regularisasi L2, yang menimbang kesalahan dengan kuadratnya, untuk menghukum kesalahan yang lebih signifikan dengan lebih kuat.
Regularisasi ini sering menyebabkan model yang lebih jarang dengan koefisien yang lebih sedikit, karena beberapa koefisien dapat menjadi nol dan oleh karena itu dikecualikan dari model. Ini memungkinkannya untuk ditafsirkan.
Penerapan
The
sklearnregresi lasso hadir dengan model yang cross-validasi yang memilih yang paling efektif dari banyak model dilatih dengan parameter fundamental yang berbeda dan jalur pembelajaran yang mengotomatisasi tugas yang lain akan harus melakukan secara manual.
from sklearn.linear_model import LassoCV
model = LassoCV()
model.fit(X_train, y_train)
4. Regresi ridge (regresi ridge)
Teori
Regresi ridge atau regresi ridge sangat mirip dengan regresi LASSO yang menerapkan kompresi. Kedua algoritma tersebut cocok untuk kumpulan data dengan sejumlah besar fitur yang tidak independen satu sama lain (collinearity).
Namun, perbedaan terbesar di antara keduanya adalah bahwa regresi ridge menggunakan regularisasi L2, yaitu tidak ada koefisien yang tidak menjadi nol, seperti halnya regresi LASSO. Sebaliknya, koefisien semakin mendekati nol, tetapi memiliki sedikit insentif untuk mencapainya karena sifat regularisasi L2.
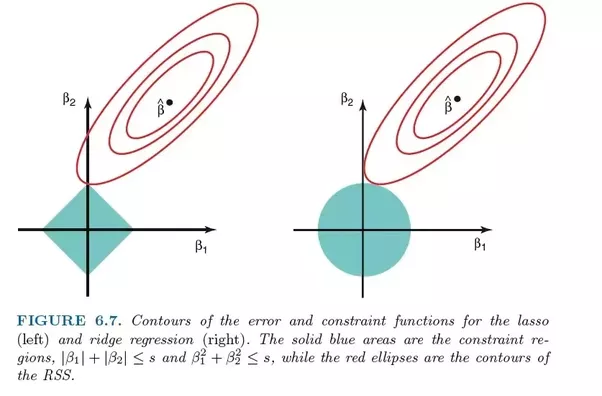
Perbandingan kesalahan dalam regresi laso (kiri) dan regresi ridge (kanan). Karena Regresi Punggung menggunakan regularisasi L2, areanya menyerupai lingkaran, sedangkan regularisasi L1 menggambar garis lurus. Gambar gratis. Sumber
Dalam laso, peningkatan dari kesalahan 5 ke kesalahan 4 dibobotkan dengan cara yang sama seperti peningkatan dari 4 menjadi 3, dan juga dari 3 ke 2, dari 2 ke 1, dan dari 1 ke 0. Oleh karena itu, lebih banyak koefisien mencapai nol dan lebih banyak fitur dihilangkan.
Namun, dalam regresi ridge, peningkatan dari kesalahan 5 ke kesalahan 4 dihitung sebagai 5² - 4² = 9, sedangkan peningkatan dari 4 ke 3 diberi bobot hanya sebagai 7. Secara bertahap, penghargaan untuk perbaikan menurun; oleh karena itu, lebih sedikit fitur yang dihilangkan.
Regresi ridge paling cocok untuk situasi di mana kita ingin memprioritaskan sejumlah besar variabel, yang masing-masing memiliki pengaruh kecil. Jika model Anda perlu memperhitungkan beberapa variabel, yang masing-masing memiliki pengaruh sedang hingga besar, laso adalah pilihan terbaik.
Penerapan
Regresi punggungan
sklearndapat diimplementasikan sebagai berikut (lihat di bawah). Seperti halnya regresi laso, sklearnterdapat implementasi untuk memvalidasi silang pemilihan model terbaik dari banyak model terlatih.
from sklearn.linear_model import RidgeCV
model = Ridge()
model.fit(X_train, y_train)
5. Regresi ElasticNet
Teori
ElasticNet bertujuan untuk menggabungkan yang terbaik dari Regresi Ridge dan Regresi Lasso dengan menggabungkan regularisasi L1 dan L2.
Lasso dan Ridge Regression adalah dua metode regularisasi yang berbeda. Dalam kedua kasus tersebut, λ adalah faktor kunci yang mengontrol besarnya denda:
- λ = 0, , .
- λ = ∞, - . , , .
- 0 < λ < ∞, λ , .
Untuk parameter λ, regresi ElasticNet menambahkan parameter tambahan α , yang mengukur bagaimana "mencampurkan" regularisasi L1 dan L2. Jika α adalah 0, modelnya adalah regresi ridge murni, dan jika α adalah 1, itu adalah regresi laso murni.
"Rasio pencampuran" α hanya menentukan berapa banyak regularisasi L1 dan L2 yang harus dipertimbangkan dalam fungsi kerugian. Ketiga model regresi populer - Ridge, Lasso, dan ElasticNet - bertujuan untuk mengurangi ukuran koefisiennya, tetapi masing-masing bertindak secara berbeda.
Penerapan
ElasticNet dapat diimplementasikan menggunakan model validasi silang sklearn:
from sklearn.linear_model import ElasticNetCV
model = ElasticNetCV()
model.fit(X_train, y_train)
Apa lagi yang harus dibaca tentang topik ini: